五种IO模型(阻塞 非阻塞 IO多路复用 信号驱动 异步)和两种IO事件处理模式(Reactor Proactor)
欢迎交流 QQ 2431173627 微信 ccc17862701790
引入
在介绍六种IO模型之前首先需要理解 四个概念:同步 异步 阻塞 非阻塞
关于同步 异步 阻塞 非阻塞 在不同上下文讨论时候背景是不同的 这里讨论的背景是linux环境下的networkIO
首先一个IO操作其实分成了两个步骤:
1.用户进程向内核发起IO请求,等待内核数据准备
2.实际的IO操作,将数据从内核拷贝到进程缓存区中
阻塞IO和非阻塞IO的区别在于第一步,
发起IO请求是否会被阻塞,如果阻塞直到完成那么就是传统的阻塞IO,
如果不阻塞,那么就是非阻塞IO。
即进程/线程要访问的数据是否就绪,进程/线程是否需要等待;
同步IO和异步IO的区别就在于第二个步骤是否阻塞。
如果实际的IO读写阻塞请求进程,那么就是同步IO,
因此后面可以看到阻塞IO、非阻塞IO、IO复用、信号驱动IO都是同步IO;
如果不阻塞,而是操作系统帮你做完IO操作再将结果返回给你,那么就是异步IO。
访问数据的方式,同步需要主动读写数据,在读写数据的过程中还是会阻塞;
异步只需要I/O操作完成的通知,并不主动读写数据,由操作系统内核完成数据的读写。
有了上面的同步 异步 阻塞 非阻塞的概念介绍以后
就有了 同步阻塞 同步非阻塞 异步阻塞 异步非阻塞的组合
同步阻塞I/O
在此种方式下,用户进程在发起一个I/O操作以后,必须等待I/O操作的完成,
只有当真正完成了I/O操作以后,用户进程才能运行。
下面要介绍的阻塞IO模型和IO复用模型就是这种类型
同步非阻塞I/O
在此种方式下,用户进程发起一个I/O操作以后边可返回做其它事情,
但是用户进程需要时不时的询问I/O操作是否就绪,这就要求用户进程不停的去询问,
从而引入不必要的CPU资源浪费。
下面要介绍的信号驱动模型和非阻塞模型就是这种类型
异步阻塞IO
略
异步非阻塞I/O
在此种模式下,用户进程只需要发起一个I/O操作然后立即返回,
等I/O操作真正的完成以后,应用程序会得到I/O操作完成的通知,
此时用户进程只需要对数据进行处理就好了,不需要进行实际的I/O读写操作,
因为真正的I/O读取或者写入操作已经由内核完成了。
下面要介绍的异步io模型就是这种类型
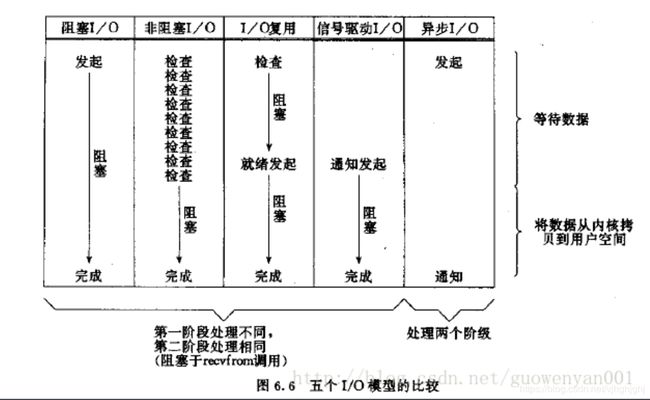
五种IO模型
阻塞IO模型

第一阶段:当用户进程调用了recvfrom这个系统调用,
kernel就开始了IO的第一个阶段:准备数据。
对于network io来说,
很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),
这个时候kernel就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。
第二阶段:当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,
然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
非阻塞IO模型
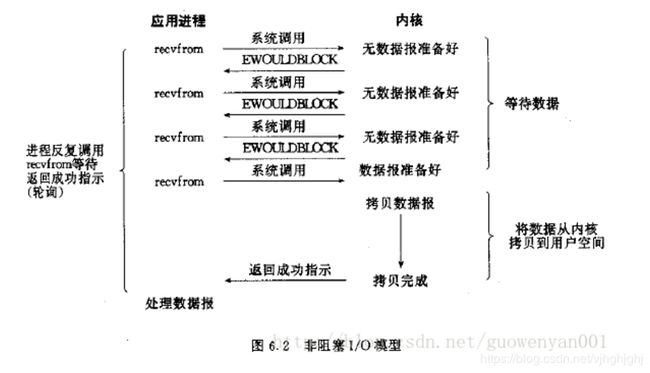
第一阶段:当用户进程发出read操作时,如果kernel中的数据还没有准备好,
那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,
它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。
用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。
第二阶段:一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,
那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
IO复用模型
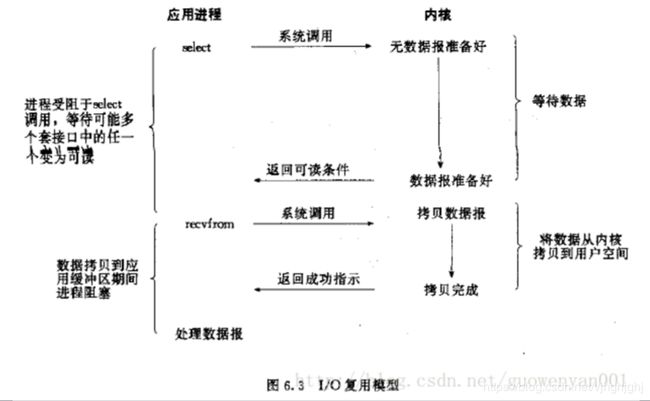
第一阶段:用户进程调用了select,整个进程会被block,
而同时,kernel会“监视”所有select负责的socket,
当任何一个socket中的数据准备好了,select就会返回。
第二阶段:这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
分析:
1.这个图和blocking IO的图其实并没有太大的不同,
事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),
而blocking IO只调用了一个system call (recvfrom)。
但是,用select的优势在于它可以同时处理多个connection。
2.如果处理的连接数不是很高的话,
使用select/epoll的web server不一定比
使用multi-threading + blocking IO的web server性能更好,
可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,
而是在于能处理更多的连接。
3.在IO multiplexing Model中,
实际中,对于每一个socket,一般都设置成为non-blocking,
但是,如上图所示,整个用户的process其实是一直被block的。
只不过process是被select这个函数block,而不是被socket IO给block。
信号驱动IO模型
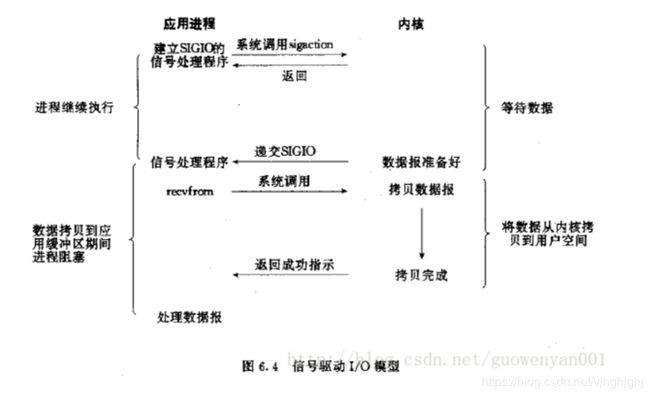
第一阶段:当需要等待数据的时候,首先用户态会向内核发送一个信号,
告诉内核我要什么数据,等到这个数据来的时候给它发信号
然后用户态就不管了,做别的事情去了.
第二阶段:当内核态中的数据准备好之后,内核立马发给用户态一个信号,
说”数据准备好了,快来查收“,用户态进程收到之后,
立马调用recvfrom,等待数据从内核空间复制到用户空间,
待完成之后recvfrom返回成功指示,用户态进程才处理别的事情。
通过上面的图,可以看出信号驱动式I/O模型有种异步操作的赶脚,
但是在将数据从内核复制到用户空间这段时间内用户态进程是阻塞的异步IO模型
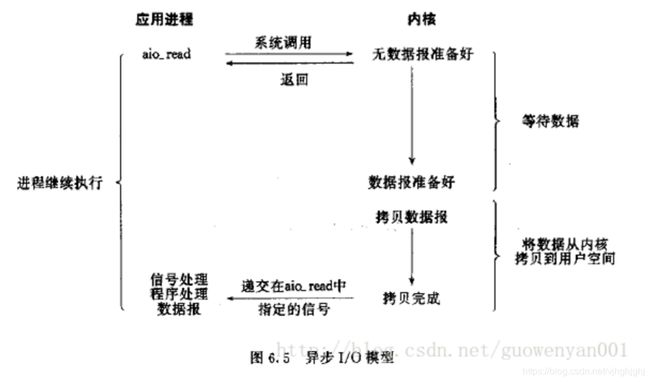
第一阶段 首先用户态进程告诉内核态需要什么数据(上图中通过aio_read),
然后用户态进程就不管了,做别的事情.
第二阶段:内核等待用户态需要的数据准备好,然后将数据复制到用户空间,
此时才告诉用户态进程,”数据都已经准备好,请查收“,
然后用户态进程直接处理用户空间的数据。
在复制数据到用户空间这个时间段内,用户态进程也是不阻塞的
很少有Linux系统支持这种模型 在Windows下的IOCP就是该模型比较
两种IO事件处理模式
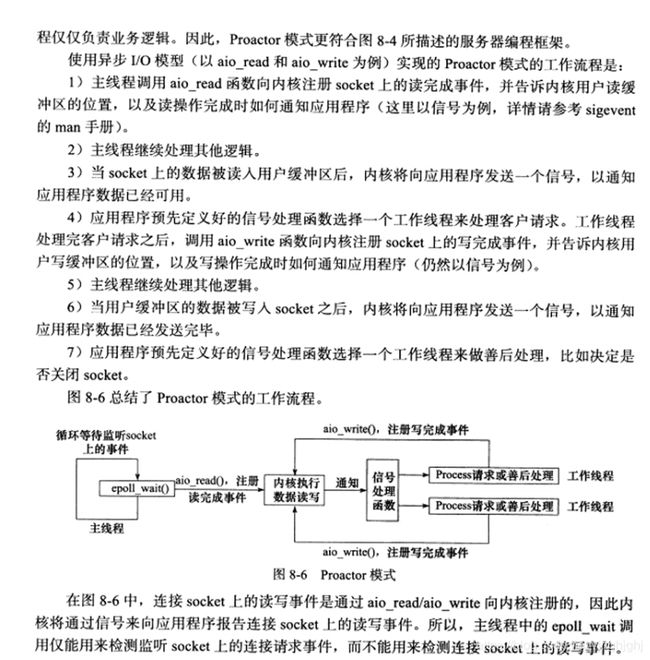
Reactor模式
原理讲解
以小饭馆的服务模式为例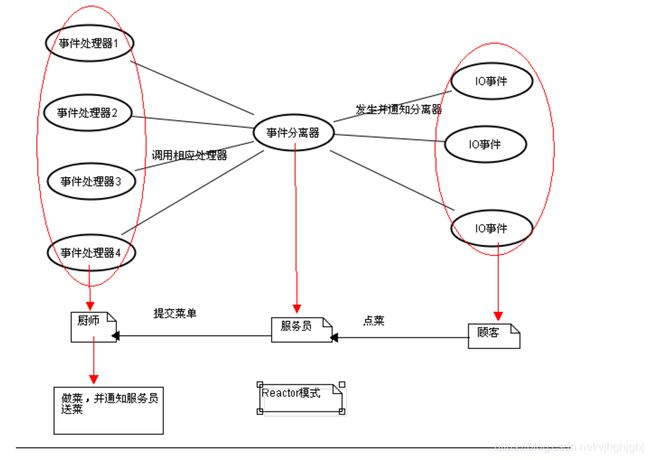
每一个顾客就对应这服务器所接受到的外部事件(IO事件,定时器,信号),
服务员对应着事件分离器 负责监听外部事件
服务员会把菜单交给厨师 然后厨师针对这个事件进行处理 也就是做菜
我们以读操作为例来看看Reactor中的具体步骤:
读取操作:
1. 应用程序注册读就绪事件和相关联的事件处理器
在饭馆里面每一个菜对应着有一个对应的厨师做那道菜
要先让服务员知道每个菜(注册就绪事件) 和那道菜对应的厨师 (注册对应的事件处理器)
2. 事件分离器等待事件的发生
相当于服务员等待客人点菜
3. 当发生读就需事件的时候,事件分离器调用第一步注册的事件处理器
相当于客人点菜了 服务员找到对应这道菜的厨师
4. 事件处理器首先执行实际的读取操作,然后根据读取到的内容进行进一步的处理
相当于大厨先知道这道菜的菜名 然后开始做
但是怎么做 用那些配料等等这些后续的操作是他自己来决定的由于这里真正执行IO操作的(也就是从内核区读取io数据到缓存区的这一步)是事件处理器自身,
也就是说在io操作的第二阶段应用程序是阻塞的,所以我们说Reactor模式是同步的
实现方案
在服务器端程序设计的时候 用Reactor模式的一个实现方案是
1.在Reactor中注册好感兴趣的事件(IO事件 信号 定时器)
2.用一个主线程(IO处理单元)负责监听文件描述符上的是否有事件发生除此之外它不做别的实质性的工作 ,采用io复用的形式 比如用select epoll poll这些.
3.当发生了对应事件 主线程就通知工作进程 (通过请求队列)
4.在工作线程(逻辑单元)中读写数据 接受新的连接 处理客户请求等等
使用基于epoll来实现Reactor模式的一个方案如下
由于这里真正执行IO操作的(也就是从内核区读取io数据到缓存区的这一步)是工作线程自身,
也就是说在io操作的第二阶段应用程序是阻塞的,所以我们说Reactor模式是同步的
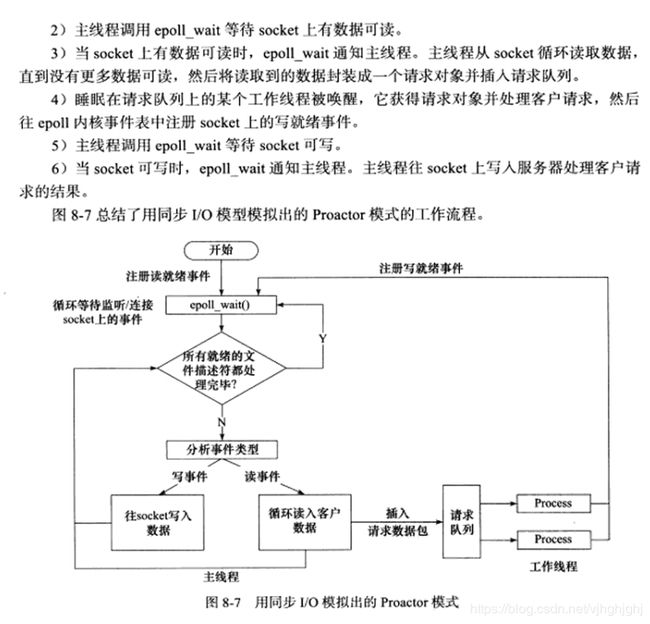
Proactor模式
原理讲解
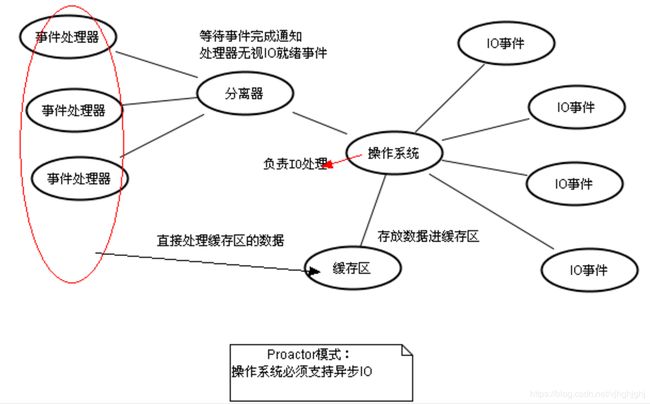
下面我们来看看Proactor模式中读取操作和写入操作的过程:
读取操作:
1. 应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,
而是关注读取完成事件,这是区别于Reactor的关键。
2. 事件分离器等待读取操作完成事件
3. 在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作,
并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,
应用程序需要传递缓存区。
4. 事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,
事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
Proactor中写入操作和读取操作,只不过感兴趣的事件是写入完成事件。
从上面可以看出,Reactor和Proactor模式的主要区别就是真正的读取和写入操作是有谁来完成的,
Reactor中需要应用程序自己读取或者写入数据,而Proactor模式中,
应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,
操作系统会读取缓存区或者写入缓存区到真正的IO设备.
实现方案
![]()