ORB-SLAM3论文解读
ORB-SLAM3论文解读
- ORB-SLAM3论文解读
- 主要的创新点
- 数据关联模型
- 系统整体
- Atlas地图集
- 跟踪线程
- 局部建图线程
- 回环和地图合并线程
- 相机模型
- 相机模型带来的重定位问题
- 相机模型带来的双目问题
- 视觉惯性SLAM部分
- IMU初始化
- 纯视觉最大后验估计
- 纯惯性最大后验估计
- 视觉惯性联合最大后验估计
- 跟踪和建图
- 地图合并和回环检测
- 场景识别
- 纯视觉地图合并
- 地图缝合
- 地图优化
- 视觉惯性地图合并
- 实验和结论
ORB-SLAM3论文解读
ORB-SLAM1和2的作者Juan已经毕业了,其工作仍然由同一课题组的Carlos继续完成并撰写论文和代码,这次论文同样对应着开源代码,youtube演示效果惊人,很多场景下无需大量修改即可直接使用,可谓是工作党的KPI,学生党的SCI。
废话少说,直入主题。ORB-SLAM3与前两次作品相比,引入和视觉惯性和多地图模式的SLAM。其算法支持的传感器也有单目、双目、RGBD相机等。在相机的成像模型中 ,采用了针孔、鱼眼相机模型(见摘要的第一段)。
代码传送门:链接: https://github.com/UZ-SLAMLab/ORB_SLAM3.
论文传送门:链接: https://arxiv.org/pdf/2007.11898.pdf.
主要的创新点
大佬的自吹自擂部分中也提到,他们的主要创新点有两点:
- “完全”基于最大后验估计MAP的VI-SLAM ,无论在初始化阶段还是运行阶段,都采用了MAP进行状态估计,因此ORB-SLAM3在室内外、大小场景中鲁棒性很好,且精确度是其他方法的2~5倍;如文中所讲,本文的IMU和视觉的组合系统是extemely robust的。
- 多地图系统,当定位丢失即lost时,ORB-SLAM3会自动建立一个新的小地图,并在revisit的时候进行地图的seamlessly merge,因此,这一算法能够使用不仅仅几帧之前的信息,而是运用了全局的信息,能够在bundle adjustmen中利用视差较大的帧来增加BA求解的准确性(因为当视察较小时,求解不准确,且优化容易进入局部极值)。这种方法里对同一特征的观测可能在时间上的间隔较大,因为我们对其上一次的观测甚至可能出现在之前一张小地图中(中间过程里lost了至少一次);
数据关联模型
- short-term,在短程模式下,路标点一旦退出我们的视野,我们将这个路标点丢弃,其在优化时计算效率高,但存在累计误差,即使重新回到同一地点,也无法实现重定位或者回环检测,位姿图无法构成闭环。
- mid-term,在中程模式下,和短程模式类似,累计误差只有在重新回到地图中已知区域才有可能实现重定位,建立一个封闭的环状位姿图以消除累计误差。这与大多数SLAM系统中的方法类似。这一方法能够保证局部定位的准确性。
- long-term,长期模型中,采用place recognition的方式,例如Dbow词袋库的回环检测与重定位,无视累计误差和跟踪丢失,直接将当前位姿和之前一记录位姿对齐。并通过图优化的方式消除(平摊)累计误差。这一方法能够保证大环境重定位的稳定性。在运用词袋库的回环检测模型中,需要被检测帧具有时间一致性,即需要连续三帧均能出发词袋库召回匹配。在此之后,还需要检查是否具有几何一致性,因此,召回的准确性得到了较大提升,然而其召回率却难以得到保证,这种方法的计算过于缓慢,难以将之前建立的小地图充分应用起来。因此ORB-SLAM3先进行几何一致性的检测,随后再对局部一致性(即连续三个存在共视的帧的匹配性)进行检测。其中,时间一致性将连续三个关键帧进行比较,而此处局部一致性将连续三个共视关键帧进行了检查。由于其存在共视,关键点的匹配会更多,所以其准确性和召回率得到了提升,而计算量会少许增大。
系统整体
这部分就直接按照论文中的部分进行依次解读 (fan)(yi)。

Atlas地图集
整个ORB3最牛逼的地方就在这里了,最早在IROS2019的一篇文章,即参考文献[9]中提到。在ORB3中,Atlas地图集由一系列不连续的小地图构成,并能够无缝连接,实现重定位、回环检测、地点识别等功能。当每一个新的视觉帧进入流程,跟踪线程立即追踪并定位新一帧的位姿。地图集本身也随着时间逐步优化且会将新的视觉帧经过挑选作为关键帧。在Atlas中,DBoW2被用于重定位、回环检测、地图合并。地图的状态也分为active和non-active两个状态,在跟踪线程的介绍里将会详细介绍这一机制。
跟踪线程
跟踪线程被用来根据当前的active地图,实时地跟踪最新一帧的位置,利用最小化重投影误差的方式实现位姿的最大后验估计MAP。决定新一帧是否作为关键帧加入地图也是在这个线程中完成的。跟踪线程接受IMU、Frame输入,IMU 被预积分处理,而Frame被提取ORB特征,整体跟踪流程中规中矩,没什么值得一提的地方。
当定位跟踪失败时:首先会在所有的Atlas地图集中搜索当前位置的匹配,如果成功,则将当前的地图设置为non-active,而将在Atlas搜索到的地图设置为active,并继续在active的地图上进行局部跟踪。如果在全图搜索失败,则在一定时间后,当前的active地图会强行被设置为non-active,新的小地图将被构建,并设置为active。这样,就的地图的正确性不会被局部定位的失败影响,新旧地图之间的位姿变换关系不确定性也有希望被之后的共视减小或者消除。
局部建图线程
局部建图线程中规中矩,只有active的地图被添加关键帧,在添加关键帧的时候,重复的关键点被移除。VI-Bundle Adjustment在当前被插入帧前后窗口内被用来提升地图的质量。但是,在Local mapping框图中的后三项,ORB3加入了一些改进,用了他们的novel MAP,后续会介绍。
回环和地图合并线程
当每一个关键帧被插入,地点识别都被启动,这一关键帧被和整个Atlas地图集关键帧进行比较,如果检测到两关键帧是同一地点,分为两种情况:若被召回帧是当前的active地图中的一部分,则需要进行loop correction回环矫正,在回环矫正之后,Full BA在另一个线程中被悄悄进行,全局位姿图得到优化,整体的地图一致性得到了提升;若被召回帧是属于一个non-active的map,两个地图则会被合并成一个地图并将大地图设置为当前的active地图。这一过程和跟踪并行,不会影响跟踪的实时性。
相机模型
相机模型带来的重定位问题
相机模型这块,ORB3将系统中所有与相机模型相关的部分(投影和反投影公式以及其雅可比)提取了出来,让相机模型成为了一个独立的模块儿,以便随时替换其他的相机模型。在重定位中,由于需要使用PnP(Perspective n points)算法,所以需要一个标定好的针孔模型,因此,其他相机模型不再适用,在此我们选择MLPnP(Maximum Likelihood PnP)来作为求解算法。这种算法直接应用光线投影作为输入,只需要使用者提供一个将像素反投影为光束的unprojection公式以及相应像素点的坐标就可以求解相机的位姿。
相机模型带来的双目问题
在针孔相机双目视觉中,在寻找特征点匹配时,可以直接在另一个相机的同一行像素上进行搜索,实现快速的匹配,但这一加速技巧在鱼眼相机或者两个不同的针孔相机上难以实现。因此我们将一个双目相机看作是两个具有固定位姿变化SE3的单目相机,且两个相机帧之间存在较大的共视区域。两个单目被分别加入BA优化。为了利用双目的优势,如果两个相机之间存在共视区域,这一区域的特征点可以在第一次被看见的时候被三角化,且尺度的不确定性被双目SE3的尺度信息所消除。在没有共视的区域,特征点依旧按照多视图几何的方式进行三角化。
视觉惯性SLAM部分
ORB-SLAM-VI将ORB-SLAM改装成VI-SLAM。但这一算法仍有其局限性,虽然能够实现地图的复用,但其只能用针孔相机且初始化特慢,在此一一叙述。关于预积分和视觉重投影误差的部分我就不再多说了。分别将两个残差的信息矩阵加权马氏距离进行求和最小化即是最终的损失函数。在优化时,调整路标点的三维坐标以及机器人状态(R,p,v,q,b)使目标损失函数最小。如下:
min S ‾ k , X ( ∑ i = 1 k ∥ r I i − 1 , i ∥ Σ I i , i + 1 2 2 + ∑ j = 0 l − 1 ∑ i ∈ K j ρ Hub ( ∥ r i j ∥ Σ i j ) ) \min _{\overline{\mathcal{S}}_{k}, \mathcal{X}}\left(\sum_{i=1}^{k}\left\|\mathbf{r}_{\mathcal{I}_{i-1, i}}\right\|_{\Sigma_{\mathcal{I}_{i, i+1}}^{2}}^{2}+\sum_{j=0}^{l-1} \sum_{i \in \mathcal{K}^{j}} \rho_{\text {Hub }}\left(\left\|\mathbf{r}_{i j}\right\|_{\Sigma_{i j}}\right)\right) Sk,Xmin(i=1∑k∥∥rIi−1,i∥∥ΣIi,i+122+j=0∑l−1i∈Kj∑ρHub (∥rij∥Σij))
IMU初始化
ORB3中的初始化主要在accuracy和efficiency上进行了改进,以获得一个准确的IMU状态初始值。主要有三点改进的insight:1.纯视觉问题可以单独拿出来解决。2.尺度应该作为一个单独的优化变量而不是作为一个隐含变量存在于逆深度、相机位移等包含尺度的量中,这样的优化具有更快的收敛性。3.在初始化的时候应该考虑传感器uncertainty,否则会带来较大的误差。
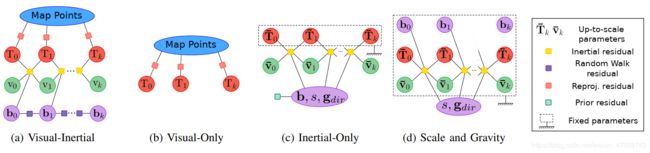
纯视觉最大后验估计
在这一过程中,首先以4Hz的频率插入关键帧,运行2s纯视觉mapping,这时将会有大约10个相机位姿和几百个特征点,对这一系列变量做一个BA,如图2b所示,获得了一条轨迹。
纯惯性最大后验估计
在这一过程中,我们确定需要在IMU信息优化阶段需要估计的变量有:
Y k = { s , R w g , b , v ‾ 0 : k } \mathcal{Y}_{k}=\left\{s, \mathbf{R}_{\mathrm{w} g}, \mathbf{b}, \overline{\mathbf{v}}_{0: k}\right\} Yk={s,Rwg,b,v0:k}
其中s是scale,Rwg是重力旋转方向,b是bias,v顾名思义。在此我们整一个最大后验估计:
p ( Y k ∣ I 0 : k ) ∝ p ( I 0 : k ∣ Y k ) p ( Y k ) p\left(\mathcal{Y}_{k} \mid \mathcal{I}_{0: k}\right) \propto p\left(\mathcal{I}_{0: k} \mid \mathcal{Y}_{k}\right) p\left(\mathcal{Y}_{k}\right) p(Yk∣I0:k)∝p(I0:k∣Yk)p(Yk)
其中公式就是贝叶斯公式的去掉分母的版本,后验=似然*先验。其中花体的I就是IMU测量值,我们将公式搞进最大似然argmax有:
Y k ∗ = arg max Y k ( p ( Y k ) ∏ i = 1 k p ( I i − 1 , i ∣ s , g d i r , b , v ‾ i − 1 , v ‾ i ) ) \mathcal{Y}_{k}^{*}=\underset{\mathcal{Y}_{k}}{\arg \max }\left(p\left(\mathcal{Y}_{k}\right) \prod_{i=1}^{k} p\left(\mathcal{I}_{i-1, i} \mid s, \mathbf{g}_{d i r}, \mathbf{b}, \overline{\mathbf{v}}_{i-1}, \overline{\mathbf{v}}_{i}\right)\right) Yk∗=Ykargmax(p(Yk)i=1∏kp(Ii−1,i∣s,gdir,b,vi−1,vi))
然后假设IMU预积分值分布和参数的先验分布概率密度函数为高斯分布的密度函数,就可以对整个函数整个求对数并加负号,argmax变argmin:
Y k ∗ = arg min Y k ( ∥ r P ∥ Σ p 2 + ∑ i = 1 k ∥ r I i − 1 , i ∥ Σ I i − 1 , i 2 ) \mathcal{Y}_{k}^{*}=\underset{\mathcal{Y}_{k}}{\arg \min }\left(\left\|\mathbf{r}_{\mathbf{P}}\right\|_{\Sigma_{p}}^{2}+\sum_{i=1}^{k}\left\|\mathbf{r}_{\mathcal{I}_{i-1, i}}\right\|_{\Sigma_{\mathcal{I}_{i-1, i}}}^{2}\right) Yk∗=Ykargmin(∥rP∥Σp2+i=1∑k∥∥rIi−1,i∥∥ΣIi−1,i2)
rp就是先验,后面那个就是针对每一次IMU预积分的求和。这个y函数的最小值就是我们所需要估计的参数的最大后验估计。在优化上为了保证旋转矩阵还在流形上,我们整了指数变换来更新这一李群:
R w g n e w = R w g o l d Exp ( δ α g , δ β g , 0 ) \mathbf{R}_{\mathrm{wg}}^{\mathrm{new}}=\mathbf{R}_{\mathrm{wg}}^{\mathrm{old}} \operatorname{Exp}\left(\delta \alpha_{\mathrm{g}}, \delta \beta_{\mathrm{g}}, 0\right) Rwgnew=RwgoldExp(δαg,δβg,0)
为了让尺度更新的时候不至于搞出来负数,我们也用指数更新尺度:
s new = s old exp ( δ s ) s^{\text {new }}=s^{\text {old }} \exp (\delta s) snew =sold exp(δs)
这一下纯IMU部分就完全ok了。值得一提的是,先验选取中,IMU的bias设置为0,使之不会偏离0太远,且初始的协方差矩阵按照IMU的datasheet设定。当完成了IMU的MAP估计后,纯视觉的尺度被对齐,并且重力方向上也与Rwg旋转后的方向对齐,Bias值也得到了一个合理的估计。
视觉惯性联合最大后验估计
这就没啥好说的了,和其他VIO算法一样,做一个VIO的联合BA,如图2a所示。但bias是不变的。且IMU方面的先验是和纯惯性估计的先验是一样的。初始化在2s时,尺度误差已经收敛到5%以内,此时我们就称初始化完成了。但VI联合MAP优化是在延时5-15s之后才运行的,为的是保证初始化的效率。VI联合优化后,地图才被称为时mature的,scale的误差可以收敛到1%以内。
跟踪和建图
跟踪方面和ORB-SLAM2一样,没有什么特别的地方,实际上跟踪问题就是最新两帧的VI-BA优化问题,而t-1帧路标点是fix的。在建图时,需要在滑动窗口和共视图里做一个范围更大的BA,以获得更高的地图准确性,参与建图BA优化的帧由于计算量限制不能把所有帧加进来,而是仅仅包含窗口内的帧and与当前帧有共同观测的帧。有的时候,初始化并不理想,这时候我们把头100帧或者前75s的keyframe全部纳入初始化优化阶段,用于获得一个较好的重力旋转向量和尺度。实际上这个过程就是“初始化不好的时候就让他初始化久一点”,但这一过程中只优化图2d框框外的变量。当跟踪过程中小于15个可辨认特征点时,进入visually lost即视觉丢失状态。并采用应对策略:从IMU估计当前位姿,并扩大滑动窗口的长度,将IMU获得的位姿以及当前帧特征点投影到这个大一点的滑动窗口中去寻找匹配。如果这一过程5s后仍没有成功重定位,则开启新的小地图,并将新图切换为active状态。从而进入咱们的下一章节:
地图合并和回环检测
作者又说了,这块儿是他最牛逼的地方,牛逼之处主要有两块儿,第一点是我们前面所说的回环检测与地图合并机制,除此之外,他们用在共视图local window上的一致性检测,代替了时间上的一致性检测,理论上讲,graph上的距离范围内的一致性确实比单纯时间上的一致性要有道理地多,实验效果反正是又好又快:-)
场景识别
首先,我们用DBoW操作一番得到三个Ka的匹配候选帧Km,然后将Km、Km的n个最佳共视帧、所有这些帧看到的路标点放进local window里,通过词袋库的正向索引得到各个匹配点的2D匹配关系,从而建立匹配点的3D匹配关系。然后需要我们计算Km到Ka的一个相似变换Sim(3)若尺度不确定。计算这一变换时,我们采用Horn algorithm(霍恩法),同时还要做一个RANSAC操作:为得到候选变换,我们把每个匹配的点对重投影误差计算出来,当小于一定阈值,就给这个变换投一票,采用民主共和的方式选出最好的位姿变换T。
得到T后,由于前面是基于采样计算的位姿变换,没有用到全部的特征点匹配信息,我们需要用上所有信息refine一下这个位姿变换。我们在local window里找所有与这帧图像中特征点匹配的路标,并使用双向转移误差作为误差目标函数来优化这一位姿变换,还用一下Huber来增强一波稳定性。如果inlier的个数ok,我们再在更小的local window(减小前面的n)中开始第二次的引导匹配。为了验证这一结果,我们把后续进来的3帧都做一下检验:在Ka的active map中找两个共视帧,然后看这两帧与local windows的匹配点数目是否超过阈值。这一过程持续三帧成功或者连续两帧失败来作为验证成功失败的判断条件。最最最最后用IMU重力再验证一波pitch和roll才算最终通过考验,成为一个place recognition。
纯视觉地图合并
地图合并主要分为缝合和优化两部分
地图缝合
当我们发现了Ka和Km的匹配发生在不同小地图之间,就需要对他们进行缝合(wlding)操作。为此我们将Ka、Km两帧、Ka和Km所有共视帧、所有这些帧的特征点都放进缝合窗口(welding window)。在将地图Ma(最新的地图)里面的特征点放进窗口前,我们见所有特征点均通过Tma变换到Mm地图(被召回的地图)下。在地图缝合时,需要将两图中重复的特征点进行剔除:对Ma中的每个特征点都在Mm中寻找其匹配点,如果找到则把Ma中的该点去除,并将这次观测放入Mm中去。同时,共视图也应当进行更新。
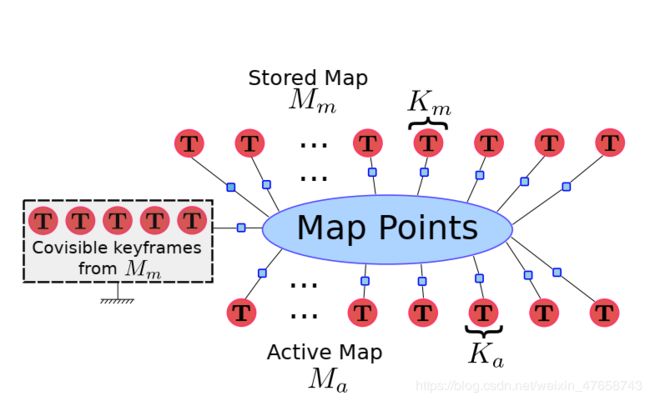
地图优化
缝合完之后需要进行优化,调整大的内部关系。优化分为两块:缝合优化和整体优化。首先我们进行缝合优化:我们将缝合窗口之外的部分进行固定,再在缝合窗口内部进行一个BA优化,到此我们的缝合后的地图就可以用于追踪新来的帧了。但是为了提升窗口内外的一致性,利用地图缝合减小整体的累计误差,我们需要进行整体的位姿图优化:在优化时,缝合窗口内被固定,窗口外采用essential graph进行优化。此时,回环矫正从缝合窗口传递向整个地图,缝合优化就完成了。
视觉惯性地图合并

和上一节讲的差不多,区别有两点:
- 如果active的地图是mature的,一切照旧;如果不mature,说明尺度信息暂时不可靠,在缝合时,需要用相似变换Sim(3)变换而不是SE(3)将Ma中的点对齐到Mm。
- 优化的变量和固定的变量如图所示,Easy。
实验和结论
效果非常好 :-)
结论非常硬 :-)
于2020/7/27 17:30