SPI总线协议关键概念进阶剖析(基于NXP1088A SPI控制器)
在学习资料满天飞的大环境下,知识变得非常零散,体系化的知识并不多,这就导致很多人每天都努力学习到感动自己,最终却收效甚微,甚至放弃学习。我的使命就是过滤掉大量的垃圾信息,将知识体系化,以短平快的方式直达问题本质,把大家从大海捞针的痛苦中解脱出来。
文章目录
- 1 配置和初始化
- 1.1 SCK相关配置
- 1.1.1波特率
- 1.1.2时钟模式(取决于时钟极性和相位)
- 1.1.3时钟是否持续输出
- 1.2 SDI/O相关配置
- 1.2.1侠义数据帧长度
- 1.2.2 MSB/LSB
- 1.3 CS相关配置
- 1.3.1片选是低有效还是高有效
- 1.3.2广义数据帧长度
- 1.3.3相邻两个广义数据帧间的时间间隙
- 1.3.4开始(结束)片选沿与时钟开始(结束)生效沿的时间间隙
- 1.2 数据传输
- 1.2.1 数据交换
- 1.2.2 数据写
- 1.2.3 数据读
1 配置和初始化
1.1 SCK相关配置
1.1.1波特率
为了完整性,将该概念列出来。但该概念比较简单,一般不容易出错,所以不展开了。
1.1.2时钟模式(取决于时钟极性和相位)
时钟极性(clock polar)指的是空闲情况下时钟是高电平还是低电平;时钟相位(clock phase)指的是在时钟的奇数跳变沿采样(偶数跳变沿数据改变)还是偶数跳变沿采样(奇数跳变沿数据改变)。两者组合后会有4种时钟模式(第2种模式比较常用):
Tips:注意在确定时钟相位时,起始位置是非常关键的。起始位置要从片选拉低的时刻开始算起,时钟第一次跳变产生的阶跃就是第一个时钟沿(1为奇数,所以这个沿为奇数沿),第二次跳变产生的阶跃是第二个时钟沿(2为偶数,所以这个沿为偶数沿),以此类推。
(1)空闲为高电平,奇数沿采样 : 输入引脚下降沿采样,输出引脚上升沿改变数据。
(2)空闲为高电平,偶数沿采样 : 输入引脚上升沿采样,输出引脚下降沿改变数据。
(3)空闲为低电平,奇数沿采样 : 输入引脚上升沿采样(实际是在上升沿靠后的一小段高电平内采样,如果是编写模拟SPI程序,可以在高电平的正中间采样),输出引脚下降沿改变数据(实际是在下降沿后的一小段低电平内改变输出引脚的电平,如果是编写模拟SPI程序,可以在底电平的正中间改变引脚电平)。
(4)空闲为低电平,偶数沿采样 : 输入引脚下降沿采样,输出引脚上升沿改变数据。
1.1.3时钟是否持续输出
根据时钟是否持续输出,可以将SPI时钟节拍分为连续模式和非连续模式。什么叫持续输出呢?时钟持续输出就是一个移位寄存器中的比特数据都拍出后,时钟并不停下来等待移位寄存器的装载,而是继续输出。
一般使用的都是时钟非连续模式。
Tips:这个概念很少有人提,一般使用的都是时钟非连续模式。了解有时钟连续模式即可,但不建议使用。
时钟持续输出模式,如果连续发送 “n*移位寄存器长度” ,由于等待移位寄存器中的数据发送完成后填充下一个Buffer的时候,时钟还在不停地拍,有时会导致一个bit数据对应两个节拍时钟(造成1bit数据被发送两次)。这种情况对于读写都很危险。因此,不建议使用时钟持续输出的模式。最稳定的模式就是移位寄存器数据全部移完之后就将时钟停拍等待。
1.2 SDI/O相关配置
1.2.1侠义数据帧长度
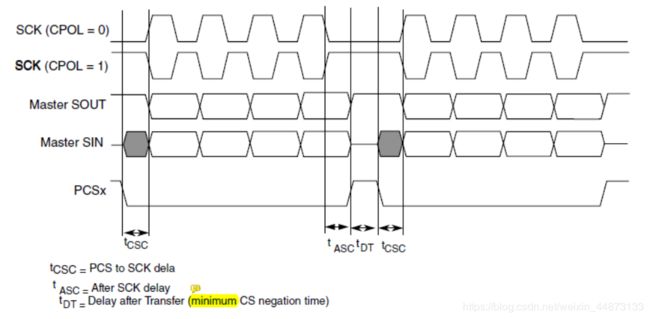
这里的数据帧长度是狭义上的数据帧长度,即移位寄存器的位宽,如下图(图1)所示。 从下图中可以看出侠义数据帧长度为4bit。怎么看的呢?老铁们打起精神来了,这里是一个比较关键的点~
首先说明,不是看片选引脚(图中的PCSx)拉低和拉高间的bit位数(这里恰巧也是4,不要被误导了)。而是看SCK引脚——SCK起拍和停拍之间的bit数,这就是移位寄存器的位宽。
Tips:注意下图的图示不是时钟连续模式,是非连续模式,即移位寄存器中的bit全部拍出后会停拍等待“填装子弹”。
图1:
1.2.2 MSB/LSB
Tips:该概念比较简单,只要稍加注意就可以了,不展开说了。
1.3 CS相关配置
1.3.1片选是低有效还是高有效
取决于硬件设计。
1.3.2广义数据帧长度
这里的数据帧长度指的是广义数据帧长度。广义数据帧长度是由CS引脚决定的,在一个CS有效周期内的所有侠义数据帧共同组成一个广义数据帧。广义数据帧的位数是狭义数据帧(寄存器位宽)的整数倍,如下图(图2)所示。
图2:
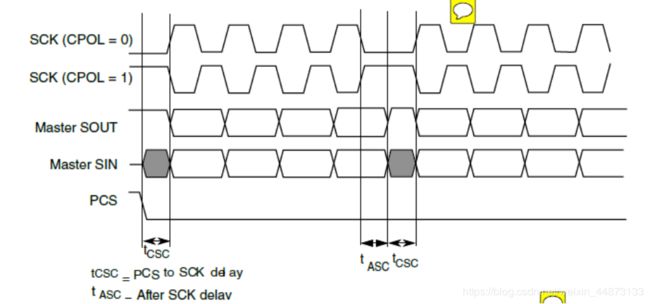
从图中可以看出,侠义数据帧的长度是4bit(判断方法见前文,当然你可以设置侠义数据帧长度为其他值,但一般都是4/8/16/32,具体要看数据手册)。第一个侠义数据帧发送完成后,CS引脚(图中的PCS)并没有拉高,而是依然保持有效,延了一段时间(tASC+tCSC)之后继续发送第二个侠义数据帧……以此类推,可以不停地发送下去,直到CS引脚拉高,假设这时已经发送了n个侠义数据帧了,那么广义数据帧的长度就是4*n bit。
Tips:(注意,这段不看也没有关系,和概念不相关,和1088A芯片中SPI控制器的寄存器设计相关,如果不使用这款芯片请直接略过这个tips)
某些很奇怪的控制器(如1088A中的SPI控制器)是通过配置相关寄存器位来控制CS的拉高拉低时机(通过设置一些时序参数,和帧结束标记)而不是直接设计一个bit位来供使用者直接控制CS引脚电平,这种设计非常不方便。
但大多数控制器还是很正常的(没这么变态),有直接的寄存器bit位供程序员使用,可以封装片选拉高和拉低的函数,从而可以在传输广义帧数据时方便地使用。
1.3.3相邻两个广义数据帧间的时间间隙
即一个片选结束沿和下一个片选开始沿之间的时间,对应图1中的tDT。
1.3.4开始(结束)片选沿与时钟开始(结束)生效沿的时间间隙
SPI时序要求片选有效时长包络时钟和数据,就像一张纸一样,其他时序都需要“画”在这张纸上,超出的部分全部无效。而这两个时间间隙就等同于页边距。“左页边距”对应图1中的tCSC;“右页边距”对应图1中的tASC。
1.2 数据传输
1.2.1 数据交换
SPI控制器的协议和硬件实现都决定了SPI通信是“硬性”全双工通信,即发送1bit的同时就接收了1bit。这取决于SPI通信的硬件实现原理。因此,读写是同时进行的,发送缓冲区的数据发送完后就可以去接收缓冲区读取接收到的数据了。在编写SPI驱动函数时可以先编写一个包含读写的数据交换函数(交换狭义数据帧)供其他函数调用。
例如:
// nomal spi transmit one frame function iterface
int spi_trans(u16 send16Data, u16 rev16Data);
// 1088A spi transmit frames function interface
int spi_trans(u8 u8Len, u16 *send16Data, u16 *rev16Data);上例中的侠义数据帧长度是16bit。需要说明的是常规的接口一般都定义为第一种,直接交互一个侠义帧即可。由于片选控制的设计(上文中提到过),1088A的接口比较特殊,可以忽略这种接口定义。
1.2.2 数据写
前面提到过了广义数据帧和狭义数据帧的概念,而且广义数据帧长度是狭义数据帧长度的整数倍(这里标识为n)。编写数据写函数时要提供一个CS周期内发送n个狭义数据帧的函数,编写时调用数据交换函数。
例如:
// spi write interface
int spi_write(u8 u8SpiId, u8 u8Len, u16 *pu16Data);1.2.3 数据读
如果是Master设备,在读之前肯定要发送读写标记位和地址给从器件,从器件才会返回数据(从器件开始返回数据时一般会忽略主设备发送的数据),因此,Master设备的读函数一般要包含写。和数据写函数一样,需要提供一个CS周期内接收n个狭义数据帧的功能,编写时调用数据交换函数。
还有一点需要注意,提供的读函数内部可以具备无效数据回收/丢弃功能,也可以交给调用它的函数来做(使用更灵活),无论怎样,一定要在函数说明中写清楚。
例如:
// spi read interface
int spi_read(u8 u8SpiId, u8 u8WLen, u16 *pu16WData, u8 u8RLen, u16 *pu16RData);就酱,麻麻再也不用担心我的SPI协议了~
<完>