本周AI热点回顾:全球首个 AI 发球机器人诞生、MIT再爆数据集ImageNet存在系统性Bug...
01
惨遭下架后,MIT再爆知名数据集ImageNet存在系统性Bug
近日,麻省理工学院研究团队发表了一篇论文指控知名数据集ImageNet存在系统性Bug,该论文被国际机器学习大会ICML2020接收。
同时,这篇论文名为《From ImageNet to Image Classification: Contextualizing Progress on Benchmarks》,也发表在了在预印论库arXiv上。

麻省理工研究团队之所以在ICML大会上介绍这项研究,是因为近期陷入的“Tiny Images”争议事件。
就在本月初,麻省理工学院(MIT)宣布永久删除了包含8000万张图像的Tiny Images数据集,并公开表示歉意。其原因是,有关研究人员发表了一篇论文指控Tiny ImageNet数据集存在多项危险标签,包括种族歧视、性别歧视、色情内容等,而且指控有理有据。
论文中表明,ImageNet在语义结构分析上,使用的WordNet名词,它包含了种族歧视等危险内容,同时,由于图像过小,数据量过大,并未手动对图像标签进行逐一核对,由此导致了问题的出现。
众所周知,知名数据集ImageNet也使用了WordNet用于语义结构分析。他们发现,ImageNet数据集中大约有20%的图像包含两个或更多的对象目标。在通过对多个目标识别模型进行分析后,数据表明包含多个对象目标的照片会导致总体基准的准确性下降10%。
简单举个栗子:假如此图是ImageNet数据集中的一张高清图像,我们可以看到图片中不止包含了一个对象目标,包含女孩、吉他和唱麦,而且图片的主目标应该是女孩。

但ImageNet的数据标签可能不是女孩,也可能是唱麦或者吉他,重要的是ImageNet只会标注一个标签,这样可能就会导致ImageNet在目标识别中出现失误。
信息来源:机器之心
02
百度AI闪耀ACL2020:展现多项前沿技术、举办首届机器同传研讨会
近日,第58届国际计算语言学协会年会ACL 2020(The Association for Computational Linguistics)于线上开启。这次会议,百度共有11篇论文被录用,覆盖自然语言处理众多前沿研究方向;百度联合谷歌、Facebook、清华大学等全球顶尖机构,共同举办首届同声传译研讨会;在线上展台主题技术TALK环节,百度还就开放域人机对话技术、ERNIE核心技术等业内关注的话题展开分享,展现了中国企业在自然语言处理及人工智能领域的技术创新与落地实践能力。

ACL2020共收录百度11篇论文
除了在国际AI学界的影响力外,ACL无论是审稿规范还是审稿质量,都是当今AI领域国际顶级会议中公认的翘楚。
本届大会百度共有11篇论文被收录,覆盖了人机对话系统、情感分析/预训练表示学习、NLP文本生成与摘要、机器翻译/同声翻译、知识推理、AI辅助临床诊断等诸多自然语言处理界的前沿研究方向,提出了包括端到端开放域生成模型PLATO、面向开放域对话的基于图谱的对话管理机制、情感知识增强的语言模型预训练方法、基于图表示的多文档生成式摘要方法GraphSum等诸多新框架、新算法、新数据,不仅极大提升了相关领域的研究水平,也将推动人机交互、机器翻译、智慧医疗等场景的技术落地应用。
本次会议中,百度联合国内外顶尖企业和高校共同举办全球首届同声传译研讨会,汇集包括机器翻译、语音处理和人类口译领域的研究和从业人员,共同就机器同传架构、翻译模型、数据资源等问题展开研讨。

百度技术委员会主席、百度自然语言处理首席科学家吴华受邀做线上报告
研讨会有多场高质量主题演讲,百度技术委员会主席、百度自然语言处理首席科学家吴华等国内外多名专家就机器同传研究现状、面临挑战以及未来发展进行探讨,加深了机器同传与口译两个领域之间的交流,极大地推动了机器同传技术发展以及机器和人工同传的协同合作。
在本次研讨会同期举办的国际首届同传评测比赛中,百度行业首发业内最大规模面向真实场景的中英同传数据,涵盖信息技术、经济、文化、生物、艺术等多个领域。同时,基于百度深度学习平台飞桨的一站式AI开发实训平台百度大脑AI Studio,百度为参赛选手提供在线编程环境、免费GPU算力、海量开源算法和开放数据,帮助开发者快速创建和部署模型。
信息来源:百度NLP
03
8.6M超轻量中英文OCR模型开源,训练部署一条龙
作为一名开发者,各种OCR相关的需求自然也少不了:卡证识别、票据识别、汽车场景、教育场景文字识别……
那么,这个模型大小仅8.6M,没有GPU也能跑得动,还提供自定义训练到多硬件部署的全套开发套件的开源通用OCR项目,了解一下?
话不多说,先来看效果。

难度略高,且实际生活当中经常遇到的场景也不在话下:

而在这个开源项目中,开发者也贴心提供了直接可供测试的Demo。
在实际上手测试中,在移动端Demo上这样一个不到10M的模型,基本上可以做到秒出效果。
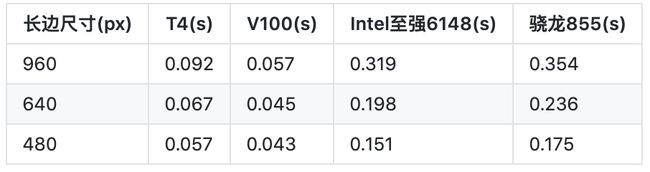
在中文公开数据集ICDAR2017-RCTW上,限定图片长边尺寸960px,测试数据与测试条件相同的前提下,将该项目与之前一度登上GitHub热榜的Chineseocr_Lite(5.1k stars)最新发布的10M模型进行测试对比。在模型大小、精度和预测速度方面,结果如下:
该8.6M超轻量模型,V100 GPU单卡平均预测耗时57ms,CPU平均预测耗时319ms。
而Chineseocr_Lite的10M模型,V100单卡预测速度230ms,CPU平均预测耗时739ms。
当然,这里面模型预测速度的提升不仅是因为模型大小更小了,也离不开算法与框架深度适配优化。
项目中给出的Benchmark如下:
作为一名面向GitHub编程的程序员,顿时感到老板再来各种OCR需求都不方了。
而且这个8.6M超轻量开源模型,背后还有大厂背书。
因为出品方不是别人,是国产AI开发一哥百度,他们把这个最新开源的OCR工具库取名:PaddleOCR。
GitHub 地址:
https://github.com/PaddlePaddle/PaddleOCR
信息来源:飞桨PaddlePaddle
04
全球首个 AI 发球机器人诞生,国球练出新高度
近日,全球首台人工智能机器人乒乓球发球机庞伯特(Pong bot),在位于上海的中国乒乓球学院诞生。
这位发球机器人并不简单,据一位体验者介绍,一套训练下来,「感觉仿佛在和一个真人交手,而且还是一个高手!」
这款机器人由中国乒乓球学院和上海新松机器人自动化股份有限公司合作研发。
这款机器人不仅能够还原自然发球动作,打出落点不一、旋转不同的球,还能任意组合发球节奏,帮助运动员进行针对性的加强训练。
庞伯特有两条机械臂,一个用于抛球,一个用于击打,还原了真人的发球动作,还能通过球拍快换模拟不同的打法风格。

未来,这个乒乓球机器人还将引入社区、学校和健身房等,助推乒乓球的普及。
信息来源:HyperAI超神经
05
本周论文推荐
【ACL 2020 | 百度】:启发式同声翻译算法
Simultaneous Translation Policies: fromFixed to Adaptive
论文介绍:

同声翻译是机器翻译中的一个重要问题,它不仅要求高质量的翻译结果,而且要求翻译的过程有较低的时延。同声翻译的过程可以认为是一个选择“读”或“写”的决策过程,而所采用的策略则决定了同声翻译的质量与时延。
本文提出一种简单的启发式算法,根据翻译模型输出的概率分布,可以将几种精简的固定“读写”策略组合成一种灵活的策略。本文进一步将该算法与集成方法相结合,既提高了翻译质量,又降低了翻译过程的时延。这种简单的算法不需要训练策略模型,使得其更易于在产品中使用。
END
