nodejs玩儿转进程
序言
- nodejs是如何充分利用多核cup 服务器的?
- 如何保证进程的稳健型?
正文
因为Node运行在V8引擎上,我们的JavaScript 将会运行在单个进程的单个线程上。它带来的好处是: 程序状态是单一的,在没有多线程的情况 下没有锁、线程同步问题,操作系统在调度时也因为较少上下文的切换,可以很好地提高CPU的使用率
从严格的意义上而言,Node并非真正的单线程架构,Node自身还有 一定的I/O线程存在,这些I/O线程由底层libuv处理,这部分线程对于JavaScript开发者而言是透明 的,只在C++扩展开发时才会关注到
进程和线程的区别及优劣:
1进程是操作系统分配资源的最小单元
多进程的缺点主要体现在
1 无法共享内部状态(进程池的方式可以解决)
2 以及创建和销毁进程时候
多线程相对多进程的优点:
创建和销毁线程相对进程来说开销小很多,(并且线程之间可以共享数据 ,内存浪费的问题得
以解决)并且利用线程池可以减少创建和销毁线程的开销
多线程的缺点:
每个线程都有自己独立的堆栈,每个堆栈都要占用一定的内存空间
服务模型的变迁:
从“古”到今,Web服务器的架构已经历了几次变迁。从服务器处理客户端请求的并发量这个纬度来看,每次变迁都是里程碑的见证
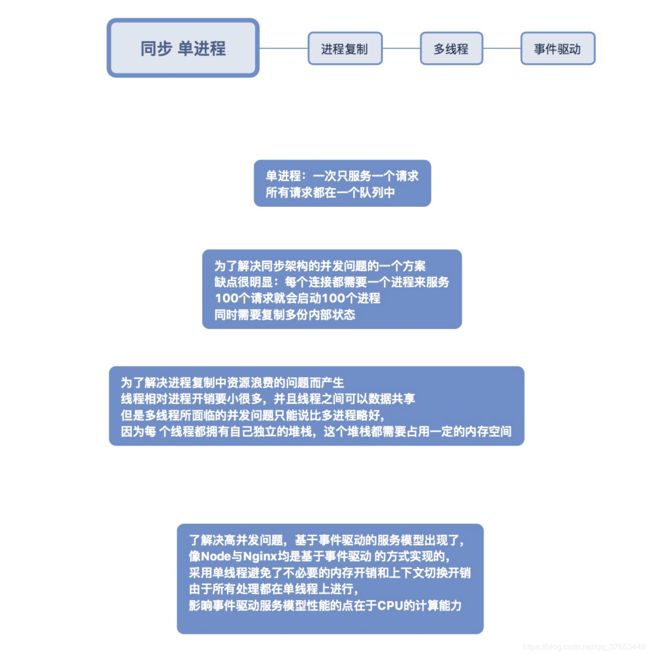
由此来看 多线程和事件驱动都有自己弊端
事件驱动:CPU的计算能力决定这类服务的性能上线
多线程模式:受资源上限的影响
那么nodejs是如何充分利用多核cup 服务器的?
答案是通过fork进程的方式 ,我们再一次将经典的示例代码存为worker.js文件,代码如下:
var http = require('http'); http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(Math.round((1 + Math.random()) * 1000), '127.0.0.1');
通过node worker.js启动它,将会侦听1000到2000之间的一个随机端口
将以下代码存为master.js,并通过node master.js启动它:
/**
* 充分利用cup的资源同时启动在多个进程上启动服务
*/
const cpus = require("os").cpus();
const fork = require("child_process").fork;
for (let index = 0; index < cpus.length; index++) {
fork("./worker.js");
}
这段代码将会根据当前机器上的CPU数量复制出对应Node进程数。在*nix系统下可以通过ps aux | grep worker.js查看到进程的数量,如下所示
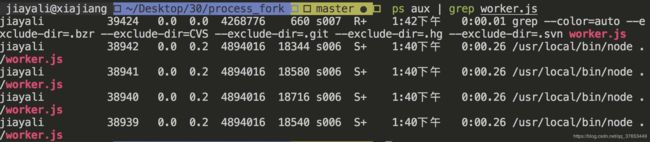
创建子进程
child_process 模块赋予了node可以随意创建子进程的能力 ,它提供了4个方法用于创建子进程:
spawn(): 启动一个子进程来执行命令
exec: 启动一个子进程来执行命令,与spawn不同的是其接口不同,他有一个回掉函数来获知子进程的状况。
execFile():启动一个子进程来执行可执行文件。
fork():与spawn()类似,不同点在于它创建Node的子进程只需指定要执行的JavaScript文件模块即可。
spawn()与exec()、execFile()的不同是:
后两者创建时可以指定timeout属性设置超时时间,一旦创建的进程运行超过设定的时间将会
被杀死。
exec()与execFile()不同的是,exec()适合执行已有的命令,execFile()适合执行文件。这里我们以一个寻常命令为例,node worker.js分别用上述4种方法实现,如下所示
var cp = require('child_process');
//spawn
cp.spawn('node', ['worker.js']);
//exec
cp.exec('node worker.js', function (err, stdout, stderr) {
// some code
});
//execFile
cp.execFile('worker.js', function (err, stdout, stderr) {
// some code
});
//fork
cp.fork('./worker.js');

如果是JavaScript文件通过execFile()运行,它的首行内容必须添加如下代码
#!/usr/bin/env node
尽管4种创建子进程的方式有些差别,但事实上后面3种方法都是spawn()的延伸应用
进程间通信
主线程与工作线程之间通过onmessage()和postMessage()进行通信,子进程对象则由send() 方法实现主进程向子进程发送数据,message事件实现收听子进程发来的数据,与API在一定 程度上相似。通过消息传递内容,而不是共享或直接操作相关资源,这是较为轻量和无依赖 的做法
parent.js
//
var cp = require('child_process');
var n = cp.fork(__dirname + '/sub.js');
n.on('message', function (m) { console.log('PARENT got message:', m);
});
n.send({hello: 'world'});
sub.js
process.on('message', function (m) {
console.log('CHILD got message:', m);
});
process.send({foo: 'bar'});
通过fork()或者其他API,创建子进程之后,为了实现父子进程之间的通信,父进程与子进程之间将会创建IPC通道。通过IPC通道,父子进程之间才能通过message和send()传递消息
进程间通信原理
IPC的全称是Inter-Process Communication,即进程间通信
进程间通信的目的是为了让不同的进程能够互相访问资源并进行协调工作
实现进程间通信的技术有很多,如
命名管道
匿名管道
socket
信号量
共享内存
消息队列
Domain Socket等
Node中实现IPC通道的是管道(pipe) 技术。但此管道非彼管道,在Node中管道是个抽象层面的称呼,具体细节实现由libuv提供,在 Windows下由命名管道(named pipe)实现,*nix系统则采用Unix Domain Socket实现。表现在应用层上的进程间通信只有简单的message事件和send()方法,接口十分简洁和消息化。下图为IPC 创建和实现的示意图。
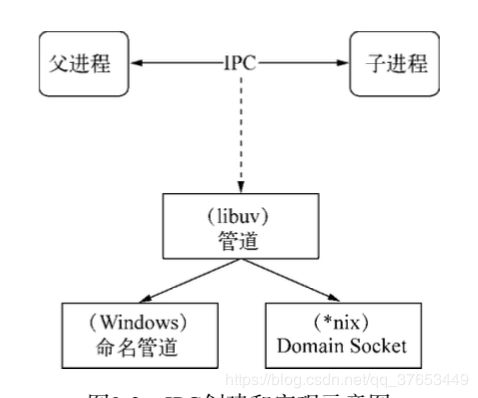
父进程在实际创建子进程之前,会创建IPC通道并监听它,然后才真正创建出子进程并通 过环境变量(NODE_CHANNEL_FD)告诉子进程这个IPC通道的文件描述符。子进程在启动的过程中, 根据文件描述符去连接这个已存在的IPC通道,从而完成父子进程之间的连接
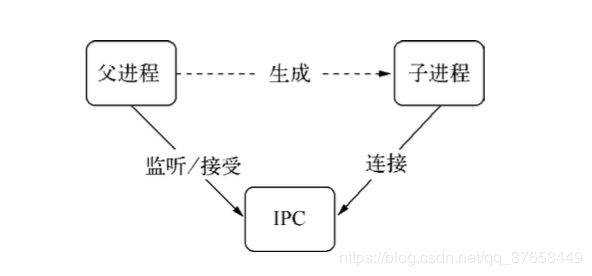
句柄传递
建立好进程之间的IPC后,如果仅仅只用来发送一些简单的数据,显然不够我们的实际应用 使用
如果让服务都监听 到相同的端口,将会有什么样的结果?
这时只有一个工作进程能够监听到该端口上,其余的进程在监听的过程中都抛出了 EADDRINUSE异常,这是端口被占用的情况,新的进程不能继续监听该端口了。这个问题破坏了我 们将多个进程监听同一个端口的想法。要解决这个问题,通常的做法是让每个进程监听不同的端 口,其中主进程监听主端口(如80),主进程对外接收所有的网络请求,再将这些请求分别代理 到不同的端口的进程上。示意图如图9-4所示。
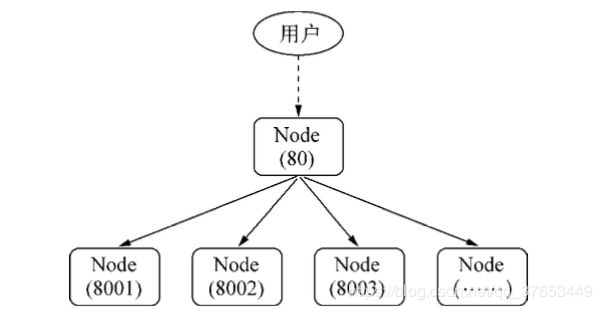
通过代理,可以避免端口不能重复监听的问题,甚至可以在代理进程上做适当的负载均衡, 使得每个子进程可以较为均衡地执行任务。由于进程每接收到一个连接,将会用掉一个文件描述 符,因此代理方案中客户端连接到代理进程,代理进程连接到工作进程的过程需要用掉两个文件 描述符。操作系统的文件描述符是有限的,代理方案浪费掉一倍数量的文件描述符的做法影响了 系统的扩展能力
主进程代码如下所示
var child = require('child_process').fork('child.js');
// Open up the server object and send the handle
var server = require('net').createServer();
server.on('connection', function (socket) {
socket.end('handled by parent\n');
});
server.listen(1337, function () {
child.send('server', server);
});
子进程代码如下所示:
process.on('message', function (m, server) {
if (m === 'server') {
server.on('connection', function (socket) {
socket.end('handled by child\n');
});
}
});
然后新开一个命令行窗口,用上curl工具,如下所示:
$ curl "http://127.0.0.1:1337/"
handled by parent
$ curl "http://127.0.0.1:1337/"
handled by child
$ curl "http://127.0.0.1:1337/"
handled by child
$ curl "http://127.0.0.1:1337/"
handled by parent
命令行中的响应结果也是很不可思议的,这里子进程和父进程都有可能处理我们客户端发起 的请求。
试试将服务发送给多个子进程,如下所示:
parent.js
var cp = require('child_process');
var child1 = cp.fork('child.js');
var child2 = cp.fork('child.js');
// Open up the server object and send the handle
var server = require('net').createServer();
server.on('connection', function (socket) {
socket.end('handled by parent\n');
});
server.listen(1337, function () {
child1.send('server', server);
child2.send('server', server);
});
然后在子进程中将进程ID打印出来,如下所示:
// child.js
process.on('message', function (m, server) {
if (m === 'server') {
server.on('connection', function (socket) {
socket.end('handled by child, pid is ' + process.pid + '\n');
});
}
});
再用curl测试我们的服务,如下所示:
$ curl "http://127.0.0.1:1337/"
handled by child, pid is 24673
$ curl "http://127.0.0.1:1337/"
handled by parent
$ curl "http://127.0.0.1:1337/"
handled by child, pid is 24672
测试的结果是每次出现的结果都可能不同,结果可能被父进程处理,也可能被不同的子进程 处理。
其实我们可以在父进程启动之后立马把他close掉
const cp = require("child_process")
const child1 = cp.fork("child.js");
const child2 = cp.fork('child.js');
const server = require("net").createServer();
server.on("connection",(socket)=>{
socket.end('handled by parent\n');
})
server.listen(1337,()=>{
child2.send('server', server);
child1.send('server', server);
server.close();
})
整个过程中,服务的过程发生了一次改变,如
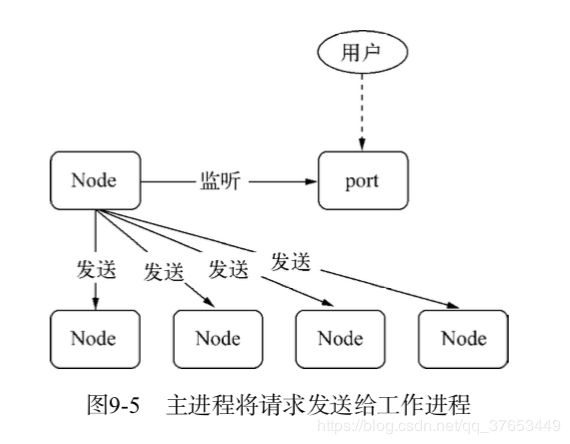
主进程发送完句柄并关闭监听之后成为了下图所示的结构
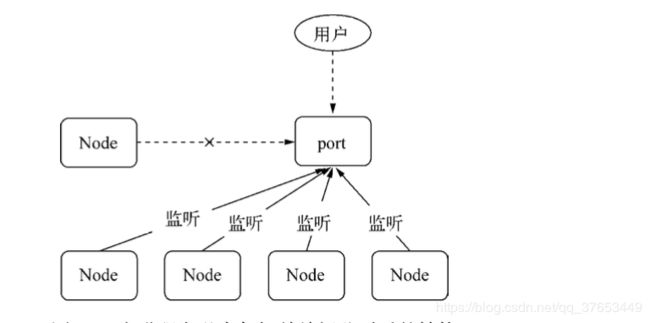
我们神奇地发现,多个子进程可以同时监听相同端口,再没有EADDRINUSE异常发生了
句柄发送与还原
句柄发送跟我们直接将服务器对象发送给子进程有没有差别?它是否真的将服务器对象发送给了子进程?为什么它可以发送到多个子进程 中?发送给子进程为什么父进程中还存在这个对象?
目前子进程对象send()方法可以发送的句柄类型包括如下几种。
- net.Socket。TCP套接字。
- net.Server。TCP服务器,任意建立在TCP服务上的应用层服务都可以享受到它带来的好处。
- net.Native。C++层面的TCP套接字或IPC管道。
- dgram.Socket。UDP套接字。
- dgram.Native。C++层面的UDP套接字。
send()方法在将消息发送到IPC管道前,将消息组装成两个对象,一个参数是handle,另一个 是message。message参数如下所示
{
cmd: 'NODE_HANDLE',
type: 'net.Server',
msg: message
}
发送到IPC管道中的实际上是我们要发送的句柄文件描述符,文件描述符实际上是一个整数 值。这个message对象在写入到IPC管道时也会通过JSON.stringify()进行序列化。所以最终发送 到IPC通道中的信息都是字符串,send()方法能发送消息和句柄并不意味着它能发送任意对象。
连接了IPC通道的子进程可以读取到父进程发来的消息,将字符串通过JSON.parse()解析还 原为对象后,才触发message事件将消息体传递给应用层使用。在这个过程中,消息对象还要被 进行过滤处理,message.cmd的值如果以NODE_为前缀,它将响应一个内部事件internalMessage。
如果message.cmd值为NODE_HANDLE,它将取出message.type值和得到的文件描述符
一起还原出一个对应的对象。这个过程的示意图如图所示

以发送的tcp服务器句柄为例 子进程收到消息后的还原过程如下
function(message, handle, emit) {
var self = this;
var server = new net.Server();
server.listen(handle, function() {
emit(server); 4 });
}
上面的代码中,子进程根据message.type创建对应TCP服务器对象,然后监听到文件描述符上。由于底层细节不被应用层感知,所以在子进程中,开发者会有一种服务器就是从父进程中直接传递过来的错觉。值得注意的是,Node进程之间只有消息传递,不会真正地传递对象,这种错 觉是抽象封装的结果
端口共同监听
多个进程可以监听到 相同的端口而不引起EADDRINUSE异常?
我们独立启动的进程中,TCP服务器端socket套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。
Node底层对每个端口监听都设置了SO_REUSEADDR选项,这个选项的涵义是不同进程可以就相 同的网卡和端口进行监听,这个服务器端套接字可以被不同的进程复用,如下所示
setsockopt(tcp->io_watcher.fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on))
由于独立启动的进程互相之间并不知道文件描述符,所以监听相同端口时就会失败。但对于 send()发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引 起异常
多个应用监听相同端口时,文件描述符同一时间只能被某个进程所用。换言之就是网络请求 向服务器端发送时,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求进行服务。 这些进程服务是抢占式的。
集群稳定之路
搭建好了集群,充分利用了多核CPU资源,似乎就可以迎接客户端大量的请求了。但请等等, 我们还有一些细节需要考虑。
- 性能问题。
- 多个工作进程的存活状态管理。
- 工作进程的平滑重启。
- 配置或者静态数据的动态重新载入。
- 其他细节。
进程事件
再次回归到子进程对象上,除了引人关注的send()方法和message事件外,子进程还有些什 么呢?首先除了message事件外,Node还有如下这些事件:
error:当子进程无法被复制创建、无法被杀死、无法发送消息时会触发该事件
exit:子进程退出时触发该事件,子进程如果是正常退出,这个事件的第一个参数为退出 码,否则为null。如果进程是通过kill()方法被杀死的,会得到第二个参数,它表示杀死进程时的信号。
close:在子进程的标准输入输出流中止时触发该事件,参数与exit相同
disconnect:在父进程或子进程中调用disconnect()方法时触发该事件,在调用该方法时将关闭监听IPC通道。
自动重启
有了父子进程之间的相关事件之后,就可以在这些关系之间创建出需要的机制了。至少我们 能够通过监听子进程的exit事件来获知其退出的信息,接着前文的多进程架构,我们在主进程上 要加入一些子进程管理的机制,比如重新启动一个工作进程来继续服务。
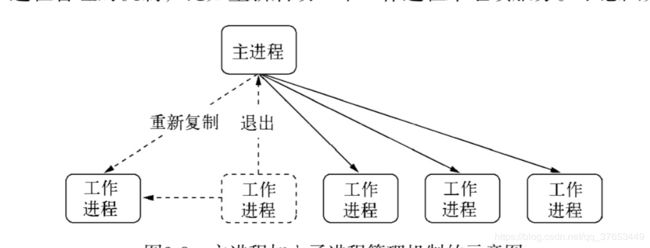
实现代码如下所示:
master.js
// 主进程
const fork = require("child_process").fork;
const cpus = require("os").cpus();
// 创建tcp server
const server = require("net").createServer();
server.listen(1337);
const workers = {}
// 创建进程的函数
const createWorker = () =>{
const worker = fork(__dirname+"/work.js");
// 监听进程退出事件 自动重启
worker.on("exit",()=>{
delete workers[worker.pid];
console.log(worker.pid+"is delete");
createWorker();
})
// 发送当前进程的句柄文件描述符
worker.send("server",server)
workers[worker.pid]= worker
console.log('created worker :', worker.pid);
}
for (let index = 0; index < cpus.length; index++) {
createWorker();
}
// 进程自己退出时,让所有工作进程退出
process.on('exit', function () {
for (var pid in workers) {
workers[pid].kill();
}
});
console.log('process.pid', process.pid)
work.js
var http = require('http');
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('handled by child, pid is' + process.pid + '\n');
});
var worker;
process.on('message', function (m, tcp) {
if (m === 'server') {
worker = tcp;
worker.on('connection', function (socket) {
server.emit('connection', socket);
});
}
});
process.on('uncaughtException', function () { // 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
});
});
测试一下上面的代码,如下所示:
$ node master.js
Create worker: 30504
Create worker: 30505
Create worker: 30506
Create worker: 30507
上述代码的处理流程是,一旦有未捕获的异常出现,工作进程就会立即停止接收新的连接; 当所有连接断开后,退出进程。主进程在侦听到工作进程的exit后,将会立即启动新的进程服务, 以此保证整个集群中总是有进程在为用户服务的。
通过kill命令杀死某个进程试试,如下所示
$ kill 30506
结果是30506进程退出后,自动启动了一个新的工作进程30518,总体进程数量并没有发生改 变,如下所示:
Worker 30506 exited.
Create worker. pid: 30518
自杀信号
当然上述代码存在的问题是要等到已有的所有连接断开后进程才退出,在极端的情况下,所 有工作进程都停止接收新的连接,全处在等待退出的状态。但在等到进程完全退出才重启的过程 中,所有新来的请求可能存在没有工作进程为新用户服务的情景,这会丢掉大部分请求。
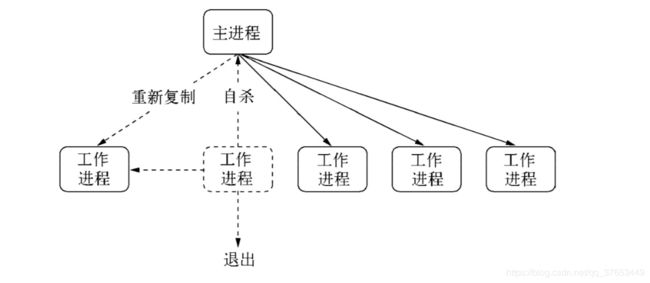
为此需要改进这个过程,不能等到工作进程退出后才重启新的工作进程。当然也不能暴力退 出进程,因为这样会导致已连接的用户直接断开。于是我们在退出的流程中增加一个自杀 (suicide)信号。工作进程在得知要退出时,向主进程发送一个自杀信号,然后才停止接收新的 连接,当所有连接断开后才退出。主进程在接收到自杀信号后,立即创建新的工作进程服务。
代码改动如下所示:
// master.js 主要是重启进程的任务放到了 接收到suicide 事件之后
// 主进程
const fork = require("child_process").fork;
const cpus = require("os").cpus();
// 创建tcp server
const server = require("net").createServer();
server.listen(1337);
const workers = {}
// 创建进程的函数
const createWorker = () =>{
const worker = fork(__dirname+"/work.js");
// 启动新的进程
worker.on('message', function (message) {
if (message.act === 'suicide') {
createWorker();
}
});
worker.on("exit",()=>{
delete workers[worker.pid];
console.log(worker.pid+"is delete");
})
// 发送当前进程的句柄文件描述符
worker.send("server",server)
workers[worker.pid]= worker
console.log('created worker :', worker.pid);
}
for (let index = 0; index < cpus.length; index++) {
createWorker();
}
// 进程自己退出时,让所有工作进程退出
process.on('exit', function () {
for (var pid in workers) {
workers[pid].kill();
}
});
console.log('process.pid', process.pid)
work.js主要是再接收到未捕获的异常之后向主进程发送事件告知子进程将要退出 此时创建新的进程为用户服务 ,之后子进程才退出 再回头看重启信息,如下所示:
created worker : 14397
14394is delete
与前一种方案相比,创建新工作进程在前,退出异常进程在后。在这个可怜的异常进程退出 之前,总是有新的工作进程来替上它的岗位。至此我们完成了进程的平滑重启,一旦有异常出现, 主进程会创建新的工作进程来为用户服务,旧的进程一旦处理完已有连接就自动断开。整个过程 使得我们的应用的稳定性和健壮性大大提高。示意图如图所示
这里存在问题的是有可能我们的连接是长连接,不是HTTP服务的这种短连接,等待长连接 断开可能需要较久的时间。为此为已有连接的断开设置一个超时时间是必要的,在限定时间里强 制退出的设置如下所示:
process.on('uncaughtException', function (err) {
process.send({act: 'suicide'}); 2 // 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
}); // 5秒后退出进程
setTimeout(function () {
process.exit(1);
}, 5000);
});
进程中如果出现未能捕获的异常,就意味着有那么一段代码在健壮性上是不合格的。为此退 出进程前,通过日志记录下问题所在是必须要做的事情,它可以帮我们很好地定位和追踪代码异 常出现的位置,如下所示:
process.on('uncaughtException', function (err) { // 记录日志
logger.error(err);
// 发送自杀信号
process.send({act: 'suicide'}); // 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
});
// 5秒后退出进程
setTimeout(function () {
process.exit(1);
}, 5000);
});
通过自杀信号告知主进程可以使得新连接总是有进程服务,但是依然还是有极端的情况。工 作进程不能无限制地被重启,如果启动的过程中就发生了错误,或者启动后接到连接就收到错误, 会导致工作进程被频繁重启,这种频繁重启不属于我们捕捉未知异常的情况,因为这种短时间内 频繁重启已经不符合预期的设置,极有可能是程序编写的错误。
为了消除这种无意义的重启,在满足一定规则的限制下,不应当反复重启。比如在单位时间 内规定只能重启多少次,超过限制就触发giveup事件,告知放弃重启工作进程这个重要事件。
为了完成限量重启的统计,我们引入一个队列来做标记,在每次重启工作进程之间进行打点 并判断重启是否太过频繁,如下所示:
// 重启次数
var limit = 10;
// 时间单位
var during = 60000;
var restart = [];
var isTooFrequently = function () {
// 记录重启时间
var time = Date.now();
var length = restart.push(time);
if (length > limit) {
// 取出最后10个记录
restart = restart.slice(limit * -1);
}
// 最后一次重启到前10次重启之间的时间间隔
return restart.length >= limit && restart[restart.length - 1] - restart[0] < during;
};
var workers = {};
var createWorker = function () {
// 检查是否太过频繁
if (isTooFrequently()) {
// 触发giveup事件后,不再重启
process.emit('giveup', length, during);
return;
}
var worker = fork(__dirname + '/worker.js');
worker.on('exit', function () {
console.log('Worker ' + worker.pid + ' exited.');
delete workers[worker.pid];
});
// 重新启动新的进程
worker.on('message', function (message) {
if (message.act === 'suicide') {
createWorker();
}
});
// 句柄转发
worker.send('server', server); workers[worker.pid] = worker;
console.log('Create worker. pid: ' + worker.pid);
};
giveup事件是比uncaughtException更严重的异常事件。uncaughtException只代表集群中某个
工作进程退出,在整体性保证下,不会出现用户得不到服务的情况,但是这个giveup事件则表示 集群中没有任何进程服务了,十分危险。为了健壮性考虑,我们应在giveup事件中添加重要日志, 并让监控系统监视到这个严重错误,进而报警等。
负载均衡
在多进程之间监听相同的端口,使得用户请求能够分散到多个进程上进行处理,这带来的好 处是可以将CPU资源都调用起来。这犹如饭店将客人的点单分发给多个厨师进行餐点制作。既然 涉及多个厨师共同处理所有菜单,那么保证每个厨师的工作量是一门学问,既不能让一些厨师忙不过来,也不能让一些厨师闲着,这种保证多个处理单元工作量公平的策略叫负载均衡。
Node默认提供的机制是采用操作系统的抢占式策略。所谓的抢占式就是在一堆工作进程中,闲着的进程对到来的请求进行争抢,谁抢到谁服务。
一般而言,这种抢占式策略对大家是公平的,各个进程可以根据自己的繁忙度来进行抢占。对于Node而言,它的繁忙是由CPU、I/O两个部分构成的,影响抢占的是CPU 的繁忙度。对不同的业务,可能存在I/O繁忙,而CPU较为空闲的情况,这可能造成某个进程能 够抢到较多请求,形成负载不均衡的情况
为此Node在v0.11中提供了一种新的策略使得负载均衡更合理,这种新的策略叫 Round-Robin,又叫轮叫调度。轮叫调度的工作方式是由主进程接受连接,将其依次分发给工作 进程。分发的策略是在N个工作进程中,每次选择第i = (i + 1) mod n个进程来发送连接。在cluster 模块中启用它的方式如下:
状态共享
Node进程中不宜存放太多数据,因为它会加重垃圾回收的负担,进 而影响性能。同时,Node也不允许在多个进程之间共享数据。但在实际的业务中,往往需要共享 一些数据,譬如配置数据,这在多个进程中应当是一致的。为此,在不允许共享数据的情况下, 我们需要一种方案和机制来实现数据在多个进程之间的共享。
-
第三方数据存储
解决数据共享最直接、简单的方式就是通过第三方来进行数据存储,比如将数据存放到数据 库、磁盘文件、缓存服务(如Redis)中,所有工作进程启动时将其读取进内存中。但这种方式 存在的问题是如果数据发生改变,还需要一种机制通知到各个子进程,使得它们的内部状态也得 到更新。
实现状态同步的机制有两种,一种是各个子进程去向第三方进行定时轮询,示意图如图所示。
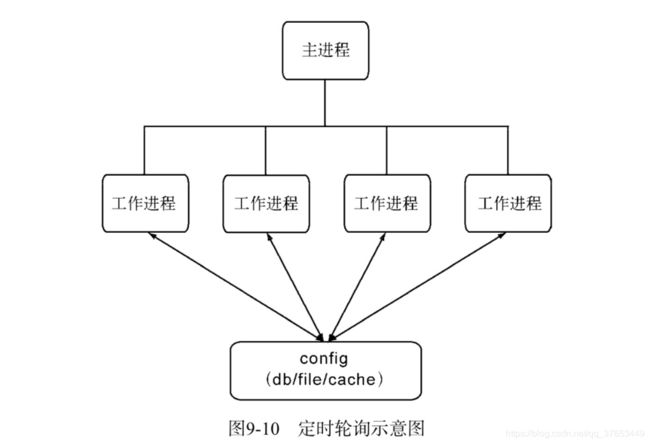
实现状态同步的机制有两种:一种是各个子进程去向第三方进行定时轮询
定时轮询带来的问题是轮询时间不能过密,如果子进程过多,会形成并发处理,如果数据没 有发生改变,这些轮询会没有意义,白白增加查询状态的开销。如果轮询时间过长,数据发生改 变时,不能及时更新到子进程中,会有一定的延迟。
2. 主动通知
一种改进的方式是当数据发生更新时,主动通知子进程。当然,即使是主动通知,也需要一 种机制来及时获取数据的改变。这个过程仍然不能脱离轮询,但我们可以减少轮询的进程数量, 我们将这种用来发送通知和查询状态是否更改的进程叫做通知进程。为了不混合业务逻辑,可以 将这个进程设计为只进行轮询和通知,不处理任何业务逻辑,示意图如图所示
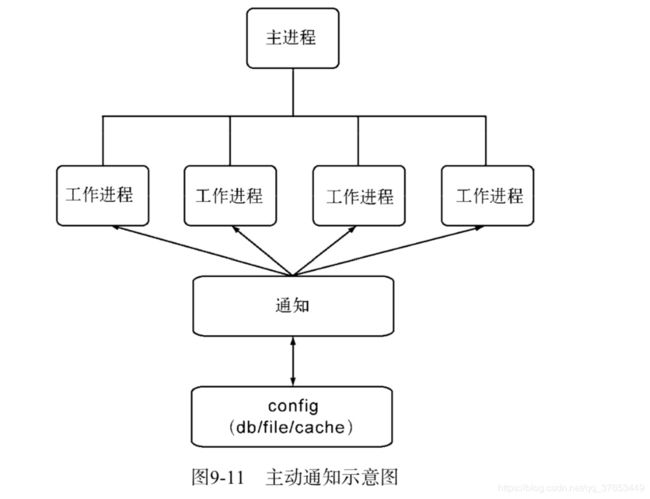
这种推送机制如果按进程间信号传递,在跨多台服务器时会无效,是故可以考虑采用TCP或 UDP的方案。进程在启动时从通知服务处除了读取第一次数据外,还将进程信息注册到通知服务 处。一旦通过轮询发现有数据更新后,根据注册信息,将更新后的数据发送给工作进程。由于不涉及太多进程去向同一地方进行状态查询,状态响应处的压力不至于太过巨大,单一的通知服务 轮询带来的压力并不大,所以可以将轮询时间调整得较短,一旦发现更新,就能实时地推送到各个子进程中。
Cluster 模块
v0.8时直接引入了cluster模块,用以解决多核CPU的利用率问题,同时也提供了较完 善的API,用以处理进程的健壮性问题
对于开头提到的创建Node进程集群,cluster实现起来也是很轻松的事情,如下所示
// 事实上cluster模块就是child_process和net模块的组合应用
const cluster = require("cluster");
const cpus = require('os').cpus();
cluster.setupMaster({
exec: "worker.js"
})
for(var i = 0; i < cpus.length; i++) {
cluster.fork();
}
Cluster 事件
对于健壮性处理,cluster模块也暴露了相当多的事件。
fork:复制一个工作进程后触发该事件。
online:复制好一个工作进程后,工作进程主动发送一条online消息给主进程,主进程收到消息后,触发该事件。
listening:工作进程中调用listen()(共享了服务器端Socket)后,发送一条listening消息给主进程,主进程收到消息后,触发该事件。
disconnect:主进程和工作进程之间IPC通道断开后会触发该事件。
exit:有工作进程退出时触发该事件。
setup:cluster.setupMaster()执行后触发该事件。
这些事件大多跟child_process模块的事件相关,在进程间消息传递的基础上完成的封装。 这些事件对于增强应用的健壮性已经足够了
尽管通过child_process模块可以大幅提升Node的稳定性,但是一旦主进程出现问题,所 有子进程将会失去管理。在Node的进程管理之外,还需要用监听进程数量或监听日志的方式确 保整个系统的稳定性,即使主进程出错退出,也能及时得到监控警报,使得开发者可以及时处 理故障
欢迎访问我的博客