MADlib——基于SQL的数据挖掘解决方案(6)——数据转换之矩阵分解
矩阵分解(Matrix Factorization)简单说就是将原始矩阵拆解为数个矩阵的乘积。在一些大型矩阵计算中,其计算量大,化简繁杂,使得计算非常复杂。如果运用矩阵分解,将大型矩阵分解成简单矩阵的乘积形式,则可大大降低计算的难度以及计算量。这就是矩阵分解的主要目的。而且,对于矩阵的秩的问题,奇异性问题,特征值问题,行列式问题等等,通过矩阵分解后都可以清晰地反映出来。另一方面,对于那些大型的数值计算问题,矩阵的分解方式以及分解过程也可以作为计算的理论依据。MADlib提供了低秩矩阵分解和奇异值分解两种矩阵分解方法。
一、低秩矩阵分解
矩阵中的最大不相关向量的个数,叫做矩阵的秩,可通俗理解为数据有秩序的程度。秩可以度量相关性,而向量的相关性实际上又带有了矩阵的结构信息。如果矩阵之间各行的相关性很强,那么就表示这个矩阵实际可以投影到更低维度的线性子空间,也就是用几个特征就可以完全表达了,它就是低秩的。所以我们可以总结的一点是:如果矩阵表达的是结构性信息,例如图像、用户推荐表等,那么这个矩阵各行之间存在一定的相关性,这个矩阵一般就是低秩的。
如果A是一个m行n列的数值矩阵,rank(A)是A的秩,假如rank(A)远小于m和n,则我们称A是低秩矩阵。低秩矩阵每行或每列都可以用其它的行或列线性表示,可见它包含大量的冗余信息。利用这种冗余信息,可以对缺失数据进行恢复,也可以对数据进行特征提取。
MADlib的lmf模块可用两个低维度矩阵的乘积逼近一个稀疏矩阵,逼近的目标就是让预测矩阵和原来矩阵之间的误差平方(RMSE)最小,从而实现所谓“潜在因子模型”。lmf模块提供的低秩矩阵分解函数,就是为任意稀疏矩阵A,找到两个矩阵U和V,使得![]() 的值最小化,其中
的值最小化,其中![]() 代表Frobenius范数。换句话说,只要求得U和V,就可以用它们的乘积来近似模拟A。因此低秩矩阵分解有时也叫UV分解。假设A是一个m x n的矩阵,则U和V分别是m x r和n x r的矩阵,并且1<=r<=min(m,n)。
代表Frobenius范数。换句话说,只要求得U和V,就可以用它们的乘积来近似模拟A。因此低秩矩阵分解有时也叫UV分解。假设A是一个m x n的矩阵,则U和V分别是m x r和n x r的矩阵,并且1<=r<=min(m,n)。
1. MADlib低秩矩阵分解函数
MADlib的lmf_igd_run函数能够实现低秩矩阵分解功能。本节介绍MADlib低秩矩阵分解函数的语法和参数含义,下一节用一个实例说明该函数的具体用法。
(1) lmf_igd_run函数语法
lmf_igd_run( rel_output,
rel_source,
col_row,
col_column,
col_value,
row_dim,
column_dim,
max_rank,
stepsize,
scale_factor,
num_iterations,
tolerance )(2) 参数说明
参数名称 |
数据类型 |
描述 |
rel_output |
TEXT |
输出表名。输出的矩阵U和V是以二维数组类型存储。RESULT AS ( matrix_u DOUBLE PRECISION[], matrix_v DOUBLE PRECISION[], rmse DOUBLE PRECISION) 行i对应的向量是matrix_u[i:i][1:r],列j对应的向量是matrix_v[j:j][1:r]。 |
rel_source |
TEXT |
输入表名。输入矩阵的格式如下: {TABLE|VIEW} input_table ( row INTEGER, col INTEGER, value DOUBLE PRECISION) 输入包含一个描述矩阵的表,数据被指定为(row、column、value)。输入矩阵的行列值大于等于1,并且不能有NULL值。 |
col_row |
TEXT |
包含行号的列名。 |
col_column |
TEXT |
包含列号的列名。 |
col_value |
FLOAT8 |
(row, col)位置对应的值。 |
row_dim(可选) |
INTEGER |
指示矩阵中的行数,缺省为:“SELECT max(col_row) FROM rel_source”。 |
column_dim(可选) |
INTEGER |
指示矩阵中的列数,缺省为:“SELECT max(col_col) FROM rel_source”。 |
max_rank |
INTEGER |
期望逼近的秩数。 |
stepsize(可选) |
FLOAT8 |
缺省值为0.01。超参数,决定梯度下降法的步长。 |
scale_factor(可选) |
FLOAT8 |
缺省值为0.1。超参数,决定初始缩放因子。 |
num_iterations(可选) |
INTEGER |
缺省值为10。不考虑收敛情况下的最大迭代次数。 |
tolerance(可选) |
FLOAT8 |
缺省值为0.0001,收敛误差,小于该误差时停止迭代。 |
表1 lmf_igd_run函数参数说明
矩阵分解一般不用数学上直接分解的办法,尽管直接分解出来的精度很高,但是效率实在太低!矩阵分解往往会转化为一个优化问题,通过迭代求局部最优解。但是有个问题是,通常原矩阵的稀疏度很大,分解很容易产生过拟合(overfitting),简单说就是为了迁就一些错误的偏僻的值导致整个模型错误的问题。所以现在的方法是在目标函数中增加一项正则化(regularization)参数,来避免过拟合问题。
因此,一般的矩阵分解的目标函数(或者称为损失函数,loss function)为:
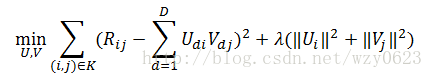
前一项是预测后矩阵和原矩阵的误差,这里计算只针对原矩阵中的非空项。后一项就是正则化因子,用来解决过度拟合的问题。这个优化问题求解的就是分解之后的U、V矩阵的潜在因子向量。
madlib.lmf_igd_run函数使用随机梯度下降法(stochastic gradient descent)求解这个优化问题,迭代公式为:
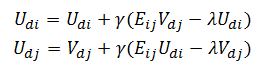
其中,![]() 。
。
γ是学习速率,对应stepsize参数;λ是正则化系数,对应scale_factor参数。这是两个超参数,对于最终结果影响极大。在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,以提高学习的性能和效果。γ的大小不仅会影响到执行时间,还会影响到结果的收敛性。γ太大的话会导致结果发散,一般都会把γ取得很小,不同的数据集取得值不同,但大概是0.001这个量级。这样的话训练时间会长一些,但结果会比较好。λ的值一般也比较小,大概取0.01这个量级。
迭代开始前,需要对U、V的特征向量赋初值,这个初值很重要,会严重地影响到计算速度。一般的做法是在均值附近产生随机数作为初值。也正是由于这个原因,从数据库层面看,madlib.lmf_igd_run函数是一个非确定函数,也就是说,同样一组输入数据,多次执行函数生成的结果数据是不同的。迭代结束的条件一般是损失函数的值小于了某一个阈值(由tolerance参数指定),或者到达指定的最大迭代次数(由num_iterations参数指定)。
2. 低秩矩阵分解函数示例
我们将通过一个简单示例,说明如何利用madlib.lmf_igd_run函数实现潜在因子(Latent Factor)推荐算法。该算法的主要思想是:每个用户(user)都有自己的偏好,比如一个歌曲推荐应用中,用户A喜欢带有小清新的、吉他伴奏的、王菲等元素,如果一首歌(item)带有这些元素,那么就将这首歌推荐给该用户,也就是用元素去连接用户和歌曲。每个人对不同的元素偏好不同,而每首歌包含的元素也不一样。
(1) 潜在因子矩阵
我们希望能找到这样两个矩阵:
- 潜在因子-用户矩阵Q,表示不同的用户对于不同元素的偏好程度,1代表很喜欢,0代表不喜欢。比如图1所示:
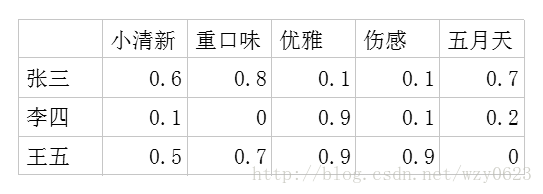
图1 潜在因子-用户矩阵
- 潜在因子-歌曲矩阵P,表示每首歌曲含有各种元素的成分,比如图2中,音乐A是一个偏小清新的音乐,含有小清新这个潜在因子的成分是0.9,重口味的成分是0.1,优雅的成分是0.2等等。
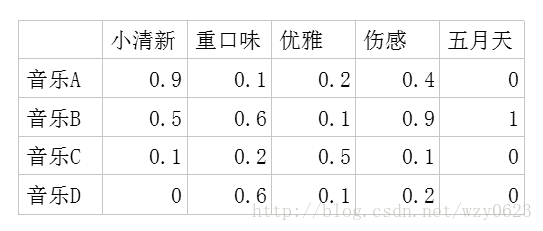
图2 潜在因子-音乐矩阵
利用这两个矩阵,我们能得出张三对音乐A的喜欢程度是:张三对小清新的偏好*音乐A含有小清新的成分+对重口味的偏好*音乐A含有重口味的成分+对优雅的偏好*音乐A含有优雅的成分+……即:0.6*0.9+0.8*0.1+0.1*0.2+0.1*0.4+0.7*0=0.68。
每个用户对每首歌都这样计算可以得到不同用户对不同歌曲的评分矩阵![]() ,如图3所示。注意,这里的波浪线表示的是估计的评分,接下来我们还会用到不带波浪线的R表示实际的评分矩阵。
,如图3所示。注意,这里的波浪线表示的是估计的评分,接下来我们还会用到不带波浪线的R表示实际的评分矩阵。
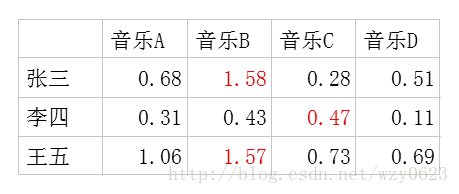
图3 估计的评分矩阵
因此我们对张三推荐四首歌中得分最高的B,对李四推荐得分最高的C,王五推荐B。如果用矩阵表示即为:
![]()
(2) 如何得到潜在因子
潜在因子是怎么得到的呢?面对大量用户和歌曲,让用户自己给歌曲分类并告诉我们其偏好系数显然是不现实的,事实上我们能获得的只有用户行为数据。假定使用以下量化标准:单曲循环=5, 分享=4, 收藏=3, 主动播放=2 , 听完=1, 跳过=-2 , 拉黑=-5,则在分析时能获得的实际评分矩阵R,也就是输入矩阵如图4所示:
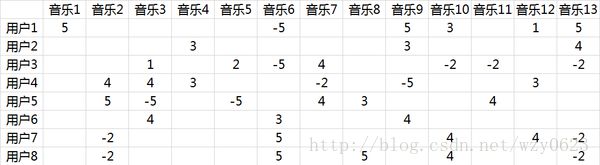
图4 实际评分矩阵
推荐系统的目标就是预测出空白对应位置的分值。推荐系统基于这样一个假设:用户对项目的打分越高,表明用户越喜欢。因此,预测出用户对未评分项目的评分后,根据分值大小排序,把分值高的项目推荐给用户。这是个非常稀疏的矩阵,因为大部分用户只听过全部歌曲中很少一部分。如何利用这个矩阵去找潜在因子呢?这里主要应用到的就是矩阵的UV分解,如图5所示。
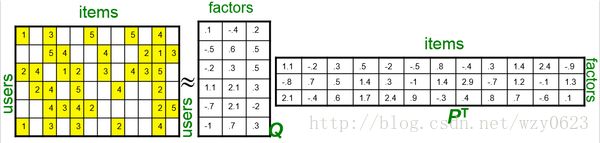
图5 矩阵的UV分解
矩阵分解的想法来自于矩阵补全,即依据一个矩阵给定的部分数据,把缺失的值补全。一般假设原始矩阵是低秩的,我们可以从给定的值来还原这个矩阵。由于直接求解低秩矩阵从算法以及参数的复杂度来说效率很低,因此常用的方法是直接把原始矩阵分解成两个子矩阵相乘。例如将图5所示的评分矩阵分解为两个低维度的矩阵,用Q和P两个矩阵的乘积去估计实际的评分矩阵,而且我们希望估计的评分矩阵和实际的评分矩阵不要相差太多,也就是求解矩阵分解的目标函数:
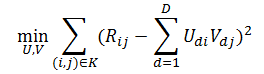
如前所述,实际应用中,往往还要加上2范数的罚项,然后利用梯度下降法就可以求得这P,Q两个矩阵的估计值。例如我们上面给出的那个例子可以分解成为这样两个矩阵(图6):
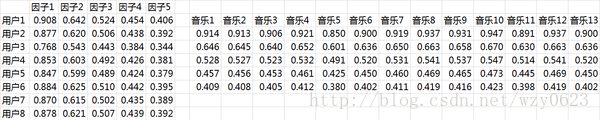
图6 分解后得到的UV矩阵
这两个矩阵相乘就可以得到估计的得分矩阵(图7):
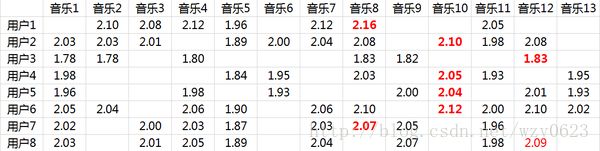
图7 预测矩阵
将用户已经听过的音乐剔除后,选择分数最高音乐的推荐给用户即可(红体字)。在这个例子里面用户7和用户8有强的相似性(图8):
![]()
图8 评分相似的用户
从推荐的结果来看,正好推荐的是对方评分较高的音乐(图9):
![]()
图9对相似用户的推荐
该算法假定我们要恢复的矩阵是低秩的,实际上这种假设是十分合理的,比如一个用户对某歌曲的评分是其他用户对这首歌曲评分的线性组合。所以,通过低秩重构就可以预测用户对其未评价过的音乐的喜好程度。从而对矩阵进行填充。
(3) 利用madlib.lmf_igd_run函数实现
- 建立输入表并生成输入数据
-- 创建用户索引表
drop table if exists tbl_idx_user;
create table tbl_idx_user (user_idx bigserial, userid varchar(10));
-- 创建音乐索引表
drop table if exists tbl_idx_music;
create table tbl_idx_music (music_idx bigserial, musicid varchar(10));
-- 创建用户行为表
drop table if exists lmf_data;
create table lmf_data (
row int,
col int,
val float8
);
-- 生成输入表数据
-- 用户表
insert into tbl_idx_user (userid)
values ('u1'),('u2'),('u3'),('u4'),('u5'),('u6'),('u7'),('u8'),('u9'),('u10');
-- 音乐表
insert into tbl_idx_music (musicid)
values ('m1'),('m2'),('m3'),('m4'),('m5'),('m6'),('m7'),('m8'),('m9'),('m10'),('m11'),('m12'),('m13'),('m14'),('m15');
-- 用户行为表
insert into lmf_data values (1, 1, 5), (1, 6, -5), (1, 9, 5), (1, 11, 3), (1, 12, 1), (1, 13, 5);
insert into lmf_data values (2, 4, 3), (2, 9, 3), (2, 13, 4);
insert into lmf_data values (3, 3, 1), (3, 5, 2), (3, 6, -5), (3, 7, 4), (3, 11, -2), (3, 12, -2), (3, 13, -2);
insert into lmf_data values (4, 2, 4), (4, 3, 4), (4, 4, 3), (4, 7, -2), (4, 9, -5), (4, 12, 3);
insert into lmf_data values (6, 2, 5), (6, 3, -5), (6, 5, -5), (6, 7, 4), (6, 8, 3), (6, 11, 4);
insert into lmf_data values (7, 3, 4), (7, 6, 3), (7, 9, 4);
insert into lmf_data values (8, 2, -2), (8, 6, 5), (8, 11, 4), (8, 12, 4), (8, 13, -2);
insert into lmf_data values (9, 2, -2), (9, 6, 5), (9, 8, 5), (9, 11, 4), (9, 13, -2); 说明:
- 从前面的解释可以看到,推荐矩阵的行列下标分别表示用户和歌曲。然而在业务系统中,userid和musicid很可能不是按从1到N的规则顺序生成的,因此通常需要建立矩阵下标值与业务表ID之间的映射关系,这里使用HAWQ的BIGSERIAL自增数据类型对应推荐矩阵的索引下标。
- 在生成原始数据时对图4的例子做了适当的修改。用户表中u5和u10用户没有给任何歌曲打分,而音乐表中的m10、m14、m15无评分。我们希望看到的结果是,除了与打分行为相关的用户和歌曲以外,也能为u5、u10推荐歌曲,并可能将m10、m14、m15推荐给用户。
2. 调用lmf_igd_run函数分解矩阵
-- 执行低秩矩阵分解
drop table if exists lmf_model;
select madlib.lmf_igd_run( 'lmf_model',
'lmf_data',
'row',
'col',
'val',
11,
16,
7,
0.1,
1,
10,
1e-9
); 说明:
- 最大行列数可以大于实际行列数,如这里传入的参数是11和16,而实际的用户数与歌曲数是10和15。
- max_rank参数为最大秩数,要小于min(row_dim, column_dim),否则函数会报错:
NOTICE: Matrix lmf_data to be factorized: 11 x 16 ERROR: plpy.SPIError: Function "madlib.lmf_igd_transition(double precision[],integer,integer,double precision,double precision[],integer,integer,integer,double precision,double precision)": Invalid parameter: max_rank >= row_dim || max_rank >= column_dim (plpython.c:4663) - 最大秩数实际可以理解为最大的潜在因子数,也就是例子中的最大量化指标个数。本例中共有7个指标,因此max_rank参数传7。
- stepsize和scale_factor参数对于结果的影响巨大,而且不同的学习数据,参数值也不同。也就是说超参数的值是与输入数据相关的。在本例中,使用缺省值时RMSE很大。经过反复测试,对于测试矩阵,stepsize和scale_factor分别为0.1和1时误差相对较小。
函数执行结果的控制台输出如下:
NOTICE: Matrix lmf_data to be factorized: 11 x 16
NOTICE: CREATE TABLE will create implicit sequence "lmf_model_id_seq" for serial column "lmf_model.id"
CONTEXT: SQL statement "
CREATE TABLE lmf_model (
id SERIAL,
matrix_u DOUBLE PRECISION[],
matrix_v DOUBLE PRECISION[],
rmse DOUBLE PRECISION)"
PL/pgSQL function "lmf_igd_run" line 49 during exception cleanup
NOTICE:
Finished low-rank matrix factorization using incremental gradient
DETAIL:
* table : lmf_data (row, col, val)
Results:
* RMSE = 0.0032755443518
Output:
* view : SELECT * FROM lmf_model WHERE id = 1
lmf_igd_run
-------------
1
(1 row)
Time: 2477.339 ms可以看到,误差值为0.0033,分解用时2秒多。
3. 检查结果
从上一步的输出看到,lmf_igd_run()函数返回的模型ID是1,需要用它作为查询条件。
select array_dims(matrix_u) as u_dims, array_dims(matrix_v) as v_dims
from lmf_model
where id = 1; 结果:
u_dims | v_dims
-------------+-------------
[1:11][1:7] | [1:16][1:7]
(1 row)
Time: 158.163 ms 结果表中包含分解成的两个矩阵,U(用户潜在因子)矩阵11行7列,V(歌曲潜在因子)矩阵16行7列。
4. 查询结果值
select matrix_u, matrix_v from lmf_model where id = 1;5. 矩阵相乘生成推荐矩阵
MADlib的矩阵相乘函数是matrix_mult,支持稠密和稀疏两种矩阵表示。稠密矩阵需要指定矩阵对应的表名、row和val列,稀疏矩阵需要指定矩阵对应的表名、row、col和val列。现在要将lmf_igd_run函数输出的矩阵装载到表中再执行矩阵乘法。这里使用稀疏形式,只要将二维矩阵的行、列、值插入表中即可。
-- 建立用户稀疏矩阵表
drop table if exists mat_a_sparse;
create table mat_a_sparse as
select d1,d2,matrix_u[d1][d2] val from
(select matrix_u,
generate_series(1,array_upper(matrix_u,1)) d1,
generate_series(1,array_upper(matrix_u,2)) d2
from lmf_model) t;
-- 建立音乐稀疏矩阵表
drop table if exists mat_b_sparse;
create table mat_b_sparse as
select d1,d2,matrix_v[d1][d2] val from
(select matrix_v,
generate_series(1,array_upper(matrix_v,1)) d1,
generate_series(1,array_upper(matrix_v,2)) d2
from lmf_model) t;
-- 执行矩阵相乘
drop table if exists matrix_r;
select madlib.matrix_mult('mat_a_sparse', 'row=d1, col=d2, val=val',
'mat_b_sparse', 'row=d1, col=d2, val=val, trans=true',
'matrix_r'); 结果:
matrix_mult
-------------
(matrix_r)
(1 row)
Time: 5785.798 ms这两个矩阵(11 x 3与16 x 3)相乘用时将近6秒。生成的结果表是稠密形式的11 x 16矩阵,这就是我们需要的推荐矩阵。为了方便与原始的索引表关联,将结果表转为稀疏表示。
drop table if exists matrix_r_sparse;
select madlib.matrix_sparsify('matrix_r', 'row=d1, val=val',
'matrix_r_sparse', 'col=d2, val=val'); 结果:
matrix_sparsify
-------------------
(matrix_r_sparse)
(1 row)
Time: 2252.413 ms 最后与原始的索引表关联,过滤掉用户已经已经听过的歌曲,选择分数最高的歌曲推荐。
select t2.userid,t3.musicid,t1.val
from (select d1,d2,val,row_number() over (partition by d1 order by val desc) rn
from matrix_r_sparse t1
where not exists (select 1 from lmf_data t2 where t1.d1 = t2.row and t1.d2 = t2.col)) t1,
tbl_idx_user t2, tbl_idx_music t3
where t1.rn = 1 and t2.user_idx= t1.d1 and t3.music_idx = t1.d2
order by t2.user_idx; 结果:
userid | musicid | val
--------+---------+------------------
u1 | m7 | 4.46508576767804
u2 | m1 | 3.45259331270197
u3 | m14 | 1.21085044974838
u4 | m15 | 2.87854763370041
u5 | m12 | 3.07991997971589
u6 | m9 | 2.8073075471921
u7 | m8 | 5.70400322091688
u8 | m8 | 4.229015803831
u9 | m12 | 4.14559001844873
u10 | m8 | 2.16407771238165
(10 rows)
Time: 743.415 ms 这就是为每个用户推荐的歌曲。可以看到,用户u5、u10分别推荐了m12和m8,m14和m15也推荐给了用户。
MADlib的低秩矩阵分解函数可以作为推荐类应用的算法实现。从函数调用角度看,madlib.lmf_igd_run函数是一个非确定函数,也就是说,同样一组输入数据,函数生成的结果数据却不同,结果就是对于同样的输入数据,每次的推荐可能不一样。在海量数据的应用中,推荐可能需要计算的是一个几亿 x 几亿的大型矩阵,如何保证推荐系统的性能将成为巨大挑战。
二、奇异值分解
1. 奇异值分解简介
低秩矩阵分解是用两个矩阵的乘积近似还原一个低秩矩阵。MADlib还提供了另一种矩阵分解方法,即奇异值分解。奇异值分解简称SVD(Singular Value Decomposition),可以理解为将一个比较复杂的矩阵用更小更简单的三个子矩阵的相乘来表示,这三个小矩阵描述了原矩阵重要的特性。SVD的用处有很多,比如推荐系统、数据降维等。
要理解奇异值分解,先要知道什么是特征值和特征向量。m×n矩阵M的特征值和特征向量分别是标量值λ和向量u,它们是如下方程的解:
Mu=λu
换言之,特征向量(eigenvector)是被M乘时除量值外并不改变的向量。特征值(eigenvalue)是缩放因子。该方程也可以写成(M-λE)u=0,其中E是单位矩阵。
对于方阵,可以使用特征值和特征向量分解矩阵。假设M是n×n矩阵,具有n个独立的(正交的)特征向量![]() 和n个对应的特征值
和n个对应的特征值![]() 。设U是矩阵,它的列是这些特征向量,即
。设U是矩阵,它的列是这些特征向量,即![]() ;并且Λ是对角矩阵,它的对角线元素是
;并且Λ是对角矩阵,它的对角线元素是![]() ,1≤i≤n。则M可以被表示为:
,1≤i≤n。则M可以被表示为:
![]()
这样,M可以被分解成3个矩阵的乘积。U称为特征向量矩阵(eigenvector matrix),而Λ称为特征值矩阵(eigenvaluematrix)。
更一般地,任意矩阵都可以用类似的方法分解。对于一个M x N(M>=N)的矩阵M,存在以下的SVD分解:
![]()
其中U是m×m矩阵,∑是m×n矩阵,V是n×n矩阵。U和V是标准正交矩阵,即它们的列向量都是单位长度,并且相互正交。这样,![]() ,
,![]() ,E是单位矩阵。∑是对角矩阵,其对角线元素非负,并且被排好序,使得较大的元素先出现,即
,E是单位矩阵。∑是对角矩阵,其对角线元素非负,并且被排好序,使得较大的元素先出现,即![]() 。
。
V的列向量![]() 是右奇异向量(rightsingular vector),U的列向量是左奇异向量(leftsingular vector)。奇异值矩阵(singular value matrix)∑的对角线元素通常记作
是右奇异向量(rightsingular vector),U的列向量是左奇异向量(leftsingular vector)。奇异值矩阵(singular value matrix)∑的对角线元素通常记作![]() ,称为M的奇异值(singular value)。最多存在rank(M)≤min(m,n)个非零奇异值。
,称为M的奇异值(singular value)。最多存在rank(M)≤min(m,n)个非零奇异值。
可以证明![]() 的特征向量是右奇异向量(即V的列),而
的特征向量是右奇异向量(即V的列),而![]() 的特征向量是左奇异向量(即U的列)。
的特征向量是左奇异向量(即U的列)。![]() 和
和![]() 的非零特征值是
的非零特征值是![]() ,即奇异值的平方。方阵的特征值分解可以看作奇异值分解的一个特例。
,即奇异值的平方。方阵的特征值分解可以看作奇异值分解的一个特例。
矩阵的奇异值分解也可以用下面的等式表示。注意,尽管看上去像点积,但它并不是点积,其结果是秩为1的m×n矩阵。
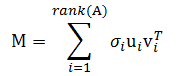
这种表示的重要性是每个矩阵都可以表示成秩为1矩阵的以奇异值为权重的加权和。由于以非递增序排列的奇异值通常下降很快,因此有可能使用少量奇异值和奇异值向量得到矩阵的很好的近似。这对于维归约是很有用的。
数据矩阵的SVD分解具有如下性质。
- 属性中的模式被右奇异向量(即V的列)捕获。
- 对象中的模式被左奇异向量(即U的列)捕获。
- 矩阵M可以通过依次取公式
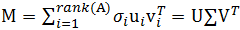 中的项,以最优的方式不断逼近。就是说奇异值越大,该奇异值和其相关联的奇异向量决定矩阵的比例越大。
中的项,以最优的方式不断逼近。就是说奇异值越大,该奇异值和其相关联的奇异向量决定矩阵的比例越大。
很多情况下,前10%甚至更少的奇异值的平方就占全部奇异值平方的90%以上了,因此可以用前k个奇异值来近似描述原矩阵:
![]()
k的取值有下面的公式决定:
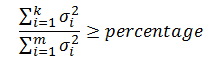
其中percentage称为“奇异值平方和占比的阈值”,一般取90%,k是一个远小于m和n的值,这样也就达到了降维的目的。
2. MADlib奇异值分解函数
MADlib的SVD函数可以对稠密矩阵和稀疏矩阵进行奇异值因式分解,并且还提供了一个稀疏矩阵的本地高性能实现函数。
(1) 稠密矩阵的SVD函数
语法:
svd( source_table,
output_table_prefix,
row_id,
k,
n_iterations,
result_summary_table );参数:
参数名称 |
数据类型 |
描述 |
source_table |
TEXT |
源表名(稠密矩阵数据表)。 |
output_table_prefix |
TEXT |
指定输出表名的前缀。 |
row_id |
TEXT |
代表行ID的列名。 |
k |
INTEGER |
计算的奇异值个数。 |
n_iterations(可选) |
INTEGER |
运行的迭代次数,必须在[k, 列维度数]范围内。 |
result_summary_table(可选) |
TEXT |
存储结果摘要的表的名称。 |
表2 svd函数参数说明
source_table表中含有一个row_id列标识每一行,从数字1开始。其它列包含矩阵的数据。可以使用两种稠密格式的任何一个,例如下面示例的2 x 2矩阵。
格式一:
row_id col1 col2
row1 1 1 0
row2 2 0 1
格式二:
row_id row_vec
row1 1 {1, 0}
row2 2 {0, 1}(2) 稀疏矩阵的SVD函数
表示为稀疏格式的矩阵使用此函数。为了高效计算,在奇异值分解操作之前,输入矩阵会被转换为稠密矩阵。
语法:
svd_sparse( source_table,
output_table_prefix,
row_id,
col_id,
value,
row_dim,
col_dim,
k,
n_iterations,
result_summary_table );参数:
参数名称 |
数据类型 |
描述 |
source_table |
TEXT |
源表名(稀疏矩阵数据表)。 |
output_table_prefix |
TEXT |
指定输出表名的前缀。 |
row_id |
TEXT |
包含行下标的列名。 |
col_id |
TEXT |
包含列下标的列名。 |
value |
TEXT |
包含值的列名。 |
row_dim |
INTEGER |
矩阵的行数。 |
col_dim |
INTEGER |
矩阵的列数。 |
k |
INTEGER |
计算的奇异值个数。 |
n_iterations(可选) |
INTEGER |
运行的迭代次数,必须在[k, 列维度数]范围内。 |
result_summary_table(可选) |
TEXT |
存储结果摘要的表的名称。 |
表3 svd_sparse函数参数说明
(3) 稀疏矩阵的本地实现SVD函数
此函数在计算SVD时使用本地稀疏表示(不跨节点),能够更高效地计算稀疏矩阵,适合高度稀疏的矩阵。
语法:
svd_sparse_native( source_table,
output_table_prefix,
row_id,
col_id,
value,
row_dim,
col_dim,
k,
n_iterations,
result_summary_table );参数:同svd_sparse函数。
(4) 输出表
三个SVD函数的输出都是以下三个表:
- 左奇异矩阵表:表名为
_u。 - 右奇异矩阵表:表名为
_v。 - 奇异值矩阵表:表名为
_s。
左右奇异向量表的格式为:
- row_id:INTEGER类型。每个特征值对应的ID,降序排列。
- row_vec:FLOAT8[]类型。该row_id对应的特征向量元素,数组大小为k。
由于只有对角线元素是非零的,奇异值表采用稀疏表格式,其中的row_id和col_id都是从1开始。奇异值表具有以下列:
- row_id:INTEGER类型,第i个奇异值为i。
- col_id:INTEGER类型,第i个奇异值为i(与row_id相同)。
- value:FLOAT8类型,奇异值。
除了矩阵分解得到的三个输出表外,奇异值分解函数还会输出一个结果摘要表,存储函数执行的基本情况信息,具有以下列:
- rows_used:INTEGER类型,SVD计算使用的行数。
- exec_time:FLOAT8类型,计算SVD使用的总时间。
- iter:INTEGER类型,迭代运行次数。
- recon_error:FLOAT8类型,质量得分(近似精度)。计算公式为:
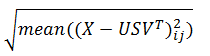
- relative_recon_error:FLOAT8类型,相对质量分数。计算公式为:

(5) 联机帮助
可以执行下面的查询获得SVD函数的联机帮助。
select madlib.svd();
-- 用法
select madlib.svd('usage');
-- 示例
select madlib.svd('example');3. 奇异值分解函数示例
本节我们使用稀疏SVD函数解决前面低秩矩阵分解示例中的歌曲推荐问题,但使用的不是潜在因子算法,而是另一个推荐系统的常用算法——协同过滤。
(1) 建立输入表并生成输入数据
建立用户索引表。
drop table if exists tbl_idx_user;
create table tbl_idx_user (user_idx bigserial, userid varchar(10)); 建立音乐索引表。
drop table if exists tbl_idx_music;
create table tbl_idx_music (music_idx bigserial, musicid varchar(10)); 建立用户行为数据表。
drop table if exists source_data;
create table source_data (
userid varchar(10), -- 用户ID
musicid varchar(10), -- 歌曲ID
val float8 -- 用户评分
); 建立用户评分矩阵表。
drop table if exists svd_data;
create table svd_data (
row_id int, -- 行ID,从1开始,表示用户
col_id int, -- 列ID,从1开始,表示作品
val float8 -- 分数
); 生成用户行为数据表数据。
insert into source_data values
('u1', 'm1', 5), ('u1', 'm6', -5),
('u2', 'm4', 3),
('u3', 'm3', 1), ('u3', 'm5', 2), ('u3', 'm7', 4),
('u4', 'm2', 4), ('u4', 'm3', 4), ('u4', 'm4', 3), ('u4', 'm7', -2),
('u5', 'm2', 5), ('u5', 'm3', -5), ('u5', 'm5', -5),
('u5', 'm7', 4), ('u5', 'm8', 3),
('u6', 'm3', 4), ('u6', 'm6', 3),
('u7', 'm2', -2), ('u7', 'm6', 5),
('u8', 'm2', -2), ('u8', 'm6', 5), ('u8', 'm8', 5),
('u9', 'm3', 1), ('u9', 'm5', 2), ('u9', 'm7', 4) ;从行为数据表生成用户索引表数据。
insert into tbl_idx_user (userid)
select distinct userid from source_data order by userid; 从行为数据表生成歌曲索引表数据。
insert into tbl_idx_music (musicid)
select distinct musicid from source_data order by musicid; 这里从业务数据生成有过打分行为的9个用户,以及被打过分的8首歌曲。注意查询中的排序子句,作用是便于业务ID与矩阵里的行列ID对应。
从行为数据表生成评分矩阵表数据。
insert into svd_data
select t1.user_idx, t2.music_idx, t3.val
from tbl_idx_user t1, tbl_idx_music t2, source_data t3
where t1.userid = t3.userid and t2.musicid = t3.musicid; 之所以要用用户行为表作为数据源,是因为矩阵中包含所有有过打分行为的用户和被打过分的歌曲,但不包括与没有任何打分行为相关的用户和歌曲。与低秩矩阵分解不同的是,如果包含无行为记录的用户或歌曲,会在计算余弦相似度时出现除零错误。正因如此,如果要用奇异值分解方法推荐没有被评过分的歌曲,或者为没有评分行为的用户形成推荐,需要做一些特殊处理,如将一个具有特别标志的虚拟用户或歌曲,用平均分数赋予初值,手工添加到评分矩阵表中。
(2) 执行SVD
调用svd_sparse_native函数。
drop table if exists svd_u, svd_v, svd_s, svd_summary cascade;
select madlib.svd_sparse_native
( 'svd_data', -- 输入表
'svd', -- 输出表名前缀
'row_id', -- 行索引列名
'col_id', -- 列索引列名
'val', -- 矩阵元素值
9, -- 矩阵行数
8, -- 矩阵列数
7, -- 计算的奇异值个数,小于等于最小行列数
NULL, -- 使用缺省的迭代次数
'svd_summary' -- 概要表名
);选择svd_sparse_native函数的原因是测试数据比较稀疏,矩阵实际数据只占1/3(25/72),该函数效率较高。这里给出的行、列、奇异值个数分别为9、8、7。svd_sparse_native函数要求行数大于等于列数,而奇异值个数小于等于列数,否则会报错。结果U、V矩阵的行数由实际的输入数据所决定,例如测试数据最大的行值为9,最大列值为8,则结果U矩阵的行数为9,V矩阵的行数为8,而不论行、列参数的值是多少。U、V矩阵的列数、S矩阵的行列数均由奇异值个数参数所决定。
查看SVD结果。
select array_dims(row_vec) from svd_u;
select * from svd_s order by row_id, col_id;
select array_dims(row_vec) from svd_v;
select * from svd_summary; 结果:
dm=# select array_dims(row_vec) from svd_u;
array_dims
------------
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
(9 rows)
dm=# select * from svd_s order by row_id, col_id;
row_id | col_id | value
--------+--------+------------------
1 | 1 | 10.6650887159422
2 | 2 | 10.0400685494281
3 | 3 | 7.26197376834847
4 | 4 | 6.5227892843447
5 | 5 | 5.11307075598297
6 | 6 | 3.14838515537081
7 | 7 | 2.67251694708377
7 | 7 |
(8 rows)
dm=# select array_dims(row_vec) from svd_v;
array_dims
------------
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
[1:7]
(8 rows)
dm=# select * from svd_summary;
rows_used | exec_time (ms) | iter | recon_error | relative_recon_error
-----------+----------------+------+----------------+----------------------
9 | 10364.79 | 8 | 0.116171249851 | 0.0523917951113
(1 row)可以看到,结果U、V矩阵的维度分别是9 x 7和8 x 7,奇异值是一个7 x 7的对角矩阵。这里还有一点与低秩矩阵分解函数不同,低秩矩阵分解函数由于引入了随机数,是不确定函数,相同参数的输入,可能得到不同的输出结果矩阵。但奇异值分解函数是确定的,只要入参相同,输出的结果矩阵就是一样的。
(3) 对比不同奇异值个数的逼近程度
让我们按k的取值公式计算一下奇异值的比值,验证k设置为6、8时的逼近程度。
-- k=8
drop table if exists svd8_u, svd8_v, svd8_s, svd8_summary cascade;
select madlib.svd_sparse_native
('svd_data', 'svd8', 'row_id', 'col_id', 'val', 9, 8, 8, NULL, 'svd8_summary');
-- k=6
drop table if exists svd6_u, svd6_v, svd6_s, svd6_summary cascade;
select madlib.svd_sparse_native
('svd_data', 'svd6', 'row_id', 'col_id', 'val', 9, 8, 6, NULL, 'svd6_summary'); 对比逼近程度。
select * from svd6_summary;
select * from svd_summary;
select * from svd8_summary;
select s1/s3, s2/s3
from (select sum(value*value) s1 from svd6_s) t1,
(select sum(value*value) s2 from svd_s) t2,
(select sum(value*value) s3 from svd8_s) t3; 结果:
dm=# select * from svd6_summary;
t3;
rows_used | exec_time (ms) | iter | recon_error | relative_recon_error
-----------+----------------+------+----------------+----------------------
9 | 3051.51 | 8 | 0.335700790666 | 0.151396899541
(1 row)
dm=# select * from svd_summary;
rows_used | exec_time (ms) | iter | recon_error | relative_recon_error
-----------+----------------+------+----------------+----------------------
9 | 6122.36 | 8 | 0.116171249851 | 0.0523917951113
(1 row)
dm=# select * from svd8_summary;
rows_used | exec_time (ms) | iter | recon_error | relative_recon_error
-----------+----------------+------+-------------------+----------------------
9 | 4182.38 | 8 | 1.52006310774e-15 | 6.85529638348e-16
(1 row)
dm=# select s1/s3, s2/s3
dm-# from (select sum(value*value) s1 from svd6_s) t1,
dm-# (select sum(value*value) s2 from svd_s) t2,
dm-# (select sum(value*value) s3 from svd8_s) t3;
?column? | ?column?
-------------------+-------------------
0.977078978809393 | 0.997255099805013
(1 row) 可以看到,随着k值的增加,误差越来越小。在本示例中,奇异值个数为6、7的近似度分别为97.7%和99.7%,当k=8时并没有降维,分解的矩阵相乘等于原矩阵。后面的计算都使用k=7的结果矩阵。
(4) 基于用户的协同过滤算法UserCF生成推荐
所谓UserCF算法,简单说就是依据用户的相似程度形成推荐。
定义基于用户的协同过滤函数。
create or replace function fn_user_cf(user_idx int)
returns table(r2 int, s float8, col_id int, val float8, musicid varchar(10)) as
$func$
select r2, s, col_id, val, musicid
from
(select r2,s,col_id,val,row_number() over (partition by col_id order by col_id) rn
from
(select r2,s,col_id,val
from
(select r2,s
from
(select r2,s,row_number() over (order by s desc) rn
from
(select t1.row_id r1, t2.row_id r2,
(madlib.cosine_similarity(v1, v2)) s
from
(select row_id, row_vec v1
from svd_u where row_id = $1) t1,
(select row_id, row_vec v2 from svd_u) t2
where t1.row_id <> t2.row_id) t) t
where rn <=5 and s < 1) t1, svd_data t2
where t1.r2=t2.row_id and t2.val >=3) t
where col_id not in (select col_id from svd_data where row_id = $1)) t1,
tbl_idx_music t2
where t1.rn = 1 and t1.col_id = t2.music_idx
order by t1.s desc, t1.val desc limit 5;
$func$
language sql; 说明:
- 最内层查询调用madlib.cosine_similarity函数返回指定用户与其他用户的余弦相似度。
select t1.row_id r1, t2.row_id r2, (madlib.cosine_similarity(v1, v2)) s
from (select row_id, row_vec v1 from svd_u where row_id = $1) t1,
(select row_id, row_vec v2 from svd_u) t2
where t1.row_id <> t2.row_id- 外面一层查询按相似度倒序取得排名。
select r2,s,row_number() over (order by s desc) rn from …- 外面一层查询取得最相近的5个用户,同时排除相似度为1的用户,因为相似度为1说明两个用户的歌曲评分一模一样,而推荐的应该是用户没有打过分的歌曲。
select r2,s from … where rn <=5 and s < 1- 外面一层查询取得相似用户打分在3及其以上的歌曲索引ID。
select r2,s,col_id,val from … wheret1.r2=t2.row_id and t2.val >=3- 外面一层查询取得歌曲索引ID的排名,目的是去重,避免相同的歌曲推荐多次,并且过滤掉被推荐用户已经打过分的歌曲。
select r2,s,col_id,val,
row_number() over (partition by col_id order by col_id) rn
from … where col_id not in (select col_id from svd_data where row_id =$1)- 最外层查询关联歌曲索引表取得歌曲业务主键,并按相似度和打分推荐前5个歌曲。
select r2, s, col_id, val, musicid ...
where t1.rn = 1 and t1.col_id =t2.music_idx
order by t1.s desc, t1.val desc limit5定义接收用户业务ID的函数。
create or replace function fn_user_recommendation(i_userid varchar(10))
returns table (r2 int, s float8, col_id int, val float8, musicid varchar(10)) as
$func$
declare
v_rec record;
v_user_idx int:=0;
begin
select user_idx into v_user_idx from tbl_idx_user where userid=i_userid;
for v_rec in (select * from fn_user_cf(v_user_idx)) loop
r2:=v_rec.r2;
s:=v_rec.s;
col_id:=v_rec.col_id;
val :=v_rec.val;
musicid:=v_rec.musicid;
return next;
end loop;
return;
end;
$func$
language plpgsql;通常输入的用户ID是业务系统的ID,而不是索引下标,因此定义一个接收业务系统的ID函数,内部调用fn_user_cf函数生成推荐。
测试推荐结果。
select * from fn_user_recommendation('u1');
select * from fn_user_recommendation('u3');
select * from fn_user_recommendation('u9'); 结果:
dm=# select * from fn_user_recommendation('u1');
r2 | s | col_id | val | musicid
----+---------------------+--------+-----+---------
6 | 0.0446031939822096 | 3 | 4 | m3
2 | 0.0304067953459913 | 4 | 3 | m4
5 | 0.00259120409706406 | 2 | 5 | m2
5 | 0.00259120409706406 | 7 | 4 | m7
5 | 0.00259120409706406 | 8 | 3 | m8
(5 rows)
dm=# select * from fn_user_recommendation('u3');
r2 | s | col_id | val | musicid
----+---------------------+--------+-----+---------
6 | 0.109930597010835 | 6 | 3 | m6
2 | 0.0749416547815916 | 4 | 3 | m4
5 | 0.00638637254275688 | 2 | 5 | m2
5 | 0.00638637254275688 | 8 | 3 | m8
(4 rows)
dm=# select * from fn_user_recommendation('u9');
r2 | s | col_id | val | musicid
----+---------------------+--------+-----+---------
6 | 0.109930597010835 | 6 | 3 | m6
2 | 0.0749416547815916 | 4 | 3 | m4
5 | 0.00638637254275688 | 2 | 5 | m2
5 | 0.00638637254275688 | 8 | 3 | m8
(4 rows)可以看到,因为u3和u9的评分完全相同,相似度为1,所以为他们生成的推荐也完全相同。
(5) 基于歌曲的协同过滤算法ItemCF生成推荐
所谓ItemCF算法,简单说就是依据歌曲的相似程度形成推荐。
定义基于歌曲的协同过滤函数。
create or replace function fn_item_cf(user_idx int)
returns table(r2 int, s float8, musicid varchar(10)) as
$func$
select t1.r2, t1.s, t2.musicid
from (select t1.r2,t1.s,row_number() over (partition by r2 order by s desc) rn
from (select t1.*, row_number() over (partition by r1 order by s desc) rn
from (select t1.row_id r1, t2.row_id r2, (madlib.cosine_similarity(v1, v2)) s
from (select row_id, row_vec v1
from svd_v
where row_id in (select col_id from svd_data where row_id=$1)) t1,
(select row_id, row_vec v2
from svd_v
where row_id not in (select col_id from svd_data where row_id=$1)) t2
where t1.row_id <> t2.row_id) t1) t1
where rn <=3) t1, tbl_idx_music t2
where rn = 1 and t1.r2 = t2.music_idx
order by s desc;
$func$
language sql;说明:
- 最内层查询调用madlib.cosine_similarity函数返回指定用户打过分的歌曲与没打过分的歌曲的相似度。
select t1.row_id r1, t2.row_id r2, (madlib.cosine_similarity(v1, v2)) s
from (select row_id, row_vec v1
from svd_v
where row_id in (select col_id from svd_data where row_id=$1)) t1,
(select row_id, row_vec v2
from svd_v
where row_id not in (select col_id from svd_data where row_id=$1)) t2
where t1.row_id <> t2.row_id- 外面一层查询按相似度倒序取得排名。
select t1.*, row_number() over (partitionby r1 order by s desc) rn …- 外面一层查询取得与每个打分歌曲相似度排前三的歌曲,并以歌曲索引ID分区,按相似度倒序取得排名,目的是去重,避免相同的歌曲推荐多次。
select t1.r2,t1.s,row_number() over(partition by r2 order by s desc) rn
from … where rn <=3- 最外层查询关联歌曲索引表取得歌曲业务主键并推荐。
select t1.r2, t1.s, t2.musicid
from ... where rn = 1 and t1.r2 = t2.music_idx order by s desc定义接收用户业务ID的函数。
create or replace function fn_item_recommendation(i_userid varchar(10))
returns table (r2 int, s float8, musicid varchar(10)) as
$func$
declare
v_rec record;
v_user_idx int:=0;
begin
select user_idx into v_user_idx from tbl_idx_user where userid=i_userid;
for v_rec in (select * from fn_item_cf(v_user_idx)) loop
r2:=v_rec.r2;
s:=v_rec.s;
musicid:=v_rec.musicid;
return next;
end loop;
return;
end;
$func$
language plpgsql;通常输入的用户ID是业务系统的ID,而不是索引下标,因此定义一个接收业务系统的ID函数,内部调用fn_item_cf函数生成推荐。
测试推荐结果。
select * from fn_item_recommendation('u1');
select * from fn_item_recommendation('u3');
select * from fn_item_recommendation('u9');结果:
dm=# select * from fn_item_recommendation('u1');
r2 | s | musicid
----+--------------------+---------
3 | 0.120167300602806 | m3
7 | 0.063463750764015 | m7
4 | 0.0474991338483946 | m4
(3 rows)
dm=# select * from fn_item_recommendation('u3');
r2 | s | musicid
----+--------------------+---------
2 | 0.211432380780157 | m2
4 | 0.125817242051348 | m4
1 | 0.120167300602806 | m1
6 | 0.115078854619122 | m6
8 | 0.0747298357682603 | m8
(5 rows)
dm=# select * from fn_item_recommendation('u9');
r2 | s | musicid
----+--------------------+---------
2 | 0.211432380780157 | m2
4 | 0.125817242051348 | m4
1 | 0.120167300602806 | m1
6 | 0.115078854619122 | m6
8 | 0.0747298357682603 | m8
(5 rows)可以看到,因为u3和u9的评分作品完全相同,相似度为1,所以按作品相似度为他们生成的推荐也完全相同。
(6) 为新用户寻找相似用户
假设一个新用户u10的评分向量为'{0,4,5,3,0,0,-2,0}',要利用已有的奇异值矩阵找出该用户的相似用户。
1. 添加行为数据
insert into source_data
values ('u10', 'm2', 4), ('u10', 'm3', 5), ('u10', 'm4', 3), ('u10', 'm7', -2);
insert into tbl_idx_user (userid)
select distinct userid
from source_data
where userid not in (select userid from tbl_idx_user)
order by userid; 2. 确认从评分向量计算svd_u向量的公式
u10[1:8] x svd_v[8:7] x svd_s[7:7]^-1drop table if exists mat_u10;
create table mat_u10(row_id int, row_vec float8[]);
insert into mat_u10 values (1, '{0,4,5,3,0,0,-2,0}'); 4. 根据计算公式,先将前两个矩阵相乘
drop table if exists mat_r_10;
select madlib.matrix_mult('mat_u10', 'row=row_id, val=row_vec',
'svd_v', 'row=row_id, val=row_vec',
'mat_r_10'); 5. 根据公式,求奇异值矩阵的逆矩阵
drop table if exists svd_s_10;
create table svd_s_10 as
select row_id, col_id,1/value val from svd_s where value is not null;6. 根据公式,将4、5两步的结果矩阵相乘。注意 4 的结果mat_r_10是一个稠密矩阵,5 的结果svd_s_10是一个稀疏矩阵。
drop table if exists matrix_r_10;
select madlib.matrix_mult('mat_r_10', 'row=row_id, val=row_vec',
'svd_s_10', 'row=row_id, col=col_id, val=val',
'matrix_r_10'); 7. 查询与u10相似的用户
select t1.row_id r1, t2.row_id r2, madlib.cosine_similarity(v1, v2) s
from (select row_id, row_vec v1 from matrix_r_10 where row_id = 1) t1,
(select row_id, row_vec v2 from svd_u) t2
order by s desc; 结果:
dm=# select t1.row_id r1, t2.row_id r2, madlib.cosine_similarity(v1, v2) s
dm-# from (select row_id, row_vec v1 from matrix_r_10 where row_id = 1) t1,
dm-# (select row_id, row_vec v2 from svd_u) t2
dm-# order by s desc;
r1 | r2 | s
----+----+----------------------
1 | 4 | 0.989758250631095
1 | 6 | 0.445518586781384
1 | 2 | 0.117185108937363
1 | 8 | 0.00673214822878822
1 | 1 | -0.0026200076051774
1 | 5 | -0.00988637492741542
1 | 3 | -0.0276611552976064
1 | 9 | -0.0276611552976064
1 | 7 | -0.253951334956948
(9 rows)可以看到,u10与u4的相似度高达99%,从原始的评分向量可以得到验证:
u4:'{0,4,4,3,0,0,-2,0}'
u10:'{0,4,5,3,0,0,-2,0}'8. 将结果向量插入svd_u矩阵
insert into svd_u
select user_idx, row_vec from matrix_r_10, tbl_idx_user where userid = 'u10';