导语:
DDLog,即CocoaLumberjack是iOS开发用的最多的日志框架,出自大神Robbie Hanson之手(还有诸多知名开源框架如 XMPPFramework、 CocoaAsyncSocket,都是即时通信领域很基础应用很多的框架)。了解DDLog的源码将有助于我们更好的输出代码中的日志信息,便于定位问题,也能对我们在书写自己的日志框架或者其他模块时有所启发。
此系列文章将分为以下几篇:
- DDLog源码解析一:框架结构
- DDLog源码解析二:设计初衷
- DDLog源码解析三:FileLogger
上一节介绍了框架结构和主要几个类的内容,本节将重点关注DDLog的核心部分,对于线程的考虑:通过一些线程方面的设计,以达到上一节跳提到的“准确”、“快速”、“安全”的目的,试图去解析DDLog设计的初衷,下面我将通过逐步引导来切入正题:
如何快速?
- 作为线程方面考虑的最基本原则,我们都应该想到日志作为高频操作,由于不需要UIKit方面接口调用,一定要放在子线程。
- 另外,“快速”也相对于NSLog,上一节提到NSLog因为要同时输出日志两个源(ASL和控制台,但不支持文件),所以效率肯定低,我们平时的需求除非正好跟NSLog输出的两个源吻合,否则我们只需要自己对应一个源的输出,例如只输出到控制台。
- 代码执行的速度,这里讲在后面具体讲解DDLog哪些操作可以加速代码的执行。
如何准确?
- 因为要保证日志记录的顺序严格准确的,我们自然而然地就会想到串行队列,让所有想保证顺序的操作都在这个队列中排队进行。
- 当我们要处理多个输出源的时候,我们肯定要将不同的输出源的日志操作放在不同线程中,因为不同的源记录的内容是各自顺序正确即可,互相没有依赖和耦合,如果放在一个线程将降低写日志的速度。
- 另外每个源的记录内容要高度统一,不然会造成误解或内容确实,影响问题的定位,这时我们就要保证各个不同源的线程要同步,不能某个快很多,其他慢很多,这时候就需要考虑同步的策略,待选的方案可能有@synchronized、NSLock、dispatch_semaphore、NSCondition、OSSpinLock等多种,我们直接站在巨人的肩膀上,dispatch_semaphore是效率最高的。
如何安全?
(1)线程安全
DDLog在线程安全方面主要就是通过串行队列来对一些可能多出访问的资源进行保护,并且通过dispatch_group和信号量dispatch_semaphore来保证多个线程(串行队列)中间的同步。
(2)文件安全
在文件安全方面,主要就是不能让日志文件无限制的增大,影响到整个app甚至系统的使用,直接影响用户对app的留存。这里DDLog有一套时间轮询和文件变化时的检查来控制文件,并且周期更新文件的个数,保证总占用空间及文件个数符合开发者的配置。
总结
基于以上分析,我们基本摸清了DDLog类在线程方面的设计的考虑,下面考虑一下实际可能需要面对的一个简单场景:在我们记录日志的过程中可能存在先removeLogger、addLogger,然后进行高频的日志写操作,由于addLogger之后支持三种Logger的写日志操作,所以需要支持三种Logger一起执行,并且在日志写之后又addLogger。
对于上面的场景,我们将DDlog处理时线程的设计描绘如下图:
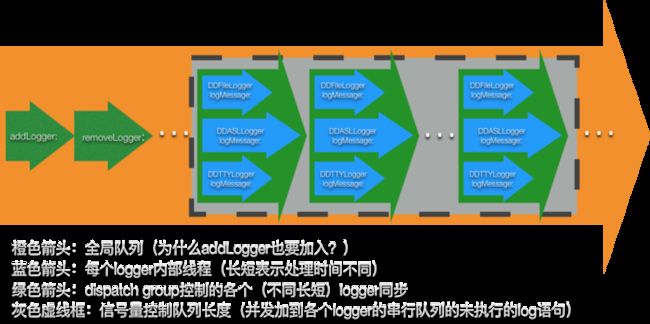
全局日志队列
图中橙色箭头表示DDLog类中生成的串行队列,我们称之为全局日志队列,用于控制全局的logger的增减、logger的获取、各个logger的写日志等操作的排序执行,这里为什么Logger的增减也要跟写日志放在一个队列中呢? 看下如下的常见DDLog调用代码:
// 初始化
DDLog addLogger:[DDTTYLogger sharedInstance]];
DDLog addLogger:[[DDFileLogger alloc] init]];
// 开始打印日志
DDLogInfo(@"log msg 1");
DDLogInfo(@"log msg 2”);
// 更改日志格式后再打印
[logger setFormatter:myFormatter];
DDLogInfo(@"log msg 3");
当addLogger的两句代码和DDLogInfo在不同线程执行时,势必可能存在一种可能,当第一句DDLogInfo执行时,并没有将日志写到文件中,这就可能是因为没有按照语句的顺序来执行实际的操作。
对于这个队列主要涉及创建、标记、和判断当前是否是这个线程三个方面:
+ (void)initialize
{
static dispatch_once_t DDLogOnceToken;
dispatch_once(&DDLogOnceToken, ^{
NSLogDebug(@"DDLog: Using grand central dispatch");
_loggingQueue = dispatch_queue_create("cocoa.lumberjack", NULL);
_loggingGroup = dispatch_group_create();
void *nonNullValue = GlobalLoggingQueueIdentityKey; // Whatever, just not null
dispatch_queue_set_specific(_loggingQueue, GlobalLoggingQueueIdentityKey, nonNullValue, NULL);
_queueSemaphore = dispatch_semaphore_create(DDLOG_MAX_QUEUE_SIZE);
// Figure out how many processors are available.
// This may be used later for an optimization on uniprocessor machines.
_numProcessors = MAX([NSProcessInfo processInfo].processorCount, (NSUInteger) 1);
NSLogDebug(@"DDLog: numProcessors = %@", @(_numProcessors));
});
}
这里注意下,_loggingQueue、_loggingGroup、_queueSemaphore由于在DDLog的类方法和实例方法都要用到,所以需要声明为静态变量,并且在DDLog这个类第一次使用时就初始化完成,所以这里将初始化的过程放在 + (void)initialize 方法中。
各个Logger的串行队列-- “行进有序”
前面已经提过,由于各个Logger不耦合无依赖关系,所以各个Logger讲生成各自的串行队列来进行内部的写日志、设置formatter、flush的顺序执行,这里设置formatter由于是各个Logger通用的代码,将其放在基类来执行:
// @implementation DDAbstractLogger
- (id )logFormatter
{
NSAssert(![self isOnGlobalLoggingQueue], @"Core architecture requirement failure");
NSAssert(![self isOnInternalLoggerQueue], @"MUST access ivar directly, NOT via self.* syntax.");
dispatch_queue_t globalLoggingQueue = [DDLog loggingQueue];
__block id result;
dispatch_sync(globalLoggingQueue, ^{
dispatch_sync(_loggerQueue, ^{
result = _logFormatter;
});
});
return result;
}
- (void)setLogFormatter:(id )logFormatter {
NSAssert(![self isOnGlobalLoggingQueue], @"Core architecture requirement failure");
NSAssert(![self isOnInternalLoggerQueue], @"MUST access ivar directly, NOT via self.* syntax.");
dispatch_block_t block = ^{
@autoreleasepool {
if (_logFormatter != logFormatter) {
if ([_logFormatter respondsToSelector:@selector(willRemoveFromLogger:)]) {
[_logFormatter willRemoveFromLogger:self];
}
_logFormatter = logFormatter;
if ([_logFormatter respondsToSelector:@selector(didAddToLogger:inQueue:)]) {
[_logFormatter didAddToLogger:self inQueue:_loggerQueue];
} else if ([_logFormatter respondsToSelector:@selector(didAddToLogger:)]) {
[_logFormatter didAddToLogger:self];
}
}
}
};
dispatch_queue_t globalLoggingQueue = [DDLog loggingQueue];
dispatch_async(globalLoggingQueue, ^{
dispatch_async(_loggerQueue, block);
});
}
这段代码已经很清楚表明上面图示的意思:各个Logger内部的写日志、设置formatter、flush都将首先被加到全局日志队列中排队,然后再加到各个Logger内部的日志串行队列排队,通过这两个串行队列来保证顺序的正确性。
通过全局日志队列和logger内部队列 两个队列的约束,从而保证了日志相关操作真正做到了“行进有序”。
dispatch_group + dispatch_semaphore:“齐头并进” + “流量控制”
单个Logger内部通过串行队列已经保证了日志相关操作的顺序,但我们面临上面提到的问题----很容易忽略的问题:当我们app的进程被杀掉时,很有可能出现系统日志或者文件中的日志并不如控制台上完备,丢失了最后时刻的很多重要信息。 这个原因就是因为系统日志和写文件的串行队列执行速度比控制台慢很多,如果进程被杀掉前一时刻有很多日志操作,就会导致系统日志和文件的队列中有大量排队中未执行的日志操作,在杀掉进程时没法完全flush到对应的源中。
DDLog处理这个情况就是通过dispatch_group + dispatch_semaphore这对GCD基友组合,请留意图中的绿色箭头和灰色框内部的部分:
- 每个绿色箭头内部有三个箭头表示三种输出源,由于处理日志速度不同,三个蓝色箭头长度不同,所以绿色箭头代表的dispatch_group就是要控制三者可以并行运行的前提下,一同向前,等三者都执行完了,才执行后面的日志语句。
- 灰色框体内有多个排队中待执行的log语句(绿色箭头),为了控制待执行的语句数量不会无限制的大,这里使用了信号量来控制总数量,否则队列过大就有可能在进程杀掉时,无法全部执行完队列中待执行的log语句。
通过一段代码来了解下:
for (DDLoggerNode *loggerNode in self._loggers)
{
// skip the loggers that shouldn't write this message based on the log level
if (!(logMessage->_flag & loggerNode->_level)) {
continue;
}
dispatch_group_async(_loggingGroup, loggerNode->_loggerQueue, ^{ @autoreleasepool {
[loggerNode->_logger logMessage:logMessage];
} });
}
dispatch_group_wait(_loggingGroup, DISPATCH_TIME_FOREVER);
dispatch_semaphore_signal(_queueSemaphore);
其中DDLoggerNode就是含有Logger信息的model,_loggingGroup就是dispatch_group,loggerNode->_loggerQueue就是logger内部的日志队列。
可见,对于一次logMessage:logMessage语句,都会将其放在每个logger内部的队列中去执行,并且通过dispatch_group_wait来保证这个队列都完成再向后运行,这里就保证了“齐头并进”。
上面代码中还出现了dispatch_semaphore_signal,它和dispatch_semaphore_wait是好基友,二者通过对初始化时的信号量分别进行-1和+1操作来保证“流量控制”
_queueSemaphore = dispatch_semaphore_create(1000);
.
.
.
- (void)queueLogMessage:(DDLogMessage *)logMessage asynchronously:(BOOL)asyncFlag
{
dispatch_semaphore_wait(_queueSemaphore, DISPATCH_TIME_FOREVER);
dispatch_block_t logBlock = ^{
@autoreleasepool {
[self lt_log:logMessage];
}
};
if (asyncFlag) {
dispatch_async(_loggingQueue, logBlock);
} else {
dispatch_sync(_loggingQueue, logBlock);
}
}
综上,总结下DDLogInfo这句日志语句最终执行代码的调用栈:
DDLogInfo
V
V
宏替换
V
V
[DDLog log:]
V
V
[DDLog queueLogMessage:]
V
V
lt_log
V
V
[loggerNode->_logger logMessage:]
宏替换
这里的宏替换,一方面让代码更简洁,减少代码正文中频繁的接口调用和嵌套,另一方面的考虑就是前文提到的“快速”,下面我们从宏替换实际工作的过程,看下为什么通过宏替换可以“快速” (DDLegacyMacros.h):
从DDLogInfo的定义开始:
#define DDLogInfo(frmt, ...) LOG_OBJC_MAYBE(LOG_ASYNC_INFO, LOG_LEVEL_DEF, LOG_FLAG_INFO, 0, frmt, ##__VA_ARGS__)
其中使用可变参数... 通过后面的VA_ARGS来标识,VA_ARGS前面的##是为了兼容这个位置可能没有参数的情况。LOG_OBJC_MAYBE定义如下:
#define LOG_OBJC_MAYBE(async, lvl, flg, ctx, frmt, ...) \
LOG_MAYBE(async, lvl, flg, ctx, __PRETTY_FUNCTION__, frmt, ## __VA_ARGS__)
可以看出LOG_OBJC_MAYBE的宏定义中只是插入另一个____PRETTY_FUNCTION__(函数名)参数到LOG_MAYBE中,而LOG_MAYBE的定义如下:
#define LOG_MAYBE(async, lvl, flg, ctx, fnct, frmt, ...) \
do { if(lvl & flg) LOG_MACRO(async, lvl, flg, ctx, nil, fnct, frmt, ##__VA_ARGS__); } while(0)
使用do{...}while(0)构造后的宏定义不会受到大括号、分号等的影响,使{}内部的语句按正常意愿执行。这里其实参数未变,只是替换成LOG_MACRO:
#define LOG_MACRO(isAsynchronous, lvl, flg, ctx, atag, fnct, frmt, ...) \
[DDLog log : isAsynchronous \
level : lvl \
flag : flg \
context : ctx \
file : __FILE__ \
function : fnct \
line : __LINE__ \
tag : atag \
format : (frmt), ## __VA_ARGS__]
这一步就已经到了类DDLog的log接口中。其中FILE表示文件名,LINE 表示行数。
综上,上面只是打印函数的宏定义接口之一DDLogInfo的宏替换过程,其他几个宏定义接口DDLogError、DDLogWarn、DDLogDebug、DDLogVerbose都有着相似的过程,但部分传入参数有区别,试想下我们如果不要上面的宏替换,直接让开发者调用[DDLog log : xxxxxx]方法,那开发者一定崩溃了,参数太多了。
所以从易用性角度出发,必然要给开发者暴露只含有必要参数的接口。但是如果DDLogError、DDLogWarn、DDLogDebug、DDLogVerbose、DDLogInfo都分别封装一个接口,都需要DDLog类中多写几次函数的调用才能最终调用到[DDLog log : xxxxxx]方法,这种方式相对于当前宏替换的方案明显增加了很多次堆栈控件的申请、保存返回地址,将形参压栈,释放堆栈等操作,必然降低代码执行的效率,所以我们说这种宏替换的方式在预编译阶段就直接将需要使用的最终接口确定,使代码执行做到了“快速”,这一点点的提升对于高频的写日志操作来说是有必要的。