Kmean聚类分析
文档主旨:
基于对无标注数据的聚类分析的场景使用频繁,为重用代码与规范操作流程,故写此文档,记录下标准的操作过程,以期望达到再次使用时快速实现的目的。
第一步:构造数据;
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
#构造向明显向K个中心点聚合的数据集
#
import numpy as np
import random
print np.random.random()
def createSampleData():
with open( "data.txt",'w') as f:
k=0
for i in xrange(100):
udid='udid{0}'.format(i)
if i%14==0:
k = 100
elif i%11==0:
k=400
else:
k=1
for c in xrange(5):
event="event{0}".format(c)
cnt = np.random.random()+k+c
print udid,event,cnt
line="{0}\t{1}\t{2}".format(udid,event,cnt)
f.write(line+'\n')
#这个数据集合,应该有明显的三个中心点,特征维度为5个
createSampleData()数据结果形如:
udid0 event0 100.698776793
udid0 event1 101.449693717
udid0 event2 102.061550813
udid0 event3 103.247865424
udid0 event4 104.725784024
udid1 event0 1.78156461729
udid1 event1 2.57909059891
udid1 event2 3.09038576805
udid1 event3 4.97415010982
udid1 event4 5.85007575861
udid2 event0 1.053742126
udid2 event1 2.83877427547
udid2 event2 3.65598654876
udid2 event3 4.4454847136
udid2 event4 5.62992477574
udid3 event0 1.94631534413
特征维度:
event0
event1
event2
event3
event4
第二步:构造特征稀疏矩阵
实验代码结构如下:
入口文件如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#pyspark driver_main.py --packages com.databricks:spark-csv_2.10:1.5.0
print "=============================="
print "=======CHENGSHOUMENG ENTER===="
print "=============================="
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages com.databricks:spark-csv_2.10:1.5.0 pyspark-shell'
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
conf = SparkConf()
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
sc.setLogLevel(logLevel='WARN')
sc.addPyFile('feature.py')
sc.addPyFile('featuredata.py')
sc.addPyFile('createdata.py')
sc.addPyFile('traindata.py')
sc.addPyFile('common.py')
sc.addPyFile('hdfs_helper.py')
sc.addPyFile('param.py')
sc.addPyFile('predictdata.py')
sc.addFile('spark-csv_2.10-1.5.0.jar')
sc.addFile('commons-csv-1.4.jar')
# rdd=sc.textFile("")
# rdd.getNumPartitions()
# rdd.get
from common import *
set_python_env()
print get_worker_info()
import createdata
import traindata
import predictdata
if __name__ == '__main__':
createdata.main(sc,sqlContext)
#traindata.main(sc,sqlContext)
#predictdata.main(sc,sqlContext)输出的稀疏矩阵如下:
(u’udid32’, [(0, 1.75619569497), (1, 2.80490356785), (2, 3.18822609037), (3, 4.13118345304), (4, 5.60090624605)])
(u’udid37’, [(0, 1.40088552033), (1, 2.19790459313), (2, 3.23904429736), (3, 4.72201872689), (4, 5.49403759479)])
(u’udid34’, [(0, 1.84492889268), (1, 2.22331591647), (2, 3.48573590805), (3, 4.17018742234), (4, 5.76907135692)])
(u’udid39’, [(0, 1.96684764034), (1, 2.16238504415), (2, 3.87203511791), (3, 4.51722070961), (4, 5.53510816611)])
(u’udid98’, [(0, 100.2201528), (1, 101.871590213), (2, 102.542169699), (3, 103.654456239), (4, 104.877682044)])
(u’udid31’, [(0, 1.85737686287), (1, 2.09337189725), (2, 3.97334995643), (3, 4.46003192616), (4, 5.83826372458)])
(u’udid36’, [(0, 1.56356444955), (1, 2.78351312188), (2, 3.39557804173), (3, 4.0251704133), (4, 5.13514900333)])
(u’udid38’, [(0, 1.1382088621), (1, 2.02576521757), (2, 3.33589897592), (3, 4.04993951172), (4, 5.61447058964)])
(u’udid69’, [(0, 1.27989660423), (1, 2.90355838167), (2, 3.43408619604), (3, 4.08104742326), (4, 5.04930500541)])
(u’udid48’, [(0, 1.19583765772), (1, 2.45170396996), (2, 3.12072583188), (3, 4.77598780962), (4, 5.52395643554)])
(u’udid1’, [(0, 1.78156461729), (1, 2.57909059891), (2, 3.09038576805), (3, 4.97415010982), (4, 5.85007575861)])
(u’udid2’, [(0, 1.053742126), (1, 2.83877427547), (2, 3.65598654876), (3, 4.4454847136), (4, 5.62992477574)])
(u’udid7’, [(0, 1.82031081909), (1, 2.04826366353), (2, 3.26271726806), (3, 4.12617925182), (4, 5.04376358246)])
(u’udid8’, [(0, 1.72294995234), (1, 2.77056380506), (2, 3.34888752477), (3, 4.69625300762), (4, 5.21943957825)])
(u’udid95’, [(0, 1.74051715486), (1, 2.20828154549), (2, 3.76597984104), (3, 4.68499816997), (4, 5.5424543626)])
(u’udid96’, [(0, 1.28737740729), (1, 2.6944782683), (2, 3.56428729609), (3, 4.49175464429), (4, 5.56717896827)])
(u’udid80’, [(0, 1.3285248878), (1, 2.63762517115), (2, 3.30295488139), (3, 4.11078905224), (4, 5.34775083597)])
(u’udid87’, [(0, 1.68540849303), (1, 2.85823555965), (2, 3.60036356842), (3, 4.22307598901), (4, 5.95144608133)])
(u’udid89’, [(0, 1.54126163133), (1, 2.99860252637), (2, 3.48678225556), (3, 4.2911522278), (4, 5.57344608925)])
(u’udid25’, [(0, 1.66980723512), (1, 2.70176492461), (2, 3.42662470593), (3, 4.00744736814), (4, 5.84365294819)])
(u’udid20’, [(0, 1.89432847332), (1, 2.95026387974), (2, 3.78965630109), (3, 4.24153197756), (4, 5.96310769215)])
(u’udid23’, [(0, 1.48593547427), (1, 2.23382862385), (2, 3.25089376871), (3, 4.44241421989), (4, 5.49824901154)])
(u’udid29’, [(0, 1.1188571191), (1, 2.42601923712), (2, 3.8035673509), (3, 4.49056656217), (4, 5.51978073419)])
(u’udid46’, [(0, 1.83089408248), (1, 2.85163845723), (2, 3.71581036703), (3, 4.78101929669), (4, 5.20255762853)])
(u’udid61’, [(0, 1.72463423782), (1, 2.55748549778), (2, 3.60007801544), (3, 4.8995339846), (4, 5.17586090086)])
(u’udid45’, [(0, 1.72874985589), (1, 2.02524864152), (2, 3.85018999582), (3, 4.67549462089), (4, 5.22452607854)])
(u’udid64’, [(0, 1.3037602855), (1, 2.13359880425), (2, 3.8620502933), (3, 4.25665984725), (4, 5.80332227234)])
(u’udid40’, [(0, 1.19817691967), (1, 2.07059533118), (2, 3.88095137508), (3, 4.38884387848), (4, 5.9954235435)])
(u’udid67’, [(0, 1.57067309796), (1, 2.44804554753), (2, 3.4651315085), (3, 4.87730486975), (4, 5.62827255585)])
(u’udid49’, [(0, 1.72956862621), (1, 2.09603766), (2, 3.8985397459), (3, 4.28986015564), (4, 5.75265571287)])
(u’udid0’, [(3, 103.247865424), (4, 104.725784024), (0, 100.698776793), (1, 101.449693717), (2, 102.061550813)])
(u’udid5’, [(0, 1.08290248853), (1, 2.16671957751), (2, 3.22642185572), (3, 4.894007313), (4, 5.9327838108)])
第三步:计算分散强度值进行聚类分析,选择合适的K值
def getPredictStrength(featureMat):
numUser = featureMat.count()
assert numUser > 0
logfile.w("getPredictStrength() begin;numUser:{0} {1}->{2}".format(numUser, INPUT_PARAM.CLUSTER_MIN,INPUT_PARAM.CLUSTER_MAX))
psfields = ['k', 'r','a'] + ['c{0}'.format(i) for i in xrange(INPUT_PARAM.CLUSTER_MAX)]
psfile = HdfsApi(sc, INPUT_PARAM.strength_file, fields=psfields)
begin_index = 1
for k in xrange(INPUT_PARAM.CLUSTER_MIN, INPUT_PARAM.CLUSTER_MAX + 1):
first_lable_table = convertLableRdd(featureMat, k, 0).collect()
for r in xrange(begin_index, begin_index + INPUT_PARAM.RUNS, 1):
second_lable_table = convertLableRdd(featureMat, k, r).collect()
mat = np.zeros((k, k), dtype=float)
for i in xrange(numUser):
c1 = first_lable_table[i]
c2 = second_lable_table[i]
mat[c1][c2] += 1.0
ps_list, ps_detaillist = [], []
for i in xrange(k):
t1, t2 = max(mat[i]), sum(mat[i])
ps = (t1 + 0.01) / (t2 + 0.01)
ps_list.append(ps)
logfile.w(
'getPredictStrength() >k={0} r={1} i={2} ps:{3} t1:{4} t2:{5}'.format(k, r, i, ps, t1, t2))
psfile.w(wrapperOutline(INPUT_PARAM.CLUSTER_MAX, k, r, ps_list))
logfile.w("getPredictStrength() end")输出结果是:一个记录K取不同值时,每个族被重新划分不分散的程度。假设一个数据集应该分为K类,那么应该有这样的预期,重复划分N次,被划分到一个群里的个体,依旧被划分到了一个群里。
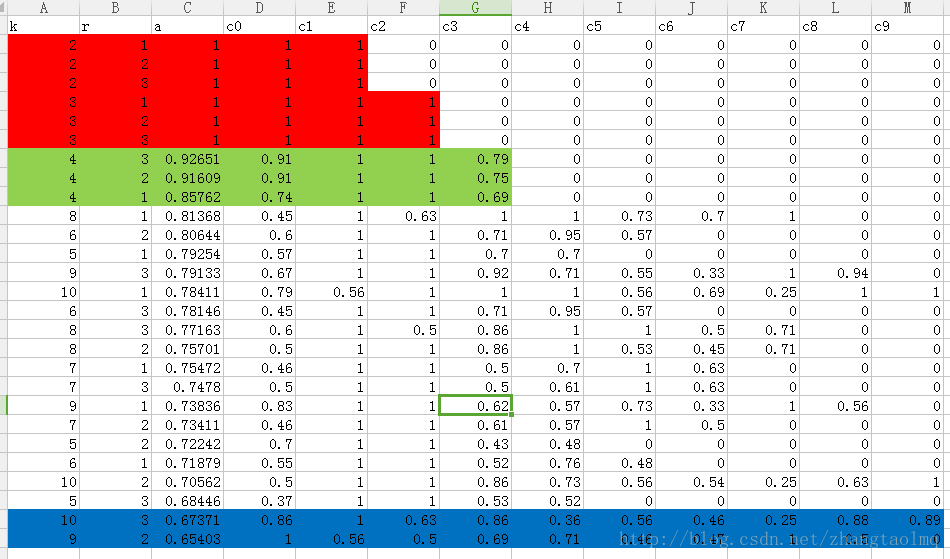
分析结论:K=2,3,4比较稳定,K=9,10比较发散;
第四步:观察类均值,进行验证
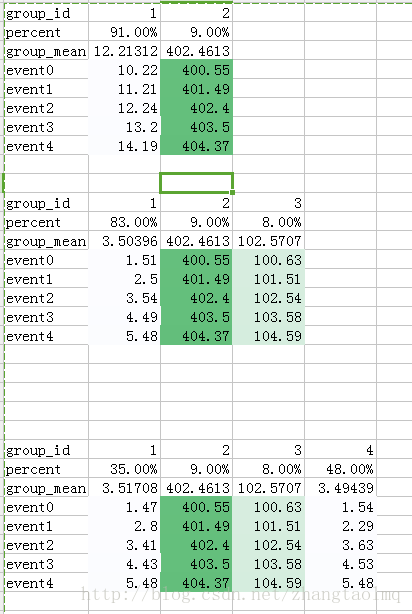
通过观察,K=3符合预期;
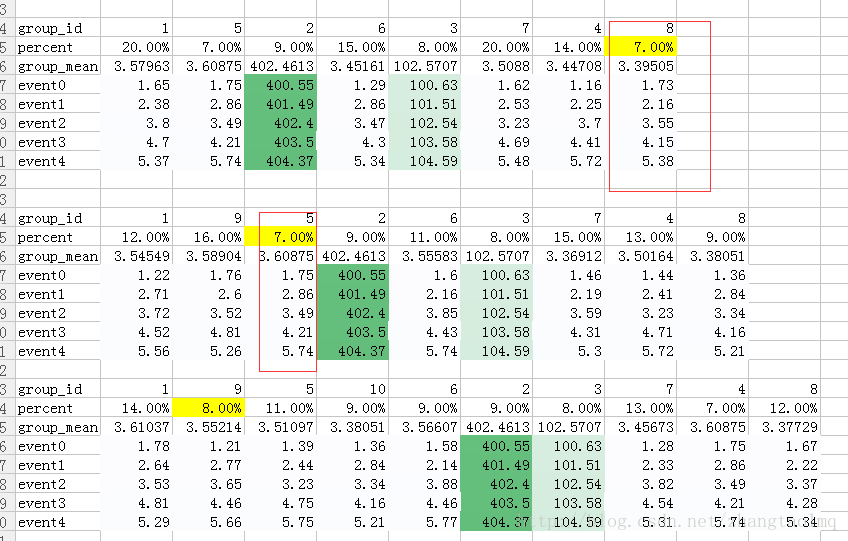
第五部:排除小群,可能异常数据的集合
关于代码:
如需代码,请留邮箱索取。