shell 脚本学习笔记
( 参考自 linux shell 脚本攻略)
基础
- 赋值等号之间不用空格
- 带空格的等号是判断是否相等
- 数值计算
no=100
echo "ibase=2;obase=10;$no" | bc
a=1;b=2
let c=a+b
c=$[ a + b ]
c=$(( a + b ))4.重定向
标准输入0,标准输出1,标准错误2
4.1 stdin 1
先清空再写入, > 等同于 1>
echo "This is a sample text 1" > temp.txt追加, >> 等同于 1>>
echo "This is a sample text 1" >> temp.txt4.2 stderr 0 stdout 2
当一个命令发生错误并退回时,会返回一个非零的退出状态;
而成功完成后,他会返回数字0.
退出状态可以从特殊变量$?中获得
将错误重定向到out.txt
ls + 2> out.txt单独分别重定向
cmd 2>stderr.txt 1>stdout.txtstderr 转换成 stdout, stderr和stdout都被定向到了同一个文件中
cmd 2>&1 output.txt
cmd &1 output.txt
执行时丢弃错误
cat a* 2> /dev/null善用tee
追加(-a)写入stdin文件并stdout stderr
cat a* | tee -a out.txt | cat -n 5 重定向2
数组
数组有两种:1. 普通数组,只能用数字作为索引。 2. 关联数组,可以使用字符串
#普通数组
[clz@localhost ~]$ array_var=(1,2,3,4,5,6)
[clz@localhost ~]$ array_var[0]='test1'
[clz@localhost ~]$ echo ${array_var[0]}
test1
[clz@localhost ~]$ echo ${array_var[@]}
test1
# 关联数组
[clz@localhost ~]$ declare -A ass_array
[clz@localhost ~]$ ass_array=([index1]='val1' [index]='val2')
## 值
[clz@localhost ~]$ echo ${ass_array[@]}
val1 val2
## 索引
[clz@localhost ~]$ echo ${!ass_array[@]}
index1 index
别名
alias命令只是暂时起作用,一旦关闭当前终端便失效, 可以将它放入bashrc中
echo 'alias "cp $@ ~/backup; rm $@"' >> ~/.bashrc\conmand # 转义,使得alias失效处理日期和延时
# 日期
[clz@localhost ~]$ date
Wed Nov 11 19:02:31 PST 2015
#原子钟
[clz@localhost ~]$ date +%s
1447297366
# 提取信息
[clz@localhost ~]$ date --date "Jan 20 2001" +%A
Saturday
#输出想要的格式
[clz@localhost ~]$ date "+%d %B %Y"
11 November 2015
日期格式表
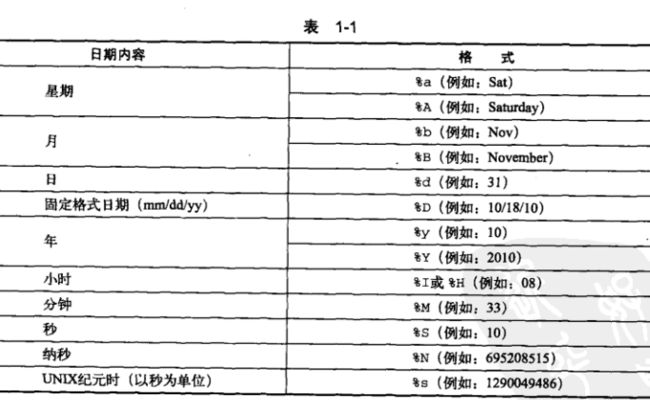
## 延时
sleep
#! /bin/bash
#Filename: sleep.sh
echo -n Count:
tput sc # 记录光标位置
Count=0;
while true;
do
if [[ $Count -lt 40 ]];
then let Count++;
sleep 1;
tput rc # 恢复光标位置
tput ed # 清除从当前光标位置到行尾之间的所有内用
echo -n $Count;
else exit 0;
fi
done调试脚本

#!/bin/bash
#FileName:debug.sh
for i in {1..6}
do
set -x
echo $i
set +x
done
echo "Acript executed"
# result
[clz@localhost ~]$ ./debug.sh
+ echo 1
1
+ set +x
+ echo 2
2
+ set +x
+ echo 3
3
+ set +x
+ echo 4
4
+ set +x
+ echo 5
5
+ set +x
+ echo 6
6
+ set +x# 快速设置调试
#!/bin/bashc-xv 函数
#!/bin/bash
#Filename:func.sh
function fname()
{
echo $1, $2;
echo "$@";
echo "$*";
return 0;
}
fname 1 2读取命令输出
cmd_output=$(ls | cat -n)
#或者反引用
cmd_output=`ls | cat -n`
echo $cmd_output利用shell生车一个独立的进程
pwd;
(cd /bin; ls);
pwd;通过引用子shell的凡是保留空格和换行符
out="$(cat text.txt)"
out="$(cat text.txt)"read
read -n 2 var
21
echo $var
21
分隔符数据读取
line="root:x:0:0:root:/root:bin/bash";
oldIFS=$IFS;
IFS=":";
count=0;
for item in $line;
do
[ $count -eq 0 ] && user=$item;
[ $count -eq 6 ] && shell=$item;
let count++
done;
IFS=$oldIFS;
echo $user\'s shell is $shell;
循环

比较与测试
if
if condition;
then
commands;
elif condition;
then
commands
else
commands
fi
# ifelse 嵌套
[ condition ] && action; #if true, action
[ condition ] || action; # if false, action算数比较
[ $var -ne 0 -a $var2 -gt 2 ] # 逻辑与
[ #vat -ne 0 -o $var2 -gt 2 ] # 逻辑或
文件系统相关测试
[ -f $file_var ] # 包含文件名返回真
[ -x $var ] # 如果可执行返回真
#!/bin/bash
#Filename:fileexists.sh
fpath="/etc/passwd"
if [ -e $fpath ]
then
echo File exists
else
echo Dose not exist;
fi字符串比较
使用字符串比较使用双中括号,因为有时候单个的中括号会产生错误、

=号前各有一个空格才是比较``常用命令
cat
-s 压缩空白行
-T 制表符标记橙^|
-n 行号find
根据文件正则表达式进行检索
find /home -name '8.txt' -print
find . \( -name "*.txt" -o -name "*.pdf" \) -print
# path 匹配文件和文件名
find /home/users -path "*slynux*" -print
# -regex 正则表达式匹配
find . iregex ".*\(\.py\|\.sh\)$"
# 匹配不以txt的文件名
find . ! -name "*.txt" -print一些例子:
find . -regex ".*[winprice|processed|hashed]_.*_201511.*" -type f -exec rm -f {} \;基于目录深度的搜索
find . -maxdepth 1 -type f -print注意顺序, 先深度后type效率高

根据时间进行检索

find . -maxdepth 1 -atime +7 -print
基于文件大小的搜索
find . -type f -size +2k # gt 2k
find . -type f -size 2k # qe 2kdel 匹配的文件
# 找出没有执行权限的文件
find . -type f -name "*.php" ! -perm 644 -print找用户的文件
find . -typr f -user clz -print结合find命令执行命令动作
#找到clz的文件并cat输入到文件中
find . -type f -user clz -exec cat {} \; >../all_clz_dils.txt
find . -type f -name "*.sh" -exec printf "Text file: %s\n" {} \;find 跳过指定目录

xargs , stdin格式化输出等

基础
-d 分割
-n 划分多行cat args.txt | xargs -n 2 ./cecho.sh
arg1 arg2#
arg3#选项-I
cat args.txt | xargs -I {} ./cecho.sh -p {} -l
-p arg1 -l #
-p arg2 -l #
-p arg3 -l #结合find使用xargs
cat files.txt | ( while read arg; do cat $arg; done )
cat files.txt | xargs -I {} cat {}tr 转换
将制表符转换为空格
cat text | tr '\t' ' '删除特定的字符
echo "Hello 123 world 456" | tr -d '0-9'
Hello world补集
删除除了数字外的字符
echo hello 1 char 2 next 4 | tr -d -c '0-9 \n'
1 2 4压缩字符
echo 'GNU is not UNNNNIX' | tr -s ' N'
GNU is not UNIX- 实现相加

校验和与核实
# 生成MD5
[clz@localhost shell_learn]$ md5sum *.sh
55dfc48e7248ec2d88abe82b155a1725 cecho.sh
97e3c6038257978fb9bde47a97104beb debug.sh
335e04f8d5cdda182304840c35e30ee1 digui.sh
342e36c8d6203dda904f34a76d09e95d fileexists.sh
2b1cad931b74465c3c29628f8e8270e4 func.sh
62ab033ac0ab10bae684e006a570be35 IFSread.sh
9b6da33a9d92bcc27ad436f8bcfef7e1 sleep.sh
bd984f8245d30781ea00ee8e6984b8b1 success_test.sh
[clz@localhost shell_learn]$ md5sum *.sh > file_sum.md5
# 校验
[clz@localhost shell_learn]$ md5sum -c file_sum.md5
cecho.sh: OK
debug.sh: OK
digui.sh: OK
fileexists.sh: OK
func.sh: OK
IFSread.sh: OK
sleep.sh: OK
success_test.sh: OK排序,单一与重复
sort
-n 数字 -r 逆序 -M 月份
-C 是否已经排序
-nC 是否按照数字排序找出已排序文件中不重复的行
cat files | uniq > uniq_lines.txt合并两个排过序的文件
sort -m sorted1 sorted2按字段排序
[clz@localhost shell_learn]$ cat data.txt
1 mac 2000
3 winxp 4000
2 bsd 1000
# 按照第一列逆序排序
[clz@localhost shell_learn]$ sort -nrk 1 data.txt
3 winxp 4000
2 bsd 1000
1 mac 2000
# 按照第二列排序
[clz@localhost shell_learn]$ sort -k 2 data.txt
2 bsd 1000
1 mac 2000
3 winxp 4000uniq
-u 只显示未出现重复得到行
-c 统计各行在文件中出现的次数
-d 重复行
-s 调过前n个字符
-w 指定用于比较的最大字符数
[clz@localhost shell_learn]$ sort data.txt
d:04:linux
u:01:bash
u:01:gnu
u:01:hack
[clz@localhost shell_learn]$ sort -r data.txt | uniq -s 2 -w 2
u:01:hack
d:04:linux在用xargs命令输入的时候,最好为输出的各行添加一个0值字节终止符。
[clz@localhost shell_learn]$ uniq -z data.txt | xargs -0
u:01:gnu
d:04:linux
u:01:bash
u:01:hack
[clz@localhost shell_learn]$ uniq -z data.txt | xargs
xargs: WARNING: a NUL character occurred in the input. It cannot be passed through in the argument list. Did you mean to use the --null option?
u:01:gnu d:04:linux u:01:bash u:01:hack
文件分割
-b 文本块大小分割
-d 新文件用数字命名
-a 文件名长度
-l 根据行数分割split -b 10k data.file -d -a 4
根据扩展名切分文件名
%操作符 取出文件名, 删除%右侧的(最短)通配符;
%% 最长匹配删除
[clz@localhost shell_learn]$ file_jpg="sample.jpg"
[clz@localhost shell_learn]$ name=${file_jpg%.*}
[clz@localhost shell_learn]$ echo File name is : $name
File name is : sample取出后缀
[clz@localhost shell_learn]$ extension=${file_jpg#*.}
[clz@localhost shell_learn]$ echo Extension is: $extension
Extension is: jpg‘#’删除前面的
‘##’删除最长的
rename
该脚本将当前目录下文件重命名
#!/bin/bash
#Filename:rename.sh
#rename file
#set -x
count=1;
for img in *.[tT][xX][tT]
do
new=image-$count.${img##*.}
mv "$img" "$new" 2> /dev/null
if [ $? -eq 0 ]
then
echo "rename $img to $new"
let count++
else
echo "error"
fi
done