python的文件操作——带图详解
文章目录
- 文件操作之读文件
- 说明
- 读取文件 实操
- 当前包中读取
- 文件操作之写文件
- 二进制拷贝图片
- 文件操作之os模块
- 说明
- os模块
- os.path模块
- os.walk方法
- shutil和zipfile模块
- 递归实现遍历所有文件和目录
- os调用操作系统命令
- os执行可执行文件
文件操作之读文件
说明
open() 方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode):open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 可以用来读取或拷贝图片呢,下面有demo实验 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
- file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close() 关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next()返回文件下一行。 |
| 6 | file.read([size])从文件读取指定的字节数,如果未给定或为负则读取所有。seze=数字,数字代表字符串数量。 |
| 7 | file.readline([size])读取整行,包括 “\n” 字符(自带)。f.readline().strip()去掉\n符 ,size是一行中的多少字符 |
| 8 | file.readlines([sizeint])读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。如果要去掉自带\n,要用 for循环遍历:for i in file.readlines() : print(i.strip()) |
| 9 | file.seek(offset[, whence])设置文件当前位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | file.truncate([size])截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
读取文件 实操
当前包中读取
先在当前包中建一个txt 文件把,然后自定义一些内容:
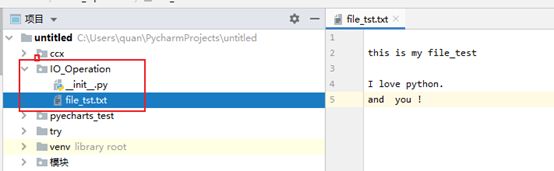
然后新建一个py文件:
# -- 读取文件
f = open('file_tst.txt') # 打开一个文件,返回一个对象f
print(f.read()) # 一次性读取所有内容
f.close() # 文件操作后一定要关闭

骚气一点,可以放在try中:
# -- 读取文件
try:
f = open('file_tst.txt') # 打开一个文件,返回一个对象f
except FileExistsError as e:
print('文件找不到: ',e)
else:
print(f.read()) # 一次性读取所有内容
finally:
if f:
f.close() # 文件操作后一定要关闭
上面代码可以使用with…as简写。 真实环境中,很多都是用的下面这种写法,你现在可以不会写,但你得看得懂!!!!!
#简写,使用with...as 语句,会自动调用close()
with open('file_tst.txt') as e:
print(f.read())
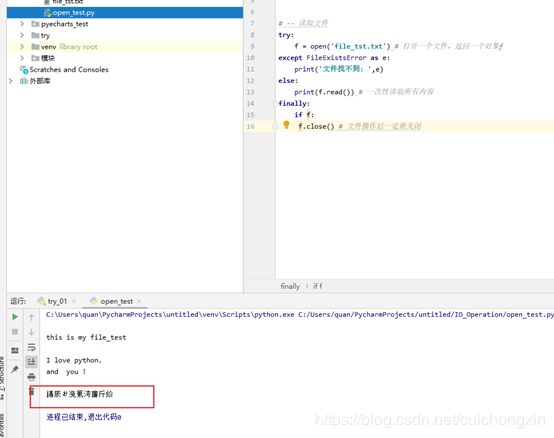
读取文件加上参数说明:
如果文件中有中文,如果我们不指定字符集,可能会乱码:
所以我们要指定字符集(如果不清楚,看上面的说明,里面有每个参数的详细解释),如果报错就加个单引号:open(file, encoding='utf8')
和几个常用参数对象说明!!!!
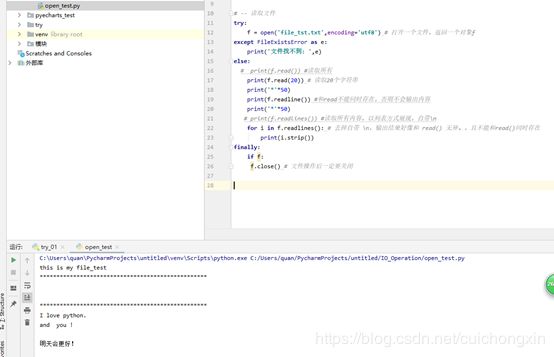
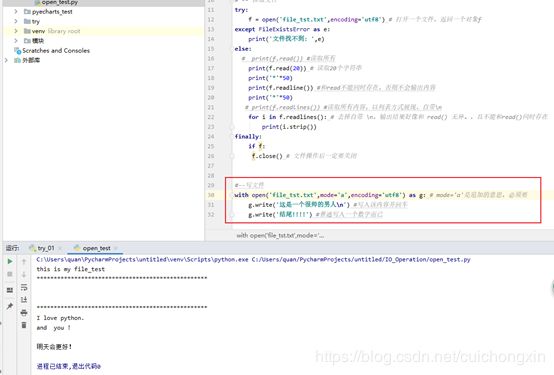
# -- 读取文件
try:
f = open('file_tst.txt',encoding='utf8') # 打开一个文件,返回一个对象f
except FileExistsError as e:
print('文件找不到: ',e)
else:
# print(f.read()) #读取所有
print(f.read(20)) # 读取20个字符串
print('*'*50)
print(f.readline()) #和read不能同时存在,否则不会输出内容
print('*'*50)
# print(f.readlines()) #读取所有内容,以列表方式展现,自带\n
for i in f.readlines(): # 去掉自带 \n,输出结果好像和 read() 无异。,且不能和read()同时存在
print(i.strip())
finally:
if f:
f.close() # 文件操作后一定要关闭
文件操作之写文件
单独拿出来说 是怕你没注意看!!!!
命令也是open,使用文件看读文件中的说明!!!
写文件也就是open的一个对象而已:
file.writelines(sequence)
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
来一个demo看效果:
# -- 读取文件
try:
f = open('file_tst.txt',encoding='utf8') # 打开一个文件,返回一个对象f
except FileExistsError as e:
print('文件找不到: ',e)
else:
# print(f.read()) #读取所有
print(f.read(20)) # 读取20个字符串
print('*'*50)
print(f.readline()) #和read不能同时存在,否则不会输出内容
print('*'*50)
# print(f.readlines()) #读取所有内容,以列表方式展现,自带\n
for i in f.readlines(): # 去掉自带 \n,输出结果好像和 read() 无异。,且不能和read()同时存在
print(i.strip())
finally:
if f:
f.close() # 文件操作后一定要关闭
#--写文件
with open('file_tst.txt',mode='a',encoding='utf8') as g: # mode='a'是追加的意思,必须要
g.write('这是一个很帅的男人\n') #写入该内容并回车
g.wr
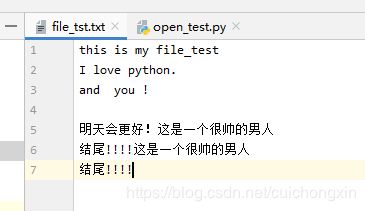
去文件看内容:
注,因为我执行了2次,所以追加了2次内容!!!
二进制拷贝图片
# --读写二进制文件
# 以复制一张图片为例
# 前提条件你的先 放一张图片在当前包中
with open('zhuomian.png',mode='rb') as write: #读取图片文件
with open('new_zhuomian.png',mode='wb') as out: #之前说了,这是放执行代码块,这里执行拷贝代码
out.write(write.read())
print('拷贝成功')
文件操作之os模块
说明
os模块可以帮助我们直接对操作系统进行操作,我们可以直接调用操作系统的命令和可执行文件,还能操作文件和目录等等,是系统运维的核心基础。
os模块
import os
# 返回当前操作系统的类型
print(os.name) # windows->nt linux和unix->posix java虚拟机->java
# 当前系统路径分隔符
print(os.sep) # windows->\ linux和unix->/
# getcwd() 获取当前工作目录
print(os.getcwd()) # D:\Project\pythonTest
# listdir() 获取指定目录下所有文件和文件夹相对路径,保存到列表中
ls = os.listdir('./') # ./表示当前文件所在目录
print(ls) # ['.idea', '.vscode', 'test.py', 'test_file']
# mkdir() 用于创建文件夹
os.mkdir('test_file2') # 如果不指定绝对路径,则默认在当前文件夹下创建
# mkdir创建的文件夹名不能与已存在的重命名,否则报错
os.mkdir('test_file2') # FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: 'test_file2'
# rename() 对文件或者文件夹重命名
os.rename('电影', 'movies')
# remove() 删除文件
os.remove('a.txt') # 如果文件不存在,则报错FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'a.txt'
#一般建议 加个 if判断条件,否则会报错
if os.path.exists('new_zhuomian.png'): #os.path模快自帶判斷條件
os.remove('new_zhuomian.png') # 如果不加这个,如果不存在就会报错
else:# 这个条件不要也可
print('文件不存在')
# rmdir() 用于删除文件夹
os.rmdir('test_file2') # 只能删除空的文件夹, 否则报错:OSError: [WinError 145] 目录不是空的。: 'test_file2'
#一般建议 加个 if判断条件,否则会报错
if os.path.exists('new_zhuomian'): #os.path模快自帶判斷條件
os.remove('new_zhuomian') # 如果不加这个,如果不存在就会报错
else:# 这个条件不要也可
print('文件夹不存在')
os.rmdir('test_fil') # FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'test_fil'
# 创建多级目录
# os.makedirs('电影/小电影/金瓶梅') # 在当前目录下创建多级目录
# 删除多级目录
os.removedirs('电影/小电影/金瓶梅') # 同样的只能删除为空的目录
# chdir() 切换目录
os.chdir('c:')
print(os.getcwd()) # C:\
# ../表示返回当前文件的上一级
os.makedirs(r'../技术/python/入门') # 当前py文件路径为: D:\Project\pythonTest\test.py, ../表示当前文件的上一级目录,即Project下创建多级目录
os.path模块
os.path模块提供了目录相关(路径判断、路径切分、路径链接、文件夹遍历)的操作。
import os
print(os.path) # 输出的是python环境的路径 ==》 os.walk方法
os.walk()用来递归遍历所有文件和目录,返回一个包含3个元素的元组
(dirpath, dirnames, filenames),生成器:
dirpath:要列出指定目录的路径
dirnames:目录下的所有文件夹
filenames:目录下的所有文件
import os
path = os.getcwd()
print(path) # D:\Project\pythonTest
list_file = os.walk(path)
print(list_file) # shutil和zipfile模块
shutil模块是python标准库中提供的,主要用来做文件和文件夹的拷贝,移动、删除等;还可以做文件和文件夹的压缩,解压缩操作。os莫提供了对文件或目录的一般操作,shutil模块作为补充,提供了移动、复制、压缩、解压等操作,这些os模块都没有提供。
import shutil
shutil.copyfile('test.py', 'test_copy.py') # 复制文件
shutil.copytree('movies', 'movies_copy') # 复制目录
shutil.move( 'src(路径)', 'dst(当前路径则重命名,其他路径则移动)') #移动文件、目录。或者文件、目录重命名。如果dst存在,则不可覆盖
shutil.remove('file') #删除文件
# 压缩
shutil.make_archive('movies_copy', 'zip', 'movies') # 目标文件, zip 源文件
还有个模块zipfile可以解压缩:
import zipfile
# 压缩
z1 = zipfile.ZipFile('test.zip', 'w')
z1.write('test.py')
z1.write('test_copy.py') # 将test.py和test_copy.py文件压缩到test.zip中
z1.close()
# 解压
z2 = zipfile.ZipFile('test.zip', 'r')
z2.extractall('test') # 解压到test目录下
z2.close()
递归实现遍历所有文件和目录
上面我们使用了os.walk方法实现了遍历指定目录下所有文件和目录,现在我们通过递归自己实现这种遍历。
import os
src_path = os.getcwd() # 获取当前目录绝对路径
all_files = []
def get_all_files(src_path):
src_child = os.listdir(src_path) # 获取指定目录下的文件和目录
for child in src_child:
src_child = os.path.join(src_path, child)
if os.path.isdir(src_child): # 判断是否是目录
get_all_files(src_child) # 如果是目录,则回调
all_files.append(src_child)
get_all_files(src_path)
for f in all_files:
print(f)
上面使用方法都挺简单的,之间按需要执行就可以了,下面会说到调用windows的操作,我会放图片。
os调用操作系统命令
比如在windows系统下,我们在运行里面输入notepad.exe可打开记事本工具;
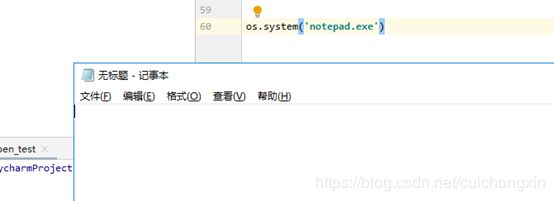
同样,我们可以使用os模块调用操作系统命令打开:
import os
os.system('notepad.exe') # 打开记事本
同样我们还可以调用其他命令:
os.system('regedit') # 打开注册表
os.system('ping www.hao123.com') # ping命令
os.system('cmd') # 打开dos窗口
os执行可执行文件
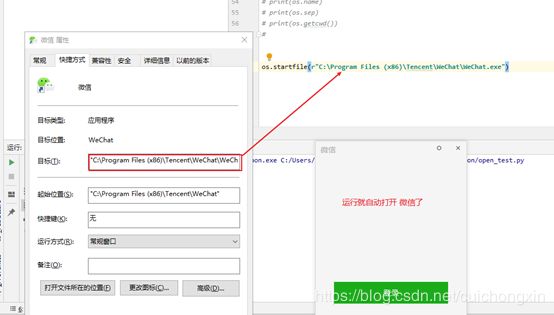
比如我们平常登录微信,需要用鼠标双击打开登录界面,使用os模块也打开:
import os
#查看软件路径方法,右键-属性-目标
#os.startfile(r"路径") # 打开指定文件
# 如打开微信
os.startfile(r"C:\Program Files (x86)\Tencent\WeChat\WeChat.exe")