Python数据分析一条龙(菜鸟上手项目记录--爬虫阶段)
Python数据分析小项目
项目结构
需求分析
用网络爬虫去无讼网站爬取电信网络诈骗一审案例。爬取内容:
-
案例编号
-
案例详情URL
-
案例名称(Title)
-
被告人基本信息:姓名、出生日期、籍贯
-
法院判决结果:罚款数、判决年限
-
法院所在地区
建立一个回归模型,分析判决年限受什么因素的影响
项目阶段分析
在本次项目中,需要完成从数据源到回归分析的一系列过程,将步骤划分为如下阶段:
- 编写爬虫程序,从无讼案例网抓取相关数据
- 编写数据清洗程序,将抓取下来的原始数据进行清洗
- 编写数据处理程序,将原始数据转换为数字的形式
- 编写回归分析程序,通过sklearn模块完成回归模型的构建
1. 爬虫阶段
分析
访问https://www.itslaw.com/home,输入电信网络诈骗。访问结果如下:
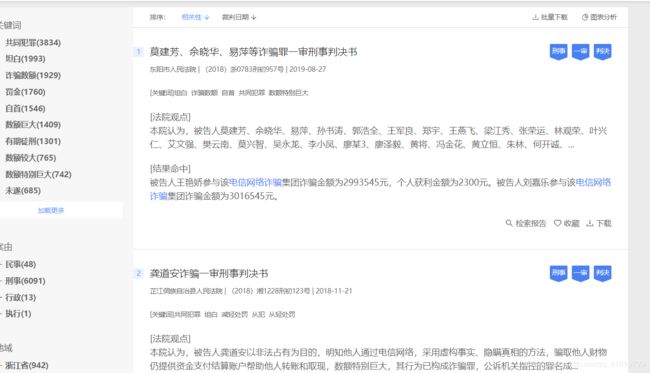
通过F12抓包,发现服务器向当前浏览器通过Ajax返回了一段Json数据,其中包含当前页面的所有信息 
查看路径为https://www.itslaw.com/api/judgements?_timer=1592998113495&sortType=1&conditions=searchWord%2B%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97%2B1%2B%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97&startIndex=0&countPerPage=20
尝试改变该url能否获取不同的信息:
https://www.itslaw.com/api/judgements?_timer=1592998113495&sortType=1&conditions=searchWord%2B电信网络诈骗%2B1%2B电信网络诈骗&startIndex=2&countPerPage=20

发现通过改变startIndex的值可以指定当前浏览的页数,即完成加载更多的功能
解析该json字符串发现了一些有用的信息: 
按照多次爬虫的经验,猜想这个id应该是访问该案件详情信息url的某个部分。所以接下来验证猜想。
进入详情页面来获取详细的信息。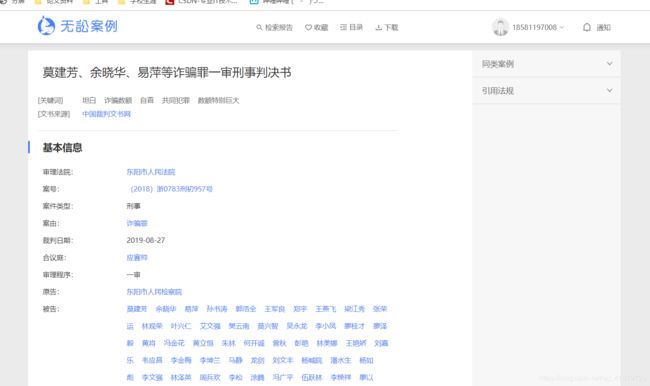
通过F12抓包,发现服务器向当前浏览器通过Ajax返回了一段Json数据 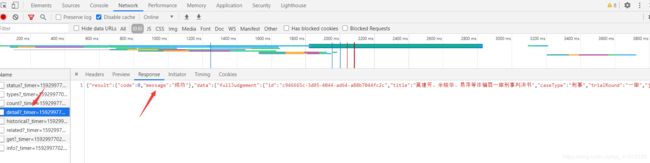
该json的url为https://www.itslaw.com/api/judgements/detail?_timer=1592997701254&judgementId=c946665c-3d05-4044-ad64-a88b7044fc2c
重新抓取一个新的案例的详情页面请求 
该json的url为https://www.itslaw.com/api/judgements/detail?_timer=1592997816911&judgementId=1e68789b-101d-458e-8116-73029c82c93f
发现该路径是由judgementId来区分的,再通过访问案例首页可以获取到的这个judgementId,所以可以总结我们的爬虫思路如下:
- 通过访问搜索结果页面,获取每个案例对应的
judgementId - 通过拼接url,完成对每个案例的详情页面爬取
- 通过改变startIndex来切换搜索结果页面。完成对多个页面多个案例的爬取
代码实现
import requests
from lxml import etree
import time
import re
import csv
import threading
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'referer': 'https://www.itslaw.com/search?initialization=%7B%22category%22%3A%22CASE%22%2C%22filterList%22%3A%5B%7B%22type%22%3A%22searchWord%22%2C%22id%22%3A%22%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97%22%2C%22searchType%22%3A1%2C%22label%22%3A%22%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97%22%2C%22category%22%3A%22%E6%90%9C%E7%B4%A2%E8%AF%8D%22%7D%5D%7D',
'cookie': 'home_sessionId=true; UM_distinctid=172ac09f5d0615-06776b04780c1f-f7d123e-144000-172ac09f5d186f; subSiteCode=bj; cookie_allowed=true; reborn-userToken=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJhdWQiOiIxODU4MTE5NzAwOCJ9.acHtpLjruIbYjdXgginyZziPzw5h3bF1ysf4WJ-v1Jc; CNZZDATA1278721950=1838275561-1592021007-https%253A%252F%252Fwww.baidu.com%252F%7C1592023319',
'origin': 'https://www.lagou.com',
}
count = 0
writable = True
def request_list_page():
url = "https://www.itslaw.com/api/judgements?_timer=1592026821471&sortType=1&conditions=searchWord%2B%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97%2B1%2B%E7%94%B5%E4%BF%A1%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97&startIndex={}&countPerPage=20"
save_title_csv()
for x in range(0, 120): # 120页数据
response = requests.get(url.format(x), headers=HEADERS)
# print(response.json()) # 如果返回的是json数据,这个方法会把这些json数据自动load成字典
result = response.json()
judgement_list = result['data']['searchResult']['judgements']
'''judgement_list是[{}]多个字典组成的列表'''
for judgement in judgement_list: # 获取每页的20个详情页面
judgement_id = judgement['id']
detail_url = 'https://www.itslaw.com/api/judgements/detail?_timer=1592031388718&judgementId={}'.format(
judgement_id)
parse_jugement_detail(detail_url)
def parse_jugement_detail(url):
global writable
detail_data = dict()
response = requests.get(url, headers=HEADERS)
try:
detail_dict = response.json()['data']['fullJudgement']
if not detail_dict['title'].__contains__('一审'):
return
detail_data['id'] = detail_dict['id']
detail_data['sourceUrl'] = detail_dict['sourceUrl']
detail_data['title'] = detail_dict['title']
detail_data['court'] = detail_dict['proponents'][0]['name']
case_info_list = detail_dict['paragraphs']
'''被告信息'''
opponent_info_dict = case_info_list[0]
opponents = ""
# opponents_list = opponent_info_dict['subParagraphs'][1]['text'] 应该是1-3-5等奇数列
for i in range(len(opponent_info_dict['subParagraphs'])):
if (i % 2 != 0):
opponent = opponent_info_dict['subParagraphs'][i]['text'][0]
opponents += "{}\t{}".format(opponent, "")
detail_data['opponent'] = opponents
'''裁判结果'''
judgementResults = ""
for case_info in case_info_list:
if case_info['typeText'] == "裁判结果":
writable = True
judgementResult_list = case_info['subParagraphs']
for index, judgementResult in enumerate(judgementResult_list):
ret = judgementResult['text'][0]
if (index == (len(judgementResult_list) - 1)):
judgementResults += ret
else:
judgementResults += "{}\t{}".format(ret, "")
detail_data['judgementResults'] = judgementResults
if judgementResults =="":
writable =False
if writable:
save_data_csv(detail_data)
except Exception as e:
print(e)
def save_title_csv():
data_title = ['id', 'sourceUrl', 'title', 'court',
'opponent', 'judgementResults']
with open('data.csv', 'a', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(f, data_title)
writer.writeheader()
def save_data_csv(data):
global count
with open('data.csv', 'a', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
writer.writerow([i for i in data.values()])
count += 1
print('=' * 20 + '第{}条csv写入成功'.format(count) + '=' * 20)
def main():
request_list_page()
if __name__ == '__main__':
main()
抓取到的原始数据如下:


由于opponent和judgementResults包含了多个被告的信息,所以需要通过数据清洗ETL将之变为我们希望的样子: ![]()