【paper-note6】去摩尔纹相关研究现状
摘要
这篇文章写一个去摩尔纹相关研究的综述,理清自己前段时间看的论文。
上一篇paper note提出了摄屏图像去摩尔纹这个问题后,我去找了一下这个领域至今为止的相关工作,找到了大概8篇论文,看了其中4篇,做个综述,分别是:
- 《Moiré Photo Restoration Using Multiresolution Convolutional Neural Networks》Yujing Sun
TIP2018 - 《MOIR ´E PATTERN REMOVAL WITH MULTI-SCALE FEATURE ENHANCING NETWORK》Tianyu Gao
ICMEW2019 - 《Multi-scale Dynamic Feature Encoding Network for Image Demoir´eing》Xi Cheng
ICCVW2019 - 《Mop Moire Patterns Using MopNet》Bin He
ICCV2019
以下用作者的姓代替论文:Sun、Gao、Cheng、He。
方法
Sun TIP2018
主要工作
Sun的工作已经在上一篇论文笔记中详细阐述,这里就简要介绍一下:
-
首先提出摄屏图像去摩尔纹这个问题,提出摄屏图像的摩尔纹的特点是多频率的(a moir´e pattern spans over a wide range of frequencies)。

-
针对摩尔纹多频率的特性,提出一个多分辨率网络,对原始feature map做下采样(用了S2的conv),在各自的分辨率上顺序卷积,然后利用反卷积(转置卷积)进行上采样,最后紧跟一个C3的conv3x3输出RGB图像,把每一个分支的输出简单相加,得到输出。loss用到是L2距离。


-
创造了一个大规模摩尔纹数据集,用的是ImageNet ISVRC 2012 dataset,放在三个屏幕上,用三款手机进行拍摄,每个组合得到15000对图像,共15000*9 = 135000对图像。这成为后续工作的公开数据集。
结果
论文拿了7+1种方法进行对比,多出来的1种是作者把上述网络最后的sum变成了concate,输出C32的feature map,紧跟两个C32的Conv3*3,结果如下。

虽然V_Concate和U-Net有时候会有更高的PSNR,但是其视觉效果并不如Our method。

Future Work
作者还提出了该方法的limit和future work。
- 首先,有一些failure example,没有说原因,但是我猜是因为网络不能处理低频摩尔纹和大面积色块导致的。

- 其次,作者说创建数据集的时候可能对齐没做好,或者是拍照时产生移动模糊,或者是摩尔纹自身就破坏了高频信息等等。
- 再者,可以对摩尔纹进行分类,在处理的时候加入类别信息可能会提升效果。这点应该能解决问题1。
- 最后,需要一个更好的描述摩尔纹的方式(除了PSNR和SSIM),perceptive loss&GAN loss?。
Gao ICMEW2019
这是大连理工大学一个组在ICME Worshop2019上的一个工作,其数据集采用的是上面提出的ImageNet Screen Shot Dataset(ISSD),借鉴了Sun的思想,提出一个多尺度网络,类似于U-net的encoder-decoder结构,并在跳跃连接的时候应用特征增强分支(FEB),将低分辨率特征融合到高分辨率特征中。loss也是L2 loss。
主要工作
-
针对摩尔纹的多频率特性,提出一个多尺度特征增强网络(MSFE),基于U-net,结构如下。input layer和output layer都是用了Conv5*5。

其中,Residual Block就是用了何凯明在Resnet中提出的BasicBlock( B 1 B B_1B B1B):

把左边的下采样当作encoder,用Maxpool,右边的上采样当作decoder,用Deconv,sacle factor是2。在对应的层之间采用concatenate加入跳跃连接:
y i = f [ u p ( y i + 1 ) , x i ] y_i = f[up(y_{i+1}), x_i] yi=f[up(yi+1),xi]

-
特征增强分支(FEB)

FEB加在每一个跳跃连接中间,将低分辨率的特征融合进高分辨率的特征,融合的操作原文中叫做semantic embedding operation(X),这是Zhang[1]提出来的,就是element-wise的乘法。

缺点很明显,只把低分辨率的特征嵌入到高分辨率特征中,没有把高分辨率信息融合到低分辨率特征。
结果
论文拿了Sun的方法、U-net和U-net+FEB以及自己的MSFE(baseline+feature enhancing branch+multi-scale)做比较,数据集还是ISSD,结果如下

不过为什么Sun自己说有26.77的PSNR,到了他这里就只有21.24了,MSFE的结果也是一般般。
Future Work
这个方法的缺点很明显,层数少;只考虑从下往上融合,没考虑从上往下融合;用了U-net,这种很thin的结构,先下采样到低分辨率再上采样到高分辨率,如果用resnet这种很深的结构效果应该会好。
Cheng ICCVW2019
本文是Aim 2019 Demoireing Challenge比赛Fidelity组第二名,Perceptual组第三名,数据集是AIM官方提供的,所用的模型叫做多尺度动态特征编码网络,主要包含两方面:1. Multi-scale 2. Dynamic Feature Encoding。中间用的激活函数是PReLU,loss是Charbonnier loss。

数据集也比较简单,没有Imagenet那么复杂。这个数据集来源是AIM 2019 demoiring challenge[7]的数据集,据说也是合成的。

主要工作
-
Multi-Scale
多尺度和上面的论文一样,分了四个Branch,每个branch下采样1/2,下采样操作用S2的conv,在branch的最后用Subpixel Conv上采样。
随后每个分支紧跟一个Scale module操作,可以理解为每个branch分配一个权重,让网络自动去学习其权重大小,具体实现形式可以是每个feature map* factor,最后把每个分支的输出相加,得到最后的output。
-
Dynamic Feature Encoding
本文最重要的工作就是提出了Channel attention Dynamic feature encoding Residual block(CDR)和Dynamic feature encoding(DFE),可以用下图解释。

-
CDR
CDR是上半部分,除了正常残差块的Conv层,还加入了一个CA层(Channle Attention),CA操作分为squeeze和excitation两部分,squeeze即求每个channle的均值,得到一个1*1*C的特征:

excitation是一个bottleneck:

原文说 W u W_u Wu和 W d W_d Wd是两个conv1*1, C1/16,但是这样就不是bottleneck了,所以我猜 W u W_u Wu是(C, 1/16C), W d W_d Wd是(1/16C, C)。
除了Channel级别的attention,还在全局残差之前加入了一个Non-local层(NL),region-level的non-local[2]操作旨在探索当前分辨率的自相似性。
-
DFE
摩尔纹模式是动态变化的,在一幅图像的不同地方有不同的尺度和角度,针对这种特点,收到任意图像风格迁移[3, 4]的启发,采用了一个bypass结构,并用AdaIN(adaptive instance normalizeation)连接。
如上图下半部分,先计算 x e n c x^{enc} xenc(conv后)的均值和方差:

然后把均值和方差传输主干网络的AdaIN中,计算 x i + 1 x_{i+1} xi+1:

其中 μ i \mu_i μi和 σ i 2 \sigma_i^2 σi2是指上半部分主干网络经过残差块的特征均值和方差,以此来动态归一化。
-
Loss function
作者提出,直接用MSE会造成过度平滑和模糊,因此采用Charbonnier loss,只是多了一个charbonnier penalty ϵ \epsilon ϵ,设为0.001。

结果
论文找了三个方法做对比,分辨是Sun,Gao的MSFE和用于降噪的DnCNN,结果如下。

Future Work
优点:
- 这篇论文到处用Attention结构,包含了channel级别的Attention(CDR)和region级别的Attention(Non-local block)。
- DFE的思想引入的bypass结构和AdaIN块连接,能够进行动态特征编码。
问题也是很明显的:
- 虽然用了多尺度网络,但是各个分辨率之间没有进行信息交互(Feature Enhance/Interaction)。
- 高分辨率的特征的卷积层少,低分辨率的卷积层多。理论上应该反过来,越高的分辨率应该有需要越多的卷积层,因为高分辨率能够学到的东西多,低分辨率能够学到的东西少。
He ICCV2019
本文提出了一个MopNet(Moir´e pattern Removal Neural Network),包含了三个部分:
- 多尺度网络特征整合,解决摩尔纹的多频率问题。
- RGB Channel级别的边缘检测,解决色彩通道之间的不平衡强度(彩色摩尔纹)。
- 摩尔纹类别分类器,在网络中加入类别特征。

主要工作
-
多尺度网络

其多尺度网络参考了DenseNet的结构,中间采用了bottelneck block(之后有空可以细看DenseNet),DenseNet的特点就是较少的channel深度,每一层都把之前所有的feature map拼接起来作为输入,能够提高feature map的利用率,减少网络训练时中间变量的存储量。
在每个尺度的输出上应用Nonlinear Upsampling上采样至原图像相同大小,再拼接,随后是一个Squeeze & Excitation,作用和上一篇论文一样,做了一个Channel级别的Attention,能够选择性的增强某个尺度的输出特征。公式如下:

-
RGB Channel级别的边缘检测器

下面两个模块都是一些tricks,给主干网络增加信息,该模块针对每个RGB Channel进行边缘预测,输入为用sobel算子检测并增强过的摩尔纹图像 I s I_s Is,假设 E s r , E s g , E s b E_{sr}, E_{sg}, E_{sb} Esr,Esg,Esb是 I s I_s Is的sobel算子检测出来的edge信息,用三个E增强 I s I_s Is,逐Channel相加(WxHx3),输入到edge predictor中,输出干净图像的Edge,训练的时候groudtruth可以用clear图像的sobel edge。公式如下:

网络结构文中没有说,目测类似于U-net,或者FCN这种形式,在每一层的的feature map上应用non-local block,探索其自相似性,以此帮助弱边缘获得更强的相应(通过对强边缘加权)。
当网络得到原始图像的边缘时,送入特征提取层块得到 F e F_e Fe, F e F_e Fe与主干网络的输入特征拼接,目的是保边并防止过度平滑。
-
摩尔纹类别分类器
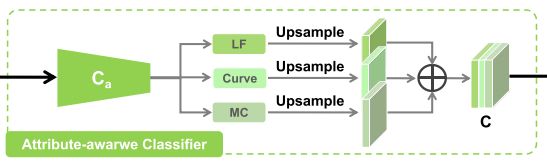
对摩尔纹进行分类的思想在Sun那篇文章就提出来了,因为缺乏统一标准和工程量大一直没有人做,本文算是一个很好的尝试。
本文根据摩尔纹的频率,形状,颜色进行分类,分别为:高频和低频;直线和曲线;单色和多色。可以看到都是二分类,故每张图片就会有三个属性。

这三个属性都是标量(0or1?),经过上采样后拼接起得到 C C C, C C C再和主干网络的特征 F m F_m Fm拼接起来,输入到 g r g_r gr生成最后的output。

g r g_r gr 包含了一个SE block和几个前馈的卷积层。
这里可以看到:
- 网络的特征融合操作都是Concat,这也符合了DenseNet的思想。
- SE block可以做为网络Channel级别自动加权的工具,比线性相加要好。
-
整体结构
整个网络的目标函数由如下三个loss组成:

其中 L E , e L_{E,e} LE,e和 L E , o L_{E,o} LE,o分别代表了预测edge和真实edge的L2距离,output和groudtruth图片的L2距离, α \alpha α=0.1, L F L_F LF代表了feature-based loss,从预训练中的VGG-16的relu1_2层中提取得到的浅层特征。
首先单独训练了edge prediction 网络50个epochs,训练分类网络20个epochs,然后固定分类网络,端到端的训练整个网络150个epochs。
数据集也是Sun的那个数据集,摩尔纹分类网络的数据集是从135000对图片中采样12000对图片,人工打标,用预训练的VGG网络fine-tune达到分类器的目的。
结果
拿了DnCNN,VDSR,U-Net,Sun的DMCNN定量比较,在定性比较的时候增加了Yang[5]的传统方法,和photoshop的descreen[6]方法做对比,结果如下:

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hdXSwAUi-1573889744545)(https://raw.githubusercontent.com/Badstu/pic_set/master/img/20191116151923.png)]
作者有点偷懒,指标上面直接用了Sun文章里面的数据,不过PSNR还是比Sun高,有说服力。剩下的消融研究是增加工作量的。
Future Work
除了把方法泛化到纹理图像上这种正常操作之外,作者还探索了高分辨率摩尔纹图像的去摩尔纹,受限于显存,高分辨率图像无法在显卡中完整的计算,本文的方法是先下采样HR-input为LR-input,经过去摩尔纹后得到LR-result,再送入预训练好的超分辨率网络,得到HR-input,结果也不错,之后可以考虑把超分和去摩尔纹结合起来。
limitation也是有的,当碰到砂石地面等不规则不稳定的背景时,网络也会出错,主要是由于这种图案的边缘特征很难确定,有待改进。
参考文献
[1] Zhenli Zhang, Xiangyu Zhang, Chao Peng, Xiangyang Xue, and Jian Sun, “Exfuse: Enhancing feature fusion for semantic segmentation,” in Computer Vision - ECCV 2018 - 15th European Conference, Munich,Germany, September 8-14, 2018, Proceedings, Part X, 2018, pp. 273–288.
[2] Tao Dai, Jianrui Cai, Yongbing Zhang, Shu-Tao Xia, and Lei Zhang. Second-order attention network for single image super-resolution. In Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition, pages 11065– 11074, 2019.
[3] Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceed- ings of the IEEE International Conference on Computer Vision, pages 1501–1510, 2017.
[4] Hao Wang, Xiaodan Liang, Hao Zhang, Dit-Yan Yeung, and Eric P Xing. Zm-net: Real-time zero-shot image manipula- tion network. arXiv preprint arXiv:1703.07255, 2017
[5] Jingyu Yang, Xue Zhang, Changrui Cai, and Kun Li. Demoir´eing for screen-shot images with multi-channel layer decomposition. In IEEE Visual Communications and Image Processing, pages 1–4. IEEE, 2017.
[6] http://www.descreen.net/eng/soft/descreen/descreen.htm
[7] YUAN, Shanxin, et al. AIM 2019 Challenge on Image Demoireing: Dataset and Study. arXiv preprint arXiv:1911.02498, 2019.