前端笔记
积累
1.判断数据的类型
JS中数据的类型有基本数据类型和复杂数据类型。
基本数据类型:number、String、Boolean、null、undefined、(ES6中的Symbol)
复杂数据类型L: Object(Object,Function,Array)
1.typeof (适合用于校对基本数据类型)
对于基本数据类型的null来说其返回值为Object,但是相对于复杂类型的Function来说返回的是 Function(可以作为判断依据)。
2.instanceof (适合用作复杂数据类型)
该方法是通过原型链来判断其类型,但是要注意只要是在该原型链上就会返回true
例如 [] instanceof Array和[] instanceof Object 返回值都是true
该操作符适合用来补充typeof带来的缺陷,可以用来判断除了Function以外的复杂类型以及可以判断null;
3.Object.protptype.toString.call()(最适合用来判断数据的类型)
所有数据类型都可以通过该方法来判断,该方法会返回[Object 实际数据类型],由此来判断数据类型(实际上第二个参数就是对象的内部属性[[class]],无法直接访问,只能通过该方法查看)
2.转换类数组的方法
有的时候需要把类数组(一组通过数字索引的值)转换成数组来对其进行操作,例如函数参数转为数组。
1.Array.prototype.slice.call()
2.Array.From()(ES6中的方法)
3.[…arr]
3.数字进制的转换
在进行项目开发时需要用到,数字在直接作为值时并不可以访问Number对象的方法(不能直接 10.toString(16)),数字需要被赋予到一个变量上(let a = 1 ;a.toString(16))或者用小括号包裹数字,如果直接写数字该数字会被是被成数字字面量的一部分,然后才是对象属性运算符
1.toString(num)把数字转成指定进制
要注意如果数字要使用该方法首先必须为数字对象的实例,使用(num).toString(16)转成16进制
2.parseInt(num,num)把指定进制转成数字
相当于上面方法的你逆推,使用toString()可以把10转成a,使用parseInt("a",10)可以把a转成10
4.判断数字
由于NaN实际上是一个不是数字的数字,实际上也是属于Number的,所以在判断的时候很容易把NaN当成是数字。
1.Number.isNaN()(ES6中)
2.自己创建方法(在非ES6中可以使用)
typeof val === ‘number’&& window.isNaN(val)
5.对象的封装和拆封
这里的封装和拆封主要说的是对于基本数据类型的
1.封装
实际上就是通过制定基本类型的构造函数创建出来的对象,该对象在使用typeof会被认为是Object。
2.拆封
使用valueof()方法把封装的对象转成值类型!
6.数组拼接和字符串拆分
1.arr.slice(str,end)
主要用于数组的截取,函数会返回截取部分的数组,不是一个数组变异方法。
2.arr.splice(idx,num,item,item)
主要用于数组的替换,会改变数组,是一个变异数组。
3.str.split(',')
主要用于字符串的分割。
4.arr.join('')
把数组用指定间隔转换成字符串可以是空格。
5.arr.toString()
直接把数字变成字符串保留数组中的逗号。let a= [1,2,3] a.toStrng() // "1,2,3"
7.逻辑运算符
在执行的过程中,其判断过程是自左向右的,先判断第一个值是否是布尔类型,如果不是就强转成布尔类型,在进行接下来的判断。&&运算符__优先级比||运算符__高。
1.&&与
代表与,只有其关联的所有值为true才会返回true,会进行隐式转换(转换成true和false),可以作为js的一种简写 let a = true; a && foo()如果前面值判定成功那么就会执行后面的函数,如果失败就不执行,类似于三元操作符(flag?isRight:noRight)。
其次在&&运算符运算的时候会返回值,且该值不是 true或者false而是返回进行操作的值,他会返回第一个为false的值,如果全是true就会返回最后一个为true的值(平常都是用if来判断,有隐式转换)
2.||或
代表或,在进行操作的值中,只要有一个值符合true那么就会返回true,该运算符会返回第一个为true的值。通常被用作默认值 a= b||"normal"如果b的值为false那么就会返回第一个值。
同样的在||运算符运算的时候会返回值,他会返回第一个为true的值,如果全是false就会返回最后一个为false的值(平常都是用if来判断,有隐式转换)
8.布尔值显式和隐式转换
1.隐式转换
①if(…)
②for(…;…;…)
③while(…);do…while(…)
④三元判断表达式
⑤逻辑运算符&& 和 ||
2.显式转换
①!!a
!!null,!!undefine,!!'',!![],!!{}//false,false,false,true,true
②toBoolean()
9.== 和 ===
1.区别和联系
相对于===来说,宽松相等允许在相等比较中进行强制类型转换,其性能相差不大(几百万分之一秒),在宽松相等中要注意 NaN不等于NaN(可以使用ES6中的Number.isNaN()),同时其强制转换的规则是,所有其他类型都转成数字来对比(包括布尔类型和字符串) true == “42”//false ,实际上true会被转成1 然后1和42对比。
同时注意 > 和 < 是先判断String如果都不是字符串才转成数字。字符串的判断是以字母顺序来判断的,例如“42”<"043"//false这是由于4>0.同时根据规范 a <= b 会处理为!(a>b)
10.视图更新的几种方法(需更新)
1.this.$set(obj,key,val)
2.Vue.set(obj,key,val)
Vue.set()向响应式对象中添加一个属性,并确保这个新属性同样是响应式的,且触发视图更新。它必须用于向响应式对象上添加新属性,因为 Vue 无法探测普通的新增属性。
vue源码对set的实现总的来说分为两种情况,对数组和对对象。
对数组:实际上设置了set只有的数组对象其变异方法不是直接连接到Array.prototype上的,它使用了Vue给其提供的变异方法,这个提供变异方法其__ proto __就是Array.prototype,实际上set底层只是调用了splice方法实现。
对对象:vue是对使用的Object.defineProperty给对象做了一层拦截,当触发get的时候就会进行依赖收集(这里收集的依赖还是像数组那样,理解成渲染函数),当触发set的时候就会触发依赖,导致渲染函数执行页面重新渲染。那么第一次是在哪里触发get的呢?其实是在首次加载页面渲染的时候触发的,这里会进行递归将对象的属性都依赖收集,所以我们修改对象已有属性值得时候会导致页面重新渲染。自己添加属性却不会进行重新渲染
3.使用数组变异方法
push(),pop(),shift(),unshift(),splice(),
4.放入vuex中,自动添加setter
compute钩子没有setter只有getter
11.运算符优先级
&&运算符__优先级比||运算符__高,而__||运算符__比__三元运算符__高
1.执行顺序
三元操作符和字符串赋值都是右关联的,例如var a = b = c =42//实际上其执行顺序为
var (a = (b = (c =42)))
12.let和const(暂时性死区!!)
1.const
可以定义一个常量(无法修改的变量),但是如果是对象或者是数组却可以修改某个键的值,能使用const就使用const,这样容易维护.
2.let
和const类似,但是其保存的是一个变量
3.共同特征
暂时性死区:当程序的控制流程在新的作用域(module function 或 block 作用域)进行实例化时,在此作用域中用let/const声明的变量会先在作用域中被创建出来,但因此时还未进行词法绑定,所以是不能被访问的,如果访问就会抛出错误。因此,在这运行流程进入作用域创建变量,到变量可以被访问之间的这一段时间,就称之为暂时死区。
变量提升:实际上变量提升是js自带的变量的特性,实际上let和const会被提升到TDZ中,所以无法被访问到。
块级作用域:(module function 或 block 作用域)中可使用,出了作用域就被销毁。相对于var多了一个block的作用域即for循环中大括号内的作用域
无法重复声明:在作用域中只能有一个变量的声明(包括var前let后)
13.传递参数
按值传递:传内存拷贝。
拷贝一份值到参数作用域中,函数内直接使用这份值
按引用传递:传内存指针。
直接把对象的应用传入到参数中,函数内直接使用这个引用
按共享传递:传引用的拷贝。
如果是传引用的话会先赋值一份应用到参数,这份引用和之前的引用是相互独立,但是都指向同一个地址(实际上也是按值传递,不过拷贝的只是对象的引用罢了)
14.执行环境
1.执行环境
概念:义了变量或函数有权访问其他数据,决定了他们各自的行为。每一个执行环境都有一个相对应的变量对象,里面有所有在该环境下定义的所有函数和数据,我们不能直接使用它,但是解析器会在后台使用这个对象。执行环境会在环境中所有代码执行完毕后进行销毁。
每当执行到可执行代码时,即会进入一个执行环境。活动的执行环境构成一个栈:栈的底部始终是全局环境,顶部是当前活动的执行环境。
每个函数都有自己的执行环境,当执行到函数时,都会向栈中插入一个新的执行环境,等待执行完成就把执行环境重栈中弹出,回到上一个执行环境。最底层的执行环境就是全局执行环境(window),只在程序结束后才会被销毁
2.变量对象
概念:是执行环境在一生属性,存放着当前环境下所有可访问的数
1.函数的形参
2.var声明的变量
3.函数声明(不包括函数表达式)据
由于变量和执行环境有关,所以变量需要知道自己在变量环境中的位置以及如何获取到变量环境,这就引出了变量对象,每一个执行环境中实际上会关联着一个变量对象,变量对象存放着当前环境所有的数据(不包括上级环境中可访问的数据),简单来说变量对象和执行环境的关系是
执行环境 = {
变量对象:{
//当前环境中的数据
}
}
3.作用域
概念:当代码在该环境变量中运行的时候,会创建变量对象的一个作用域链,可以保证对执行环境有权访问的函数和变量进行有序的访问,每个环境只能沿着作用域链向上搜索,每个作用域链的最前端就是该执行环境的变量对象。
作用域链本质上,是一个指向变量对象的指针列表,它只引用但不实际包含变量对象。
注意重要的一点:[[scope]]属性在函数创建时被存储,永远不变,直到函数销毁。函数可以不被调用,但这个属性一直存在。且与作用域链相比,作用域链是执行环境的一个属性,而[[scope]]是函数的属性。
4.活动对象
概念:每个函数中的形参和实参以及声明的变量就是这个函数的活动对象,活动对象会作为这个函数的执行环境,存在于函数作用域链的最前端
即函数中的变量对象,argument属性
15.垃圾收集
1.引用计数
如果元素被引用一次那么该标记+1,当标记为0时说明没有被引用无法访问,所以会被清除,其优点是运行速度很快,其缺点是无法解决循环引用的问题,例如:
A.b = B //b属性引用着B对象
B.a = A //a属性引用着A对象
A=null;b=null;但实际上A和B还是在引用状态,无法被删除
2.标记清除
常用的就是标记清除,当变量进入环境的时候,就标记为“进入环境”,离开时标记为“离开环境”,垃圾清除会把带标记的变量清除,进行内存释放。
图片中绿色圆圈代表不需要被清除的内存,X代表需要被清除的内存空白代表空白内存
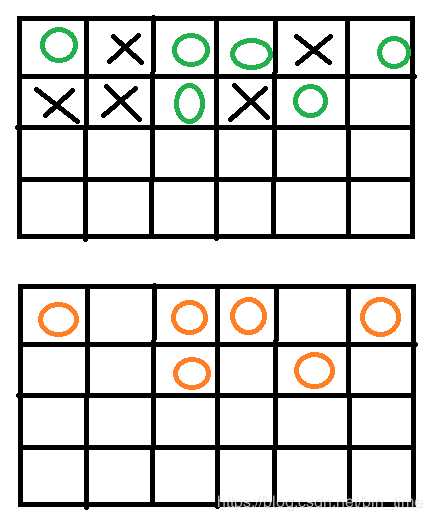
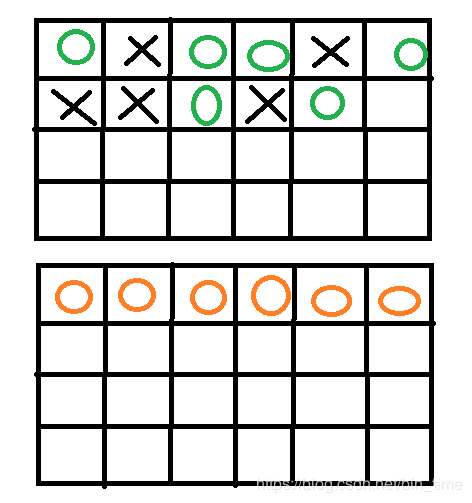
3.标记整理
标记清除的升级版,不仅可以删除释放不需要被占有的内存,还可以把内存整理好,使得零散内存变成整一块内存,就可以存放大数据(用于老年代,基本不变)
4.复制
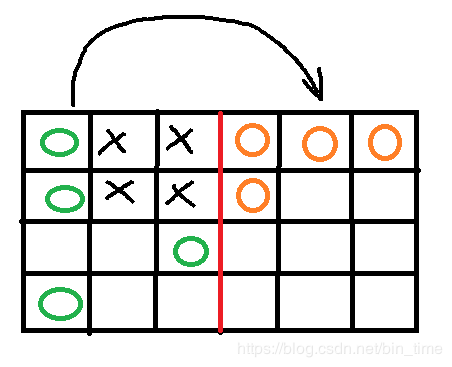
把内存分为2部分,一部分为原始数据区,一份为复制数据区,把不需要删除的存放到复制数据区,清空原始数据区。(用于新生代区,大多变量会被清除)
5.关系

创建的新元素会放入新生代的From区,From区进入复制的操作放入到To区,然后To区和From区想对换,继续进行标记阶段和清除阶段,等到达了一定的次数说明数据不会轻易改变则放入老年代区(占2/3内存),老年代区使用的是标记清除和标记整理的方法进行垃圾收集,正常情况下使用标记清除,老年代区慢了后使用标记整理。