Python3网络爬虫基本操作(一)
Python3网络爬虫基本操作(一)
- 一.前言
- 二.编写一个简单的爬虫
- 1.获取网页信息
- 2.简单实例
- (1).requests安装
- (2).requests库的基本用法
- (3).简单实例
- (4).提取需要的数据
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
Python爬虫入门简单,但是深入学习后,你会发现坑越来越多,需要反复练习才能孰能生巧。
二.编写一个简单的爬虫
1.获取网页信息
在浏览器的地址栏输入URL地址,在网页处右键单击,找到检查。(不同浏览器的叫法不同,Chrome浏览器叫做检查,Firefox浏览器叫做查看元素,但是功能都是相同的)。或者在当前页面按下F12键也可执行该操作。
这样我们就能看到这个页面的HTML代码
2.简单实例
(1).requests安装
在cmd中,使用如下指令安装requests
pip install requests
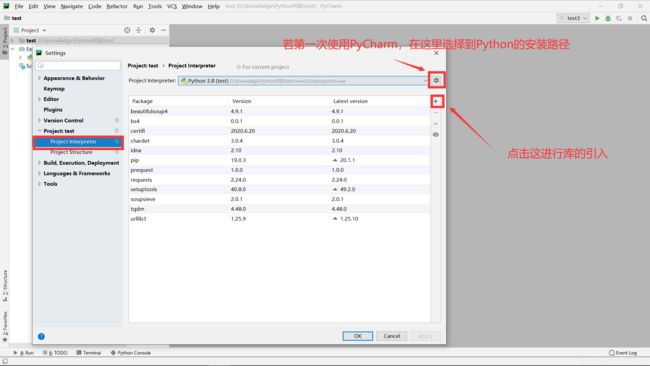
在PyCharm中可在setting中进行requests库的引入

(2).requests库的基本用法
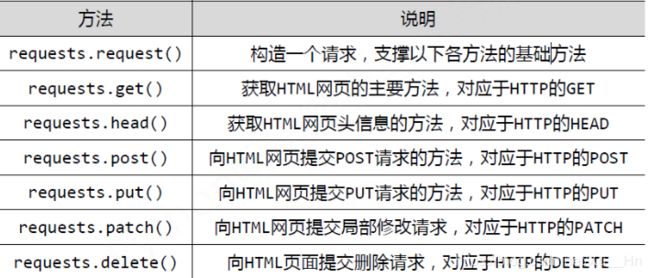
官方文档地址:https://requests.readthedocs.io/zh_CN/latest/
(3).简单实例
首先,让我们先用requests.get()方法,获取网页信息。看一个例子(以https://movie.douban.com/chart为例)来深入理解。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print(req.text)
上述代码获取了豆瓣网的HTML代码。首先Import requests引入库,使用requests.get(link, headers= headers)获取网页。需注意:
(1)用requests的headers伪装成浏览器访问。
(2)req是requests的response回复对象,我们可以从response中获取我们想要的信息。req.text是获取的网页的HTML代码
运行上述代码得到结果如图所示:
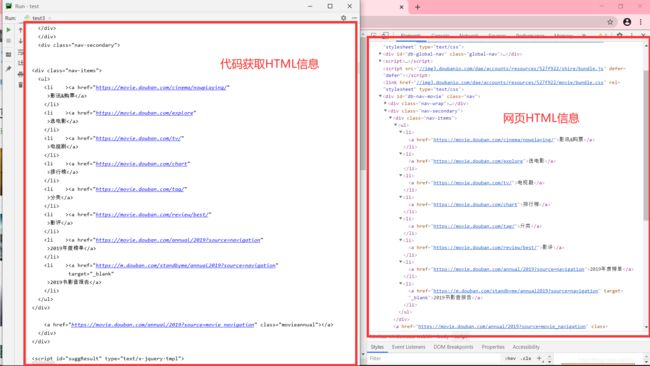
左侧是我们程序获得的结果,右侧是我们在https://movie.douban.com/chart网站审查元素获得的信息。我们可以看到,我们已经顺利获得了该网页的HTML信息。
(4).提取需要的数据
在获取整个页面的HTML代码后,我们需要从整个页面中提取我们想要的数据。
这里用到BeautifulSoup这个库来对爬下来的网页进行解析。
对初学者来说,使用BeautifulSoup从网页中提取需要的数据更加简单易用。
首先需要导入这个库:
在cmd中:
pip install beautifulsoup4
在PyCharm中:
BeautifulSoup官方文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
用刚才爬取的数据举一个例子:
我们想要获取整改网站的标题
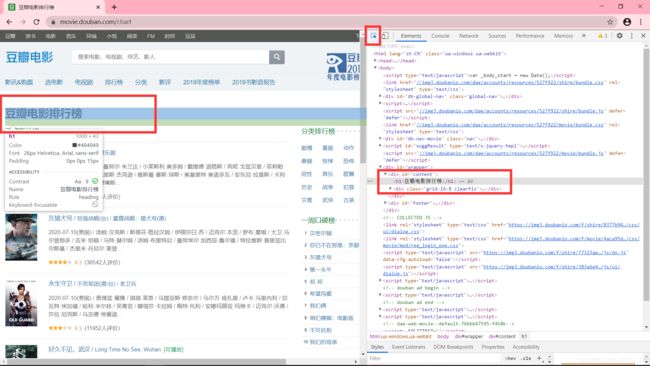
可以先打开浏览器的‘检查’页面,单机左上角的鼠标键按钮,然后在页面上单机想要的数据,下面的Elements会出现相应的code所在的地方,就定位到想要的元素了
import requests
from bs4 import BeautifulSoup
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
soup = BeautifulSoup(req.text, 'html.parser')
info = soup.find('div', id="content").h1.text.strip()
print(info)
运行结果:
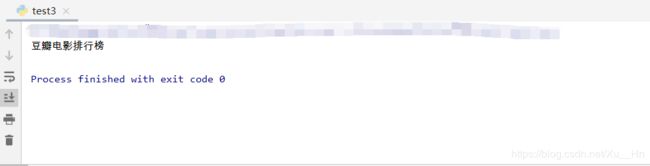
这样我们就获取到我们想要的数据了。
这就是一个最简单的爬虫实例。