【Python成长之路】从零学爬虫--给微信公众号阅读量作个弊:刷阅读量
【写在前面】
小燕同学:鹏哥,我在微信公众号上写的一些美妆博客,都没什么阅读量,老板要求我在这个月底至少让几篇博客阅读量达到10W+,你说我要不要每天自己去刷或者找水军呀?
鹏哥:博客刷阅读量?这不是公然作弊吗?
小燕同学:呜呜,要是这个月又让老板不满意,那就要扣我绩效奖金了。
鹏哥:好吧,我用10行代码帮你搞下吧。
【最终效果】
以刷“鹏哥贼优秀”公众号的博客为例:
【实现过程】
1、原理简述:爬虫刷阅读量本质其实是模拟用户点击网页查看内容的操作,因此只需要代码能访问相应的博客地址,就可以实现刷阅读量的目的。
2、最初跳的坑:request.get访问怎么不会增加阅读量?
一开始我是直接调用request.get()方法来尝试实现的,但是发现虽然我用get()方法获取到了网站内容,但是并没 有使对应的阅读量增加。后来查了一些资料,说是request.get()只是在获取URL时截获到网页响应,并没有真正动态加载JS。
3、出坑:用selenium解决
后来就采用大神们推崇的爬虫神器--Selenium,至于有多少牛逼,可以用下面这张网图来简单示意下。

![]()
4、接着跳坑:怎么用selenium实现访问:
本身selenium使用方法和request库差不多,就是 对html元素的查找方法有所改变,另外就是selenium更加智能和强大。我先用selenium来 尝试刷了下自己CSDN博客的阅读量,发现只需要2句代码就可以了!
driver = webdriver.Chrome("chromedriver.exe")
driver.get(url)
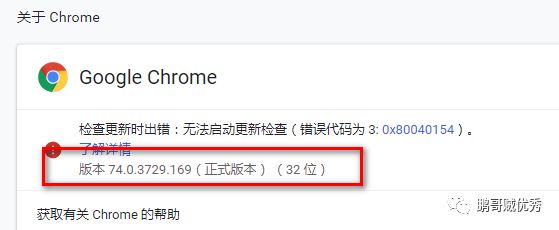
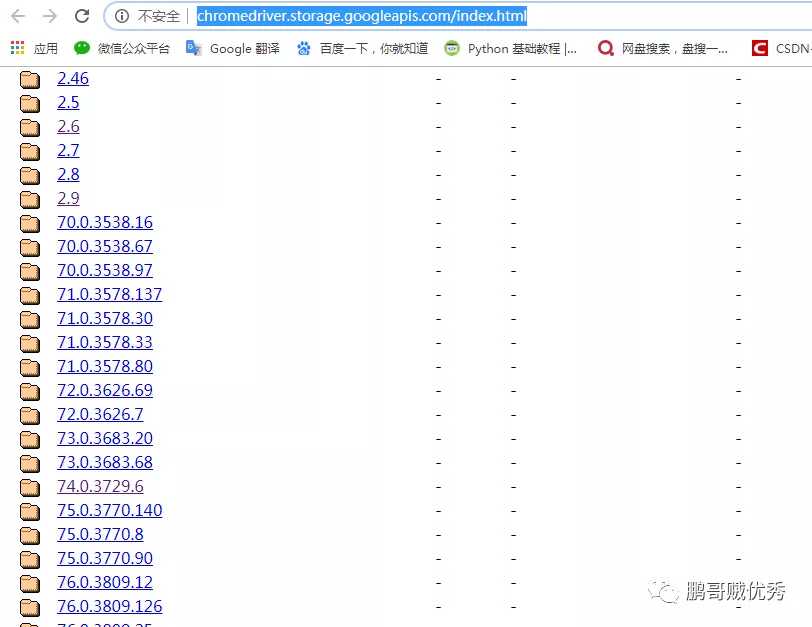
先从网上下载chromedriver.exe,是 谷歌浏览器的启动器。一开始我以为是 本地谷歌的可执行文件,后来发现 并不是,而且需要根据自己本地的chrome版本下载对应的chromedriver。chromedriver下载地址是:
http://chromedriver.storage.googleapis.com/index.html
本地的谷哥版本
下载对应的chromedriver版本
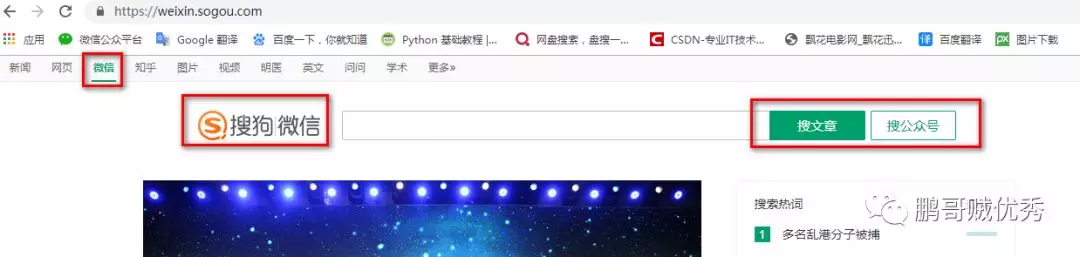
5、接着跳坑:那怎么在浏览器上访问微信公众号的文章呢?
一般在直接百度上搜索公众号文章是找不到的,需要用搜狗搜索网
站来实现。在搜狗网站上,有个“微信”选项,从这里进入就可以查找到公众号文章了。
6、再跳坑:为什么我文章对应的URL地址不可用呀?
一开始为 了偷懒,我是想把要刷的文章URL,复制到txt中的,但是发现F12 抓包得到的博客URL没用。
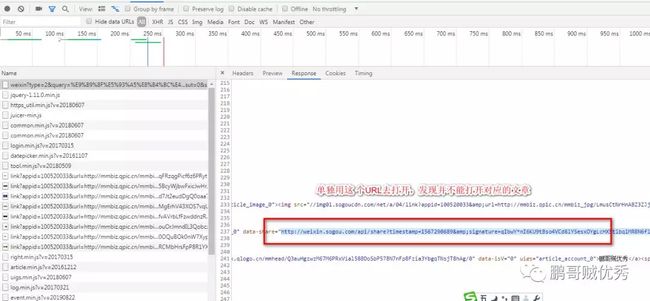
怎么办呢?
好,那我真正地放Selenium的“连续普通拳”!

7、出坑:用selenium获取到每一个博客标题对应的html元素,然后模拟用户点击操作。
find_element_by_xpath是万能的元素查找方法,当然也有很多其他查找方法,如:

下面主要参考其他大神整理好的find_element_by_xpath使用方法(URL地址在最下方):



8、成功前的最后一坑:能成功打开第一个公众号文章,但就是打不开第二个,程序报错说 找不到元素。
一开始我是用下面这句代码来查找博客标题元素的,但是第2篇开始一直报错。
driver.find_element_by_xpath('//h3[{}]/a'.format(i))
原先我以为是因为打开子窗口导致的,因此加了回到主窗口的代码 ,然后发现还是不行。最后只能再仔细看html格式,终于发现了里面的玄机!
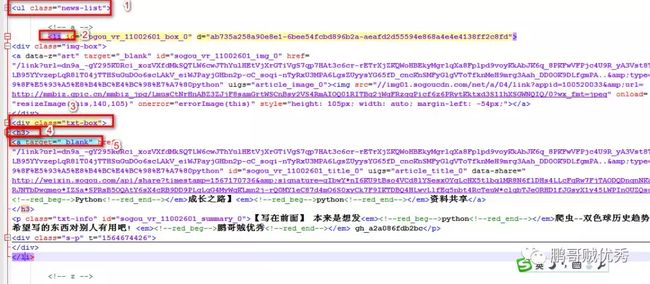
原来需要从每个h3/a元素的父元素开始往下一层层遍历,即从ul[@class="news-list"] ->li -> div[@class="txt-box"] -> h3 ->a。
另外,在程序最后要记得关闭浏览器。driver.close()是关闭的窗口,driver.quit()是停止chrome进程并关闭相关所有进程。
至此,一只小白,将刷博客阅读量实现过程中的所有的坑都跳完了!!
【示例代码】
# coding=utf-8
# @Auther : "鹏哥贼优秀"
# @Date : 2019/8/30
# @Software : PyCharm
from selenium import webdriver
import time
def RefreshReadingNum():
url = "https://weixin.sogou.com/weixin?type=2&query=%E9%B9%8F%E5%93%A5%E8%B4%BC%E4%BC%98%E7%A" \
"7%80python&ie=utf8&s_from=input&_sug_=n&_sug_type_=&w=01019900&sut=9342&sst0=156717011391" \
"9&lkt=7%2C1567170112675%2C1567170113806"
# 一共访问10W次
for j in range(100000):
# 实例化谷歌浏览器
driver = webdriver.Chrome("chromedriver.exe")
# 访问网站
driver.get(url)
# 设置搜索结果作为当前主窗口
mainwindow = driver.current_window_handle
# 搜索结果共有9篇文章
for i in range(1,10):
# 查找网页上的博客标题
btn = driver.find_element_by_xpath('//ul[@class="news-list"]/li[{}]/div[@class="txt-box"]/h3/a'.format(i))
driver.find_element_by_xpath('//h3[{}]/a'.format(i))
# 模拟用户点击博客标题,从而进入博客界面
btn.click()
# 回到主窗口
driver.switch_to.window(mainwindow)
time.sleep(5)
driver.close()
time.sleep(120)
driver.quit()
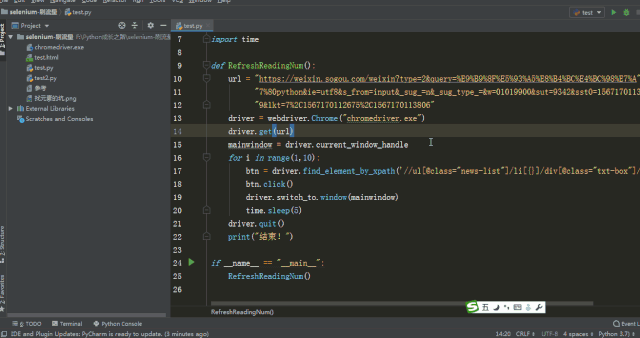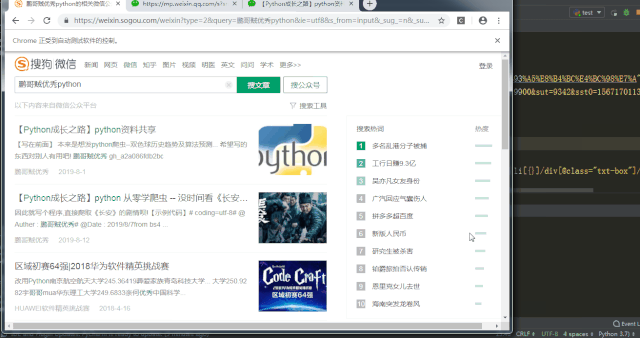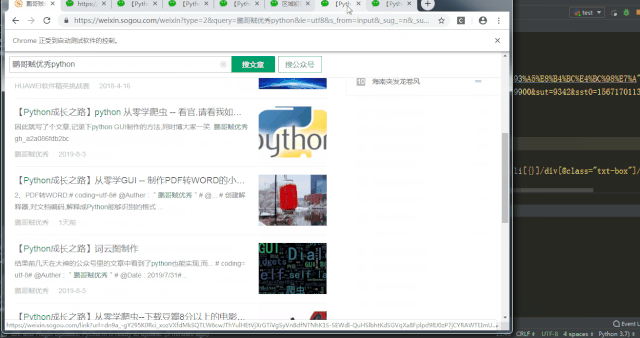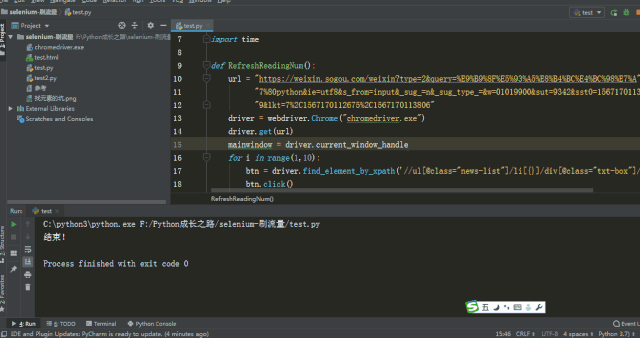
print("结束!")
if __name__ == "__main__":
RefreshReadingNum()
【写在最后】
鹏哥:小燕同学,怎么样?快夸夸我,嘻嘻!
小燕:鹏哥贼优秀!
鹏哥:你开心就好!
另外,补充说明下:
看似简单的几行代码,里面还是有很多值得琢磨的细节,比如有些网站在一定时间内访问,只会计算成一次阅读量,比如CSDN,所以我在访问结束加了120S;又比如如果有些网站有IP检测机制的话,要如何模拟IP。
【参考】
https://blog.csdn.net/u012941152/article/details/83011110