Linux存储管理
本文主要介绍了Linux存储管理相关内容,包括磁盘接口、结构等基础内容,以及磁盘分区、文件系统,LVM,RAID等
文章目录
- 一、磁盘管理
- 1. 磁盘接口类型
- IDE
- SATA
- SCSI
- SAS
- USB
- 2. 机械磁盘结构
- 3. 设备文件
- 创建设备文件
- 4. 磁盘分区
- 分区表类型
- MBR
- 扩展分区与逻辑分区
- GPT
- MBR与GPT
- BIOS与UEFI
- 5. 相关命令
- 分区管理
- dd
- 二、文件系统
- 1. VFS
- 2. EXT FS
- 相关概念
- Block
- Inode
- Bitmap Index
- Block Group
- Super Block
- GDT
- ext2、ext2、ext4的差异
- 文件与目录的存储
- 3. 链接文件
- 硬链接
- 符号链接
- ln命令
- 4. swap分区
- 5. BtrFS
- 6. 文件系统管理相关命令
- 文件系统创建
- mkfs
- mke2fs
- 其他管理命令
- blkid
- tune2fs
- lsblk
- dumpe2fs
- e2label
- fsck
- BtrFS管理命令
- 7. 挂载
- 什么是挂载
- 相关命令
- mount
- umount
- df
- du
- hdparm
- /etc/fstab文件
- 8. 例
- 三、RAID
- 1. RAID是什么
- 2. RAID的实现方式
- 3. 常用的RAID级别介绍
- RAID 0
- RAID 1
- RAID 4
- RAID 5
- RAID 6
- 组合方案
- RAID 10
- RAID 01
- RAID 50
- RAID 60
- 4. JBOD
- 5. 模拟RAID实现
- MD模块
- mdadm
- 例
- 四、LVM
- 1. 什么是LVM
- dm
- LVM基本组成
- 2. 设备路径
- 3. 相关命令
- 物理卷管理命令:pv*
- 卷组管理命令:vg*
- 逻辑卷管理命令:lv*
- 4. 例
- 创建分区
- PV阶段
- VG阶段
- LV阶段
- FS阶段
- 扩大LV容量
- 缩小LV容量
- 5. 快照卷
- 快照
- 快照卷
- 创建快照卷
- 测试
- 五、例
一、磁盘管理
1. 磁盘接口类型
Linux的一个重要思想之一就是一切皆文件,而磁盘作为存储数据的重要设备,在系统中也有与之对应的设备文件。根据不同接口类型的设备,其设备文件的命名方式亦不同。
IDE
IDE(Integrated Drive Electronics),集成磁盘电子接口,事实上IDE为磁盘的形式,这种硬盘一般使用PATA(Parallel Advanced Technology Attachment)接口,我们通常所谓的IDE硬盘即接口为PATA的硬盘,该接口为并行接口,其理论传输速度为133MB/s。
在Linux发行版中,这类硬盘的设备文件一般为sd开头(以RHEL系列发行版为例),在RHEL6以前以hd开头。通常在PC的主板上有2个IDE口,每一个接口可接2块硬盘,分为主、从盘,如/dev/hda。
而分区后,每一个分区会再次创建一个设备文件,以DEVICE#命名,如,主分区一般为dev/hda[1-4],逻辑分区为/dev/hda[5+]
即使用字母a、b、c……来区别不同设备,使用1、2、3……来区分同一设备的不同分区,下同
SATA
SATA(Serial Advanced Technology Attachment),即串行ATA,SATA有多种规格,SATA2的理论速度为3Gbps,SATA3的理论速度为6Gbps,该接口排线与SCSI兼容,SATA硬盘也可接上SAS接口。设备文件以sd开头
SCSI
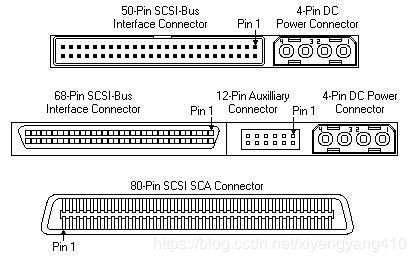
SCSI(Small Computer System Interface)小型计算机系统接口,是一种用于计算机及其周边设备之间(硬盘、软驱、光驱、打印机、扫描仪等)系统级接口的独立处理器标准。
SCSI控制器接上总线,窄总线可以可接7个Target,宽总线可接15个Target,而后还可接若干硬盘,理论速度640MB/s,设备文件通常以sd开头
SAS
SAS(Serial Attached SCSI)串行SCSI,是新一代的SCSI技术,SAS并支持与序列式ATA(SATA)设备兼容,且两者可以使用相类似的电缆,理论速度6Gbps,设备文件通常以sd开头
USB
目前日渐普及的USB Type-C:

USB(Universal Serial Bus)通用串行总线,是连接计算机系统与外部设备的一种串口总线标准,也是一种输入输出接口的技术规范,被广泛地应用于个人计算机和移动设备等信息通讯产品,并扩展至摄影器材、数字电视(机顶盒)、游戏机等其它相关领域,相信大家不会陌生
目前最新一代的USB是USB 3.2,传输速度为20Gbit/s,设备文件通常以sd开头
2. 机械磁盘结构
硬盘(Hard Disk Drive,HDD)是计算机上使用坚硬的旋转盘片为基础的非易失性存储器,它在平整的磁性表面存储和检索数字数据,数据通过离磁性表面很近的磁头由电磁流来改变极性的方式被写入到磁盘上,数据可以通过被读取,原理是磁头经过盘片的上方时盘片本身的磁场导致读取线圈中电气信号改变。

机械硬盘(HDD)主要由:盘片,磁头,盘片转轴及控制电机,磁头控制器,数据转换器,接口,缓存等几个部分组成,上图为机械硬盘的实拍,下图为各部分名称

磁头(Heads)可沿盘片的半径方向运动,加上盘片每分钟几千转的高速旋转,磁头就可以定位在盘片的指定位置上进行数据的读写操作(类似于留声机)。信息通过离磁性表面很近的磁头,由电磁流来改变极性方式被电磁流写到磁盘上,信息可以通过相反的方式读取。硬盘作为精密设备,尘埃是其大敌,所以进入硬盘的空气必须过滤
盘片(Platters)为数据的主要存储介质,往往有多片,每个碟片都有两面,因此也会相对应每碟片有2个磁头,工作时,所有盘片由一个点击带动同时旋转

对于盘片,还有一些逻辑上的结构:
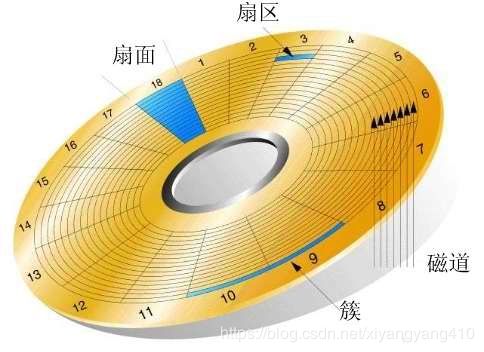
磁道(Track),盘片上的同心圆,由厂商完成划分,其容量由盘片的密度决定。在最外圈,离主轴最远的地方是“0”磁道,硬盘数据的存放就是从最外圈开始的
扇区(Sector),由于硬盘的设计机构,工作时磁道的角速度相同。由于径向长度不同,所以,线速度也不同,外圈的线速度较内圈的线速度大,即同样的转速下,外圈在同样时间段里,划过的圆弧长度要比内圈划过的圆弧长度大。每段圆弧叫做一个扇区,扇区从“1”开始编号,每个扇区中的数据作为一个单元同时读出或写入。
簇(Data cluster),有时被称为分配单元(allocation unit),是操作系统中磁盘文件存储管理的单位,可为一个或多个物理扇区组成
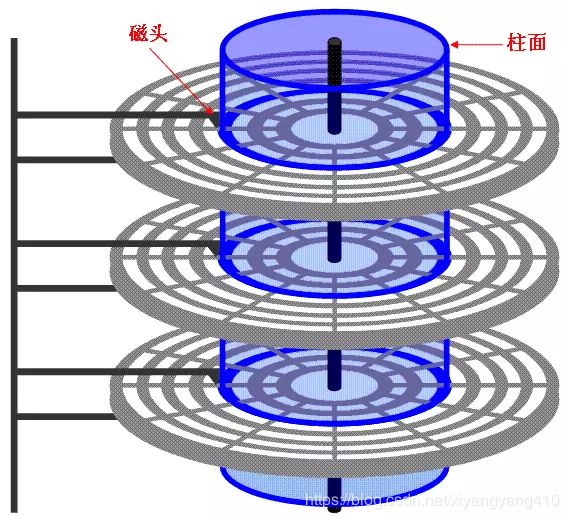
柱面(Cylinder),硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面,划分分区是按照柱面划分的
此外,对于机械硬盘而言,还有几个重要的参数:
转速,转速是硬盘内电机主轴的旋转速度,也就是硬盘盘片在一分钟内所能完成的最大转数,即RPM(Rotations Per Minute),个人设备常见的有5400RPM,7200RPM
平均寻道时间(Average Seek Time),是指硬盘的磁头移动到盘面指定磁道所需的时间,单位为毫秒。这个时间当然越小越好,目前主流硬盘的平均寻道时间通常在8ms到12ms之间。
3. 设备文件
之前有介绍,设备文件有块(block)设备与字符(char)设备之分,块设备存取单位为“块”,可随机访问,本文介绍的硬盘就是块设备;而字符设备存取单位为“字符”,是顺序访问设备
Linux内核在探测到硬件设备后,会为其创建设备文件(此特性可以在内核编译时指定是否开启,绝大部分发行版会启用此特性后续将介绍)至/dev目录中,此设备文件将关联只设备的驱动程序,访问此文件即可访问到文件所关联到的设备
每个设备分别有主次设备号
- 主设备号(major number),用于标识设备类型,进而确定要加载的驱动程序
- 次设备号(minor number),用于标识同一类型中的不同的设备
创建设备文件
用户可以手动创建设备文件,使用mknod命令,其用法为
mknod [OPTION]... NAME TYPE [MAJOR MINOR]
TYPE
b create a block (buffered) special file
c create a character (unbuffered) special file
OPTIONS
-m MODE set file permission bits to MODE
4. 磁盘分区
硬盘分区实质上是对硬盘的一种格式化,然后才能使用硬盘保存各种信息。创建分区时,就已经设置好了硬盘的各项物理参数。 其实完全可以只创建一个分区使用全部或部分的硬盘空间。
分区表类型
分区(Partition):在磁盘上建立起来的逻辑边界,创建文件系统,按柱面划分,而一个磁盘的分区信息,自然保存在当前磁盘中,其格式目前有两种:MBR与GPT
MBR
MBR(Master Boot Record),主引导记录,位于0盘面0磁道1扇区,512byte,不属于任何分区,亦不属于操作系统。主要由三部分组成:
-
Boot Loader
引导加载器,主引导记录最开头的446字节。其中的硬盘引导程序的主要作用是检查分区表是否正确并且在系统硬件完成自检以后将控制权交给硬盘上的引导程序(如GNU GRUB)。它不依赖任何操作系统,而且启动代码也是可以改变的,从而能够实现多系统引导。 -
FAT
File Allocation Table,文件分区表,共64字节,每16个字节可标识一个分区,共可标识4个分区 -
Magic Number
2字节,通常别填充为55AA,用于标识MBR是否有效
详见下表1
| 地址 | 描述 | 长度 |
|||
|---|---|---|---|---|---|
| Hex | Oct | Dec | |||
0000 |
0000 |
0 | 代码区 | 440 (最大446) |
|
01B8 |
0670 |
440 | 选用磁盘标志 | 4 | |
01BC |
0674 |
444 | 一般为空值; 0x0000 | 2 | |
01BE |
0676 |
446 | 标准MBR分区表规划 (四个16 byte的主分区表入口) |
64 | |
01FE |
0776 |
510 | 55h | MBR有效标志: 0x55AA |
2 |
01FF |
0777 |
511 | AAh | ||
| MBR,总大小:446 + 64 + 2 = | 512 | ||||
扩展分区与逻辑分区
由于MBR的设计,一块物理硬盘最多只能有4个分区,如今,这在多数情况下是不能满需求的。因此就有了扩展分区(Extended Partition)的概念
MBR中FAT标记的4个分区被称为主分区,若需要更多的分区,使用其中的一个主分区,用于指定磁盘上某一位置,存放了额外的分区信息,该分区即扩展分区,扩展分区不能格式化,其指定的分区为逻辑分区(Logical Partition),扩展分区在一个硬件设备中只能有一个
这里引用鸟哥的Linux私房菜中的例子:
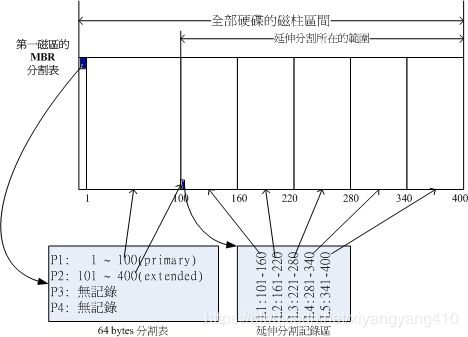
如图,我们使用了分区表中的2个分区,P1为主分区,P2为扩展分区,扩展分区的目的是指定使用额外的空间来记录分区信息,扩展分区本身是很小的,不能被格式化。我们可以使用扩展分区所指向的区域作为分区的记录区。
图中的扩展分区指定了5个额外的分区,即逻辑分区L1至L5,另外,由于逻辑分区是由扩展分区指定的,故其分区的范围就是扩展分区设定的范围,即图中的101~400
另外,上文亦有提及,扩展分区的名称是以5开始的,故图中的分区在系统的设备文件为(假设磁盘为/dev/sda):
- P1:
/dev/sda1 - P2:
/dev/sda2 - L1:
/dev/sda5 - L2:
/dev/sda6 - L3:
/dev/sda7 - L4:
/dev/sda8 - L5:
/dev/sda9
GPT
GPT( GUID(Globally Unique IDentifier) Partition Table),全局唯一标识分区表,是EFI(可扩展固件接口标准)的一部分,用来替代BIOS中的主引导记录分区表
GPT的分区信息是在分区中,而不象MBR一样在主引导扇区,为保护GPT不受MBR类磁盘管理软件的危害,GPT在主引导扇区建立了一个保护分区(Protective MBR)的MBR分区表(此分区并不必要),其类型被标识为0xEE

跟现代的MBR一样,GPT也使用LBA(Logical Block Address,逻辑区块地址)取代了早期的CHS寻址方式。传统MBR信息仅存储于LBA 0,而GPT使用了34个LBA,GPT头存储于LBA 1,接下来才是分区表本身
另外,在最后的33个LBA中,也存储了分区信息用于备份
上述图示的解释说明如下2:
-
- LBA0 (MBR兼容部分)
- 与MBR模式相似的,这个兼容区块也分为两个部份,一个就是跟之前446 bytes相似的区块,储存了第一阶段的开机管理程序!而在原本的分区表的纪录区内,这个兼容模式仅放入一个特殊标志的分区,用来表示此磁盘为GPT格式之意。而不懂GPT分割表的磁盘管理程序,就不会认识这块磁盘,除非用户有特别要求要处理之,否则该管理软件不能修改此分区信息,进一步保护了此磁盘!
-
- LBA1 (GPT 表头纪录)
- 这个部份纪录了分区表本身的位置与大小,每128字节标识一个分区(UEFI标准中的最低要求:分区表最小要有16384字节)同时纪录了备份用的GPT 分区(就是前面谈到的在最后34 个LBA 区块) 放置的位置, 同时放置了分区表的检验机制码(CRC32 ),操作系统可以根据这个检验码来判断GPT 是否正确。若有错误,还可以通过这个纪录区来取得备份的GPT(磁盘最后的备份区域) 来恢复GPT 的正常运作!其格式为
相对偏移 长度 说明 0 (0x00) 8 bytes 签名("EFI PART"的ASCII码) 8 (0x08) 4 bytes 版本号 12 (0x0C) 4 bytes GPT表头的标头大小(以字节为单位,通常为5Ch 00h 00h 00h,92字节) 16 (0x10) 4 bytes 头端的CRC32 / zlib校验,在计算过程中该字段归零 20 (0x14) 4 bytes 保留; 必须为零 24 (0x18) 8 bytes 当前LBA(此标头副本的位置) 32 (0x20) 8 bytes 备份LBA(其他标头副本的位置) 40 (0x28) 8 bytes 第一个可用于分区的LBA,即LBA34(主分区表最后一个LBA + 1) 48 (0x30) 8 bytes 最后可用的LBA(辅助分区表第一个LBA - 1) 56 (0x38) 16 bytes 磁盘GUID(在UNIX上也称为UUID) 72 (0x48) 8 bytes 启动分区条目数组的LBA(主副本中始终为2,即LBA2) 80 (0x50) 4 bytes 数组中的分区条目数,通常为128 84 (0x54) 4 bytes 单个分区条目的大小(通常为 80h,即128) 88 (0x58) 4 bytes 分区条目数组的CRC32 / zlib校验 92 (0x5C) * 保留; 对于块的其余部分,必须为零(扇区大小为512字节时为420字节;但对于更大的扇区大小,则可以更多) -
- LBA2-33 (实际纪录分区信息处)
- 从LBA2区块开始,每个LBA都可以纪录4条分区纪录,所以在默认的情况下,总共可以有4*32 = 128条分区纪录!因为每个LBA有512bytes,因此每条纪录用到128 bytes的空间,除了每条纪录所需要的识别码与相关的纪录之外,GPT在每条纪录中分别提供了64bits来记录开始/结束的扇区(Sector)号码,因此,GPT分区表对于单一分区来说,他的最大容量限制为 2 64 ∗ 512 b y t e s = 2 63 ∗ 1 K b y t e s = 2 33 T B = 8 Z B 2^{64}*512bytes=2^{63}*1Kbytes=2^{33}TB=8ZB 264∗512bytes=263∗1Kbytes=233TB=8ZB,而1ZB = 2 30 TB!
GPT的每一个分区都可以独立存在,没有所谓的扩展、逻辑分区的概念,即所有分区都是主分区
MBR与GPT
相较于MBR,GPT具有以下优点
-
得益于LBA提升至64位,以及分区表中每项128位设定,GPT可管理的空间近乎无限大(单一分区8ZB)
-
分区数量几乎没有限制,由于可在表头中设置分区数量的大小(目前windows仅支持最大128个分区)
-
自带保险,由于在磁盘的首尾部分各带一个GPT表头,任何一个受到破坏后都可以通过另一份恢复,极大地提高了磁盘的抗性
-
循环冗余检验值针对关键数据结构而计算,提高了数据崩溃的检测几率
-
GPT提供了16字节的GUID来标识分区类型,使其更不容易产生冲突
-
每个分区都可以拥有一个特别的名字,最长72字节
BIOS与UEFI
为了说明问题,此处介绍一点系统启动流程,后续将详细介绍
我们如今计算机之所以看起来聪明,能自动完成一些工作,都依赖于所执行的代码,CPU只有加载到这些代码后才可运行。计算机在开机后,会由硬件逻辑实现将主板ROM中存储的一段代码读入到CPU中,CPU执行这段代码,该过程即POST(Power On and Self-Testing,开机自检),用于探测物理设备,检查启动条件,指定硬件工作时的物理电气特性等
POST过程无误后,程序将根据CMOS中设定的引导顺序探测指定设备,以使用该设备引导系统启动
而实现以上操作的程序,目前有两种:BIOS与UEFI3
-
BIOS(Basic Input/Output System)基本输入输出系统,存储在EEPROM(电可擦除可编程只读存储器)中
-
UEFI(Unified Extensible Firmware Interface)统一可扩展固件接口,其早期为Intel开发,即EFI,后来作为工业标准,更名为UEFI
下表为关于二者的对比2
| 比较项目 | BIOS | UEFI |
|---|---|---|
| 开发语言 | 汇编语言 | C语言 |
| 硬件资源控制 | 使用中断(IRQ)管理 不可变的内存存取 不可变的输入/输出存取 |
使用驱动程序与协议 |
| 处理器运作环境 | 16 位 | CPU 保护模式 |
| 扩充方式 | 通过IRQ 连结 | 直接载入驱动程序 |
| 第三方厂商支持 | 较差 | 较佳且可支持多平台 |
| 图形化能力 | 较差 | 较佳 |
| 内置简化操作系统前环境 | 不支持 | 支持 |
5. 相关命令
分区管理
分区管理相关命令实质上就是编辑分区表,Linux系统最流行的工具为fdisk,不过该工具不能识别GPT分区,欲编辑GPT分区,可使用gdisk,其用法与fdisk类型,此处以fdisk为例说明
fdisk命令提供一个交互式接口来管理分区,有诸多子命令,分别用于不同的管理功能,此外,需要注意的是,所有的操作在保存前都存储在内存中,若直接退出,则修改将撤销
关于其选项,有一个需要介绍:
查看系统当前识别的硬盘:
fdisk -l [/DEV/TO/SOME_DEVICE_FILE],如
[root@localhost ~]# fdisk -l /dev/sda
Disk /dev/sda: 128.8 GB, 128849018880 bytes, 251658240 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000aff46
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 1026047 512000 83 Linux
/dev/sda2 1026048 251658239 125316096 8e Linux LVM
需要说明的是,关于输出内容中的Start与End的意义,CentOS 6与CentOS 7有所不同:
- CentOS 6:起始于结束柱面
- CentOS 7:起始于结束扇区
若需要编辑某磁盘的分区表,直接使用fdisk DEV/TO/SOME_DEVICE_FILE,即可进入到交互界面:
[root@localhost ~]# fdisk /dev/sda
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): m
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
g create a new empty GPT partition table
G create an IRIX (SGI) partition table
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
Command (m for help):
常用的子命令有:
| 子命令 | 说明 |
|---|---|
| p | 显示当前硬盘的分区,包括没保存的改动 |
| n | 增加一个新分区 |
| d | 删除一个分区 |
| w | 将修改写入磁盘并退出 |
| m | 显示菜单 |
| q | 不保存退出 |
| t | 修改分区id(即分区类型) |
| l | 显示支持的所有类型 |
另外,关于n命令,输入后fdisk会询问创建的分区类型,指定为p则新建一个主分区,e则新建一个扩展分区,而若已经创建了4个分区,其中一个分区为扩展分区,此时创建的分区只能是逻辑分区,如
Command (m for help): p
Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xa89f73e5
Device Boot Start End Blocks Id System
/dev/sdc1 2048 2099199 1048576 83 Linux
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): p
Partition number (2-4, default 2):
First sector (2099200-41943039, default 2099200):
Using default value 2099200
Last sector, +sectors or +size{K,M,G} (2099200-41943039, default 41943039): +1G
Partition 2 of type Linux and of size 1 GiB is set
Command (m for help): p
Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xa89f73e5
Device Boot Start End Blocks Id System
/dev/sdc1 2048 2099199 1048576 83 Linux
/dev/sdc2 2099200 4196351 1048576 83 Linux
Command (m for help): p
Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x55cfaa21
Device Boot Start End Blocks Id System
/dev/sdc1 2048 2099199 1048576 83 Linux
/dev/sdc2 2099200 4196351 1048576 83 Linux
/dev/sdc3 4196352 6293503 1048576 83 Linux
Command (m for help): n
Partition type:
p primary (3 primary, 0 extended, 1 free)
e extended
Select (default e): e
Selected partition 4
First sector (6293504-41943039, default 6293504):
Using default value 6293504
Last sector, +sectors or +size{K,M,G} (6293504-41943039, default 41943039):
Using default value 41943039
Partition 4 of type Extended and of size 17 GiB is set
Command (m for help): p
Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x55cfaa21
Device Boot Start End Blocks Id System
/dev/sdc1 2048 2099199 1048576 83 Linux
/dev/sdc2 2099200 4196351 1048576 83 Linux
/dev/sdc3 4196352 6293503 1048576 83 Linux
/dev/sdc4 6293504 41943039 17824768 5 Extended
Command (m for help): n
All primary partitions are in use
Adding logical partition 5
First sector (6295552-41943039, default 6295552):
Using default value 6295552
Last sector, +sectors or +size{K,M,G} (6295552-41943039, default 41943039): +1G
Partition 5 of type Linux and of size 1 GiB is set
Command (m for help): p
Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x55cfaa21
Device Boot Start End Blocks Id System
/dev/sdc1 2048 2099199 1048576 83 Linux
/dev/sdc2 2099200 4196351 1048576 83 Linux
/dev/sdc3 4196352 6293503 1048576 83 Linux
/dev/sdc4 6293504 41943039 17824768 5 Extended
/dev/sdc5 6295552 8392703 1048576 83 Linux
需要注意的是,创建的逻辑分区应该指定为所有可用空间,否则未被指定的空间将无法使用
另外, 在已经分区并且已经挂载其中某个分区的磁盘设备上创建新分区,内核可能再创建完成后无法直接识别(在/proc/partitions文件中显示了当前内核识别了哪些分区,可通过cat查看)
此时需要通知内核重读分区表,默认系统会试图重读系统上链接的所有磁盘
-
- 红帽5
-
artprobe [/dev/device]
-
- 红帽6
-
partx -a /dev/DEVICE,添加指定的分区或读取磁盘并添加所有分区
-n M:N指定范围
-
kpartx -a /dev/DEVICE
-f,force,强制
dd
这里再介绍一个更为底层的复制命令dd,与cp命令不同,cp复制时,是以文件为单位,而dd命令是以数据流为单位进行复制,会绕过文件系统,在块级别读写
该命令通过operand来指定执行特性,常用的operand有
if=数据来源
of=数据存储目标
bs=复制单元大小(一次读/写多少数据量),单位是字节
count=复制多少个bs
seek=#: 创建数据文件时,跳过的空间大小
oflag=FLAGS
常用形式为
dd if=input_file of=out_putfile
dd if=input_file of=out_putfile bs=#[BN|K|M|G] count=#
例:
- 磁盘拷贝
dd if=/dev/sda of=/dev/sdb - 备份MBR
dd if=/dev/sda of=/mnt/usb/mbr.backup bs=512 count=1 - 恢复MBR
dd if=/mnt/usb/mbr.backup of=/dev/sda bs=512 count=1 - 破坏bootloader
bs小于446也可,但是大于446,会破坏分区表dd if=/dev/zero of=/dev/sda bs=446 count=1 - 制作ISO镜像
dd if=/dev/cdrom of=/tmp/myiso.iso - 此外,通过
cat命令,使用重定向也可以制作ISO镜像文件cat /dev/cdrom > /tmp/myiso.iso
二、文件系统
计算机的文件系统(File System)是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘和光盘等物理设备使用数据块的概念,用户使用文件系统来保存数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,只需要记住这个文件的所属目录和文件名。在写入新数据之前,用户不必关心硬盘上的那个块地址没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。
1. VFS
文件系统是一种计算机数据的组织管理方式,而其具体实现是多样的,如
- Windows:
FAT32(Linux中叫做vfat),NTFS - Unix:
FFS(Fast File System),UFS(Unix File System),JFS2 - 光盘:
ISO9600 - 公共文件系统:Windows:
CIFS(Common Interface File System) - 基本文件系统
- Extended:
ext2,ext3,ext4 xfs:支持绝对大的单个文件ReiserFS:对于海量的小文件管理性能优越JFS,日志文件系统,IBM研发FAT32,NTFSBtrFS
- Extended:
- 交换分区:
swap - 集群文件系统
OCFS2(Oracle Cluster File System 2)CIFSGFS2,全局文件系统
- 网络文件系统:
NFS,SMBFS - 内核级分布式文件系统:
ceph - ……
而每一种文件系统的特性以及对于数据的读写方式都不同,Linux作为一个开放的系统,支持众多文件系统,可查看/lib/modules/KERNEL_VERSION/kernel/fs目录获取该信息,如
[root@localhost ~]# ls -l /lib/modules/$(uname -r)/kernel/fs
total 48
-rw-r--r--. 1 root root 21845 Mar 6 2015 binfmt_misc.ko
drwxr-xr-x. 2 root root 21 Dec 20 04:15 btrfs
drwxr-xr-x. 2 root root 26 Dec 20 04:15 cachefiles
drwxr-xr-x. 2 root root 20 Dec 20 04:15 ceph
drwxr-xr-x. 2 root root 20 Dec 20 04:15 cifs
drwxr-xr-x. 2 root root 22 Dec 20 04:15 cramfs
drwxr-xr-x. 2 root root 19 Dec 20 04:15 dlm
drwxr-xr-x. 2 root root 22 Dec 20 04:15 exofs
drwxr-xr-x. 2 root root 20 Dec 20 04:15 ext4
drwxr-xr-x. 2 root root 48 Dec 20 04:15 fat
drwxr-xr-x. 2 root root 23 Dec 20 04:15 fscache
drwxr-xr-x. 2 root root 34 Dec 20 04:15 fuse
drwxr-xr-x. 2 root root 20 Dec 20 04:15 gfs2
drwxr-xr-x. 2 root root 21 Dec 20 04:15 isofs
drwxr-xr-x. 2 root root 20 Dec 20 04:15 jbd2
drwxr-xr-x. 2 root root 21 Dec 20 04:15 lockd
-rw-r--r--. 1 root root 19589 Mar 6 2015 mbcache.ko
drwxr-xr-x. 5 root root 100 Dec 20 04:15 nfs
drwxr-xr-x. 2 root root 23 Dec 20 04:15 nfs_common
drwxr-xr-x. 2 root root 20 Dec 20 04:15 nfsd
drwxr-xr-x. 2 root root 4096 Dec 20 04:15 nls
drwxr-xr-x. 2 root root 23 Dec 20 04:15 overlayfs
drwxr-xr-x. 2 root root 23 Dec 20 04:15 pstore
drwxr-xr-x. 2 root root 24 Dec 20 04:15 squashfs
drwxr-xr-x. 2 root root 19 Dec 20 04:15 udf
drwxr-xr-x. 2 root root 19 Dec 20 04:15 xfs
通过装载这些模块,系统即可支持相应文件系统,而查看proc/filesystems文件即可获知当前已经装载支持的文件系统,如
[root@localhost ~]# cat /proc/filesystems
nodev sysfs
nodev rootfs
nodev bdev
nodev proc
nodev cgroup
nodev cpuset
nodev tmpfs
nodev devtmpfs
nodev debugfs
nodev securityfs
nodev sockfs
nodev pipefs
nodev anon_inodefs
nodev configfs
nodev devpts
nodev ramfs
nodev hugetlbfs
nodev autofs
nodev pstore
nodev mqueue
nodev selinuxfs
xfs
btrfs
Linux通过添加了一个逻辑中间层的方式,使得在对众多文件系统的支持方面效果良好,该层即VFS(Virtual Filesystem Switch),虚拟文件系统,亦称虚拟文件切换系统。是操作系统的文件系统虚拟层,在其下是实体的文件系统。虚拟文件系统的主要功用,在于让上层的软件,能够用单一的方式,来跟底层不同的文件系统沟通。在操作系统与之下的各种文件系统之间,虚拟文件系统提供了标准的操作接口,让操作系统能够很快的支持新的文件系统。下图为Linux存储栈逻辑图(点击查看大图)4
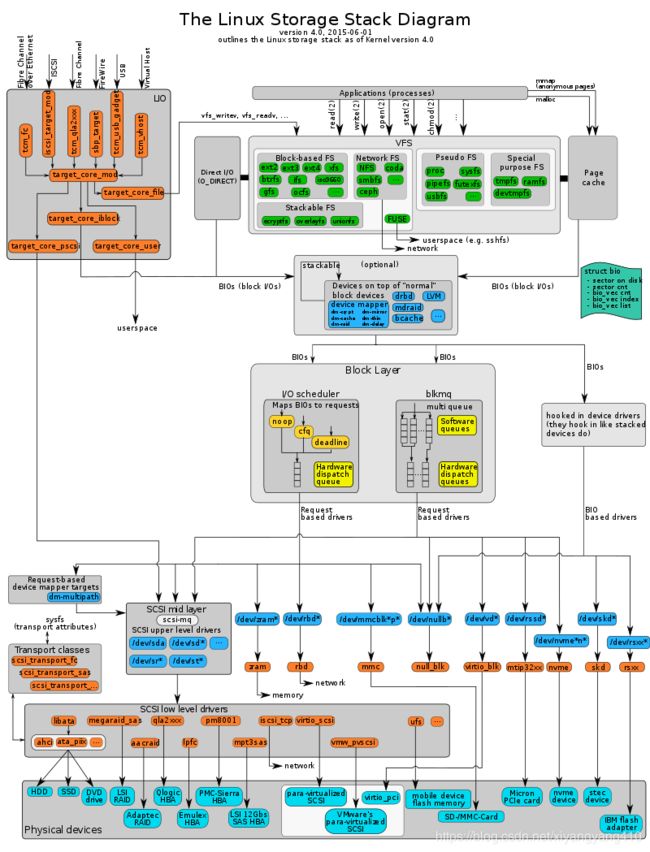
VFS在系统启动时建立,在系统关闭时消亡
2. EXT FS
ext应该说一个文件系统家族,目前常用的有ext2,ext3,ext4,是目前很多Linux发行版主要使用该文件系统。此处先以ext2文件系统为例进行说明,而后介绍ext3与ext4的新特性
相关概念
ext2大体上将磁盘分为两部分,数据区与元数据区,数据区存储文件内容,元数据区则存储文件的元数据信息,如权限、时间戳信息等(这里不包括文件名)
Block
此处也可称为Data block,用于存储数据内容,存储数据时,Block是存储空间分配的最小单位,通常为2x个扇区,常见的块大小(Block Size)有1024字节,2048字节,4096字节等,在格式化时指定
Inode
Inode即index node,索引节点。一个文件除了数据需要存储之外,一些描述信息也需要存储,例如文件类型,权限,文件大小,时间戳,还有文件所在的磁盘块等信息,inode号,(但是没有文件名)这些信息存在inode中而不是数据块中。
Inode数量也是在格式化时确定,每一个Inode为128字节(ext4为256字节)每个文件都有一个inode,一个块组中的所有inode组成了inode表
此外,inode有时也不直接指向data block,而是指向其地址,甚至有时会有多级地址:
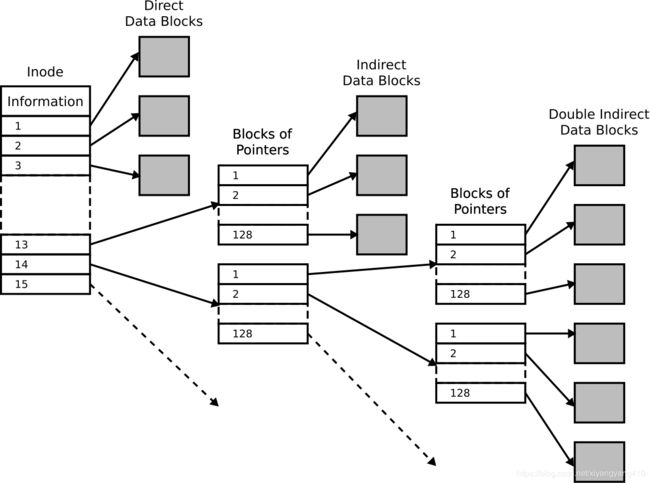
Bitmap Index
位图索引,Inode与Block都可以有位图索引,即Inode Bitmap与Block Bitmap。用于标记某位置是否已经使用,可加快查找空闲磁盘块的速度
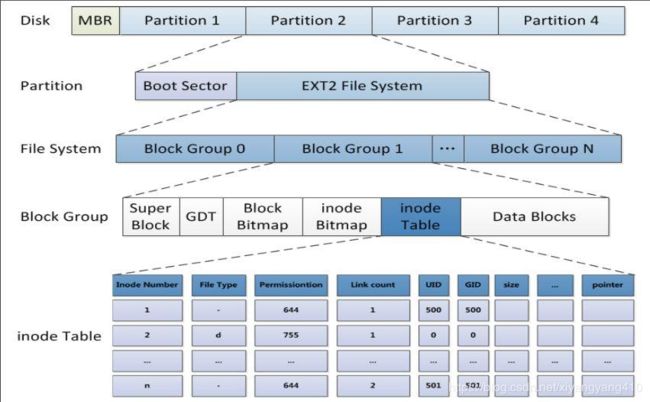
Block Group
块组,当分区建立完成后,会先将整个磁盘分区在划分成多个逻辑组(类似于分区下的子分区,对用户不可见),称为块组,块组可以跨分区引用(即一个文件可以保存在多个块组中,一个块组的inode可以指向其他块组中的块)
Super Block
Super Block即超级块。块组的数目不是固定的,就需要一个全局信息来描述,即超级块,每个块组中有独立的inode和block,每个块组中有块位图、inode位图等,超级块默认在0块组的0数据块,一般会有备份
GDT
块组描述符表(Group Description Table),保存有当前文件系统有多少块组、块组名、各个块组的始末位置等信息,一般会有备份
下图可大致描述各概念逻辑关系:
ext2、ext2、ext4的差异
ext2中存储文件时,先存储inode到元数据区,然后在数据区中存储数据。
当系统非法关机时,未存储完成的文件数据区不完整,导致无法访问,该文件没有意义,下次启动时,会有修复文件系统的操作,即删除这些文件,方法是逐个查找文件的inode,试图打开文件,这使得在大的存储器中,速度很慢
ext3:日志文件系统(Journal File System),文件系统中除了数据区、元数据区,还有日志区,在存储数据时,先将inode写入到日志区,若出现意外,系统只需直接检查日志区即可,数据存储(或修改)完成后,再将日志区中的inode移动到元数据区即可。
ext3还是使用15个inode来查找数据块,前12个为直接数据块,直接指向存储数据的数据块,接下来分别为一级间接块,二级间接块,三级间接块,如下图:
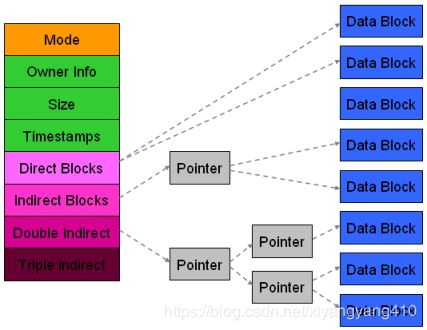
EXT3与EXT4的主要区别5
Linux kernel自2.6.28开始正式支持新的文件系统 Ext4。 Ext4是Ext3的改进版,修改了Ext3中部分重要的数据结构,而不仅仅像Ext3对Ext2那样,只是增加了一个日志功能而已。Ext4 可以提供更佳的性能和可靠性,还有更为丰富的功能:
-
与Ext3兼容。执行若干条命令,就能从Ext3在线迁移到Ext4,而无须重新格式化磁盘或重新安装系统。原有Ext3数据结构照样保留,Ext4作用于新数据,当然,整个文件系统因此也就获得了Ext4所支持的更大容量。
-
更大的文件系统和更大的文件。较之Ext3目前所支持的最大16TB文件系统和最大2TB文件,Ext4分别支持1EB(1,048,576TB,1EB=1024PB,1PB=1024TB)的文件系统,以及16TB 的文件。
-
无限数量的子目录。Ext3目前只支持32,000个子目录,而Ext4支持无限数量的子目录。
-
Extents。Ext3 采用间接块映射,当操作大文件时,效率极其低下。比如一个 100MB 大小的文件,在Ext3中要建立25,600个数据块(每个数据块大小为 4KB)的映射表。而Ext4引入了现代文件系统中流行的extents概念,每个 extent 为一组连续的数据块,上述文件则表示为“该文件数据保存在接下来的25,600个数据块中”,提高了不少效率。
-
多块分配。当 写入数据到 Ext3 文件系统中时,Ext3 的数据块分配器每次只能分配一个 4KB 的块,写一个 100MB 文件就要调用 25,600 次数据块分配器,而 Ext4 的多块分配器“multiblock allocator”(mballoc) 支持一次调用分配多个数据块。
-
延迟分配。Ext3的数据块分配策略是尽快分配,而 Ext4 和其它现代文件操作系统的策略是尽可能地延迟分配,直到文件在 cache 中写完才开始分配数据块并写入磁盘,这样就能优化整个文件的数据块分配,与前两种特性搭配起来可以显著提升性能。
-
快速 fsck。以前执行 fsck 第一步就会很慢,因为它要检查所有的 inode,现在 Ext4 给每个组的 inode 表中都添加了一份未使用 inode 的列表,今后 fsck Ext4 文件系统就可以跳过它们而只去检查那些在用的 inode 了。
-
日志校验。日志是最常用的部分,也极易导致磁盘硬件故障,而从损坏的日志中恢复数据会导致更多的数据损坏。Ext4的日志校验功能可以很方便地判断日志数据是否损坏,而且它将 Ext3 的两阶段日志机制合并成一个阶段,在增加安全性的同时提高了性能。
-
“无日志”(No Journaling)模式。日志总归有一些开销,Ext4允许关闭日志,以便某些有特殊需求的用户可以借此提升性能。
-
在线碎片整理。尽管延迟分配、多块分配和extents能有效减少文件系统碎片,但碎片还是不可避免会产生。Ext4支持在线碎片整理,并将提供e4defrag工具进行个别文件或整个文件系统的碎片整理。
-
inode 相关特性。Ext4 支持更大的inode,较之Ext3默认的inode大小128字节,Ext4为了在 inode 中容纳更多的扩展属性(如纳秒时间戳或inode版本),默认inode大小为256字节。Ext4 还支持快速扩展属性(fast extended attributes)和inode保留(inodes reservation)。
-
持久预分配(Persistent preallocation)。 P2P 软件为了保证下载文件有足够的空间存放,常常会预先创建一个与所下载文件大小相同的空文件,以免未来的数小时或数天之内磁盘空间不足导致下载失败。 Ext4在文件系统层面实现了持久预分配并提供相应的API(libc 中的 posix_fallocate()),比应用软件自己实现更有效率。
-
默认启用 barrier。磁 盘上配有内部缓存,以便重新调整批量数据的写操作顺序,优化写入性能,因此文件系统必须在日志数据写入磁盘之后才能写commit记录,若commit 记录写入在先,而日志有可能损坏,那么就会影响数据完整性。Ext4默认启用barrier,只有当barrier之前的数据全部写入磁盘,才能写 barrier之后的数据。(可通过“mount -o barrier=0″命令禁用该特性。)
文件与目录的存储
上文有提到,文件的文件名并没有保存在inode中,而“目录”(或许在Windows中被习惯称为“文件夹”)并没有像在Windows窗口中展示的那样是“包含”关系。事实上目录(文件夹),即Directory仅作为文件的访问路径,所谓“一个目录下包含的文件或子目录”,即可通过该目录直接找到的文件(目录也是文件)
故对于普通文件而言,其Data Block中存储了文件内容,而对于目录而言,其Data Block中存储了所谓的目录中的文件与一级子目录的名称与对应的inode
故也可以说文件名存储在其父目录的Data Block中
如,要获取/root/myfile文件,其简略查找过程为(假设只有一个分区)
- 由于Linux根可自引用,内核获取到
/的inode,并查看对应的Data Block,比如
– /root,对应10号inode
– /home,对应11号inode
– …… - 获取到10号inode后(即
/root),查看其对应的Data Block内容,比如
– .bashrc,对应100号inode
– myfile,对应150inode
– …… - 而后获取到150号inode(即
/root/myfile),即可查看到该inode对应的Data Block中的内容
3. 链接文件
之前有提到,ls -l的输出结果中有一项为“文件被硬链接的次数”6,经过以上的介绍,此处应该可以说明该问题。
硬链接
所谓硬链接(Hard Link)也叫作实体链接,是指向同一个inode的多个文件路径,需要说明的有以下几点
- 目录不支持硬链接
- 不能跨文件系统
- 创建硬链接会增加inode引用计数
另外,目录的硬链接次数一般为2,因为有.和当前目录名
符号链接
既然有硬链接,自然也有软链接,软链接多数被称为符号链接(Symbolic Link),类似于Windows中的快捷方式。
符号链接为指向一个文件路径的另一个文件路径,其文件内容为所指向文件的路径(字符串),该文件的大小即为字符串的大小,如果目标路径名较短则不为其分配block,而直接保存在inode中以便更快地查找,如果目标路径名较长则分配一个数据块来保存
- 符号链接与原文件是各自独立的文件,各有自己的inode
- 支持对目录创建符号链接
- 可以跨文件系统
- 删除符号链接文件不影响原文件,但删除原文件,符号指定的路径即不存在,此时会变为无效链接
- 符号链接一般不做权限限定,显示为
777,权限取决于指向的文件
ln命令
ln命令可用户创建链接文件,其使用方式如下
ln [-sv] SRC DEST
-s make symbolic links instead of hard links
-v print name of each linked file
如,创建/etc/fstab的符号链接
[root@localhost ~]# clear
[root@localhost ~]# ln -s /etc/fstab fstab.1
[root@localhost ~]# cat fstab.1
#
# /etc/fstab
# Created by anaconda on Wed Dec 19 20:12:26 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
[root@localhost ~]# ll fstab.1
lrwxrwxrwx. 1 root root 10 Feb 20 16:08 fstab.1 -> /etc/fstab
4. swap分区
swap即交换分区,是将磁盘模拟为内存的一种方式,用户解决早期内存空间不足的问题7
Linux上的交换分区必须使用独立的文件系统,且文件系统的system id要为82,而后,使用mkswap命令创建swap,最后使用swapon启用即可
mkswap命令用法如下
mkswap - set up a Linux swap area
mkswap [options] device [size]
[options]
-L 指定LABEL
-f 强制创建
swapon与swapoff可启用或关闭交换分区上的交换空间
swapon
-a 启用所有的定义在/etc/fstab文件中的所有交换分区
-p PRIORITY 指定优先级
swapoff
-a 关闭所有
5. BtrFS
即B-Tree文件系统,通常念成Butter FS,Better FS或B-tree FS,由Oracle与2007年研发,2014年8月发布稳定版,目标是取代Linux当前的ext3文件系统,改善ext3的限制,特别是单个文件的大小,总文件系统大小或文件检查和加入ext3未支持的功能,像是可写快照(writable snapshots)、快照的快照(snapshots of snapshots)、内建磁盘阵列(RAID),以及子卷(subvolumes)。Btrfs也宣称专注在“容错、修复及易于管理”。
其和核心特性如下
- 联机碎片整理
- 联机卷生长和收缩
- 联机块设备增加和删除
- 联机负载均衡(块设备间的对象移动以达到平衡)
- 文件系统级的镜像(类RAID-1)、条带(类RAID-0)
- 子卷(一个或多个单独可挂载基于每个物流分区)
- 透明压缩(当前支持zlib、LZO和ZSTD (从 4.14 开始支持))
- 快照(只读和可写,写复制,子卷复制)
- 文件克隆
- CoW支持:复制、更新及替换指针,而非“就地”更新
- 数据和元数据的校验和(当前是CRC-32C)
- 就地转换(带回滚)ext3/4
- 文件系统种子
- 用户定义的事务
- 块丢弃支持
6. 文件系统管理相关命令
文件系统创建
Linux文件系统逻辑上由两部分组成
- 内核中的模块,如ext4,xfs,vfat
- 用户空间的管理工具,如mkfs.ext4,mkfs.xfs,mkfs.vfat
此处将介绍这些管理工具,需要注意的是,创建文件系统会损坏原有文件
mkfs
mkfs即MaKe FileSystem之意,用户创建文件系统,使用格式为
mkfs -t FS_TYPE [-L LABEL] /dev/DEVICE
需要说明的是,使用mkfs -t FS_TYPE等效于mkfs.FS_TYPE命令,如
mkfs -t ext2 = mkfs.ext2
mkfs -t ext3 = mkfs.ext3
系统中有众多以mkfs.开头的命令:
[root@localhost ~]# mkfs.
mkfs.btrfs mkfs.ext2 mkfs.ext4 mkfs.minix mkfs.vfat
mkfs.cramfs mkfs.ext3 mkfs.fat mkfs.msdos mkfs.xfs
在/proc/filesystems文件中显示当前内核所支持的文件系统
mke2fs
该命令专用户创建ext家族的文件系统,其用法为
mke2fs OPTIONS /dev/DEVICE
OPTIONS
-t {ext2|ext3|ext4} 指定文件系统类型,默认为ext2
-j 即Journal,创建ext3类型文件系统,等于-t ext3
-b {1024|2048|4096} 指定块大小,默认为4096
-L LABEL 指定分区卷标
e2lable /dev/DEVICE 查看设备的卷标
e2lable /dev/DEVICE LABLE 设置卷标
-m # 指定预留给管理员的块数百分比,默认为5,指定时不用加%
-i # 意为bytes per inode
用于指定为多少个字节的空间创建一个inode,默认为8192,这里给出的数值应该为块大小的2^n倍
在nke2fs的配置文件(/etc/mke2fs.conf)中为创建不同大小的分区指定了相应的值(inode_ratio)
-I # 指定inode大小
-N # 指定要创建的inode个数
-F 强制创建文件系统,默认当文件系统被挂载时,不能创建
-E 用于指定额外的文件系统属性
-O FEATURE [, … ] 启用指定分区特性
-O ^FEATURE 关闭指定分区特性
故要创建ext系列文件系统,以下命令等效
ext3:mkfs -t ext3 = mkfs.ext3 = mke2fs -t ext3 =mke2fs -j
ext4:mkfs -t ext4 = mkfs.ext4 = mke2fs -t ext4
其他管理命令
blkid
blkid即block id,用于显示或定位block设备的属性,使用格式为
blkid [OPTIONS] /dev/DEVICE
-U UUID 根据UUID(统一全局标示符)查找设备
-L LABEL 根据卷标查找设备
如
[root@localhost ~]# blkid /dev/sda
/dev/sda: PTTYPE="dos"
[root@localhost ~]# blkid /dev/sda1
/dev/sda1: UUID="a8cac4fb-841a-421d-ba11-ea7eee1c57bc" TYPE="xfs"
tune2fs
该命令用于查看或设定ext系列文件系统的可调整参数的值,用法如下
tune2fs OPTIONS DEVICE
OPTIONS
-j 不损坏原有数据,将ext2升级为ext3
可以将ext3文件系统挂载为etx2,不使用日志区,但不能降级
-L LABEL 设定或修改卷标
-m # 调整给超级用户预留的空间百分比
-r # 指定预留块数
-o 设定文件系统的默认挂载选项
# tune2fs -o MOUNT-OPTION 设备 指定默认挂载属性
# tune2fs -o ^MOUNT-OPTION 设备 取消默认挂载属性
acl Enable Posix Access Control Lists
-O 调整分区特性
tune2fs -l结果中的Filesystem features字段即为分区特性
在特性前加^表示关闭该特性,不加表示打开,如
tune2fs -O ^huge_file /dev/sda1 关闭huge_file特性
tune2fs -O huge_file /dev/sda1 打开huge_file特性
在设定或清除了某些特性,必须执行e2fsck命令,man tune2fs查看详情
-c # 指定挂载次数达到#次之后进行自检,0或-1表示关闭此功能
-U UUID 修改UUID
-i # 指定没挂载多少天后进行自检,0或-1表关闭此功能
-l 显示指定文件系统超级块中保存的信息,类似于dumpe2fs -h
再次强调,在设定或清除了某些特性,必须执行e2fsck命令进行检查
lsblk
即list block,用于查看系统上的磁盘列表,如
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 120G 0 disk
├─sda1 8:1 0 500M 0 part /boot
└─sda2 8:2 0 119.5G 0 part
├─centos-root 253:0 0 50G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 67.5G 0 lvm /home
sdb 8:16 0 100G 0 disk
sdc 8:32 0 20G 0 disk
sdd 8:48 0 20G 0 disk
└─sdd1 8:49 0 5G 0 part
sr0 11:0 1 1024M 0 rom
dumpe2fs
该命令用于查看ext系列文件系统信息,可使用-h选项查看超级块中的信息如
[root@localhost ~]# dumpe2fs -h /dev/sdd1
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name:
Last mounted on: /mnt
Filesystem UUID: 7b7a81d1-d456-4acc-8a68-ebdef42d126b
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 327680
Block count: 1310720
Reserved block count: 65536
Free blocks: 1252257
Free inodes: 327668
First block: 0
Block size: 4096
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 639
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Wed Jan 9 00:49:52 2019
Last mount time: Wed Jan 9 00:50:18 2019
Last write time: Wed Jan 9 00:52:27 2019
Mount count: 1
Maximum mount count: -1
Last checked: Wed Jan 9 00:49:52 2019
Check interval: 0 ()
Lifetime writes: 213 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: e67934ba-be08-4b9d-a0e7-e22212798ebe
Journal backup: inode blocks
Journal features: journal_64bit
Journal size: 128M
Journal length: 32768
Journal sequence: 0x00000006
Journal start: 0
e2label
该命令用于管理ext系列文件系统的LABEL,实施上以上的其他命令有的选项也可指定LABEL,该命令用法交文件单,使用格式为e2label DEVICE NEW_LABEL
fsck
即File System ChecK,用于检测及修复文件系统,其使用格式为
fsck [OPTIONS] DEVICE
OPTIONS
-t FSTYPE 指定文件系统类型
-f 强行检测(默认若没有问题,则略过检测)
-a 自动修复错误
-r 交互式修复错误
需要说明的是,在指定文件系统类型时,一定要与分区上已有的文件系统类型相同,并且与mkfs类似,该命令也有fsck.FS_TYPE的类型
同时,还有一个专用于ext系列文件系统检查的工具e2fsck,使用时会自动判定文件系统:
e2fsck [OPTIONS] DEVICE
OPTIONS
-t 显示e2fsck执行的时间统计
-f 强制修复
-p 自动修复
-y 自动回答为yes
此外,建议文件系统离线检测
BtrFS管理命令
BtrFS相关命令均以“btrfs”开头,有众多子命令,此处从文件系统创建开始进行说明
-
文件系统创建:
mkfs.btrfs-L 'LABEL' 指定卷标 -d数据存储类型 raid0|raid1|raid5|raid10|raid6|single -m 元数据存储类型 raid0|raid1|raid5|raid10|raid6|single|dup -O 启用的特性 -O list-all 列出支持的所有特性 关于RAID,下文将做介绍
-
属性查看
btrfs filesystem show DEVICE DEVICE可以是欲查看BTRFS下的任意设备,如使用/dev/sdb,/dev/sdc创建了一个BTRFS,则此处指定为二者之一均可可查看btrfs-filesystem(8)获取详细信息
-
启用透明压缩机制
mount -o compress={lzo|zlib} DEVICE MOUNT_POINT -
在线修改文件系统大小
btrfs filesystem resize ([+|-]#[KMGT…])|max /DEVICE 指定为max可直接调整为最大 -
为btrfs增加设备
btrfs device add DEVICE MOUNTPOINT 如:btrfs device /dev/sdd /mydata(/mydata是btrfs设备的挂载点) -
文件系统平衡
btrfs balance start MOUNTPOINT -
拆除设备
btrfs device delete DEVICE MOUNTPOINT
-
修改数据或元数据存储方式
btrfs balance start -[d|m]convert=[raid0|raid1|raid10|raid5|raid6|dup|single] MOUNT_POINT -d:数据存储方式 -m:元数据存储方式 -d或m与comvert之间没有空格 注意不同raid级别对于设备个数的要求可查看btrfs-device(8)获取详细信息
-
创建子卷
btrfs subvolume create /PARENT_VOLUME_MOUNT_POINT/SUB_VOLUME_NAME 如:# btrfs subvolume create /mydata/logs创建子卷后,子卷可单独挂载(下文将做详细介绍)
mount -o subvol=SUB_VOLUME_NAME DEVICE SUB_VOLUME_MOUNT_POINT或
mount -o subvolid=SUB_VOLUME_ID DEVICE SUB_VOLUME_MOUNT_POINT可查看btrfs-subvolume(8)获取详细信息
子卷可单独挂载,而挂载父卷后,子卷将被自动挂载
可对子卷再次创建子卷
-
查看子卷信息
btrfs subvolume list /PARENT_VOLUME_MOUNT_POINT ID为子卷ID -
删除子卷
btrfs subvolum delete SUB_VOLUME -
为子卷创建快照卷
快照原理同LVM(下文将做介绍),创建的快照卷需与子卷属于同一个父卷btrfs subvolume snapshot SUB_VOLUME SNAPSHOT_VOLUME SNAPSHOT_VOLUME为待新建的快照卷,如 btrfs subvolume snapshot /mydata/logs/ /mydata/logs_snapshot 查看信息: # btrfs subvolume list /mydata/ ID 264 gen 74 top level 5 path cache ID 265 gen 78 top level 5 path logs ID 266 gen 78 top level 5 path logs_snapshot删除快照卷的方式同删除子卷
-
为单个文件做快照
基于BTRFS的CoW特性实现,即在修改文件时将原文件复制,修改复制出的新文件,修改完成后将文件指针指向新文件cp --reflink ORIGIN_FILE SNAP_FILE ORIGIN_FILE应与SNAP_FILE位于同一卷中 -
将ext系列文件系无损统转换为BTRFS
btrfs-convert DEVICE转换完成后,会生成
ext2_saved文件,保存有原ext文件系统相关元数据信息 -
还原回ext文件系统
btrfs-convert -r DEVICE
7. 挂载
什么是挂载
将一块磁盘分区并格式化为特性文件系统之后,就可以使用了,而我们显然不能只是通过其设备文件进行读写操作。
在Windows系统中,我们可以为每一个分区指定一个盘符,以此来访问该分区,如C:\Windows\notepad.exe,需要说明的是,Windows使用反斜线\作为路径分隔符的
而在Linux系统中,一切资源的访问都是由根/开始,因此我们不能通过绑定盘符的方式直接访问。我可可以将分区绑定到某一目录,该目录即为此分区的访问入口,这就是挂载(Mount),该目录一般被称为挂载点(Mount Point)
如,若将上面的C盘挂载到Linux系统的/mnt/windows_file目录,则该记事本程序的访问路径为/mnt/windows_file/Windows/notepad.exe
此外,需要注意的是,挂载点下可以有其他文件,但是挂载分区后,该目录下的文件将被隐藏,因为此时访问该目录实质上访问的是挂载的分区中的文件,卸载分区后,挂载点目录中原有文件就可重新访问
相关命令
mount
顾名思义,该命令用于文件系统挂载,其用法为
mount [options] [-t FSTYPE] [-o options] DEVICE MOUNT_POINT
options
-a 自动挂载/etc/fstable文件中定义的所有支持自动挂载的设备
-n 不更新/etc/mtab
默认情况下,每挂载(或卸载)一个设备,都会把挂载的设备信息保存至/etc/mtab文件中(使用不带任何参数的mount命令显示的就是该文件的内容)
应用-n选项意味着挂载设备时,不把信息写入此文件
/proc/mounts中可查看内核追踪到的已挂载的所有设备
-t FSTYPE
指定正在挂载设备上的文件系统的类型,不使用此选项时,mount会调用blkid命令获取对应文系统的类型
-r 只读挂载,挂载光盘时常用此选项,等于-o ro
-w 读写挂载
-L LABEL 以卷标指定挂载设备,LABEL="卷标"也可以
-U UUID 以UUID指定挂载设备,UUID="UUID"也可以
-B, --bind 绑定目录到另一个目录上
可以实现将两个目录绑定
-bind DIR1 DIR2 将DIR1绑定到DIR2上
-o 指定额外的挂载选项,也即指定文件系统启用的属性
可同时使用多个,使用逗号分隔
关于DEVICE,即为要挂载的设备,可以指定为:
- 设备文件:如
/dev/sda5 - 卷标:
LABEL="卷标",或-L "卷标" - UUID:
UUID="UUID",或-U 'UUID' - 伪文件系统名称:
proc,sysfs,devtmpfs,configfs等
关于挂载选项,有以下常用选项
| 选项 | 说明 |
|---|---|
| async | 启用异步I/O,默认启用 |
| sync | 启用同步I/O |
| atime | 每次访问都更新访问时间,包括目录和文件, noatime可关闭该特性 |
| diratime | 每次访问都更新访问时间,只有目录, nodiratime可关闭该特性 |
| auto | 可以使用-a选项自动挂载, noauto可关闭该特性 |
| dev | 允许启用设备上的设备文件(如果有), nodev可关闭该特性 |
| exec | 允许执行二进制文件, noexec可关闭该特性 |
| group | 允许普通用户挂载,要求用户的在设备的属组中 |
| _netdev | 若挂载的文件系统不在本地,而且无法连接到时,就不再继续挂载(默认会一直尝试挂载) |
| remount | 重新挂载当前文件系统 如: mount -o remount,rw /dev/sda1 挂载为读写,挂载点不变 |
| suid | 是否SUID与SGID权限位生效, nosuid可关闭该特性 |
| acl | 启用此文件系统上的FACL, 可以使用 tune2fs -o acl使其默认启用,前面加^关闭 |
| ro | 挂载为只读 |
| rw | 读写挂载 |
| user/nouser | 是否允许普通用户挂载此设备 |
| defaults | 默认挂载选项,相当于 rw, suid, dev, exec, auto, nouser, and async CentOS7之前为: rw, suid, dev, exec, auto, nouser, and async |
使用不带任何参数的mount命令可查看系统当前已挂载的设备
另外,可通过以下命令查看当前系统所有已挂载的设备
mountcat /etc/mtabcat /proc/mounts
关于挂载,还有一个小话题:挂载特殊设备
-
- 挂载光盘设备
-
光盘设备文件
- IDE:
/dev/dhc - SATA:
/dev/sr0
- IDE:
-
而其有众多的符号链接文件,如
/dev/cdrom/dev/cdrw/dev/dvd/dev/dvdrw
-
光盘设备问文件系统类型为
iso9600,不过在挂载光盘时可以不指定文件系统类型,系统可自动识别 -
故挂载光盘的一般方式为:
mount -r /dev/cdrom MOUNT_POINT
-
- 挂载ISO镜像(本地回环设备)
- 可以将ISO镜像文件像光盘一样挂载
-
挂载时指定
-o loop选项即可,如 -
mount -o loop /root/rhci-5.8-1.iso /media/
umount
该命令用于卸载设备,命令后跟设备或挂载点均可,即
mount DEVICE|MOUNT_POINT
注意:挂载的设备应该没有被进程使用
若设备不空闲,可使用lsof或fuser查看
fuser
identify processes using filesorsockets
-v Verbose mode
例:fuser -v /media/cdrom
-k Kill processes accessing the file
-m specifies a file on a mounted file system or a block device that is mounted
查看占用挂载点的进程:fuser -v MOUNT_POINT
杀死占用挂载点的进程:fuser -km MOUNT_POINT
df
该命令可查看文件系统的空间使用情况,用法问
df [OPTION]... [FILE]…
OPTION
-l limit listing to local file systems
-h human readable format
-i list inode information instead of block usage
-P use the POSIX output format
POSIX: Protable Operating System Interface
如
[root@localhost ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/centos-root 52403200 4923984 47479216 10% /
devtmpfs 924592 0 924592 0% /dev
tmpfs 935256 0 935256 0% /dev/shm
tmpfs 935256 9232 926024 1% /run
tmpfs 935256 0 935256 0% /sys/fs/cgroup
/dev/sda1 508588 128308 380280 26% /boot
/dev/mapper/centos-home 70687004 33204 70653800 1% /home
tmpfs 187052 0 187052 0% /run/user/0
du
我们在使用ls -l查看目录大小时,显示的是目录本身的大小而非是目录内文件的大小。而du命令可用于评估文件占用磁盘的空间情况,使用格式为
du [OPTIONS] [FILES]
OPTIONS
-s summarize,显示目录大小,默认会递归显示
-h human readable
hdparm
该命令可扩区STAT/IDE设备的相关参数,使用格式为
hdparm [OPTIONS] [DEVICE]
OPTIONS
-i 显示内核识别的信息
-I 直接从硬盘上读取信息
-g Display the drive geometry,显示布局信息
-t 评估硬盘的读取效率
-T 评估硬盘快取的读取效率
/etc/fstab文件
系统在初始化时,会读取该文件,将该文件中指定的设备挂载,故该文件可被称为文件挂载的配置文件
其内容如下
[root@localhost ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed Dec 19 20:12:26 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
#开头的为注释,该文件每行定义一个要挂载的文件系统,共有6个字段,中间使用空白字符(一般为空格括横向制表符)分隔,格式为
fs_spec fs_file fs_vfstype fs_mntops fs_freq fs_passno
fs_spec:要挂载的设备文件或伪文件系统,可指定为:
设备文件
LABEL=
UUID=
伪文件系统名(proc,sysfs,…)
fs_file:挂载点
swap没有挂载点,使用swap时,应指定为swap
fs_vfstype:文件系统类型
fs_mntops:挂载选项
多个选项间使用逗号(,)分隔
fs_freq :转储频率,即备份频率
0:从不备份,1:每日备份,2:每2日备份
fs_passno:自检次序
0:不自检
1:首先自检,通常只能被rootfs使用
…
9
自检的次序可以相同
编辑完成后,会在下次系统启动时挂载,欲立即挂载,使用mount -a
8. 例
- 创建一个2G的分区,文件系统为ext2,卷标为DATA,块大小为1024,预留管理空间为磁盘分区的8%,挂载至/backup目录,要求使用卷标进行挂载,且在挂载时启动此文件系统上的acl功能
# mke2fs -L DATA -b 1024 -m 8 /dev/sda7
# mount -o acl LABEL=DATA /backup
# tune2fs -o acl /dev/sda7
# mount LABEL=DATA /backup
- 将此文件系统的超级块中的信息中包含了block和inode的行保存至/tmp/partition.txt中
tune2fs -l | egrep -i "block|inode" >> /tmp/partition.txt
- 复制/etc目录中的所有文件至此文件系统,而后调整此文件系统类型为ext3,要求不能损坏已经复制而来的文件
# cp -r /etc/* /backup
# tune2 -j /dev/sda7
- 调整其预留百分比为3%
# tune2fs -m 3 -L DATA /dev/sda7
- 以重新挂载的方式挂载此文件系统为不更新访问时间戳,并验正其效果
# stat /backup/inittab
# cat /backup/inittab
# stat
# mount -o remount,noatime /backup
# cat
# stat
- 对此文件系统强行做一次检测
# e2fsck -f /dev/sda7
- 删除复制而来的所有文件,并将此文件系统重新挂载为同步(sync),后再次复制/etc目录中的所有文件至此挂载点,体验其性能变化
# rm -rf /backup/*
# mount -o remount,sync /backup
# cp -r /etc/* /backup
三、RAID
1. RAID是什么
RAID(Redundant Array of Independent Disks)独立硬盘冗余阵列,旧称廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),简称磁盘阵列。
其基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、容量巨大的硬盘。
1987年,加州大学伯克利分校的Patterson,Gibson和Katz发表了一篇题为“A Case for Redundant Array of Inexpensive Disks(RAID)”的论文,讲述了RAID8。是时,数据主要存储在昂贵的大型磁盘驱动程序(称为SLED,Single Large Expensive Disk)上。而后来,RAID也越来越贵了,就将Inexpensive(廉价)改成了Independent(独立)?
2. RAID的实现方式
- 外接式磁盘阵列:通过扩展卡提供适配能力
- 内接式RAID:主板集成RAID控制器
- Software RAID:软件模拟实现的RAID
3. 常用的RAID级别介绍
根据选择的RAID版本(级别)不同,RAID比单颗硬盘有以下一个或多个方面的好处:增强数据集成度,增强容错功能,增加处理量或容量。另外,磁盘阵列对于计算机来说,看起来就像一个单独的硬盘或逻辑存储单元。常用的有RAID-0,RAID-1,RAID-5,RAID-6,RAID-01,RAID-10,RAID-50,RAID-60。
需要说明到的是,RAID各级别之间没有直接的孰优孰劣之分,RAID级别仅表示其底层数据不同的组织管理方式
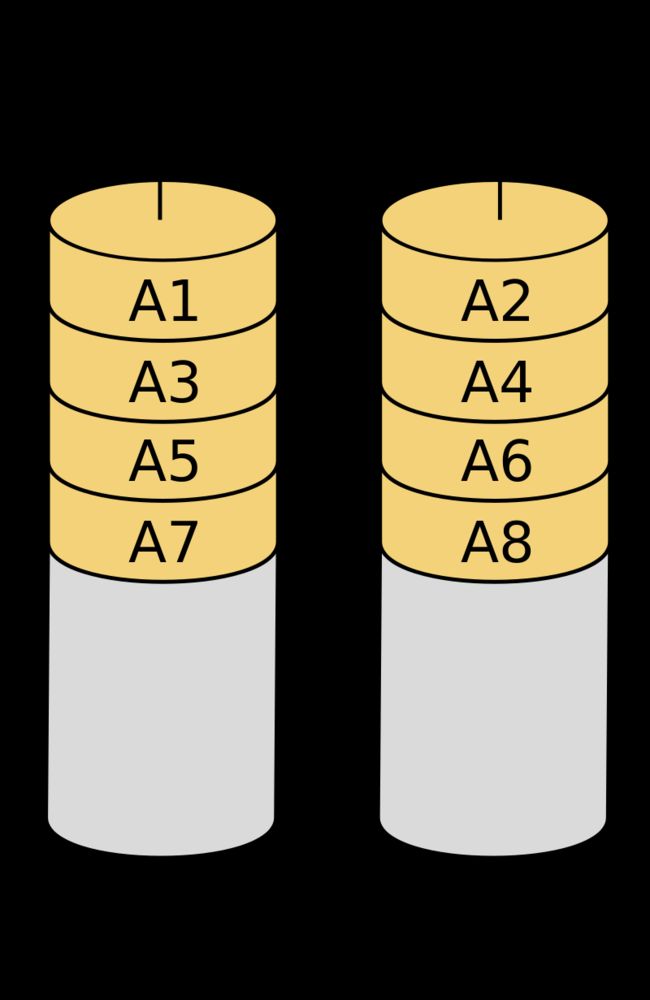
RAID 0
RAID 0亦称为带区集(strip)。它将两个以上的磁盘并联起来,成为一个大容量的磁盘。在存放数据时,分段后分散存储在这些磁盘中,因为读写时都可以并行处理,所以在所有的级别中,RAID 0的速度是最快的。但是RAID 0既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失,危险程度与JBOD相当。
RAID 1

两组以上的N个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,与RAID 0相同。另外写入速度有微小的降低。只要一个磁盘正常即可维持运作,可靠性最高。其原理为在主硬盘上存放数据的同时也在镜像硬盘上写一样的数据。当主硬盘(物理)损坏时,镜像硬盘则代替主硬盘的工作。因为有镜像硬盘做数据备份,所以RAID 1的数据安全性在所有的RAID级别上来说是最好的。但无论用多少磁盘做RAID 1,仅算一个磁盘的容量,是所有RAID中磁盘利用率最低的一个级别。
可用空间为
S i z e = m i n ( S 1 , S 2 , S 3 , . . . ) Size=min(S_1,S_2,S_3,...) Size=min(S1,S2,S3,...)
如果用两个不同大小的磁盘建RAID 1,可用空间为较小的那个磁盘,较大的磁盘多出来的空间也可以分割成一个区来使用,不会造成浪费
RAID 4
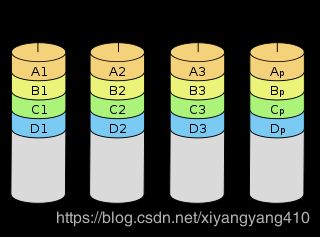
RAID4使用一块盘作为其他盘上数据的校验码(异或)盘,(块交织技术,Block interleaving)允许其中一个盘坏掉
由于访问任何一块盘都可能使用到校验盘,遂校验盘会成为瓶颈
RAID 5
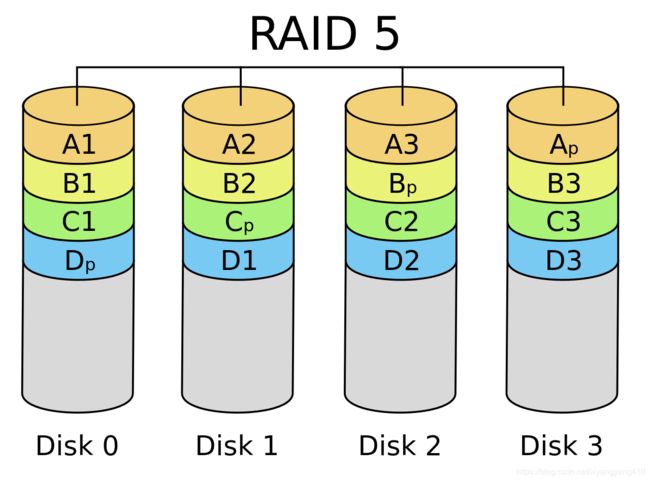
RAID5使用的是Disk Striping(硬盘分割)技术,各盘轮流作为校验盘。RAID 5至少需要三个硬盘,RAID 5不是对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。
当RAID5的一个磁盘数据发生损坏后,可以利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但保障程度要比镜像低而磁盘空间利用率要比镜像高。
RAID 5具有和RAID 0相近似的数据读取速度,只是因为多了一个奇偶校验信息,写入数据的速度相对单独写入一块硬盘的速度略慢,若使用“回写缓存”可以让性能改善不少。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较便宜。
可用容量为
S i z e = ( N − 1 ) ∗ m i n ( S 1 , S 2 , S 3 , . . . S n ) Size=(N-1) * min(S_1,S_2,S_3,...S_n) Size=(N−1)∗min(S1,S2,S3,...Sn)
RAID 6
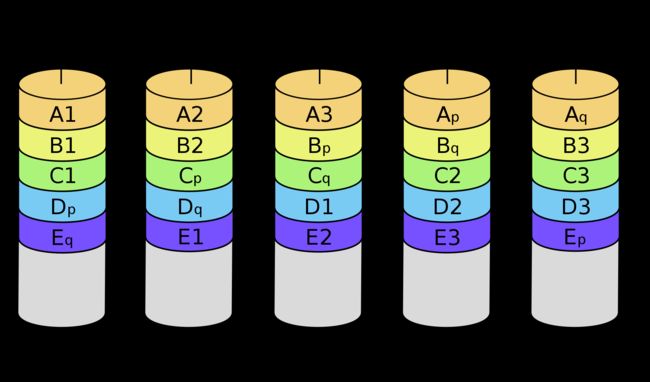
与RAID 5相比,RAID 6增加第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,任意两块磁盘同时失效时不会影响数据完整性。RAID 6需要分配给奇偶校验信息更大的磁盘空间和额外的校验计算,相对于RAID 5有更大的IO操作量和计算量,其“写性能”强烈取决于具体的实现方案,因此RAID 6通常不会通过软件方式来实现,而更可能通过硬件方式实现。
同一数组中最多容许两个磁盘损坏。更换新磁盘后,数据将会重新算出并写入新的磁盘中。
依照设计理论,RAID 6必须具备四个以上的磁盘才能生效。可使用的容量为硬盘总数减去2的差,乘以最小容量,公式为:
S i z e = ( N − 2 ) ∗ m i n ( S 1 , S 2 , S 3 , . . . S n ) Size=(N-2) * min(S_1,S_2,S_3,...S_n) Size=(N−2)∗min(S1,S2,S3,...Sn)
同理,数据保护区域容量则为最小容量乘以2。
RAID 6在硬件磁盘阵列卡的功能中,也是最常见的磁盘阵列档次。
以下表格对比了各RAID特性9
| 项目 | RAID0 | RAID1 | RAID10 | RAID5 | RAID6 |
|---|---|---|---|---|---|
| 最少硬盘数 | 2 | 2 | 4 | 3 | 4 |
| 最大容错磁盘数 | 无 | n-1 | n/2 | 1 | 2 |
| 资料安全性 | 完全没有 | 最佳 | 最佳 | 好 | 比RAID5 好 |
| 理论写入性能 | n | 1 | n/2 | ||
| 理论读出性能 | n | n | n | ||
| 可用容量 | n | 1 | n/2 | n-1 | n-2 |
| 一般应用 | 强调效能但资料不重要的环境 | 资料与备份 | 服务器、云系统常用 | 资料与备份 | 资料与备份 |
组合方案
可以将多种RAID进行组合,从而实现更可靠的存储方案,常用的组合方案有
- RAID 10
- RAID 01
- RAID 50
- RAID 60
组合RAID级别的数字,左边的即为实际RAID的下层,如RAID 10即将多组RADI1组合成RAID0,01即将多组RADI0组合成RAID1,如下图所示
RAID 10
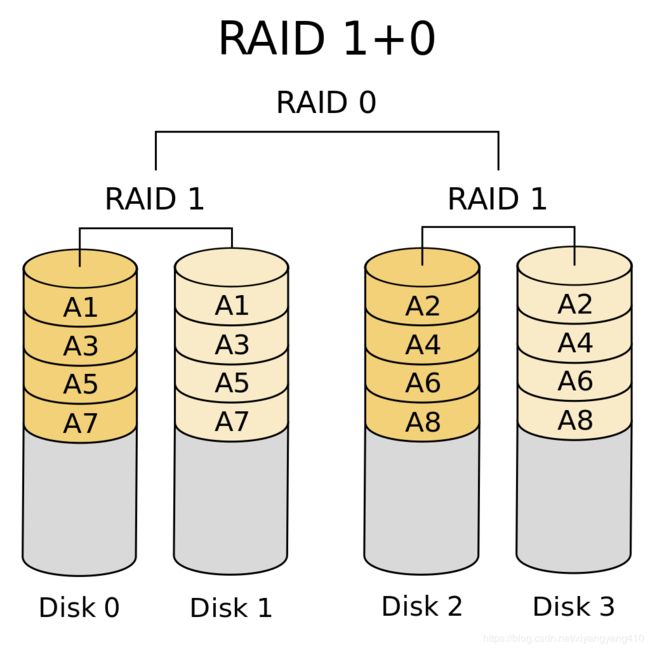
RAID 10是先镜射再分割数据,再将所有硬盘分为两组,视为是RAID 0的最低组合,然后将这两组各自视为RAID 1运作
当RAID 10有一个硬盘受损,其余硬盘会继续运作
RAID 01
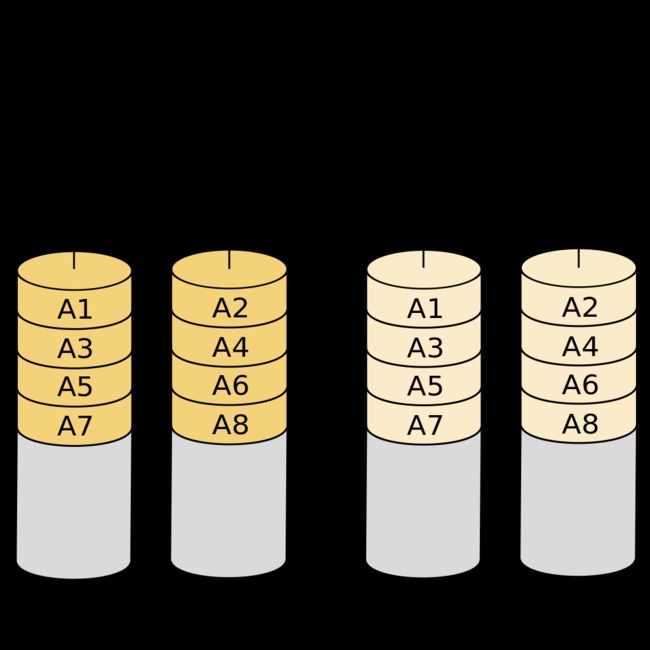
RAID 01则是跟RAID 10的程序相反,是先分割再将数据镜射到两组硬盘。它将所有的硬盘分为两组,变成RAID 1的最低组合,而将两组硬盘各自视为RAID 0运作
RAID 01只要有一个硬盘受损,同组RAID 0的所有硬盘都会停止运作,只剩下其他组的硬盘运作,可靠性较低
RAID 50
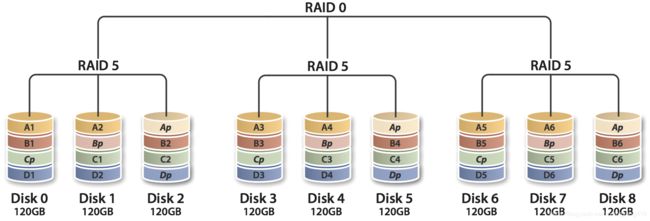
RAID 5与RAID 0的组合,先作RAID 5,再作RAID 0,也就是对多组RAID 5彼此构成Stripe访问。
由于RAID 50是以RAID 5为基础,而RAID 5至少需要3颗硬盘,因此要以多组RAID 5构成RAID 50,至少需要6颗硬盘。以RAID 50最小的6颗硬盘配置为例,先把6颗硬盘分为2组,每组3颗构成RAID 5,如此就得到两组RAID 5,然后再把两组RAID 5构成RAID 0。
RAID 50在底层的任一组或多组RAID 5中出现1颗硬盘损坏时,仍能维持运作,不过如果任一组RAID 5中出现2颗或2颗以上硬盘损毁,整组RAID 50就会失效。
RAID 50由于在上层把多组RAID 5构成Stripe,性能比起单纯的RAID 5高,容量利用率比RAID5要低。
RAID 60

RAID 6与RAID 0的组合:先作RAID 6,再作RAID 0。换句话说,就是对两组以上的RAID 6作Stripe访问。RAID 6至少需具备4颗硬盘,所以RAID 60的最小需求是8颗硬盘。
由于底层是以RAID 6组成,所以RAID 60可以容许任一组RAID 6中损毁最多2颗硬盘,而系统仍能维持运作;不过只要底层任一组RAID 6中损毁3颗硬盘,整组RAID 60就会失效,当然这种情况的机率相当低。
比起单纯的RAID 6,RAID 60的上层透过结合多组RAID 6构成Stripe访问,因此性能较高。不过使用门槛高,而且容量利用率低是较大的问题。
4. JBOD
JBOD( Just a Bunch Of Disks),磁盘簇,在分类上,JBOD并不是RAID。只是将多个硬盘空间合并成一个大的逻辑硬盘,没有错误备援机制
5. 模拟RAID实现
大体来讲RAID可以有软件RAID(software RAID)与硬件RAID(hardware RAID),硬件RAID是通过磁盘阵列卡来达成阵列的目的,磁碟阵列卡上面有一块专门的处理器在处理RAID的任务
在实现时,硬件的磁盘阵列使用较为简单,加之由于设备的不同操作亦可能不同,此处主要说明使用软件来模拟RAID的实现方式,Linux中主要通过mdadm命令实现
MD模块
mdadm命令结合内核中的md(multi devices)模块工作,事实上应该说,Linux中可以通过md模块来实现软RAID,在用户空间用mdadm来管理软RAID设备
我们可以在机器启动后通过cat /proc/mdstat看内核是否已经加载MD驱动或者cat /proc/devices是否有md块设备
[root@localhost ~]# cat /proc/mdstat
Personalities :
unused devices:
[root@localhost ~]# cat /proc/devices | grep md
9 md
254 mdp
md模块可以将多块硬盘,通过软件的方式,组合起来,形成RAID,要是用的话,需要通过这个模块来访问,若直接通过/dev/sd*访问,则还是独立的磁盘
在Linux中,使用软RAID,先模拟一个RAID,设备文件为/dev/md,系统在使用时,内核在内部将数据化成对应的格式,proc/mdstat文件会显示当前系统上所有已经启用的RAID设备
mdadm
mdadm即md admin,通过该命令,可以将任何块设备做成RAID,该命令是模式化命令,注意,adadm只是管理工具,与RAID实际工作无关,支持的RAID级别:LINEAR,RAID0,RAID1,RAID4,RAID5,RAID6,RAID10,配置文件为/etc/mdadm.conf
有以下常用模式
| 模式 | 说明 |
|---|---|
| Create | 创建模式,使用空闲的设备创建一个新的阵列,每个设备具有元数据块 |
| Assemble | 装配模式,将原来属于一个阵列的每个块设备组装为阵列 |
| Manage | 管理已经存储阵列中的设备,比如增加热备磁盘或者设置某个磁盘失效,然后从阵列中删除这个磁盘 |
| Grow | 增长模式,改变阵列中每个设备被使用的容量或阵列中的设备的数目 |
| Follow or Monitor | 监控模式,监控一个或多个阵列,上报指定的事件 |
| Manage | 管理模式,停止、拆散RAID,默认处于管理模式 |
该命令使用格式为
mdadm [mode] [options]
:/dev/md#
:可以是任意块设备
mode:模式
-A:装配模式
-C:创建模式
一般-C后要跟设备文件(md#)
可以查看/proc/mdstat获取已经启用的RAID信息
专用选项
-l # 指定RAID级别
-n # 用于创建RAID设备的设备个数
-a yes|no 是否自动为创建的RAID设备创建设备文件
-c # 指定chunk(数据块)大小,2^n,默认是512K
系统在实现软RAID时,每生成一个chunk,都会计算相当于多少个磁盘块
为提升RAID性能,创建好RAID后,在格式化时,在使用mke2fs命令中使用-b指定block后可加-E stride来指定条带(即chunk除以block的商),这样就避免了每次计算
-x # 指定热备盘个数
x的个数+n的个数应该与命令后给出的盘的个数一致
-F:监控模式
-G:增长模式
默认为管理模式
-f|--fail 模拟设备损坏,如:
mdadm /dev/md# --fail /dev/sda7 模拟md#阵列中的sda7损坏
-r|--remove 移除磁盘
-a|--add 加入新磁盘
-S 停止阵列
-D|--detail 显示阵列的详细信息
-D --scan 查看当前系统上的RAID设备详细信息
将当前RAID信息保存至配置文件,以便以后进行装配:
mdamd -D --scan > /etc/mdadm.conf
例
此处将创建一个RAID5,并进行相关管理操作。需要说明的是,RAID用于提升续写性能或可用性,故将同一磁盘上的不同分区模拟为RAID没有现实意义,此处仅作实例进行说明
- 创建分区
[root@localhost ~]# fdisk /dev/sdd
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-41943039, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-41943039, default 41943039): +2G
Partition 1 of type Linux and of size 2 GiB is set
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): p
Partition number (2-4, default 2):
First sector (4196352-41943039, default 4196352):
Using default value 4196352
Last sector, +sectors or +size{K,M,G} (4196352-41943039, default 41943039): +2G
Partition 2 of type Linux and of size 2 GiB is set
Command (m for help): n
Partition type:
p primary (2 primary, 0 extended, 2 free)
e extended
Select (default p): p
Partition number (3,4, default 3):
First sector (8390656-41943039, default 8390656):
Using default value 8390656
Last sector, +sectors or +size{K,M,G} (8390656-41943039, default 41943039): +2G
Partition 3 of type Linux and of size 2 GiB is set
Command (m for help): t
Partition number (1-3, default 3): 1
Hex code (type L to list all codes): fd
Changed type of partition 'Linux' to 'Linux raid autodetect'
Command (m for help): t
Partition number (1-3, default 3): 2
Hex code (type L to list all codes): fd
Changed type of partition 'Linux' to 'Linux raid autodetect'
Command (m for help): t
Partition number (1-3, default 3): 3
Hex code (type L to list all codes): fd
Changed type of partition 'Linux' to 'Linux raid autodetect'
Command (m for help): n
Partition type:
p primary (3 primary, 0 extended, 1 free)
e extended
Select (default e): e
Selected partition 4
First sector (12584960-41943039, default 12584960):
Using default value 12584960
Last sector, +sectors or +size{K,M,G} (12584960-41943039, default 41943039):
Using default value 41943039
Partition 4 of type Extended and of size 14 GiB is set
Command (m for help): n
All primary partitions are in use
Adding logical partition 5
First sector (12587008-41943039, default 12587008):
Using default value 12587008
Last sector, +sectors or +size{K,M,G} (12587008-41943039, default 41943039): +2G
Partition 5 of type Linux and of size 2 GiB is set
Command (m for help): t
Partition number (1-5, default 5):
Hex code (type L to list all codes): fd
Changed type of partition 'Linux' to 'Linux raid autodetect'
Command (m for help): p
Disk /dev/sdd: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x91df3cad
Device Boot Start End Blocks Id System
/dev/sdd1 2048 4196351 2097152 fd Linux raid autodetect
/dev/sdd2 4196352 8390655 2097152 fd Linux raid autodetect
/dev/sdd3 8390656 12584959 2097152 fd Linux raid autodetect
/dev/sdd4 12584960 41943039 14679040 5 Extended
/dev/sdd5 12587008 16781311 2097152 fd Linux raid autodetect
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
[root@localhost ~]# cat /proc/partitions
major minor #blocks name
8 48 20971520 sdd
8 49 2097152 sdd1
8 50 2097152 sdd2
8 51 2097152 sdd3
8 52 1 sdd4
8 53 2097152 sdd5
8 32 20971520 sdc
8 16 104857600 sdb
8 0 125829120 sda
8 1 512000 sda1
8 2 125316096 sda2
11 0 1048575 sr0
253 0 52428800 dm-0
253 1 2097152 dm-1
253 2 70721536 dm-2
- 创建RAID
[root@localhost ~]# mdadm -C /dev/md0 -l5 -n3 /dev/sdd[1-3] -x1 /dev/sdd5
mdadm: /dev/sdd1 appears to contain an ext2fs file system
size=5242880K mtime=Fri Feb 22 10:09:39 2019
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
此时,可查看/proc/mdstat文件查看当前RAID状态:
[root@localhost ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdd3[4] sdd5[3](S) sdd2[1] sdd1[0]
4190208 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [UU_]
[====>................] recovery = 22.0% (461452/2095104) finish=0.1min speed=230726K/sec
unused devices:
可通过watch命令进行动态显示,watch命令用法为:
watch:execute a program periodically, showing output fullscreen
周期性地执行一个程序,并以全屏方式显示
-n # 指定周期长度,单位为s,默认为2
一般格式为
watch -n # 'COMMAND' #和n之间可以没有空格
如:watch 'cat /proc/mdstat':重复执行命令,默认每隔2s刷新一次
- 挂载使用
MD设备可以像普通块设备那样直接读写,也可以做文件系统格式化
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=256 blocks
262144 inodes, 1047552 blocks
52377 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1073741824
32 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mount /dev/md0 /mnt/
[root@localhost ~]# cp /etc/fstab /mnt/
[root@localhost ~]# cat /mnt/
fstab lost+found/
[root@localhost ~]# cat /mnt/fstab
#
# /etc/fstab
# Created by anaconda on Wed Dec 19 20:12:26 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
-
查看RAID信息
4.1/proc/mdstat
如上介绍,可通过查看/proc/mdstat文件查看所有运行的RAID阵列的状态:[root@localhost ~]# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd3[4] sdd5[3](S) sdd2[1] sdd1[0] 4190208 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU] unused devices:在第一行中首先是MD的设备名,active和inactive选项表示阵列是否能读写,接着是阵列的RAID级别,后面是属于阵列的块设备,方括号[]里的数字表示设备在阵列中的序号,(S)表示其是热备盘,(F)表示这个磁盘是faulty状态。在第二行中首先是阵列的大小,单位是KB,接着是chunk-size的大小,然后是layout类型,不同RAID级别的layout类型不同,[3/3]和[UUU]表示阵列有3个磁盘并且3个磁盘都是正常运行的,若为[5/6]和[_UUUUU] 表示阵列有6个磁盘中5个都是正常运行的,下划线对应的那个位置的磁盘是faulty状态的
4.2
/sys/block/MD_DEVICE
此处可通过查看sys/block/md0查看相关信息[root@localhost ~]# ll /sys/block/md0/ total 0 -r--r--r--. 1 root root 4096 Feb 22 11:09 alignment_offset lrwxrwxrwx. 1 root root 0 Feb 22 11:09 bdi -> ../../bdi/9:0 -r--r--r--. 1 root root 4096 Feb 22 11:09 capability -r--r--r--. 1 root root 4096 Feb 22 11:09 dev -r--r--r--. 1 root root 4096 Feb 22 11:09 discard_alignment -r--r--r--. 1 root root 4096 Feb 22 11:09 ext_range drwxr-xr-x. 2 root root 0 Feb 22 11:07 holders -r--r--r--. 1 root root 4096 Feb 22 11:09 inflight drwxr-xr-x. 7 root root 0 Feb 22 11:01 md drwxr-xr-x. 2 root root 0 Feb 22 11:07 power drwxr-xr-x. 2 root root 0 Feb 22 11:01 queue -r--r--r--. 1 root root 4096 Feb 22 11:09 range -r--r--r--. 1 root root 4096 Feb 22 11:01 removable -r--r--r--. 1 root root 4096 Feb 22 11:09 ro -r--r--r--. 1 root root 4096 Feb 22 11:09 size drwxr-xr-x. 2 root root 0 Feb 22 11:07 slaves -r--r--r--. 1 root root 4096 Feb 22 11:09 stat lrwxrwxrwx. 1 root root 0 Feb 22 11:07 subsystem -> ../../../../class/block drwxr-xr-x. 2 root root 0 Feb 22 11:07 trace -rw-r--r--. 1 root root 4096 Feb 22 11:07 uevent [root@localhost ~]# ll /sys/block/md0/md/ total 0 -rw-r--r--. 1 root root 4096 Feb 22 11:20 array_size -rw-r--r--. 1 root root 4096 Feb 22 11:01 array_state drwxr-xr-x. 2 root root 0 Feb 22 11:07 bitmap --w-------. 1 root root 4096 Feb 22 11:20 bitmap_set_bits -rw-r--r--. 1 root root 4096 Feb 22 11:20 chunk_size -rw-r--r--. 1 root root 4096 Feb 22 11:20 component_size -r--r--r--. 1 root root 4096 Feb 22 11:20 degraded drwxr-xr-x. 2 root root 0 Feb 22 11:01 dev-sdd1 drwxr-xr-x. 2 root root 0 Feb 22 11:01 dev-sdd2 drwxr-xr-x. 2 root root 0 Feb 22 11:01 dev-sdd3 drwxr-xr-x. 2 root root 0 Feb 22 11:01 dev-sdd5 -rw-r--r--. 1 root root 4096 Feb 22 11:20 group_thread_cnt -r--r--r--. 1 root root 4096 Feb 22 11:20 last_sync_action -rw-r--r--. 1 root root 4096 Feb 22 11:20 layout -rw-r--r--. 1 root root 4096 Feb 22 11:20 level -rw-r--r--. 1 root root 4096 Feb 22 11:20 max_read_errors -rw-r--r--. 1 root root 4096 Feb 22 11:01 metadata_version -r--r--r--. 1 root root 4096 Feb 22 11:20 mismatch_cnt --w-------. 1 root root 4096 Feb 22 11:20 new_dev -rw-r--r--. 1 root root 4096 Feb 22 11:20 preread_bypass_threshold -rw-r--r--. 1 root root 4096 Feb 22 11:20 raid_disks lrwxrwxrwx. 1 root root 0 Feb 22 11:20 rd0 -> dev-sdd1 lrwxrwxrwx. 1 root root 0 Feb 22 11:20 rd1 -> dev-sdd2 lrwxrwxrwx. 1 root root 0 Feb 22 11:20 rd2 -> dev-sdd3 -rw-r--r--. 1 root root 4096 Feb 22 11:20 reshape_direction -rw-r--r--. 1 root root 4096 Feb 22 11:20 reshape_position -rw-r--r--. 1 root root 4096 Feb 22 11:20 resync_start -rw-r--r--. 1 root root 4096 Feb 22 11:20 safe_mode_delay -rw-r--r--. 1 root root 4096 Feb 22 11:20 skip_copy -r--r--r--. 1 root root 4096 Feb 22 11:20 stripe_cache_active -rw-r--r--. 1 root root 4096 Feb 22 11:20 stripe_cache_size -rw-r--r--. 1 root root 4096 Feb 22 11:20 suspend_hi -rw-r--r--. 1 root root 4096 Feb 22 11:20 suspend_lo -rw-r--r--. 1 root root 4096 Feb 22 11:20 sync_action -r--r--r--. 1 root root 4096 Feb 22 11:20 sync_completed -rw-r--r--. 1 root root 4096 Feb 22 11:20 sync_force_parallel -rw-r--r--. 1 root root 4096 Feb 22 11:20 sync_max -rw-r--r--. 1 root root 4096 Feb 22 11:20 sync_min -r--r--r--. 1 root root 4096 Feb 22 11:20 sync_speed -rw-r--r--. 1 root root 4096 Feb 22 11:20 sync_speed_max -rw-r--r--. 1 root root 4096 Feb 22 11:20 sync_speed_min4.3
mdadm命令
也可以通过mdadm命令查看指定阵列的简要信息(使用–query或者其缩写-Q)和详细信息(使用–detail或者其缩写-D) 详细信息包括RAID的版本、创建的时间、RAID级别、阵列容量、可用空间、设备数量、超级块状态、更新时间、UUID信息、各个设备的状态、RAID算法级别类型和布局方式以及块大小等信息。设备状态信息分为active, sync, spare, faulty, rebuilding, removing等[root@localhost ~]# mdadm -Q /dev/md0 /dev/md0: 4.00GiB raid5 3 devices, 1 spare. Use mdadm --detail for more detail. [root@localhost ~]# mdadm --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri Feb 22 11:01:13 2019 Raid Level : raid5 Array Size : 4190208 (4.00 GiB 4.29 GB) Used Dev Size : 2095104 (2046.34 MiB 2145.39 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Fri Feb 22 11:08:53 2019 State : clean Active Devices : 3 Working Devices : 4 Failed Devices : 0 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Name : localhost:0 (local to host localhost) UUID : 92736062:d9e0b2a0:bcc31a9c:028fa55c Events : 18 Number Major Minor RaidDevice State 0 8 49 0 active sync /dev/sdd1 1 8 50 1 active sync /dev/sdd2 4 8 51 2 active sync /dev/sdd3 3 8 53 - spare /dev/sdd5 -
模拟设备故障
[root@localhost ~]# mdadm /dev/md0 --fail /dev/sdd1 mdadm: set /dev/sdd1 faulty in /dev/md0此时,查看md自动将损坏磁盘上的数据重构到新的spare磁盘上:
[root@localhost ~]# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd3[4] sdd5[3] sdd2[1] sdd1[0](F) 4190208 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU] [===>.................] recovery = 18.9% (396940/2095104) finish=0.2min speed=99235K/sec unused devices:查看当前状态
[root@localhost ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri Feb 22 11:01:13 2019 Raid Level : raid5 Array Size : 4190208 (4.00 GiB 4.29 GB) Used Dev Size : 2095104 (2046.34 MiB 2145.39 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Fri Feb 22 11:33:56 2019 State : clean, degraded, recovering Active Devices : 2 Working Devices : 3 Failed Devices : 1 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Rebuild Status : 13% complete Name : localhost:0 (local to host localhost) UUID : 92736062:d9e0b2a0:bcc31a9c:028fa55c Events : 22 Number Major Minor RaidDevice State 3 8 53 0 spare rebuilding /dev/sdd5 1 8 50 1 active sync /dev/sdd2 4 8 51 2 active sync /dev/sdd3 0 8 49 - faulty /dev/sdd1完成后:
[root@localhost ~]# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd3[4] sdd5[3] sdd2[1] sdd1[0](F) 4190208 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU] unused devices:[root@localhost ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri Feb 22 11:01:13 2019 Raid Level : raid5 Array Size : 4190208 (4.00 GiB 4.29 GB) Used Dev Size : 2095104 (2046.34 MiB 2145.39 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Fri Feb 22 11:34:14 2019 State : clean Active Devices : 3 Working Devices : 3 Failed Devices : 1 Spare Devices : 0 Layout : left-symmetric Chunk Size : 512K Name : localhost:0 (local to host localhost) UUID : 92736062:d9e0b2a0:bcc31a9c:028fa55c Events : 37 Number Major Minor RaidDevice State 3 8 53 0 active sync /dev/sdd5 1 8 50 1 active sync /dev/sdd2 4 8 51 2 active sync /dev/sdd3 0 8 49 - faulty /dev/sdd1 其中的文件依然可用:
[root@localhost ~]# cat /mnt/fstab # # /etc/fstab # Created by anaconda on Wed Dec 19 20:12:26 2018 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/centos-root / xfs defaults 0 0 UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0 /dev/mapper/centos-home /home xfs defaults 0 0 /dev/mapper/centos-swap swap swap defaults 0 0 -
停用RAID
当阵列没有文件系统或者其他存储应用以及高级设备使用的话,可以使用–stop(或者其缩写-S)停止阵列;如果命令返回设备或者资源忙类型的错误,说明/dev/md0正在被上层应用使用,暂时不能停止,必须要首先停止上层的应用
[root@localhost ~]# mdadm -S /dev/md0 mdadm: fail to stop array /dev/md0: Device or resource busy [root@localhost ~]# umount /mnt [root@localhost ~]# mdadm -S /dev/md0 mdadm: stopped /dev/md0
四、LVM
1. 什么是LVM
想像一个情况,你在当初规划主机的时候将/home只给他 50G ,等到使用者众多之后导致这个 filesystem不够大, 此时你能怎么作?多数的朋友都是这样:再加一块新硬盘,然后重新分区、格式化,将/home的数据完整的复制过来, 然后将原本的 partition 卸载重新挂载新的 partition 。啊!好忙碌啊!若是第二次分区却给的容量太多!导致很多盘容量被浪费了! 你想要将这个 partition 缩小时,又该如何作?将上述的流程再搞一遍!唉~烦死了,尤其复制很花时间,有没有更简单的方法呢? 有的!那就是我们这个小节要介绍的 LVM 这玩意儿!
LVM(Logical Volume Manager)逻辑卷管理器。其 的重点在于可以弹性的调整 filesystem 的容量!而并非在于性能与数据安全上面。 需要文件的读写效能或者是数据的可靠性,请参考前面的 RAID 小节。 LVM 可以整合多个实体 partition 在一起, 让这些 partitions 看起来就像是一个磁盘一样!而且,还可以在未来新增或移除其他的实体 partition 到这个 LVM 管理的磁盘当中。 如此一来,整个磁盘空间的使用上,实在是相当的具有弹性啊! 既然 LVM 这么好用,那就让我们来瞧瞧这玩意吧!
dm
LVM利用Linux内核的dm(device-mapper)来实现存储系统的虚拟化(系统分区独立于底层硬件),与md类似,dm将一个或多个底层块设备组织成一个逻辑设备的模块,在内核中它通过一个一个模块化的 target driver 插件实现对 IO 请求的过滤或者重新定向等工作。

LVM基本组成
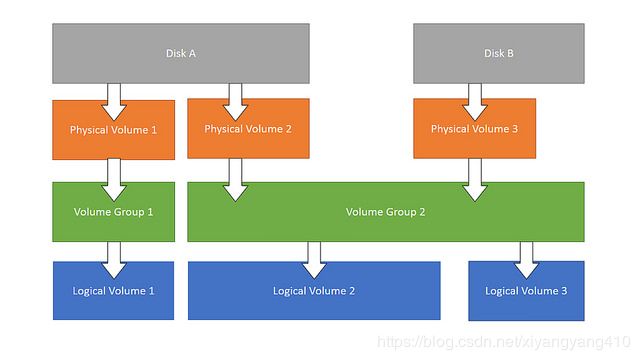
LVM的基本组成块(building blocks)如下:
-
Physical Volume (PV):物理卷,可以在上面建立卷组的媒介,可以是硬盘分区,也可以是硬盘本身或者回环文件(loopback file)。物理卷包括一个特殊的header,其余部分被切割为一块块PE
-
Volume Group (VG):卷组,将一组物理卷收集为一个管理单元。PV组合起来的大小即VG的大小,可以随着PV而改变
-
Logical Volume (LV):逻辑卷,虚拟分区,由PE组成。逻辑卷可以被格式化使用,一个卷组内可以创建多个逻辑卷
-
Physical Extent (PE):物理区域,硬盘可供指派给逻辑卷的最小单位(通常为4MB)。PE是逻辑存储单位,在创建卷组时指定,只有加入VG的物理卷才有PE
-
Logical Extend(LE):逻辑盘区,PE一旦被划分给某个逻辑卷后,称为LE,同PE,只是站在逻辑卷的角度,叫做LE(在物理卷的角度叫PE)
逻辑结构如下图10
2. 设备路径
在介绍相关命令之前,先来说明一下这类设备的设备文件,在创建逻辑设备后,会有相应的设备文件产生:
/dev/VG_NAME/LV_NAME,/dev/mapper/VG_NAME-LV_NAME,二者均指向/dev/dm-#
3. 相关命令
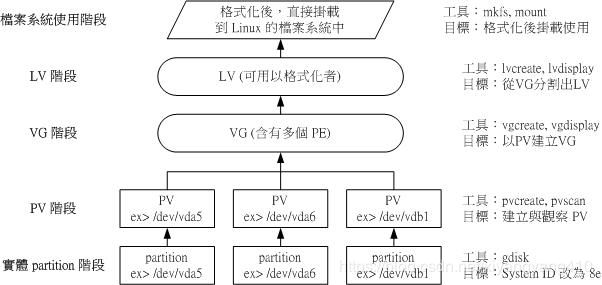
Linux大部分发行版如今使用LVM2进行逻辑卷管理,可通过下图对LVM相关使用流程有一个大致认识11
在不同的逻辑层,其管理命令各不相同,但都以固定字符开头,以下分别介绍
物理卷管理命令:pv*
pvcreate 创建
-f 强制创建
-v 显示详细信息
pvremove 移除
pvscan 扫描
pvs 简要显示
内容字段:
物理卷 所属卷组 卷格式 属性 卷大小 空闲空间
卷格式:lvm,lvm2
pvdisplay 显示详细信息
pvmove 移出物理卷上的数据
卷组管理命令:vg*
vgcreate 创建
[-s #[kKmMgGtTpPeE]] VolumeGroupName PhysicalDevicePath [PhysicalDevicePath...]
-s 指定物理盘区(PE)大小,默认是4M
vgremove 删除
vgextend 扩展
vgreduce 缩减
执行命令之前应使用pvmove将要去掉的盘上的数据移动到其他盘
vgs 显示
内容字段:
卷组 物理卷个数 逻辑卷个数 属性 卷组大小 空闲空间
vgdisplay 显示详细信息
vgscan 扫描
vgrename 重命名
逻辑卷管理命令:lv*
lvcreate 创建
lvcreate -n LV_NAME -L #[mMgGtT] VG_NAME
-n 指定逻辑卷名
-l 指定物理盘区盘区个数
-L 指定大小(直接指定空间大小)
-p 设定访问权限
lvremove 删除
lvextend 扩展
-L [+]#
lvreduce 缩减
lvs 显示
lvdisplay 显示详细信息
将上述命令汇总为下列表格供大家参考12
| 任务 | PV阶段 | VG阶段 | LV阶段 |
|---|---|---|---|
| 搜寻(scan) | pvscan | vgscan | lvscan |
| 创建(create) | pvcreate | vgcreate | lvcreate |
| 列出(display) | pvdisplay | vgdisplay | lvdisplay |
| 添加(extend) | vgextend | lvextend (lvresize) | |
| 减少(reduce) | vgreduce | lvreduce (lvresize) | |
| 删除(remove) | pvremove | vgremove | lvremove |
| 改变容量(resize) | lvresize | ||
| 改变属性(attribute) | pvchange | vgchange | lvchange |
再次说明, 格式化、挂载完成后,引用设备的路径为/dev/mapper/VGNAME-LVNAME,/dev/VGNAME/LVNAME,二者均会指向/dev/mapper/VGNAME-LVNAME
另外,也可以使用dmsetup命令(dmsetup - low level logical volume management)
4. 例
创建分区
首先创建4个分区,将其类型调整为Linux LVM,具体方式见上文,这里创建的结果为
[root@localhost ~]# fdisk -l /dev/sdc
Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x03af0ab0
Device Boot Start End Blocks Id System
/dev/sdc1 2048 4196351 2097152 8e Linux LVM
/dev/sdc2 4196352 8390655 2097152 8e Linux LVM
/dev/sdc3 8390656 12584959 2097152 8e Linux LVM
/dev/sdc4 12584960 41943039 14679040 5 Extended
/dev/sdc5 12587008 16781311 2097152 8e Linux LVM
PV阶段
[root@localhost ~]# pvcreate /dev/sdc{1,2,3,5}
Physical volume "/dev/sdc1" successfully created.
Physical volume "/dev/sdc2" successfully created.
Physical volume "/dev/sdc3" successfully created.
Physical volume "/dev/sdc5" successfully created.
[root@localhost ~]# pvscan
PV /dev/sda2 VG centos lvm2 [<119.51 GiB / 64.00 MiB free]
PV /dev/sdc2 lvm2 [2.00 GiB]
PV /dev/sdc3 lvm2 [2.00 GiB]
PV /dev/sdc1 lvm2 [2.00 GiB]
PV /dev/sdc5 lvm2 [2.00 GiB]
Total: 5 [<127.51 GiB] / in use: 1 [<119.51 GiB] / in no VG: 4 [8.00 GiB]
VG阶段
[root@localhost ~]# vgcreate -s 16M myvg /dev/sdc{1,2,3}
Volume group "myvg" successfully created
[root@localhost ~]# vgscan
Reading volume groups from cache.
Found volume group "centos" using metadata type lvm2
Found volume group "myvg" using metadata type lvm2
如此,就创建了一个名为“myvg”的vg,并将三个pv加入其中,要为vg增加容量,可使用vgextend VG_NAME DEVICE,后文将做介绍
LV阶段
[root@localhost ~]# lvcreate -L 3G -n mylv myvg
Logical volume "mylv" created.
[root@localhost ~]# ll /dev/myvg/mylv
lrwxrwxrwx. 1 root root 7 Feb 22 15:14 /dev/myvg/mylv -> ../dm-3
[root@localhost ~]# ll /dev/mapper/myvg-mylv
lrwxrwxrwx. 1 root root 7 Feb 22 15:14 /dev/mapper/myvg-mylv -> ../dm-3
FS阶段
此部分即格式化为特定文件系统,挂载并使用即可
[root@localhost ~]# mkfs.ext3 /dev/myvg/mylv
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
196608 inodes, 786432 blocks
39321 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=805306368
24 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mount /dev/myvg/mylv /mnt
[root@localhost ~]# cp /etc/fstab /mnt/
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 50G 4.7G 46G 10% /
devtmpfs 903M 0 903M 0% /dev
tmpfs 914M 0 914M 0% /dev/shm
tmpfs 914M 9.0M 905M 1% /run
tmpfs 914M 0 914M 0% /sys/fs/cgroup
/dev/sda1 497M 126M 372M 26% /boot
/dev/mapper/centos-home 68G 33M 68G 1% /home
tmpfs 183M 0 183M 0% /run/user/0
/dev/mapper/myvg-mylv 2.9G 4.6M 2.8G 1% /mnt
[root@localhost ~]# ls -a /mnt/
. .. fstab lost+found
扩大LV容量
由于文件系统边界依附于物理边界,扩展时应先扩展物理边界,再扩展文件系统边界,该操作大致步骤是
- 准备物理卷
- 扩展卷组
- 添加物理卷至卷组中
- 调整逻辑卷大小
- 调整文件系统大小
[root@localhost ~]# vgextend myvg /dev/sdc5
Volume group "myvg" successfully extended
[root@localhost ~]# vgdisplay
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 4
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 4
Act PV 4
VG Size <7.94 GiB
PE Size 16.00 MiB
Total PE 508
Alloc PE / Size 192 / 3.00 GiB
Free PE / Size 316 / <4.94 GiB
VG UUID xZH3IX-ITkJ-DON9-3SWl-pF1J-FCma-zXdAB7
[root@localhost ~]# lvextend -L +1.5G /dev/myvg/mylv
Size of logical volume myvg/mylv changed from 3.00 GiB (192 extents) to 4.50 GiB (288 extents).
Logical volume myvg/mylv successfully resized.
[root@localhost ~]# lvscan
ACTIVE '/dev/centos/swap' [2.00 GiB] inherit
ACTIVE '/dev/centos/home' [<67.45 GiB] inherit
ACTIVE '/dev/centos/root' [50.00 GiB] inherit
ACTIVE '/dev/myvg/mylv' [4.50 GiB] inherit
[root@localhost ~]# df -h /mnt/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/myvg-mylv 2.9G 4.6M 2.8G 1% /mnt
[root@localhost ~]# dumpe2fs -h /dev/myvg/mylv
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name:
Last mounted on: /mnt
Filesystem UUID: e118f701-4e99-45c2-a9cc-97953c4a1f02
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery sparse_super large_file
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 196608
Block count: 786432
Reserved block count: 39321
Free blocks: 756531
Free inodes: 196597
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 191
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Filesystem created: Fri Feb 22 15:18:02 2019
Last mount time: Fri Feb 22 15:18:16 2019
Last write time: Fri Feb 22 15:18:16 2019
Mount count: 1
Maximum mount count: -1
Last checked: Fri Feb 22 15:18:02 2019
Check interval: 0 ()
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: bd2c68a9-906e-436c-a450-fbc5edf78c66
Journal backup: inode blocks
Journal features: (none)
Journal size: 64M
Journal length: 16384
Journal sequence: 0x00000002
Journal start: 1
可以看到以上dumpe2fs的结果中
这个filesystem的 block 总数:
Block count: 786432
多少个 block 配置成为一个 block group:
Blocks per group: 32768
调整文件系统边界,可进行在线调整
[root@localhost ~]# resize2fs /dev/myvg/mylv
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/myvg/mylv is mounted on /mnt; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 1
The filesystem on /dev/myvg/mylv is now 1179648 blocks long.
[root@localhost ~]# df -h /mnt/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/myvg-mylv 4.4G 6.1M 4.2G 1% /mnt
若不指定大小,可以自动扩展至于物理边界一样的大小
若文件系统为xfs,使用xfs_growfs命令进行调整
缩小LV容量
相信很好理解:缩减时应先缩减文件系统边界,再缩减物理边界
缩减有风险,操作需谨慎,注意:
- 不能在线缩减,应先卸载
- 确保缩减后的空间大小依然能存储原有的所有数据
- 在缩减之前应先强行检查文件,以确保文件系统处于一致性状态
- 缩减逻辑卷大致步骤:
-
- 卸载卷,并执行强制检测
umount /PATH/TO/LV_DEVICE
e2fsck -f /PATH/TO/LV_DEVICE
- 卸载卷,并执行强制检测
-
- 缩减逻辑边界
resize2fs /PATH/TO/LV_DEVICE SIZE
- 缩减逻辑边界
-
- 缩减物理边界
lvreduce -L [-]SIZE /PATH/TO/LV_DEVICE
- 缩减物理边界
[root@localhost ~]# df -h /mnt/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/myvg-mylv 4.4G 6.1M 4.2G 1% /mnt
[root@localhost ~]# umount /mnt/
[root@localhost ~]# e2fsck -f /dev/myvg/mylv
e2fsck 1.42.9 (28-Dec-2013)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/myvg/mylv: 12/294912 files (0.0% non-contiguous), 36456/1179648 blocks
[root@localhost ~]# resize2fs /dev/myvg/mylv 2G
resize2fs 1.42.9 (28-Dec-2013)
Resizing the filesystem on /dev/myvg/mylv to 524288 (4k) blocks.
The filesystem on /dev/myvg/mylv is now 524288 blocks long.
[root@localhost ~]# mount /dev/myvg/mylv /mnt/
[root@localhost ~]# df -h /mnt/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/myvg-mylv 2.0G 4.6M 1.9G 1% /mnt
文件系统边界已经缩减,接下来缩减物理边界
[root@localhost ~]# lvresize -L 2.1G /dev/myvg/mylv
Rounding size to boundary between physical extents: <2.11 GiB.
WARNING: Reducing active logical volume to <2.11 GiB.
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce myvg/mylv? [y/n]: y
Size of logical volume myvg/mylv changed from 4.50 GiB (288 extents) to <2.11 GiB (135 extents).
Logical volume myvg/mylv successfully resized.
[root@localhost ~]# lvdisplay
--- Logical volume ---
LV Path /dev/myvg/mylv
LV Name mylv
VG Name myvg
LV UUID HrQwt2-zhA6-n11F-u1Xe-Tvpa-9XMN-SGtOs8
LV Write Access read/write
LV Creation host, time localhost, 2019-02-22 15:14:42 +0800
LV Status available
# open 0
LV Size <2.11 GiB
Current LE 135
Segments 2
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:3
[root@localhost ~]# pvscan
PV /dev/sda2 VG centos lvm2 [<119.51 GiB / 64.00 MiB free]
PV /dev/sdc1 VG myvg lvm2 [1.98 GiB / 0 free]
PV /dev/sdc2 VG myvg lvm2 [1.98 GiB / <1.86 GiB free]
PV /dev/sdc3 VG myvg lvm2 [1.98 GiB / 1.98 GiB free]
PV /dev/sdc5 VG myvg lvm2 [1.98 GiB / 1.98 GiB free]
Total: 5 [<127.45 GiB] / in use: 5 [<127.45 GiB] / in no VG: 0 [0 ]
此时,可以将/dev/sdc1移除,移除之前将其中内容移出
[root@localhost ~]# pvmove /dev/sdc1
/dev/sdc1: Moved: 0.79%
/dev/sdc1: Moved: 100.00%
[root@localhost ~]# vgreduce myvg /dev/sdc1
Removed "/dev/sdc1" from volume group "myvg"
[root@localhost ~]# pvscan
PV /dev/sda2 VG centos lvm2 [<119.51 GiB / 64.00 MiB free]
PV /dev/sdc2 VG myvg lvm2 [1.98 GiB / <1.86 GiB free]
PV /dev/sdc3 VG myvg lvm2 [1.98 GiB / 0 free]
PV /dev/sdc5 VG myvg lvm2 [1.98 GiB / 1.98 GiB free]
PV /dev/sdc1 lvm2 [2.00 GiB]
Total: 5 [127.46 GiB] / in use: 4 [125.46 GiB] / in no VG: 1 [2.00 GiB]
[root@localhost ~]# pvremove /dev/sdc1
Labels on physical volume "/dev/sdc1" successfully wiped.
此后,/dev/sdc1就可用作别处
将该逻辑卷挂载后,原有数据依然可用
[root@localhost ~]# mount /dev/myvg/mylv /mnt/
[root@localhost ~]# cat /mnt/fstab
#
# /etc/fstab
# Created by anaconda on Wed Dec 19 20:12:26 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
5. 快照卷
快照
快照(Snapshot),快照就是将当时的系统资讯记录下来,就好像照相记录一般! 未来若有任何数据更动了,则原始数据会被搬移到快照区,没有被更动的区域则由快照区与文件系统共享,常用作数据备份与恢复
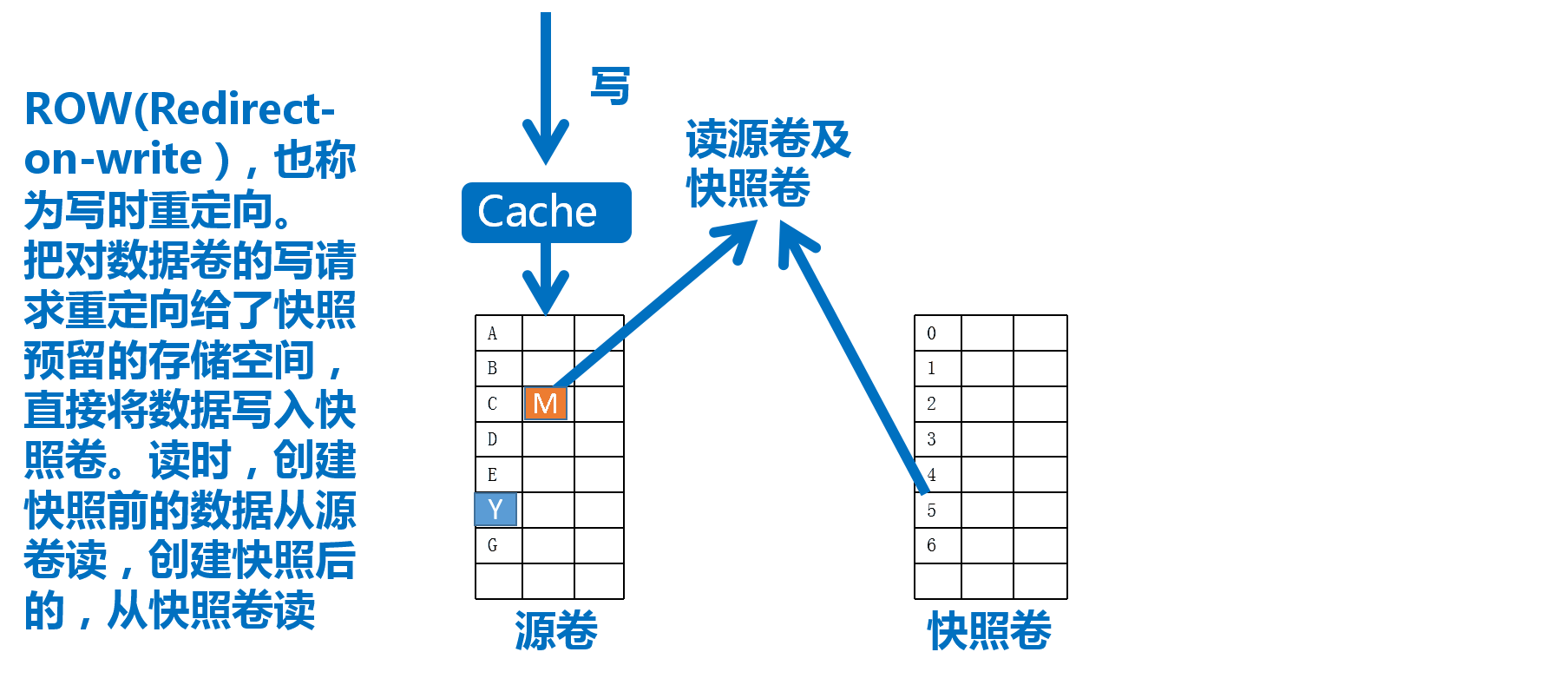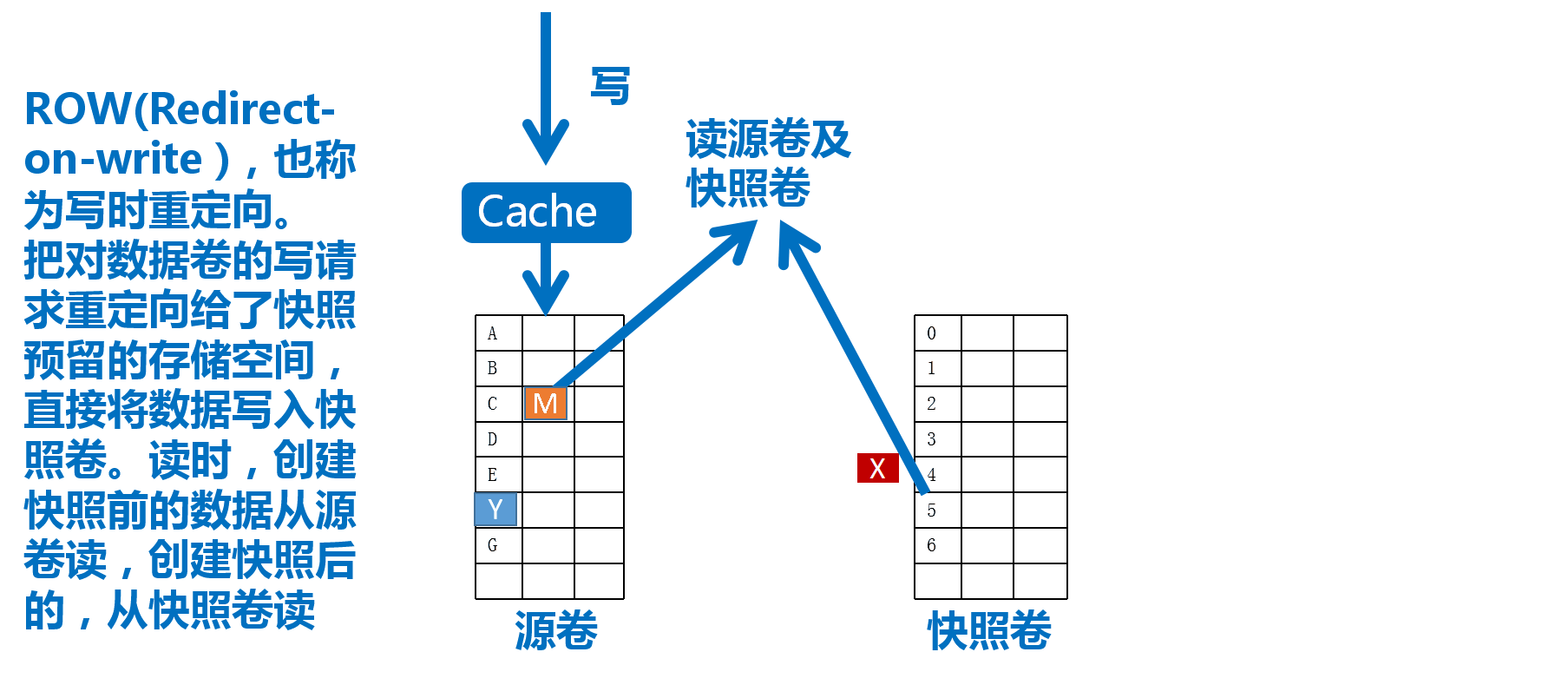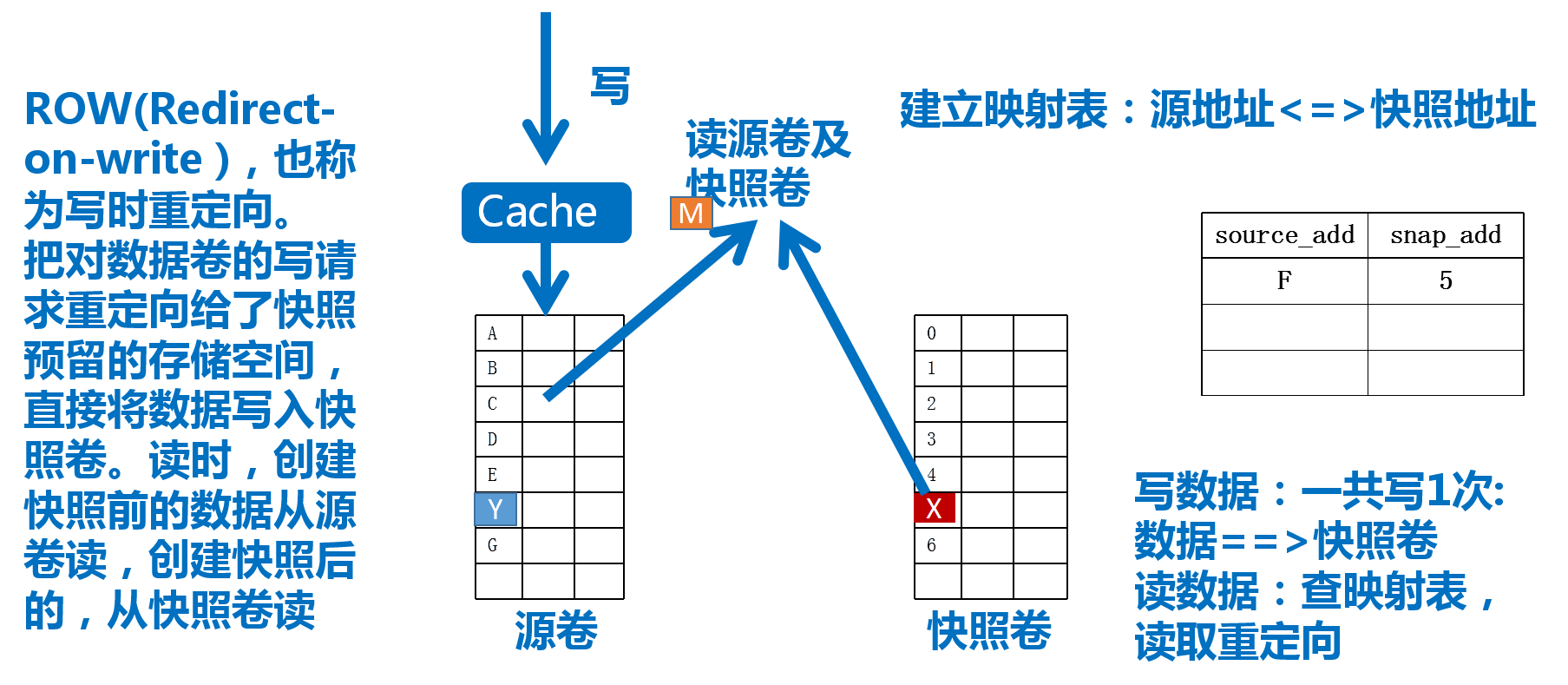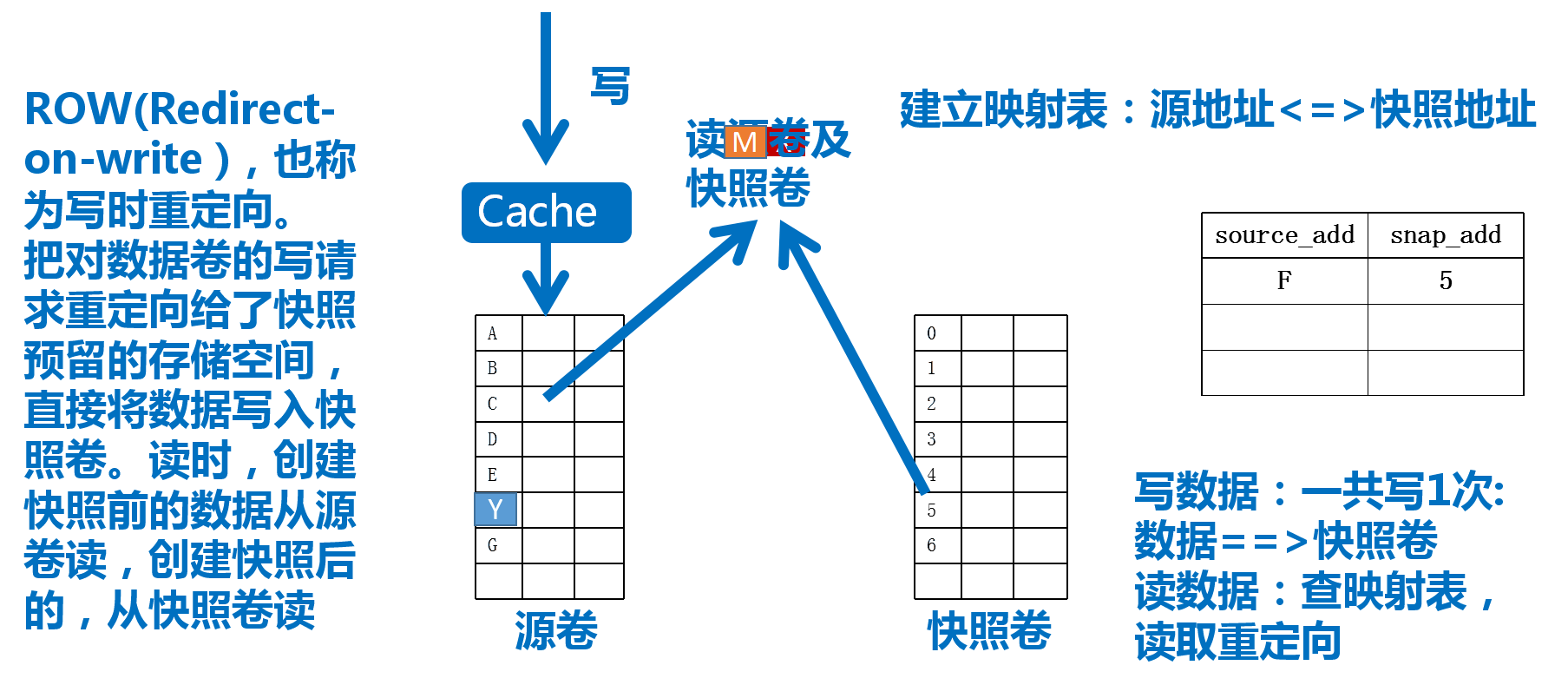
LVM的快照使用RoW(Redirect-on-Write,写时重定向)实现,大致过程如下图13
快照卷
而LVM的快照技术是通过快照卷(Snapshot Volume)实现的,如上图,我们对源逻辑卷创建快照卷后,即可通过该快照卷访问数据,当数据发成变化时,变化的数据将被写入快照卷,如此,源卷的数据将保持创建快照那一刻的状态
需要注意
- 生命周期为整个数据时长,在这段时长内,数据的增长量不能超出快照卷大小
- 快照卷应该是只读的
- 跟原卷在同一卷组内,所以创建时不必指定为哪个卷组创建,但应指定为哪个逻辑卷创建
- 快照卷可以作为原卷的访问入口,访问的是修改之前的数据,修改之后的可通过源路径访问
创建快照卷
创建快照卷依然使用lvcreate,使用如下格式
lvcreate -s -L SIZE -n SLV_NAME -p r /PATH/TO/ORIGINAL_LV_DEVICE
-s 创建快照卷
-p r|w 指定权限,应指定为只读(r)
-L 指定大小
-n 指定快照卷名称
测试
首先新建一个PV并加入VG
[root@localhost ~]# pvcreate /dev/sdc1
Physical volume "/dev/sdc1" successfully created.
[root@localhost ~]# vgextend myvg /dev/sdc1
Volume group "myvg" successfully extended
创建快照卷
[root@localhost ~]# lvcreate -L 1G -s -n myvg_sh /dev/myvg/mylv
Logical volume "myvg_sh" created.
[root@localhost ~]# lvdisplay
--- Logical volume ---
LV Path /dev/myvg/mylv
LV Name mylv
VG Name myvg
LV UUID HrQwt2-zhA6-n11F-u1Xe-Tvpa-9XMN-SGtOs8
LV Write Access read/write
LV Creation host, time localhost, 2019-02-22 15:14:42 +0800
LV snapshot status source of
myvg_sh [active]
LV Status available
# open 1
LV Size <2.11 GiB
Current LE 135
Segments 2
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:3
--- Logical volume ---
LV Path /dev/myvg/myvg_sh
LV Name myvg_sh
VG Name myvg
LV UUID 09MnZC-4xIY-jWyT-r3c9-2K5G-eUGW-K4ghj4
LV Write Access read/write
LV Creation host, time localhost, 2019-02-22 17:03:10 +0800
LV snapshot status active destination for mylv
LV Status available
# open 0
LV Size <2.11 GiB
Current LE 135
COW-table size 1.00 GiB
COW-table LE 64
Allocated to snapshot 0.01%
Snapshot chunk size 4.00 KiB
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 8192
Block device 253:6
通过快照卷访问数据
[root@localhost ~]# mount /dev/myvg/myvg_sh /tmp
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 50G 4.7G 46G 10% /
devtmpfs 903M 0 903M 0% /dev
tmpfs 914M 0 914M 0% /dev/shm
tmpfs 914M 9.1M 905M 1% /run
tmpfs 914M 0 914M 0% /sys/fs/cgroup
/dev/sda1 497M 126M 372M 26% /boot
/dev/mapper/centos-home 68G 33M 68G 1% /home
tmpfs 183M 0 183M 0% /run/user/0
/dev/mapper/myvg-mylv 2.0G 4.6M 1.9G 1% /mnt
/dev/mapper/myvg-myvg_sh 2.0G 4.6M 1.9G 1% /tmp
[root@localhost ~]# cat /tmp/fstab
#
# /etc/fstab
# Created by anaconda on Wed Dec 19 20:12:26 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
修改数据
[root@localhost ~]# echo "New Line." >> /tmp/fstab
[root@localhost ~]# cat /tmp/fstab
#
# /etc/fstab
# Created by anaconda on Wed Dec 19 20:12:26 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
New Line.
此时再通过原卷访问,则数据还是修改之前的
[root@localhost ~]# cat /mnt/fstab
#
# /etc/fstab
# Created by anaconda on Wed Dec 19 20:12:26 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a8cac4fb-841a-421d-ba11-ea7eee1c57bc /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
五、例
1、创建一个10G的分区,并格式化为ext4文件系。要求:
(1)block大小为2048,预留空间20%,卷标为MYDATA,
(2) 挂载至/mydata目录,要求挂载时禁止程序自动运行,且不更新文件的访问时间戳。
(3)可开机自动挂载。
创建分区
[root@localhost ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x87950fb6.
Command (m for help): p
Disk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x87950fb6
Device Boot Start End Blocks Id System
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-209715199, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-209715199, default 209715199): +10G
Partition 1 of type Linux and of size 10 GiB is set
Command (m for help): p
Disk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x87950fb6
Device Boot Start End Blocks Id System
/dev/sdb1 2048 20973567 10485760 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
[root@localhost ~]# cat /proc/partitions
major minor #blocks name
8 0 125829120 sda
8 1 512000 sda1
8 2 125316096 sda2
8 16 104857600 sdb
8 17 10485760 sdb1
格式化
[root@localhost ~]# mkfs.ext4 -b 2048 -m 20 -L MYDATA /dev/sdb1
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=MYDATA
OS type: Linux
Block size=2048 (log=1)
Fragment size=2048 (log=1)
Stride=0 blocks, Stripe width=0 blocks
655360 inodes, 5242880 blocks
1048576 blocks (20.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=273678336
320 block groups
16384 blocks per group, 16384 fragments per group
2048 inodes per group
Superblock backups stored on blocks:
16384, 49152, 81920, 114688, 147456, 409600, 442368, 802816, 1327104,
2048000, 3981312
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# blkid /dev/sdb1
/dev/sdb1: LABEL="MYDATA" UUID="9edaaa78-7cad-4cb5-8e46-3556cad9e964" TYPE="ext4"
挂载
[root@localhost ~]# mkdir /mydata
[root@localhost ~]# mount -o noatime,noexec /dev/sdb1 /mydata/
开机自动挂载,编辑/etc/fstab文件,在添加一行内容:
/dev/sdb1 /mydata ext4 noatime,noexec 0 0
2、创建一个大小为1G的swap分区,并启用。
创建分区,并调整为swap类型
[root@localhost ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): p
Partition number (2-4, default 2):
First sector (20973568-209715199, default 20973568):
Using default value 20973568
Last sector, +sectors or +size{K,M,G} (20973568-209715199, default 209715199): +1G
Partition 2 of type Linux and of size 1 GiB is set
Command (m for help): t
Partition number (1,2, default 2): 2
Hex code (type L to list all codes): 82
Changed type of partition 'Linux' to 'Linux swap / Solaris'
Command (m for help): p
Disk /dev/sdb: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x87950fb6
Device Boot Start End Blocks Id System
/dev/sdb1 2048 20973567 10485760 83 Linux
/dev/sdb2 20973568 23070719 1048576 82 Linux swap / Solaris
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
执行partx -a
[root@localhost ~]# partx -a /dev/sdb
partx: /dev/sdb: error adding partition 1
[root@localhost ~]# partx -a /dev/sdb
partx: /dev/sdb: error adding partitions 1-2
创建swap并启用
[root@localhost ~]# mkswap /dev/sdb2
Setting up swapspace version 1, size = 1048572 KiB
no label, UUID=0e7bcbe9-d3d1-4cd2-8127-3f8692bf7760
[root@localhost ~]# swapon /dev/sdb2
[root@localhost ~]# free
total used free shared buff/cache available
Mem: 1870512 191128 1450184 9324 229200 1491852
Swap: 3145720 0 3145720
[root@localhost ~]# swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 2097148 0 -1
/dev/sdb2 partition 1048572 0 -2
3、编写脚本计算/etc/passwd文件中第10个用户和第20个用户id号之和。
关于脚本相关介绍参考Bash编程 https://blog.csdn.net/xiyangyang410/article/details/86695841
#!/bin/bash
uid1=`head -10 /etc/passwd | tail -1 | cut -d: -f3`
uid2=`head -20 /etc/passwd | tail -1 | cut -d: -f3`
echo $[ $uid1+$uid2]
4、编写脚本,通过命令行参数传入一个用户名,判断id号是偶数还是奇数。
#!/bin/bash
if id $1 &> /dev/null; then
user_id=`id -u $1`
if [ $[$user_id%2] -eq 0 ]; then
echo "Even."
else
echo "Odd."
fi
else
echo "No such user."
fi
表格引用自 https://zh.wikipedia.org/wiki/%E4%B8%BB%E5%BC%95%E5%AF%BC%E8%AE%B0%E5%BD%95 ↩︎
内容引用自 http://linux.vbird.org/linux_basic/0130designlinux.php#partition_table ,由于习惯不同,修改了部分名词 ↩︎ ↩︎
可参看鸟哥的Linux私房菜: http://linux.vbird.org/linux_basic/0130designlinux.php#partition_bios_uefi ↩︎
图片引用自 https://en.wikipedia.org/wiki/Virtual_file_system ↩︎
引用自 http://os.51cto.com/art/201205/334497_all.htm ↩︎
详见 https://blog.csdn.net/xiyangyang410/article/details/86651541#ls_60 ↩︎
关于swap,详见进程管理内容:https://blog.csdn.net/xiyangyang410/article/details/87976734#_1742 ↩︎
该论文电子版笔者已上传至SCDN:https://download.csdn.net/download/xiyangyang410/10968807 ↩︎
表格引用自 http://linux.vbird.org/linux_basic/0420quota.php#spare ↩︎
图片引用自 https://linux.cn/article-3218-1.html ↩︎
图片引用自 http://linux.vbird.org/linux_basic/0420quota.php#lvm_whatis ↩︎
表格引用自 http://cn.linux.vbird.org/linux_basic/0420quota_3.php#lvm_hint ↩︎
图片来源 https://cloud.tencent.com/developer/article/1158686 ↩︎