GAN系列:代码阅读(2)——Generative Adversarial Networks & 李宏毅老师GAN课程P1+P4
昨天开会简直晴天霹雳,我们实验室所在的十楼要重新规划,这期间老师也不提供其他房间,等装好了再回去,估计至少半学期?猜一猜还能毕业吗?天天泡咖啡厅,肉疼。
这份代码在github上有好多stars,所以就看了看(主要还是因为今天忘记带耳机了,就没办法听课了)。注释直接写在代码里了。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import os
#gridspec module: 给图像分格
# 定义服从正态分布的函数,产生参数
def xavier_init(size):
# 产生标准差的过程
in_dim = size[0]
xavier_stddev = 1. / tf.sqrt(in_dim / 2.)
# 噪声服从正态分布,size[0]应该是噪声向量长度
return tf.random_normal(shape=size, stddev=xavier_stddev)
# placeholder实例通常用来为算法的实际输入值作占位符,赋值时必须用sess.run中的optional argument:feed_dict进行赋值
# X表示真实图片batch,每个图片向量长度为784:28*28
X = tf.placeholder(tf.float32, shape=[None, 784])
# Variable创建变量后必须赋值才能使用,在计算图的运算过程中,其值会一直保存到程序运行结束,
# 而一般的tensor张量在tensorflow运行过程中只是在计算图中流过,并不会保存下来
# varibale主要用来保存tensorflow构建的一些结构中的参数,
# 这些参数才不会随着运算的消失而消失,才能最终得到一个模型
# 创建初始随机噪声的权重和偏置变量
# 权重服从正态分布,784*128(因为下一层有128个神经元?);偏置初始化为0
D_W1 = tf.Variable(xavier_init([784, 128]))
D_b1 = tf.Variable(tf.zeros(shape=[128]))
# 继续创建下一层权重和偏置的变量
# 权重依然为正态分布,128*1(判别器网络只有两层?);偏置依然为0
D_W2 = tf.Variable(xavier_init([128, 1]))
D_b2 = tf.Variable(tf.zeros(shape=[1]))
# 整合所有判别器参数
theta_D = [D_W1, D_W2, D_b1, D_b2]
# Z为随机噪声的batch,向量长度为100
Z = tf.placeholder(tf.float32, shape=[None, 100])
# 生成器第一层权重和偏置变量
G_W1 = tf.Variable(xavier_init([100, 128]))
G_b1 = tf.Variable(tf.zeros(shape=[128]))
# 生成器第二层权重和偏置变量,输出784维向量,作为图片
G_W2 = tf.Variable(xavier_init([128, 784]))
G_b2 = tf.Variable(tf.zeros(shape=[784]))
# 整合生成器参数
theta_G = [G_W1, G_W2, G_b1, G_b2]
# 定义采样函数:随机生成-1到1的值,m*n
def sample_Z(m, n):
return np.random.uniform(-1., 1., size=[m, n])
# 定义生成器函数:z是输入的随机噪声batch矩阵,网络为全连接
def generator(z):
# matmul:矩阵相乘
# 生成器激活函数为relu,只有第一层激活
G_h1 = tf.nn.relu(tf.matmul(z, G_W1) + G_b1)
G_log_prob = tf.matmul(G_h1, G_W2) + G_b2
# 第二层输出前用sigmoid函数,为什么?
G_prob = tf.nn.sigmoid(G_log_prob)
return G_prob
# 定义判别器函数:x是输入的图像batch矩阵
def discriminator(x):
# 网络也为全连接,最后sigmoid输出,可以理解为二分类器
D_h1 = tf.nn.relu(tf.matmul(x, D_W1) + D_b1)
D_logit = tf.matmul(D_h1, D_W2) + D_b2
D_prob = tf.nn.sigmoid(D_logit)
# 判别器sigmoid前的结果也输出了
return D_prob, D_logit
# 定义画图函数,samples是要画的图像集
def plot(samples):
# 在matplotlib中,整个图像为一个Figure对象。在Figure对象中可以包含一个或者多个Axes对象。
# 每个Axes(ax)对象都是一个拥有自己坐标系统的绘图区域
# 创建图像窗口,定义尺寸4*4
fig = plt.figure(figsize=(4, 4))
# gridspec将整个图像分格:4*4共16个
gs = gridspec.GridSpec(4, 4)
# 调整图像布局参数,只影响当前Gridspec对象
gs.update(wspace=0.05, hspace=0.05)
# 遍历图像集,拼成一个大图用来展示结果
for i, sample in enumerate(samples):
# title为图像标题,Axis为坐标轴,Tick为刻度线,Tick Label为刻度注释
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
# 把图像变回28*28,cmap表示使用'Greys_r'灰度图
plt.imshow(sample.reshape(28, 28), cmap='Greys_r')
# 返回整张大图
return fig
# 把随机噪声batch矩阵输入生成器中,产生生成图像batch矩阵
G_sample = generator(Z)
# 把图像batch矩阵输入判别器得到结果
# D_logit_real是sigmoid之前的结果,用于logistic回归
D_real, D_logit_real = discriminator(X)
# 把生成图像batch矩阵输入判别器得到结果
D_fake, D_logit_fake = discriminator(G_sample)
# GAN论文中loss定义:reduce_mean因为求均值降维,得到的loss是标量
# 参数axis默认为所有维度(表示对正负样本两个batch中的所有图像求均值:axis=0表示一个batch内的求均值;axis=1,表示正负样本求均值)
# D_loss = -tf.reduce_mean(tf.log(D_real) + tf.log(1. - D_fake))
# G_loss = -tf.reduce_mean(tf.log(D_fake))
# Alternative losses:
# -------------------
# 分别计算正负样本与标签1和0之间的交叉熵,再合并
# 和原始方法比,相当于给判别器打分一个基准:0和1
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_real, labels=tf.ones_like(D_logit_real)))
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.zeros_like(D_logit_fake)))
D_loss = D_loss_real + D_loss_fake
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.ones_like(D_logit_fake)))
# 优化算法为Adam,两者都是minimize
# 原本的判别器loss形式导致其值越大,判别器效果越好;现在的形式表示loss值越小,性能越好,因此是minimize
D_solver = tf.train.AdamOptimizer().minimize(D_loss, var_list=theta_D)
G_solver = tf.train.AdamOptimizer().minimize(G_loss, var_list=theta_G)
# batch_size
mb_size = 128
# 随机噪声向量长度
Z_dim = 100
# 载入数据
mnist = input_data.read_data_sets('../../MNIST_data', one_hot=True)
# A Session object encapsulates the environment in which Operation objects are executed
# and Tensor objects are evaluated
sess = tf.Session()
# global_variables_initializer:Returns an Op that initializes global variables
# 就是初始化参数的操作
sess.run(tf.global_variables_initializer())
# 如果路径中没有输出图像的文件夹,创建一个
if not os.path.exists('out/'):
os.makedirs('out/')
i = 0
# 一共训练1000000次
for it in range(1000000):
# 每1000次迭代输出一次生成结果并保存
if it % 1000 == 0:
# 一次结果中包含16个小图片
samples = sess.run(G_sample, feed_dict={Z: sample_Z(16, Z_dim)})
fig = plot(samples)
plt.savefig('out/{}.png'.format(str(i).zfill(3)), bbox_inches='tight')
i += 1
plt.close(fig)
# 按照设置的batch_size从训练集中取图片
X_mb, _ = mnist.train.next_batch(mb_size)
# 训练过程:判别器和生成器训练同样次数?是因为用了Adam的优化算法吗?
_, D_loss_curr = sess.run([D_solver, D_loss], feed_dict={X: X_mb, Z: sample_Z(mb_size, Z_dim)})
_, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={Z: sample_Z(mb_size, Z_dim)})
# 每1000次输出当前迭代的次数,判别器和生成器优化前的loss
if it % 1000 == 0:
print('Iter: {}'.format(it))
print('D loss: {:.4}'. format(D_loss_curr))
print('G_loss: {:.4}'.format(G_loss_curr))
print()
在自己电脑上跑了一下,到Iter=122000出现了MemoryError,此时loss如下:

有一个大神复现了这个代码并且对loss可视化了,如图:

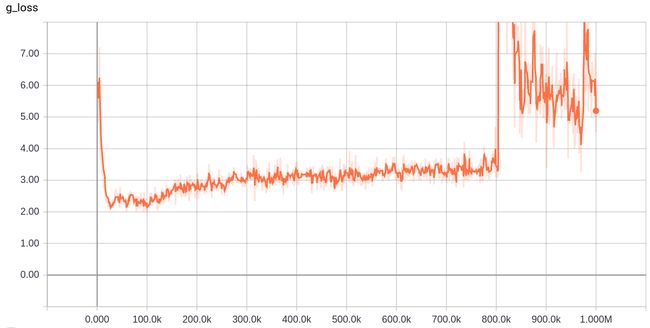
我这是卡在了122k的位置,g_loss和他接近,d_loss倒是好一些,这个原因我还没想。这位大神的博客地址:https://blog.csdn.net/jiongnima/article/details/80033169。
我的图像结果:
000:

010:

020:

030:

040:

050:

060:

070:

080:

090:

100:

110:

120:

虽然没结束,但是已经出现不断重复产生同一个数字的结果了,这就是之前提到过的Mode Collapse问题,可以尝试用WGAN解决。WGAN的代码这个作者也给出了,简单看了一眼,好像是通过weight-clipping实现的,到时候再具体看一下。
试了一下用这个代码里判别器经过sigmoid以后的输出:D_real和D_fake,发现判别器loss降低了,但生成器loss是升高的。

至于生成器和判别器的网络结构能否改进,也可以尝试一下;然后不同的优化算法也可以尝试一下;原始的loss也可以尝试。