在 PostgreSQL 上的基于触发器的将时序表分区的方案和模板
1. 前言
1.1 概述
当关系型数据库中一些表中数据量过于庞大时,我们就需要对它进行分区,以提高查询的性能。
在postgresql 9.6及其之前, 它没有提供原生的表分区方法,因此我们采用在数据库中通过触发器来分区的方法。而从postgresql 10 开始,数据库提供了原生的分区方法。
2. 设计方案
2.1 设计思想
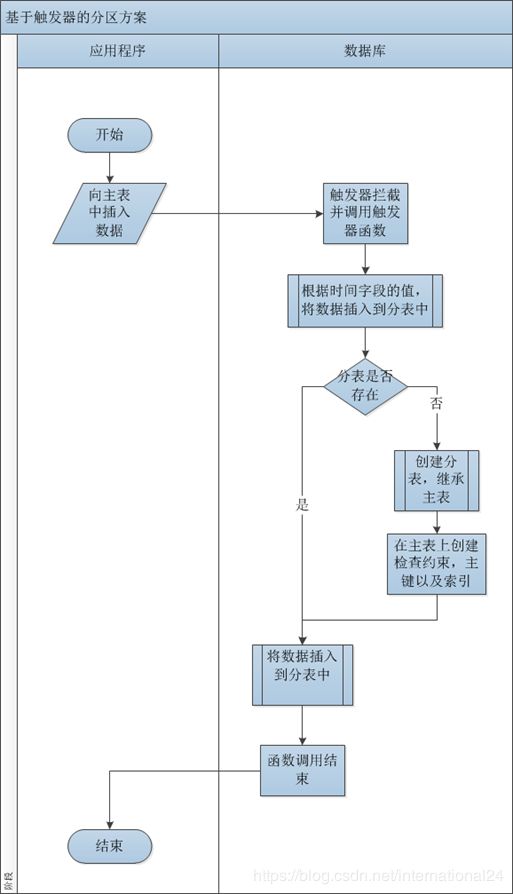
在基于触发器的分区方法中,我们需要实现下面两个目标:
- 程序向主表中插入数据时,数据库拦截并将数据插入到对应的分表中。
- 在进行数据库查询,删除,更新操作时,数据库可以定位到对应分表。
第一个目标是通过创建一个触发器函数以及调用该函数的触发器实现的。触发器的作用是拦截插入操作并调用触发器函数,而函数的作用,则是将数据插入到对应的分表中,并保证在分表不存在时创建它。
第二个目标是通过创建继承(inherit)主表的子表,并在子表上建立限定时间字段的取值范围的检查约束来实现的。当我们在子表的时间字段上建立约束后,数据库会根据查询条件中这个时间字段的取值,自动定位到相应的分表中。建立检查约束的工作通过上面的触发器函数来实现。
我们的方案的处理数据插入的流程如下图所示:
2.2 为空表创建分区
这种方案的适用的条件是,表在触发器函数和触发器创建前是空的。
2.2.1 案例
目前在ISC平台的数据库中,这些表大多数是按月份分区的。下面一个完整的案例,这里,表的名称是tb_face_stranger,分区的字段是事件事件event_time:
create or replace function func_tri_tb_face_stranger() returns trigger as
$$
declare my_tbname varchar(64);
declare my_start_time varchar(64);
declare my_end_time varchar(64);
declare sql_str text;
begin
my_tbname = TG_TABLE_NAME || '_' || to_char(NEW.event_time,'YYYYMM');
sql_str = 'INSERT INTO '|| my_tbname ||' SELECT $1.* ';
EXECUTE sql_str USING NEW;
return null;
exception when undefined_table then
begin
my_start_time = to_char(NEW.event_time,'YYYY-MM')||'-01 00:00:00';
my_end_time = (my_start_time::timestamp(0) + interval '1 month')::text;
execute 'create table ' ||my_tbname || '(constraint ck_' || my_tbname || ' check (event_time >= ' || '''' ||my_start_time || '''' || ' and event_time < '||''''|| my_end_time || '''' || ')) INHERITS ('|| TG_TABLE_NAME || ')';
execute 'alter table ' || my_tbname || ' add constraint pk_' || my_tbname || ' primary key (stranger_id)';
execute 'create index idx_'||my_tbname ||'_event_time on ' || my_tbname || ' (event_time)';
execute 'create index idx_'||my_tbname ||'_stranger_code on ' || my_tbname || ' (stranger_code)';
EXECUTE sql_str USING NEW;
return null;
exception when others then
execute sql_str using NEW;
return null;
end;
end;
$$ language plpgsql;
create trigger tri_tb_face_stranger BEFORE insert on tb_face_stranger for each row EXECUTE PROCEDURE func_tri_tb_face_stranger();
通过上面的代码创建了触发器函数和触发器之后,我们向主表tb_face_stranger中插入正确的数据时,数据库就能将数据拦截并插入到对应月份的分表中,若分表不存在则创建它。例如,我们插入一条数据,它的event_time = ‘2019-04-01 08:00:00’ ,它所在的分区表就是tb_face_stranger_201904。
2.2.2 代码复用方法
如果某个表需要按月份分区,那么按照这个模板,我们可以很快地完成触发器和触发器函数的程序代码。如何快速地完成它呢?其实,你只需要关注表的名称,表示时间的字段,表示主键的字段,以及需要建立索引的字段,就可以轻松的通过文本替换来完成代码。
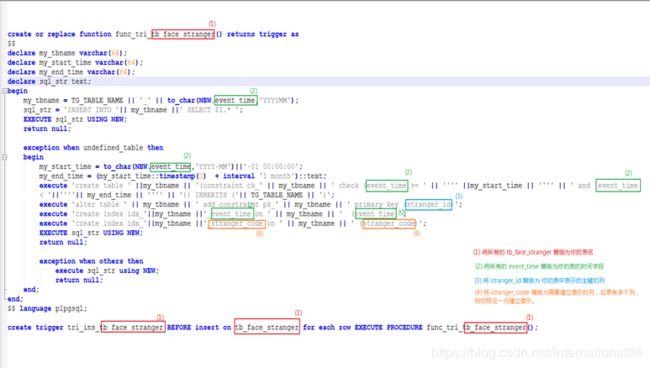
下面是替换的示意图:
即:
(1)将所有的 tb_face_stranger 替换为你的表名
(2)将所有的event_time 替换为你的表的时间字段
(3)将stranger_id 替换为你的表中表示主键的列,在触发器函数内部。
(4)为你的表中的特定列建立索引,在触发器函数内部。
2.3 为有数据的表创建分区
这种情况下,我们除了需要建立触发器函数和触发器外,还需要将原有的主表中的数据迁移到对应分表中。
我们的整体方案如下:
- 首先,像那样,为这张表创建用于分表的触发器函数和触发器。
- 创建用于将数据主表迁移到分表的函数,并执行它。
- 删除第二步创建的函数。
- 清空主表中的数据。
2.3.1 案例
下面一个完整的案例,这里依然以tb_face_stranger为例。
-- 1. 创建用于分表的触发器函数和触发器
create or replace function func_tri_tb_face_stranger() returns trigger as
$$
declare my_tbname varchar(64);
declare my_start_time varchar(64);
declare my_end_time varchar(64);
declare sql_str text;
begin
my_tbname = TG_TABLE_NAME || '_' || to_char(NEW.event_time,'YYYYMM');
sql_str = 'INSERT INTO '|| my_tbname ||' SELECT $1.* ';
EXECUTE sql_str USING NEW;
return null;
exception when undefined_table then
begin
my_start_time = to_char(NEW.event_time,'YYYY-MM')||'-01 00:00:00';
my_end_time = (my_start_time::timestamp(0) + interval '1 month')::text;
execute 'create table ' ||my_tbname || '(constraint ck_' || my_tbname || ' check (event_time >= ' || '''' ||my_start_time || '''' || ' and event_time < '||''''|| my_end_time || '''' || ')) INHERITS ('|| TG_TABLE_NAME || ')';
execute 'alter table ' || my_tbname || ' add constraint pk_' || my_tbname || ' primary key (stranger_id)';
execute 'create index idx_'||my_tbname ||'_event_time on ' || my_tbname || ' (event_time)';
execute 'create index idx_'||my_tbname ||'_stranger_code on ' || my_tbname || ' (stranger_code)';
EXECUTE sql_str USING NEW;
return null;
exception when others then
execute sql_str using NEW;
return null;
end;
end;
$$ language plpgsql;
create trigger tri_ins_tb_face_stranger BEFORE insert on tb_face_stranger for each row EXECUTE PROCEDURE func_tri_tb_face_stranger();
-- 2. 创建用于将数据主表迁移到分表的函数,并执行它
create or replace function func_part_existing_tb_face_stranger() returns int as
$body$
declare
v_min_event_time timestamp;
v_start_time_of_this_month timestamp; -- 某个月的开始时间,可变
v_end_time_of_this_month timestamp; -- 某个月的结束时间,可变
v_start_time_of_current_month timestamp; -- 本月的第一天,不变
v_first_month text;
my_tbname text;
begin
select min(event_time) into v_min_event_time from tb_face_stranger;
v_start_time_of_this_month := cast(date_trunc('month', v_min_event_time) as timestamp) ;
v_end_time_of_this_month := v_start_time_of_this_month + interval '1 month';
select cast(date_trunc('month', now()) as timestamp) into v_start_time_of_current_month;
while v_start_time_of_this_month <= v_start_time_of_current_month loop
v_first_month = to_char(v_start_time_of_this_month,'YYYYMM');
my_tbname = 'tb_face_stranger' || '_' || v_first_month;
execute 'drop table if exists ' || my_tbname;
execute 'create table ' || my_tbname || ' (like tb_face_stranger)';
execute 'insert into ' || my_tbname || ' select * from only tb_face_stranger where event_time >= ''' || v_start_time_of_this_month || ''' and event_time < ''' || v_end_time_of_this_month || '''';
execute 'alter table ' || my_tbname || ' inherit tb_face_stranger';
execute 'alter table ' || my_tbname || ' add constraint ck_' || my_tbname ||
' check (event_time >= ''' || v_start_time_of_this_month || ''' and event_time < ''' || v_end_time_of_this_month || ''')';
execute 'alter table ' || my_tbname || ' add constraint pk_' || my_tbname || ' primary key (stranger_id)';
execute 'create index idx_'||my_tbname ||'_event_time on ' || my_tbname || ' (event_time)';
execute 'create index idx_'||my_tbname ||'_stranger_code on ' || my_tbname || ' (stranger_code)';
v_start_time_of_this_month = v_start_time_of_this_month + interval '1 month';
v_end_time_of_this_month = v_end_time_of_this_month + interval '1 month';
end loop;
return 0;
end;
$body$ language plpgsql;
select func_part_existing_tb_face_stranger();
-- 3. 删除第二步创建的函数。
drop function func_part_existing_tb_face_stranger();
-- 4. 清空主表中的数据。
truncate only tb_face_stranger;
第二步创建的函数会做哪些工作呢?
- 首先,它会查询主表中的数据,获得最早的那个月份。
- 然后,它会为从最早的那个月到今天的每个月都创建一个分表,并将这个月内的数据插入到分表中,随后为这张表创建检查约束,主键约束和索引。
2.3.2 代码复用
和第一节的复用方法相似,对于整个模板
(1)将所有的 tb_face_stranger 替换为你的表名
(2)将所有的event_time 替换为你的表中用来分区的字段
(3)将stranger_id 替换为你的表中表示主键的列,在触发器函数和数据迁移函数内部。
(4)在你的表中的特定的列上建立索引,在触发器函数和数据迁移函数内部。
3. 总结
本文介绍了PostgreSQL 9.6及其以下的版本的数表的分区的方法。因为PostgreSQL 从10.0 版本起,引入了性能更好的原生的分区。因此如果你使用的是PostgreSQL 10.0 以上的版本,则建议使用原生分区。