MFCC 过程理解
---最近看信号处理相关的知识,会随时补充或者更正之前写的不对的地方,或者是补充一些自己的理解----
ref: https://www.zhihu.com/question/27268668 等。
语音识别中常用的特征提取方法: 声学特征有线性预测编码(Linear Predictive Coding,LPC),梅尔频率倒谱系数(Mel-frequency Cepstrum Coefficients,MFCC),梅尔标度滤波器组(Mel-scale Filter Bank,FBank), 其中PLP MFCC 是倒谱特征。
梅尔频率倒谱系数:一定程度上模拟了人耳对语音的处理特点
首先是基本步骤:
参考:http://lufo.me/2015/06/ASR1/
(1)预加重(Preemphasizing):在语音信号中,由于声门气流波的影响,每倍频衰减是12dB, 而唇腔辐射是每倍频增加6dB, 所以总的效果是每倍频衰减6dB, 为了弥补这6dB我们采取预加重。由于每倍频会衰减6dB, 高频部分的能量一般比较低, 提高高频部分的能量使得高频能量和低频能量大致相等, 尽量弥补每倍频损失的6dB, 预加重的公式: Y[n]=s[n]-0.95*s[n-1].
(2)分帧: 因为语音信号是快速变化的,而 fourier tansform 适用于分析平稳的信号,利用语音的短时平稳性(在每一时刻所有阶差分都是一样的),在语音识别中一般去帧长为20ms~50ms(一般取25ms),这样一帧内既有足够多的周期,又不会变化很剧烈, 一般帧移取10ms, 也就是说帧与帧之间有15ms是重复的,(s - 15)/ 10 = 帧数, 其中 s 为一段语音的毫秒数.
(3)加窗: 因为之后要做FFT,而一个信号的FFT与这个信号的周期信号的FFT相同,所以如果这个信号边缘不平滑,那么这个信号的周期信号在现实中是很少遇到的,这样就没有意义了,所以每帧信号通常要与一个平滑的窗函数相乘,让帧两端平滑的衰减到零, 这样可以降低傅立叶变换后旁瓣的强度(主瓣是变换为频谱之后振幅最大的那个波峰部分,而周围的小的波峰部分叫旁瓣),取得更高质量的频谱, 通常选用的窗函数: Hamming window,Hanning window。好的窗函数也能减弱频谱泄漏。这里也解释了为什么要帧移是10ms, 有15ms的overlap, 由于帧与帧连接处的信号因为加窗而弱化,如果没有overlap,这部分信息就丢失了. (补充一点,这里其实跟context-frames并不冲突,其实(t-5, t, t+5)11帧数据的话,去掉重叠部分能表达的时长是(10*11+15)=125ms, 通常对于一个音节来说足够了,The average syllable duration is 117 ms and the aver- age inter-syllable interval is 234 ms [1].)
[1]: P. Linhart, A. Petrusek, and R. Fuchs, “Being angry, singing fast? signalling of aggressive motivation by syllable rate in a songbird with slow song.” Behavioural Processes, vol. 100, no. 6, pp. 139–145, 2013.
(4)然后是补零(zero-padding): 因为做FFT(快速傅里叶变化)要求信号长度为2^n,所以如果采样率为16000Hz,16000*0.025=400,要补0使长度为512。
(5)FFT: 将时域谱转化为频率谱,纵坐标变为能量。fourier transform逐帧进行的,为的是取得每一帧的频谱。一般只保留幅度谱,丢弃相位谱
这个地方是相位谱是相对原点经过的的路程,由于是逐帧取,每帧时间固定,所以不需要保留相位谱(频域的相位就是时域的时间)。
(6)然后要转化到梅尔刻度(听觉音高单位),梅尔刻度是一种基于人耳对等距的音高变化的感官判断而定的非线性m刻度。人耳对低频声音的变化比高频的变化更敏感,所以要做一个转化, 具体做法为让原始信号通过一系列滤波器,实验中取40个,这40个滤波器的横轴在单位为梅尔时是均匀的。
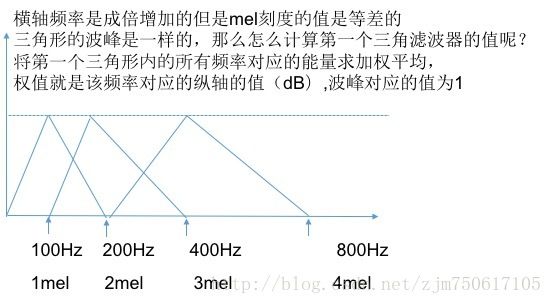
1) 傅里叶变换得到的序列很长(一般为几百到几千个点),把它变换成每个三角形下的能量,可以减少数据量(一般取40个三角形);
2) 频谱有包络和精细结构,分别对应音色与音高。对于语音识别来讲,音色是主要的有用信息,音高一般没有用。在每个三角形内积分,就可以消除精细结构,只保留音色的信息。当然,对于有声调的语言来说,音高也是有用的,所以在MFCC特征之外,还会使用其它特征刻画音高。
3) 三角形是低频密、高频疏的,这可以模仿人耳在低频处分辨率高的特性。
这一步就是取上一步结果的对数。由于高频部分的能量比较低,低频部分的能量比较高,可以放大低能量处的能量差异;更深层次地,这是在模仿倒谱(cepstrum)的计算步骤。
NOTE:到这里为止,40个三角滤波器的结果就是Fbank的特征了,所以Fbank不是倒谱特征,这里如果取26个三角滤波器的话,那么
8. Take the discrete cosine transform of the list of mel log powers, as if it were a signal.
求倒谱时这一步仍然用的是傅里叶变换。计算MFCC时使用的离散余弦变换(discrete cosine transform,DCT)是傅里叶变换的一个变种,好处是结果是实数,没有虚部。DCT还有一个特点是,对于一般的语音信号,这一步的结果的前几个系数特别大,后面的系数比较小,可以忽略。上面说了一般取40个三角形,所以DCT的结果也是40个点;实际中,一般仅保留前13~20个,这就进一步压缩了数据。得到梅尔倒谱。
上面整个过程的结果,就把一帧语音信号用一个13~20维向量表示