阿里微服务架构师随手笔记:教你如何手写Docker
模拟Docker实现一个简单的容器,不到 200行代码(包括空行、注释、异常处理),这并不是吹牛B。容器技术几乎是Linux kernel内置的模块,我们简单调用一下API就能搞定很多事情。当然你要考虑各种商业因素、政治因素那就会成长为Docker这种量级的代码量了。
盗用一下朋友圈里的段子:小公司与大公司的区别就是,以杀猪为例,小公司是找到猪直接乱刀砍死。大公司要先做一套笼具抓猪,再做一套流程磨刀,再发明一套刀法(工程师通常会就刀法争论很久)杀猪。抓猪的笼具除了能抓猪还能抓跳骚,磨刀的工具除了能磨柴刀,还能磨指甲刀。杀猪的流程除了能杀猪,也能杀鸡。做完了之后你只敲一个杀猪的命令就行。你不知道猪在哪里,因为这是另一个人负责的,代码放在你不知道的某个目录下;你也不知道刀在哪里,因为目录不可见,格式不可读。刀法是啥你也不知道。这套系统理论上威力无比,一群人费了老大劲做出来,除了用柴刀杀猪没干过别的,杀鸡从来没测试过,杀跳骚代码都不完整。但是公司里的所有人都觉得,杀猪就应该这样。所以大家每天忙忙碌碌,猪快活的过了一年又一年。
所以这系列文章我主要介绍如何找到猪、怎么持刀不伤到自己,如何发力能够更凶狠;然后现场表演一下把一头活蹦乱跳的猪捅死。
涉及到的技术
写一个容器只需要两个技术——Namespace和CGroup,而这两个东西都是Linux kernel提供的,我们要做的就是——调用一下。无耻的盗用一下Brendan Gregg大神的图。

这张图中蕴含了一个经常被忽视的细节——容器是共享内核的,它们属于多个进程同时运行在一个内核上,只不过是利用Namespace把它们隔离开,用CGroup限制可用资源。而虚拟机是共享“硬件”的,每个虚拟机都有自己独立的操作系统。所以,虚拟机是可引导的、绝对安全的隔离技术;而容器是非常脆弱的,不安全的隔离技术。
Namespace是Linux内核提供的一种隔离技术,它提供了六种隔离空间:

看的一脸懵逼对不对?没关系,简单的解释一下。
学过操作系统原理的同学都知道(没学过?你还敢在这个行业混?),在一个内核所有进程都共享操作系统定义的资源——主机名、域名、ARP表、路由表、NAT表;文件系统、用户和组、进程编号。以主机名为例,它是由操作系统定义在一块内存空间中的,所以进程A能看到,进程B也能看到(如果有权限甚至可以修改)。Namespace提供了一种隔离技术,可以让每个进程都定义“自己的主机名”。你可以理解为内核为每个进程都提供了一份当前主机名的备份,进程当然可以修改这份数据,但是这个修改只能作用于自己,其他进程感知不到——因为它不再是“全局”的。
经常有人问是不是所有应用都可以做容器化?理解Namespace就很容易回答这个问题。容器技术本质上还是共享内核,所以任何需要修改内核的应用都不可以被容器化。比如LVS、OpenvSwtich这些需要加载内核模块的应用都没有办法做成容器。
Hello world
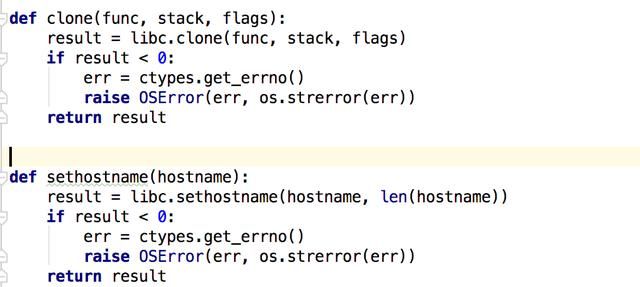
调用Namespace非常简单,只需要一个API(没错,一个,只要一个)——clone。

它会创建一个新的线程(内核不会太区分线程和进程),第一个参数指定了线程的代码入口,第二个参数是线程栈,第三个参数是标志位,第四个参数是代码入口的参数指针。
我们上面所罗列的Namespace参数就是通过第三个参数——标志位传递的。

我们先测试一下UTS(主机名)是否能正常工作,因为子进程不涉及到递归调用所以定义1024字节的stack大小应该足够了。main方法里的os.waitpid(pid, 0)是必须的,否则子进程会因为父进程终止而提前退出。
child_func是子进程的入口,这段代码里我们调用sethostname修改主机然后再执行hostname验证修改是否生效了。
libc是我封装好的系统调用,非常简单。
小试牛刀一下:

首先在父进程中输出自己的进程编号和子进程的编号,然后在子进程中输出自己的进程编号和父进程的编号。在子进程中我们调用sethostname修改了主机名并且通过hostname验证了调用结果。但是这个修改并没有波及到内核,最后我们在shell中调用hostname验证了这一结果。
要有Shell
上面只是执行一次修改hostname的动作,动作有点小,不够过瘾。我们希望能够在独立的Namespace中拿到一个shell。

只需要更改两行代码。父进程里面增加NEW_PID、NEW_IPC的标志位,子进程里调用execle执行bash,通过最后一个参数指定了环境变量PS1,这个表示提示符。
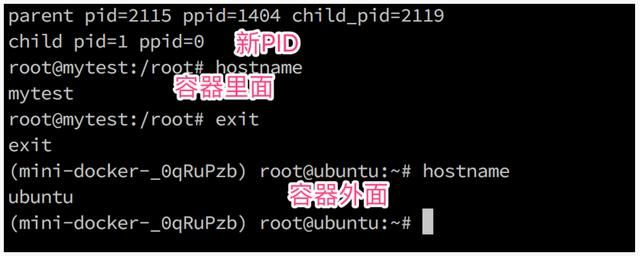
再次执行,我们发现shell已经变化了。通过hostname验证我们已经“在容器里面”了。键入exit,退出容器。
是不是已经无法掩盖自己内心的兴奋了。别急,还有更兴奋的,我们进行第三步——分离文件系统。
彻底分离
如果你在上一部的shell中输入一些top、ps、ls命令会发现几乎和“Host”环境中一摸一样。这是因为我们还没有做最重要的一部——分离文件系统。
Docker提供的有Ubuntu、CentOS的镜像,其实这些并不是严格意义上的镜像,它们准确的叫法应该是——根文件系统(root filesystem)。
容器是共享内核的,所以无论是Ubuntu、CentOS它们里面都使用Host的内核,如果你在Docker中通过uname查看会发现无论什么镜像它们的内核版本都和Host一摸一样。所以,不同“操作系统”Docker镜像其实就是不同的根文件系统。
很多人用BusyBox的rootfs做演示,作为一个风骚的男人怎么怎么可能如此俗套。所以我用CentOS 7作为演示。
真正的原因切换容器中的根目录,后续的代码执行会使用新的根文件系统,而后续的代码是依赖Python运行环境的。所以我们需要一个带Python的rootfs,CentOS 7刚好满足这个。如果我们用C或者Golang就不会有这个限制了。
你可以通过CentOS提供的Dockerfile找到相关的rootfs的下载,比如:https://github.com/CentOS/sig- ... ocker

把下载到的文件解压到/tmp目录下。

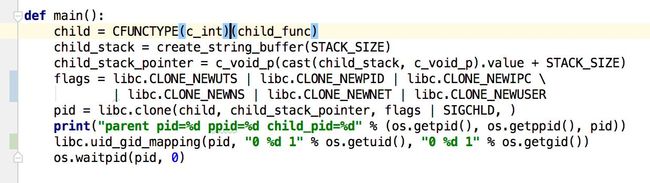
分离文件系统分为三个步骤,首先我们建立容器里面的/proc文件系统,很多Linux命令都是读取这个文件系统下的内容(比如top中显示的进程列表);其次我们要把现在的用户和容器里面的用户做映射,否则会提示权限不足;最后我们要通过pivot_root 函数把“切换”根文件系统。

不要忘记修改main方法,为标志位增加三个参数,映射用户。
再次执行。
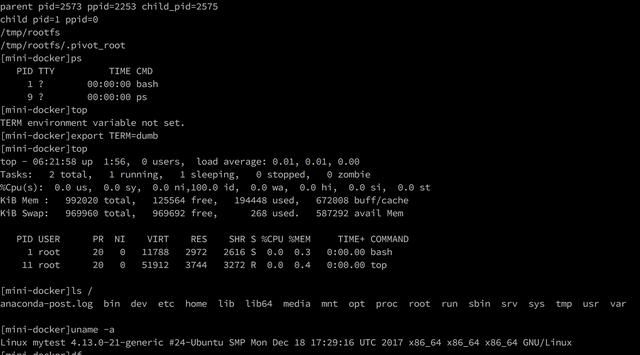
和CentOS 7一摸一样,你甚至可以用yum命令,当然由于我们现在还没有实现网络功能所以yum会告诉你无法访问网络。
再多执行几个添加文件、删除文件看看?你会发现无论做什么动作最终的数据都会被牢牢地固定在/tmp/rootfs下,也就是说——在容器里面我们是没有办法访问host的文件的。
完整代码:https://github.com/fireflyc/mini-docker。
推荐一个交流学习群:478030634 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多:
