大数据挑战赛--文本点击率预估 正式赛初赛记录
本次比赛的一些心得和记录
赛题:https://www.kesci.com/home/competition/5cc51043f71088002c5b8840/content/1
赛题描述
文本点击率预估(5月26日开赛)
搜索中一个重要的任务是根据query和title预测query下doc点击率,本次大赛参赛队伍需要根据脱敏后的数据预测指定doc的点击率,结果按照指定的评价指标使用在线评测数据进行评测和排名,得分最优者获胜。
遇到的问题
- 计算资源的匮乏,只有4核,30G的内存,而数据是9G左右,读取全部数据就会造成内存短缺
- 数据清洗,你得清洗出数据才能使用哇,代码必须非常的高效。
- 特征提取,这里使用tfidf的多,我使用了自己定义了一个相关度
- 模型建立,转成标准格式,输入输出,我使用了svm和lgb,两种模型
- 评估,loss 直接提交来看模型的好坏,但这样很容易找不到模型的问题。
数据清洗
我先抽取了后1000w的数据作为我的训练数据,也就是原始数据的1/10。写成另一个文本。
还有一种方式,随机抽取1000w数据,每1000w数据抽10w的数据。这个我个人认为去掉一定的偶然性,并且在做tfidf的时候,分布比较均匀。但,我这个代码大约跑了28h才出来,时间成本非常高。
代码没什么难度就不放了
特征提取
- 一种是使用tfidf建立
- 一种是建立相似度
- 统计特征
大概是这几类
因为本人学渣,自己建立一个相似度计算方式,贼简单的那种,但因为单特征强度不是很好,成绩也不是很好
with open("/home/kesci/input/bytedance/first-round/train.csv")as f:
i=0
with open("similar.csv","w")as f1:
for line in f:
data=line.split(",")
queryid=data[0]
query=data[1].split(" ")
querytitleid=data[2]
title=data[3].split(" ")
lable=data[4].split("\n")[0]
l=len(title)
l3=len(query)
for word in query:
if word in title:
title.remove(word)
else:
continue
l2=len(title)
s=(1-float(l2/l))
f1.write(queryid+","+querytitleid+","+str(s)+","+lable+"\n")
i+=1
if i%1000000==0:
print(i-1000000)
如上,建立了特征文件
模型建立SVM
这里因为数据量的巨大,我使用了分布式的pandas进行数据的读取
import modin.pandas as pd
train_df = pd.read_csv("/home/kesci/work/last_10000000.csv",header=None,\
names=["query_id","query_title_id","similar","lable"])
train_dev_df=pd.read_csv("/home/kesci/work/last_dev_last_1000000.csv",header=None,\
names=["query_id","query_title_id","similar","lable"])
test_df= pd.read_csv("/home/kesci/work/similar_test.csv",header=None,\
names=["query_id","query_title_id","similar"])
检查数据格式的正确后,建立训练集和测试集
X_train=train_df["similar"]
print("1")
Y_train=train_df["lable"]
print("2")
X_dev=train_df["similar"]
print("3")
Y_dev=train_df["lable"]
print("4")
X_test=test_df["similar"]
print("5")
再建立模型,引入相关包
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
from sklearn.calibration import CalibratedClassifierCV
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split,cross_val_score,cross_validate
import numpy as np
#SVC1 =SVC(kernel='rbf',C=1.5)
SVC1 =LinearSVC(C=1.5)
clf = CalibratedClassifierCV(SVC1)
print(1)
scaler = StandardScaler()
X_train_reshape=np.array(X_train).reshape(-1, 1)
Y_train_reshape=np.array(Y_train).reshape(-1, 1)
print(2)
clf.fit(X_train_reshape, Y_train_reshape)
这里,对于线性svc,和其他的核函数我都试了,线性的效果比较好

进行预测,写入文件
X_test=np.array(test_df["similar"]).reshape(-1, 1)
test_predict = clf.predict_proba(X_test)
print(test_predict[0][1])
test_predict_positive = [item[1] for item in list(test_predict)]
test_ids = test_df['query_id']
print(1)
test_tittle_ids=test_df['query_title_id']
print(1)
Data = {'query_id':test_ids,'query_title_id':test_tittle_ids, 'Pred':test_predict_positive}
print(1)
pd.DataFrame(Data, columns=['query_id','query_title_id', 'Pred']).to_csv('kjjkw.csv',index=False, header=False)
print(1)
这里,predict_proba,这个是生成正概率的参数,就是提交的概率,而不是生成的0或1
至此,svm模型建立完成
模型建立LGBM
这个模型是我第一次接触,查了好多的文档
前面的训练集测试集建立完全一致
然后转换为LGBM可使用的格式
import numpy
X_train_reshape=np.array(X_train).reshape(-1, 1)
#Y_train_reshape=np.array(Y_train).reshape(-1, 1)
Y_train_reshape=np.array(Y_train)
X_dev_reshape=np.array(X_dev).reshape(-1,1)
#Y_dev_reshape=np.array(Y_dev).reshape(-1,1)
Y_dev_reshape=np.array(Y_dev)
X_test_reshape=np.array(X_test).reshape(-1,1)
建立模型
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
gbm = lgb.LGBMRegressor(objective='regression',num_leaves=91,
learning_rate=0.1, n_estimators=20, max_depth=-1
)
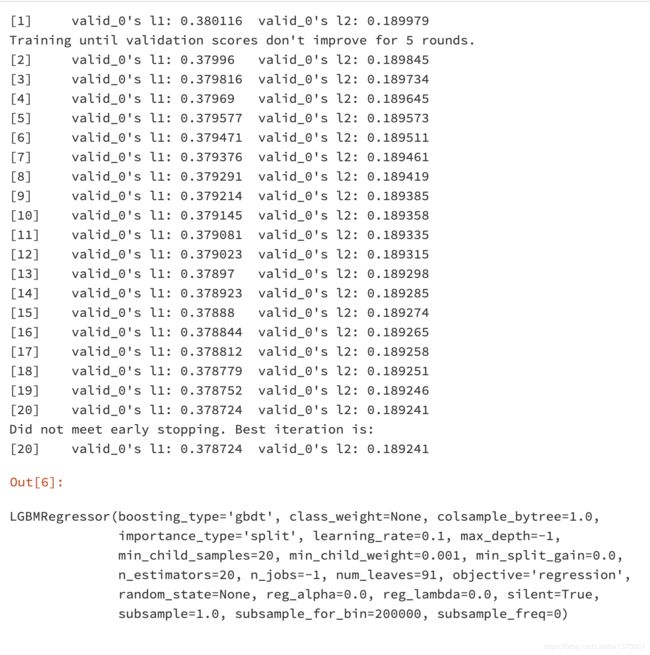
gbm.fit(X_train_reshape, Y_train_reshape,
eval_set=[(X_dev_reshape, Y_dev_reshape)],
eval_metric='l1',
early_stopping_rounds=5)
预测写入文件
y_pred = gbm.predict(X_test_reshape,num_iteration=gbm.best_iteration_)
test_ids = test_df['query_id']
print(1)
test_tittle_ids=test_df['query_title_id']
print(1)
Data = {'query_id':test_ids,'query_title_id':test_tittle_ids, 'Pred':y_pred}
print(1)
pd.DataFrame(Data, columns=['query_id','query_title_id', 'Pred']).to_csv('w2.csv',index=False, header=False)
print(1)
这里我尝试使用超参数搜索,但时间成本非常大,也就没跑
hyper_space = {'n_estimators': [20, 30, 50, 100],
'max_depth': [4, 5, 8, -1],
'num_leaves': [15, 31, 63, 127],
'subsample': [0.6, 0.7, 0.8, 1.0],
'colsample_bytree': [0.6, 0.7, 0.8, 1.0],
'learning_rate' : [0.01,0.02,0.03]
}
est = lgb.LGBMRegressor(random_state=2018)
gs = GridSearchCV(est, hyper_space, scoring='r2', cv=4, verbose=1)
gs_results = gs.fit(X_train_reshape, Y_train_reshape)
print("BEST PARAMETERS: " + str(gs_results.best_params_))
print("BEST CV SCORE: " + str(gs_results.best_score_))
至此,LGBM也结束了。
结束语
- 第一次一个人走完了这个从数据开始到建模的过程,有开心有纠结有mmp。
- 在没有外援的情况下,一个人完成了整个过程的学习过程。我太难了
- 第一次遇到资源限制的比赛,对代码的高效性有了很高的要求