麦克风阵列入门(一)
由于太忙,实在没时间整理,今天抽出空整理一点,日后会继续跟上,学会总结是进步的关键。下面几乎是干货,不会太详细,还望见谅。
什么是麦克风阵列:
所谓麦克风阵列其实就是一个声音采集的系统,该系统使用多个麦克风采集来自于不同空间方向的声音。
为什么使用麦克风阵列:
麦克风按照指定要求排列后,加上相应的算法(排列+算法)就可以解决很多房间声学问题,比如声源定位、去混响、语音增强、盲源分离等。
【注】:在深入理解概念之前,我们先理解一下麦克风的知识
什么是麦克风的指向性(方向性):
麦克风的方向性是指麦克风可以接收到语音的方向。声音可以从不同的方向传达到麦克风,麦克风的前面/后面/侧面,麦克风将会根据自身的指向性来获取声音。
一个麦克风可以以很高的灵敏度接收来自于前方的声音,而不管后方和侧面的声音,另一个麦克风还可以接收来自于前面和后面的声音,而不管侧面的,有很多种组合。
什么是指向性麦克风:
所谓指向性麦克风是指麦克风要么接收来自于指定方向的声音,要么接收所有角度传来的声音,这取决于麦克风的自身指向属性。
常用的指向性麦克风:
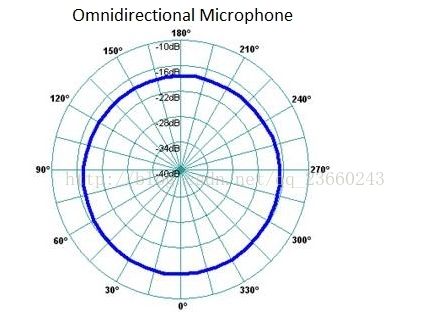
- 全向麦克风
有些麦克风接收来自于任何方向的声音,这种麦克风叫做全向麦克风(
omnidirectional microphones)。不管说话的人在哪里对着麦克风说话,前后左右,从0°到360°,所有的这些声音都会以相同的灵敏度被拾取。
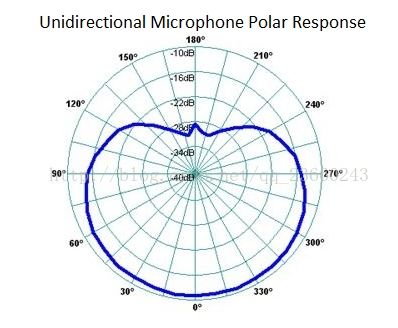
- 单向麦克风
其他的一些麦克风是单向的(
unidirectional),他们仅仅接收从指定方向来的声音。当人们对着单向麦克风说话时,要慎重选择对着麦克风的方向。我们必须要对着“接收方向”说话来获得更好的声音增益,任何不同于此方向的声音都会被削弱接收,这也就意味着增益很小。
- 双向麦克风
另外一种麦克风叫做双向麦克风(
bidirectional microphone),这种麦克风可以很好的接收来自于前向和后向的声音,但是两侧的声音增益很小。他在隔膜的相对两侧拾取具有相等灵敏度的声波,与隔膜成直角的指向null。

- 心型麦克风
另外一种是心型麦克风(
cardioid microphone),它可以接收来自于前方和两侧的声音,但是后面的声音的增益很小。事实上,他们名字来源于他们的声音拾取方向,非常的像一个心。

注意:这里没有任何一种麦克风可以说比别的怎么怎么好,不同种类的麦克风在不同的使用环境下有各自的优缺点。从上面看起来,全向麦克风比其他的要好,因为它可以接收来自于所有方向的声音而不是仅仅一个方向,但是试想如果在一个比较嘈杂的环境下,全向麦克风是一个比较low的选择,因为除了我们所需要的声音外,他还录了周围的噪音。在这种环境下,指向性(非全指向性麦克风)麦克风可能会更好,因为他在获取我们所需要方向的声音外,对其他方向的声音进行了压制,使得噪声的增益非常少。所以,这些麦克风的好坏取决于用的环境。
麦克风的排列及原理:
麦克风不同的排列对应不同的算法,那么最简单的排列就是线性排列了,也就是麦克风排列成一排。在远场(指说话人距离麦克风很远)的情况下,我们一般认为人说话的波形是平面波,如下:

那么每个麦克风接收到的信号在同一时刻都不会相同,因为有时延,你可能会问什么是时延,那么下面给出具体的统一线性麦克风阵列模型图:
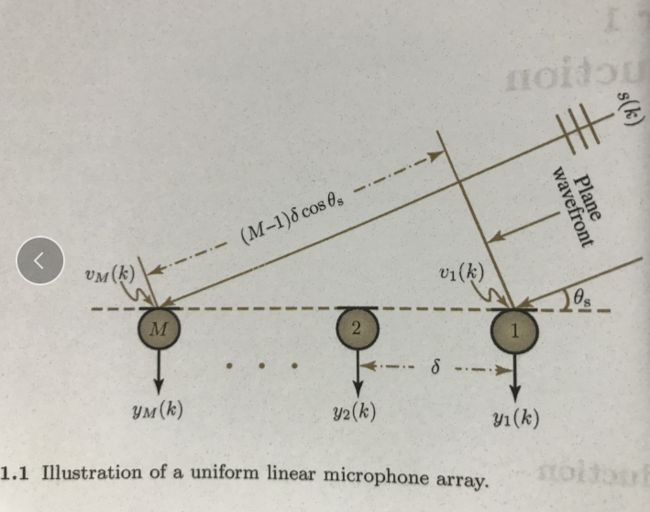
这个模型具体参数此处不做讲解,很简单直白。那么从这里我们可以看出来,每个麦克风接收到的数据ym(k)与之前的麦克风接收到的数据之前存在延迟。其公式如下:
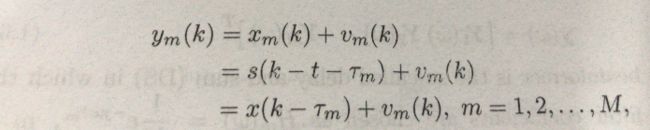
时间延迟如下(c是声速340m/s):
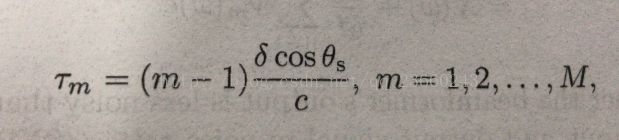
一般我们都是转化到频域去处理,所以将上述傅里叶变换后得到(别问我傅里叶变换是什么):
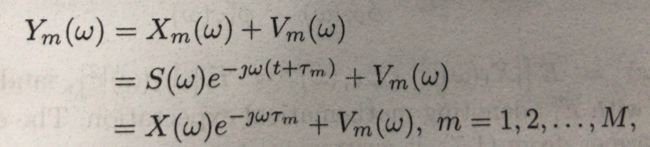
切记,这里都是原式子的傅里叶变换后的形式。
好了,理论模型推理到这里,那么开始看我们手头有什么数据,说白了,方程中有哪些参数我们是已知的,ym(k)是已知的,这就是我们的麦克风接收到的数据呀,术语观测数据。这时候不要脑袋一热就开始根据模型往回带数据,模型仅仅是为我们提供参考思路(即使想带回去也不行,vm根本就未知)。
得知观测数据的我们,需要从观测数据中抽离我们想要的内容,那么很自然的想到滤波器。我们称这种滤波器叫做:波束形成滤波器(因为它增强了我们想要的内容,削弱了我们不想要的内容,跟前面的指向性麦克风联系起来,是不是感觉世界很奇妙):
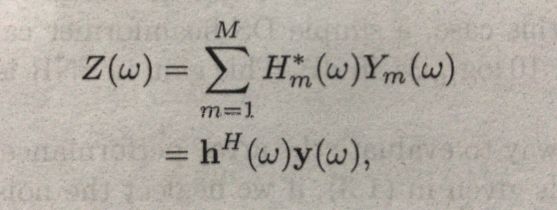
其中:
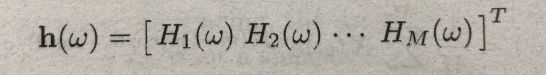
而这个得到的Z,就是我们所要求的。
问题到了这里变得很清晰,如何估计这个滤波器。波束增强有很多种算法,有很多种估计滤波器的方式,从简单到复杂,从效果差到效果好,各有不同。那么我们这里说一下基于我们上面模型的最简单的delay-and-sum(DS)滤波器,他的效果用一句话概括就是:我们仅仅把各个麦克风接收到的信号补偿他们的时延,然后求一个均值,没有考虑混响等实际场景可能发生的情况。那么,我们的Z如下:
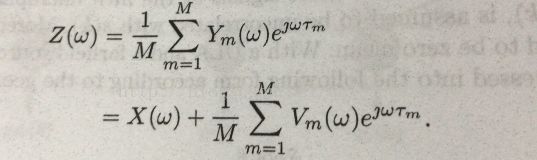
从而我们用最简单的办法得到了我们所要的信号,其性能评估等后续说明。