姓名:周小蓬 16019110037
转载自:http://blog.csdn.net/dev_csdn/article/details/78594658
[嵌牛导读]
本文通过一个简单的实例详细介绍了Cassandra数据建模的五个步骤。以下是译文。
我们最近在Instaclustr发表了一篇有关在Cassandra中经常出现的数据建模错误的文章。这篇文章非常受欢迎,并促使我思考如何设计出高质量的Cassandra数据模型,以避免在设计的过程中掉入陷阱。
在互联网上,你可以找到很多有关适配数据模型设计规则和设计模式的优秀文章,例如:Apache Cassandra数据建模指南和数据建模优秀实践。
然而,我们并没有一个详细的操作步骤来指导你对数据进行分析,并适配相应的规则和模式。但这份白皮书正尝试着填补这方面的空白。
[嵌牛鼻子]
数据
[嵌牛提问]
Cassandra NoSQL数据模型是什么,如何去进行设计
[嵌牛正文]
第一阶段:了解数据
这个阶段有两个步骤,这两个步骤都是为了更好地理解你正在建模的数据和所需的访问模式。
定义数据域
第一步是深入理解数据域。作为一个非常熟悉关系数据建模的人,我倾向于通过绘制ER图来理解这些实体、主键和互相之间的关系。但是,如果你熟悉另一种标记法,你也可以用一下试试。你需要在逻辑层面理解以下关键点:
数据模型中的实体(或对象)是什么?
实体的主要关键属性是什么?
实体之间有哪些关系(即从一个到另一个的引用)?
关系的相对基数是多少(例如,假设存在一对多的关系,那么平均是1对10,还是1对10000)?
定义所需的访问模式
下一步,弄清楚你自己需要如何访问数据:
列出需要访问数据的路径,例如:
以客户ID为索引,在某个日期范围内搜索交易记录,然后从搜索结果中搜索特定交易的详细信息。按某个特定的服务器和度量标准搜索,检索x度量值,按年龄升序排列。
按某个特定的服务器和度量检索,从特定时间点开始检索x度量值。
对于给定的传感器,检索给定日期的多个度量的所有读数。
对于给定的传感器,检索当前值。
请记住,对记录的任何更新操作都是一个访问路径,都需要仔细考虑。
从性能的角度来确定哪些访问最关键。是否有一些访问需要尽可能快的速度,而其他一些访问则需要花一定的时间进行多次读取或在一定范围内进行检索?
请记住,在这个阶段,你需要非常全面地了解如何访问数据,在Cassandra的性能、可靠性和可伸缩性之间做出权衡。
第二阶段:了解实体
这个阶段有两个具体的步骤,旨在了解与数据相关的主要和次要实体。
确定主要访问实体
现在,我们开始从分析数据域和应用需求转为开始设计数据模型了。在进入这个阶段之前,你需要把上面两个步骤的工作做得扎实一点。
这一阶段主要的想法是根据你所使用的访问模式将数据去规范化到尽可能少的表中。对于每一次按键进行的查询,需要有一张表来满足查询需求。我创造了一个术语“主要访问实体”来描述用于查询的实体(例如,按客户ID进行的查找将使用客户表作为主要访问实体,按服务器和度量名称的查找将使用服务器-度量实体作为主要访问实体)。
主要访问实体定义了去规范化结果表的分区级别(即表会为每个主要访问实体的实例提供一个分区)。
你可以选择使用二级索引来满足一些访问模式,而不是使用不同的主要访问实体来实现数据复制。请记住,包含在辅助索引中的列应比被索引的表的基数更低,并且你要对索引值的更新频率了如指掌。
对于上面举的访问模式的例子,我们将定义以下主要访问实体:
客户和交易(从客户实体获取交易清单,然后从交易实体查找交易详情)
服务器-度量
传感器
传感器
分配次要实体
下一步是寻找一个地方用来存储那些没有被选为主要访问实体的实体数据(这些实体被称为次要实体)。你可以这样做:
通过从一对多关系的父级次要实体获取数据并在主要访问实体级别存储它的多个副本(例如,将客户的电话号码存储在客户的订单记录中)。
通过从一对多关系的子次要实体获取数据并通过使用聚集键或通过使用多值类型(列表和映射)将其存储在主要访问实体级别上(例如,将记录项列表添加到交易表中)。
对于一些次要实体,只有一个相关的主要访问实体,所以不需要选择在哪个方向推入数据。对于其他实体,你需要选择将数据推入哪些主要访问实体。
为了获得最佳的读取性能,需要将数据副本推送到用作次要实体中数据访问路径的每个主要访问实体中。
然而,维护多个副本数据会影响到数据插入和更新的性能,并会增加应用程序的复杂性。因此,需要根据应用程序指定的性能要求在读取性能与数据维护成本之间做出权衡。
在这个阶段要做出的另一个决定是要选择使用聚集键还是多值类型来进行数据推升。一般来说:
在只有一个子次要实体向上推升的情况下使用聚集键,特别是在子次要实体本身有子节点上卷的情况下。
在有多个子实体推升到主要实体的时候使用多值类型
请注意,这些规则可能比较简单,但它们可以引申出对这方面更深入的思考。
第三阶段:审核与调优
最后一个阶段则是在必要的情况下对数据模型进行审核、测试,以及调优。
审核分区和聚集键
在这个阶段中,你需要将所有需要存储的数据分配到一个或多个表中,并且这些表需要支持所需的访问模式。下一步是检查生成的数据模型是否有效地使用了Cassandra,如果没有,则进行调优。在这个阶段,需要检查和调整的内容包括:
分区键是否有足够的基数?如果没有,则可能需要将列从聚集键变为分区键(例如,将主键(client_id,timestamp)更改为主键((client_id,timestamp)))或引入将多个聚集键分组为分区的新列(例如,将主键(client_id,timestamp)更改为主键((client_id,day),timestamp))。
分区键中的值是否会经常更新?对主键的更新将导致记录的删除和重新插入。例如,在一个维护了所有客户的状态的表中,可能有主键(状态,客户ID)。但是,这将导致每当客户状态发生变化时都需要删除并重新插入记录。在这种情况下,最好选择集合或列表数据类型,而不是将客户ID作为聚集键。
每个分区中的记录数是否有限制?特别大的分区和或者分布非常不均匀的分区可能会出现问题。例如,假设有一张client_updates表,其主键为(client_id,update_timestamp),则客户记录的更新次数可能并没有限制,因为可能有少量的客户已经有10年未更新,而大多数客户只有一两天而已。
测试和调优
最后一步,也可能是最重要的,即对数据模型进行测试,并根据需要进行调优。请记住,像分区或记录数增长过快的问题只有在实际负载下使用几天(或更长时间)之后才能发现。因此,测试的时候需要尽可能地接近真实负载,并密切监视各种警告信息(nodetool cfstats和cfhistograms命令对此非常有用)。
在这个阶段,你也可以考虑调整一些影响数据物理存储的设置。例如:
改变压缩策略;
如果只使用TTL来删除数据的话,则可以降低gc_grace_seconds,或者
设置缓存选项。
一个完整的例子
为了说明这一点,下文将介绍一个示例,该示例构建了一个数据库,用于存储和检索来自多个服务器的日志消息。请注意,与大多数实际的案例相比,这个例子非常简单。
步骤1:定义数据域
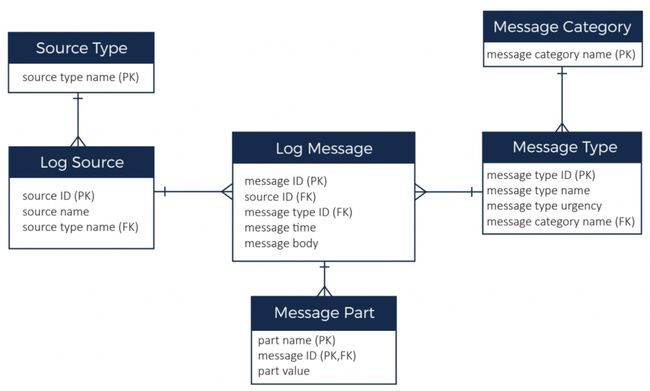
上面的ER图描述了本示例的数据域,包括:
有很多(百万数量级)的日志消息,有时间戳和主体。尽管消息ID在ER图中显示为主键,但消息时间加消息类型是备用主键。
每个日志消息都有一个消息类型,多个类型被进一步分组为一个消息类别(例如,消息类型可能是“内存不足错误”,类别可能是“错误”)。有几百个消息类型和大约20个类别。
每个日志消息来自一个消息源。消息源是生成消息的服务器。我们的系统中有1000台服务器。每个消息源都有一个源类型对其进行分类(如红帽服务器、Ubuntu服务器、Windows服务器、路由器等)。有大约20个源类型。每个源每天有大约10000条消息。
消息体可以被解析并存储为多个消息体(一般来说是键值对)。每条消息通常不超过20个消息体。
步骤2:定义所需的访问模式
我们需要能够:
检索给定源的最近10条消息的所有可用信息(并且能够从中及时回溯)。
检索给定源类型的最近10条消息的所有可用信息。
步骤3:确定主要访问实体
这里有两个主要访问实体:源和源类型。源类型的基数(约为20)使其非常适合成为二级索引,所以我们将使用源作为主要访问实体,并添加源类型为二级索引。
步骤4:分配次要实体
在这个例子中,这个步骤相对简单,因为所有数据都需要滚入到日志源主要访问实体中。所以我们需要:
下推源类型名称
下推消息类别和消息类型以记录消息
上推日志消息,使其作为新实体的聚集键
作为map类型上推消息体。
最终这将是一个带有源ID分区键和(消息时间,消息类型)聚集键的单个表。
步骤5:审核分区和聚集键
根据检查清单检查这些分区和聚集键:
分区键是否有足够的基数?是的,有1000个源。
分区键中的值是否会经常更新?不,所有的数据都是一次写入的。
每个分区中的记录数是否有限制?不,消息数可能会随着时间的推移而无限地增长。
所以,我们需要解决无限分区大小的问题。在时间序列数据中,解决这个问题的典型模式是将一组时间段引入到聚集键中。在这种情况下,每天10000条消息是一个比较合理的数字,可以包含在一个分区中,因此我们将使用“天”作为分区键的一部分。
最后,Cassandra结果表是这样的:
CREATETABLEexample.log_messages ( message_id uuid, source_name text, source_type text, message_type text, message_urgencyint, message_category text, message_timetimestamp, message_time_day text, message_body text, message_parts mapPRIMARYKEY((source_name, message_time_day,message_time, message_type) )WITHCLUSTERINGORDERBY(message_timeDESC);CREATEINDEX log_messages_sourcetype_idxONexample.log_messages (source_type);