Hadoop,Zookeeper、Kafka简单集群搭建
搭建hadoop、zookeeper、kafka集群
1. 创建虚拟机
因为配置有限,这里我只创建3台虚拟机,配置足够的话可以创建多台或者使用多台搭载linux系统的服务器,这里只放部分虚拟机创建图.




后面就按需求修改下或者直接暴力下一步就能完成。
最后开机这样就行了

2. 配置网络环境
首先对jerry1进行网络配置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
进去后进行修改和添加,修改ONBOOT为yes,增加底下的ip和网关、子网掩码等信息。

修改下hostname
hostnamectl set-hostname jerry1
修改下hosts
因为我们是一个集群3台机器一共,所以这里添加3条包括本机和另外两台机器的ip和hostname,为后面铺垫。
vi /etc/hosts

关闭一下防火墙
systemctl stop firewalld
systemctl disable firewalld
我们重启下网络
ping一下百度试试,看网通了没有
systemctl restart network.service

对jerry2,jerry3也进行上述操作。
3. 对各主机进行免密验证配置
现在jerry1做一下免密验证
直接cd ~ 命令进入root目录,输入一下命令,中间让你输入key不用管,直接Enter。
ssh-keygen -t rsa -P ""
然后会产生有一个.ssh文件夹,直接cd进去,写入秘钥
cd ./ssh/
cat id_rsa.pub >> ./authorized_keys
同文件夹下,再做对jerry2,jerry3的免密验证配置,中间输入一下yes和jerry2和jerry3的密码。
ssh-copy-id -i ./id_rsa.pub -p22 root@jerry2
ssh-copy-id -i ./id_rsa.pub -p22 root@jerry3
同样的对jerry2,jerry3做同样的上述操作,记得换下名字。
4. 上传需要安装的jdk,hadoop,zookeeper,kafka安装包
这里我使用xftp上传安装包,先建立连接

上传文件
先建立install文件夹
cd /opt
mkdir install
mkdir bigdata
然后将文件上传至install文件夹

5. 编写用于虚拟机之间传输文件的脚本
先进入root目录,创建bin文件夹,并进入,创建脚本文件并打开
cd ~
mkdir bin
cd bin
touch xrsync
vi xrsync
编写脚本文件
#!/bin/bash
# 作用于文件传输
#1 获取输入参数个数,如果没有参数,退出
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
#2 获取文件名
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录的绝对路径
pdir=`cd -P $(dirname $p1);pwd`
echo pdir=$pdir
#4 获取当前用户名字
user=`whoami`
#5 将文件拷贝到目标机器
for host in jerry1 jerry2 jerry3
do
echo ------------- $host ---------------
rsync -av $pdir/$fname $user@$host:$pdir
done
修改下xrsync脚本的权限
chmod 777 xrsync
安装下rsync
yum -y install rsync
执行脚本传输文件,就可以成功了。
[root@jerry1 .ssh]# xrsync /opt/install/
fname=install
pdir=/opt
-------------- jerry1 --------------------
sending incremental file list
sent 238 bytes received 17 bytes 510.00 bytes/sec
total size is 705,821,684 speedup is 2,767,928.17
-------------- jerry2 --------------------
sending incremental file list
install/
install/hadoop-2.6.0-cdh5.14.2.tar.gz
install/jdk-8u111-linux-x64.tar.gz
install/kafka_2.11-2.0.0.tgz
install/zookeeper-3.4.5-cdh5.14.2.tar.gz
sent 705,994,397 bytes received 96 bytes 94,132,599.07 bytes/sec
total size is 705,821,684 speedup is 1.00
-------------- jerry3 --------------------
sending incremental file list
install/
install/hadoop-2.6.0-cdh5.14.2.tar.gz
install/jdk-8u111-linux-x64.tar.gz
install/kafka_2.11-2.0.0.tgz
install/zookeeper-3.4.5-cdh5.14.2.tar.gz
sent 705,994,397 bytes received 96 bytes 108,614,537.38 bytes/sec
total size is 705,821,684 speedup is 1.00
这样就把所有的安装包都发送到集群中剩下的机器了,同时也可以使用这个脚本去传输其他各种文件。
6. 安装jdk
先解压安装包
cd /opt/install/
[root@jerry1 install]# ls
hadoop-2.6.0-cdh5.14.2.tar.gz kafka_2.11-2.0.0.tgz
jdk-8u111-linux-x64.tar.gz zookeeper-3.4.5-cdh5.14.2.tar.gz
[root@jerry1 install]# tar -zxf jdk-8u111-linux-x64.tar.gz -C /opt/bigdata/
[root@jerry1 install]# cd /opt/bigdata/
[root@jerry1 bigdata]# mv jdk1.8.0_111/ jdk180
将解压好的jdk传输给其他节点
xrsync jdk180
配置环境变量
1.创建配置文件
cd /etc/profile.d
touch env.sh
vi env.sh
2.加入jdk配置
export JAVA_HOME=/opt/bigdata/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3.给集群中所有其他主机传输一下env.sh配置文件
xrsync env.sh
3.给集群中每台主机source一下配置文件,使它生效,所有主机的jdk安装就都完成了
source /etc/profile.d/env.sh
7.安装hadoop
解压hadoop
[root@jerry1 install]# tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz -C /opt/bigdata/
[root@jerry1 install]# mv /opt/bigdata/hadoop-2.6.0-cdh5.14.2/ /opt/bigdata/hadoop260
修改hadoop的jdk路径配置
进入hadoop的etc文件夹下的hadoop文件夹中,对一下几个文件进行修改:
vi hadoop-env.sh

vi mapred-env.sh

vi yarn-env.sh

修改slaves
vi slaves
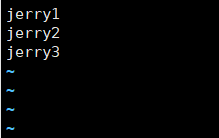
配置hadoop节点等信息
按下图来配置hadoop各个服务所在节点

配置 core-site.xml ,配置了namenode所在节点。
vi core-site.xml
"1.0" encoding="UTF-8"?>
-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
fs.defaultFS</name>
hdfs://192.168.126.131:9000</value>
</property>
hadoop.tmp.dir</name>
/opt/bigdata/hadoop260/hadoopdata</value>
</property>
hadoop.proxyuser.root.hosts</name>
*</value>
</property>
hadoop.proxyuser.root.groups</name>
*</value>
</property>
</configuration>
配置 hdfs-site.xml ,配置了secondaryNamenode节点。
vi hdfs-site.xml
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
dfs.replication</name>
1</value>
</property>
dfs.namenode.secondary.http-address</name>
jerry3:50090</value>
</property>
</configuration>
配置mapred-site.xml,配置了MapReduce任务监控节点。
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<!-- Put site-specific property overrides in this file. -->
mapreduce.framework.name</name>
yarn</value>
</property>
mapreduce.jobhistory.address</name>
jerry1:10020</value>
</property>
mapreduce.jobhistory.webapp.address</name>
jerry1:19888</value>
</property>
</configuration>
配置yarn-site.xml,配置了yarn的ResourceManager所在节点
vi yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据方式 -->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
yarn.resourcemanager.hostname</name>
jerry2</value>
</property>
<!-- 日志聚集功能使用 -->
yarn.log-aggregation-enable</name>
true</value>
</property>
<!-- 日志保留时间设置7天 -->
yarn.log-aggregation.retain-seconds</name>
604800</value>
</property>
</configuration>
配置环境变量
vi /etc/profile.d/env.sh
export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
将环境变量文件发送到集群主机
xrsync /etc/profile.d/env.sh
各个主机都要source文件,才可以生效
source /etc/profile.d/env.sh
将hadoop发送到各主机
xrsync /opt/bigdata/hadoop260
一定要先格式化namenode
hadoop namenode -format
然后我们在namenode的节点jerry1启动
start-dfs.sh
在ResourceManager的节点jerry2启动
start-yarn.sh
在各节点jps查看是否与上述节点配置图一样启动了相应的服务,都启动了就成功了
这里可以编写一个一次查看所有节点的脚本文件
cd ~
cd bin
[root@jerry1 bin]# touch showJps.sh
[root@jerry1 bin]# vi showJps.sh
#!/bin/bash
# 功能是可以输入一个命令可以循环在3个节点都执行一遍
for host in jerry1 jerry2 jerry3
do
echo ------------------------ $host -------------------------------
ssh $host "$*"
done
记得修改权限
chmod 777 showJps.sh
最后运行脚本,我们可以看到3个节点各运行了什么服务
[root@jerry1 bin]# showJps.sh jps
------------------------ jerry1 -------------------------------
12881 DataNode
13249 Jps
13108 NodeManager
12757 NameNode
------------------------ jerry2 -------------------------------
12130 DataNode
12243 ResourceManager
12525 NodeManager
12670 Jps
------------------------ jerry3 -------------------------------
11521 DataNode
11619 SecondaryNameNode
11827 Jps
11688 NodeManager
8. 安装zookeeper
zookeeper解压,改名
tar -zxf zookeeper-3.4.5-cdh5.14.2.tar.gz -C /opt/bigdata/
cd /opt/bigdata
mv zookeeper-3.4.5-cdh5.14.2/ zk345
创建zkData,写入当前节点id
mkdir zkData
cd ./zkData
touch myid
vi mydi
只需要写入当前id即可,这里jerry1我写1

修改zookeeper配置文件
cd /conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
配置data路径

新增server,根据你的虚拟机和之前配置的myid来新增,我新增的就是1,2,3

将zookeeper发送到集群各主机,并根据主机改变zkData中myid内的值

[root@jerry2 zkData]# vi myid
[root@jerry3 zkData]# vi myid
配置环境变量
vi /etc/profile.d/env.sh
添加一下变量
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
发送给集群所有主机
xrsync /etc/profile.d/env.sh
每个节点都source一下,生效
source /etc/profile.d/env.sh
编写一个启动所有节点zkServer的脚本
去root/bin目录下
touch zkop.sh
vi zkop.sh
写入以下内容
#!/bin/bash
# start stop status
case $1 in
"start"){
for host in jerry1 jerry2 jerry3
do
echo -------------- $host启动zk --------------
ssh $host "/opt/bigdata/zk345/bin/zkServer.sh start"
done
};;
"stop"){
for host in jerry1 jerry2 jerry3
do
echo -------------- $host关闭zk --------------
ssh $host "/opt/bigdata/zk345/bin/zkServer.sh stop"
done
};;
"status"){
for host in jerry1 jerry2 jerry3
do
echo -------------- $host的zk状态 --------------
ssh $host "/opt/bigdata/zk345/bin/zkServer.sh status"
done
};;
esac
启动脚本,就可以看到所有节点zookeeper服务起来了
zkop.sh start
-------------- jerry1启动zk --------------
JMX enabled by default
Using config: /opt/bigdata/zk345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
-------------- jerry2启动zk --------------
JMX enabled by default
Using config: /opt/bigdata/zk345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
-------------- jerry3启动zk --------------
JMX enabled by default
Using config: /opt/bigdata/zk345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
9. 安装kafka
解压和改名
tar -zxf /opt/install/kafka_2.11-2.0.0.tgz -C /opt/bigdata/
mv /opt/bigdata/kafka_2.11-2.0.0/ /opt/bigdata/kafka211
修改kafka配置文件
先在kafka根目录创建logs文件夹
mkdir logs
再进入config文件下,打开server.properties,根据jerry1,所以broker.id写为1,同时添加topic的可删除配置,再配置刚才创建的logs文件夹路径,(注意broker.id在不同节点需要改变,等会发送给集群各主机的时候需要改变id)。


broker.id=1
delete.topic.enable=true
log.dirs=/opt/bigdata/kafka211/logs
配置kafka环境变量
vi /etc/profile.d/env.sh
export KAFKA_HOME=/opt/bigdata/kafka211
export PATH=$PATH:$KAFKA_HOME/bin
发送给集群各主机,记得各主机都要source一下
xrsync /etc/profile.d/env.sh
xrsync kafka211/
source /etc/profile.d/env.sh #source*3
编写一个同时启动集群所有主机kafka服务的脚本
进入root/bin文件夹下
touch kfkop.sh
[root@jerry1 bin]# vi kfkop.sh
代码如下:
#!/bin/bash
case $1 in
"start"){
for host in jerry1 jerry2 jerry3
do
echo ------------- $host 启动kafka---------------
ssh $host "/opt/bigdata/kafka211/bin/kafka-server-start.sh -daemon /opt/bigdata/kafka211/config/server.properties"
done
};;
"stop"){
for host in jerry1 jerry2 jerry3
do
echo ------------- $host 关闭kafka--------------- ssh $host "/opt/bigdata/kafka211/bin/kafka-server-stop.sh"
done
};;
esac
改变脚本权限
chmod 777 kfkop.sh
启动命令
kfkop.sh start
------------- jerry1 启动kafka---------------
------------- jerry2 启动kafka---------------
------------- jerry3 启动kafka---------------
10. 到此就结束了,可以通过showJps脚本查看集群所有主机启动的服务,服务完全,如图所示,就说明成功了。

所需安装包
https://pan.baidu.com/s/1tVpuMf1oWY3oofUGEWgSQA 提取码:be2w