基于飞桨复现CVPR 2020 GhostNet的全程解析

GhostNet是CVPR2020的一篇文章。论文链接:
https://arxiv.org/pdf/1911.11907.pdf

论文作者发现在传统的深度学习网络中存在着大量冗余,但是对模型的精度至关重要的特征图。这些特征图是由卷积变化得到,又输入到下一个卷积层进行运算,这个过程包含大量的网络参数,消耗了大量的计算资源。如下面的ResNet-50某层中的特征图,扳手之间的两个特征图存在很强的线性关系,通过计算成本较低的操作即可得到。

基于这点论文作者提出了一种轻量型移动端网络GhostNet,在其中引入Ghost模块,使用depthwise卷积的方法(计算成本较低的操作),而非常规卷积的方式,去生成这些冗余的特征图,从而减少了网络计算量。通过Ghost模块可以有效解决网络中冗余特征图对网络时耗增加和参数增多的影响,在ImageNet上的精度超过了MobileNetV3。
GhostNet核心思想是先将原有的特征图经过一个普通卷积(primary conv)得到一个Channel更小的新特征图,再通过一个depthwise卷积来补足其他相似的特征图。

图中(a)为普通卷积操作,假设输入维度c1,输出维度为c2,卷积大小为k,特征图的高和宽为h和w,公式如下:
网络参数量:
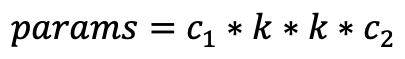
网络计算量:
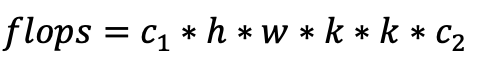
图中(b)为ghost模块操作,假设输入维度c1,输出维度为c2,普通卷积核大小为k,depthwise卷积核大小为d,特征图的高和宽为h和w,scale为s,公式如下:
网络参数量:

网络计算量:
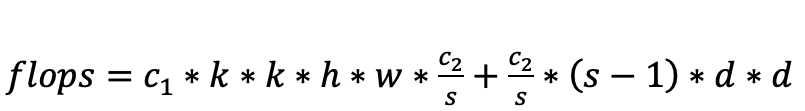
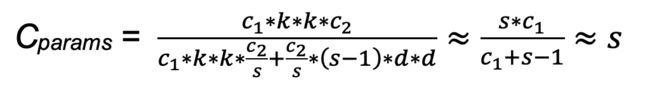
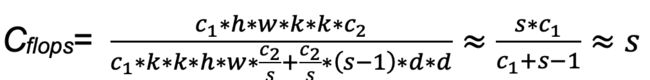
两者相除,得到flops和params的压缩比都大约等于s。关于论文的更多介绍,可以阅读论文原文,链接:
https://arxiv.org/pdf/1911.11907.pdf
基于飞桨复现GhostNet
近日,我们基于飞桨开源框架(PaddlePaddle)复现了GhostNet,并被飞桨官方模型库收录,下面我们将复现的技术细节与开发者分享。
GhostNet模型结构定义:
https://github.com/PaddlePaddle/PaddleClas/blob/master/ppcls/modeling/architectures/ghostnet.py
PaddleClas集成了GhonstNet预训练模型,简单几行代码修改,即可实现模型训练,如果您想直接使用GhostNet预训练模型,可以从这里下载:
https://github.com/PaddlePaddle/PaddleClas/blob/master/docs/zh_CN/models/models_intro.md
1. 搭建GhostNet网络
我们使用飞桨搭建了GhostNet模型结构,网络结构的核心是Ghost module。由Ghost module 组成Ghost bottleNeck,堆叠后形成GhostNet。
常规的卷积操作是根据输入和输出通道生成卷积操作。在ghost module中,先通过一个常规卷积来生成通道数更少的特征图;再通过depthwise卷积对生成的特征图进行加工,得到另一部分特征图;最后将两部分的特征图concat在一起,得到输出的结果。
假设输出通道数为out_ch, 设置比例系数ratio(ratio>1),则常规卷积的输出通道数为out_ch/ratio, depthwise卷积的输出通道数为out_ch/ratio*(ratio-1)。
同时GhostNet还有一个超参数用来控制模型的通道数,进而控制模型的大小,作者一共推出了三种不同scale的GhostNet,分别是GhostNet0.5,GhostNet1.0,GhostNet1.3,其中GhostNet0.5模型最小,GhostNet1.3模型最大。
为了帮助我们更方便地定义网络,先写一个conv_bn_layer方便后续的操作。
def conv_bn_layer(self,
input,
num_filters,
filter_size,
stride=1,
groups=1,
act=None,
name=None):
# 定义卷积操作
x = fluid.layers.conv2d(input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=None,
param_attr=ParamAttr(
initializer=fluid.initializer.MSRA(), name=name + "_weights"),
bias_attr=False)
bn_name = name + "_bn"
# 定义批归一化操作
x = fluid.layers.batch_norm(input=x,
act=act,
param_attr=ParamAttr(
name=bn_name + "_scale",
regularizer=fluid.regularizer.L2DecayRegularizer(
regularization_coeff=0.0)),
bias_attr=ParamAttr(
name=bn_name + "_offset",
regularizer=fluid.regularizer.L2DecayRegularizer(
regularization_coeff=0.0)),
moving_mean_name=bn_name + "_mean",
moving_variance_name=name + "_variance")
return x
飞桨支持静态图和动态图两种网络定义模式,这里我们选用静态图,如上代码就是定义了一个在卷积网络中最经常出现的conv_bn层,其中padding的模式为SAME。
具体参数含义如下:
input: 传入待卷积处理得张量对象
num_filters: 卷积核数量(输入张量的通道数)
filter_size: 卷积核形状
stride: 卷积步长
groups: 分组卷积的组数量
act: 接在BN层后的激活函数,如果为None,则不使用激活函数
name: 在运算图中的对象名称
接着我们定义GhostNet中的核心部分ghost module。
def ghost_module(self,
input,
output,
kernel_size=1,
ratio=2,
dw_size=3,
stride=1,
relu=True,
name=None):
init_channels = int(math.ceil(output / ratio))
new_channels = int(init_channels * (ratio - 1))
# 首先使用常规卷积操作,生成部分输出特征图
primary_conv = self.conv_bn_layer(input=input,
num_filters=init_channels,
filter_size=kernel_size,
stride=stride,
groups=1,
act="relu" if relu else None,
name=name + "_primary_conv")
# 定义成本更低的depthwise操作
cheap_operation = self.conv_bn_layer(input=primary_conv,
num_filters=new_channels,
filter_size=dw_size,
stride=1,
groups=init_channels,
act="relu" if relu else None,
name=name + "_cheap_operation")
# 将二者融合到一起,作为输出
out = fluid.layers.concat([primary_conv, cheap_operation], axis=1)
return out
输入的张量先经过一个普通的卷积操作得到primary_conv;primary_conv通过一个可分离卷积操作得到cheap_operation;最后将primary_conv, cheap_operation concatenate在一起输入结果张量。在这里primary_conv是常规卷积的输出结果,而cheap_operation则是通过depthwise卷积操作处理的输出结果。
而由ghost module组成网络的ghost bottleneck,定义代码如下:
def ghost_bottleneck(self,
input,
hidden_dim,
output,
kernel_size,
stride,
use_se,
name=None):
inp_channels = input.shape[1]
# 第一个ghost module
x = self.ghost_module(input=input,
output=hidden_dim,
kernel_size=1,
stride=1,
relu=True,
name=name + "_ghost_module_1")
if stride == 2:
# 降采样卷积
x = self.depthwise_conv(input=x,
output=hidden_dim,
kernel_size=kernel_size,
stride=stride,
relu=False,
name=name + "_depthwise")
if use_se:
# 加入SEBlock
x = self.se_block(input=x, num_channels=hidden_dim, name=name + "_se")
第二个ghost module
x = self.ghost_module(input=x,
output=output,
kernel_size=1,
relu=False,
name=name + "_ghost_module_2")
# 定义shortcut连接部分
if stride == 1 and inp_channels == output:
shortcut = input
else:
shortcut = self.depthwise_conv(input=input,
output=inp_channels,
kernel_size=kernel_size,
stride=stride,
relu=False,
name=name + "_shortcut_depthwise")
shortcut = self.conv_bn_layer(input=shortcut,
num_filters=output,
filter_size=1,
stride=1,
groups=1,
act=None,
name=name + "_shortcut_conv")
# 将二者相加返回
return fluid.layers.elementwise_add(x=x,
y=shortcut,
axis=-1)
GhostNet中的ghost bottleneck依据ResNet中的basic block,值得注意的是SEBlock是嵌入在两个ghost module之间而不是在最后。降采样时,ghost bottleneck采用的是两个ghost module之间插入步长为2的可分离卷积进行降采样,shortcut也是先经过步长为2的可分离卷积,再经过1x1的卷积进行降采样。
2. 训练策略
GhostNet属于轻量化移动端网络,训练策略与MobileNetV3类似。
对于BatchSize:GhostNet0.5的BatchSize设定为2048, GhostNet1.0和GhostNet1.3的BatchSize设定为1024;
对于初始学习率:根据线性缩减法则,对于GhostNet0.5,选用0.8作为初始学习率;对于GhostNet1.0和GhostNet1.3,选用0.4作为初始学习率。在初始的五个周期里,采用warmup策略来缓解网络初期的训练震荡;
对于训练的优化器:选用SGD+momentum来训练GhostNet,L2_decay设置为4e-5;
对于数据增广:GhostNet三个系列都使用了label smooth的方法,在GhostNet1.3采用了AutoAugment的方法来增加数据的多样性。
更多的网络策略请查看:
https://github.com/PaddlePaddle/PaddleClas/tree/master/configs/GhostNet
3. 模型复现效果
我们选用Paddle-Lite对MobileNetV3与GhostNet进行性能评估。Paddle-Lite 是飞桨推出的一套功能完善、易用性强且性能卓越的轻量化推理引擎。实现表明:基于骁龙855,MobileNetV3与GhostNet在batch size=1的情况下,精度与预测速度对比曲线如下。
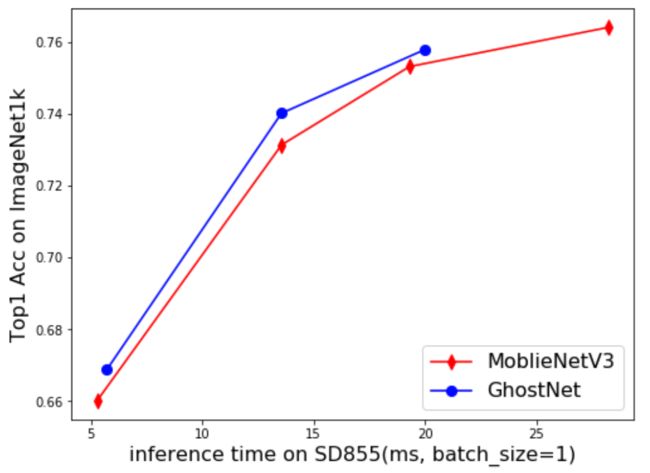
可以看出,GhostNet相比于MobileNetV3,在移动端还是更具优势的,详细的速度评估方法可以参考:
https://github.com/PaddlePaddle/PaddleClas/blob/master/docs/zh_CN/extension/paddle_mobile_inference.md
更多资源
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
