手把手教你用yolov3模型实现目标检测(二) -VOC数据集制作
网上关于数据标注的文章已有很多,大多数都会有一些细节问题,比如怎样爬取网上的原始图片数据,如何批量重命名?数据集怎样划分为训练集,测试集,验证集???标注的数据放置的目录结构不对导致训练报错的问题等等,而这些问题,在本篇文章中都考虑到了,所以只要你按照步骤一步步来,并且使用本文中的代码,将会避免遇到上面所说的问题:
我们已经知道,物体检测,简言之就是框出图像中的目标物体,并给出框的位置和置信度,就像下图这样:

置信度在终端输出了:

1、标注工具labelImg
是的,当然要用强大的labelImg,貌似记得直接可以pip install labelImg,还是查一下如何安装吧,很简单的
界面长这个样子:
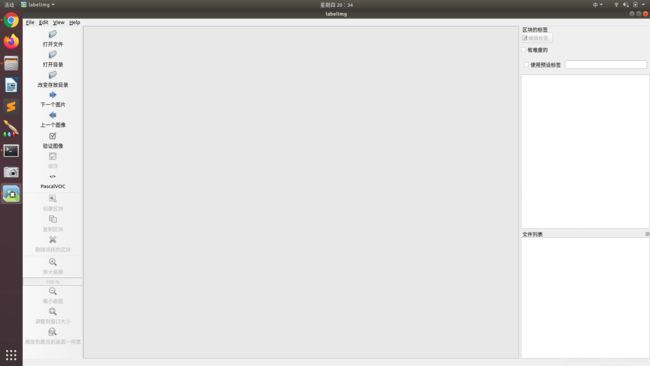
下面我们标注PascalVOC数据集:
首先下载VOC2007格式的原始数据集:
http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
下载完成后,目录应该是这样式儿的:
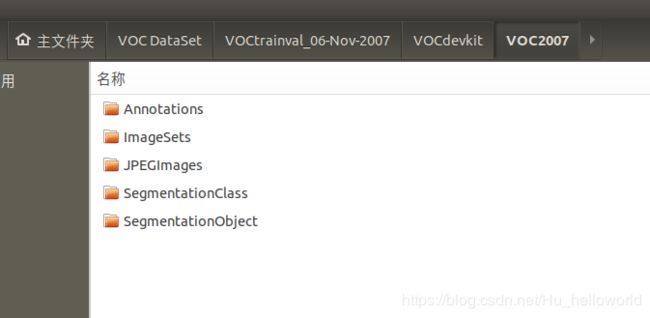
如果不需要其中的图片,直接删除,只保留空的目录结构。
其中,Annotations存放标注后的标签文件(.xml)
ImageSets存放你的训练集、测试集、验证集等的配置文件(文件中存放图片路径)
JPEGImages存放原始图片数据
SegmentationClass
SegmentationObject我们不使用
labelImg标注工具选择 打开目录->打开ImageSets目录,选择改变存放目录,存放xml到Annotations目录
labelImg使用简单快捷键:
A / D键,左右选择图片,W:开始标注,ctrl+s保存。
标注需遵守的基本规则:

----------------------------------------分割线-----------------------------------------
那知道怎么标注后,如何获取我们想要的图片数据:
请移步:
https://blog.csdn.net/Hu_helloworld/article/details/103044737
网上爬虫等下载到图片后,如何批量重命名?
一个小脚本:
食用时,请修改self.path重命名图片的路径,我会专门mkdir一个rename目录,免得出错。
而且重点是,VOC数据集格式是规定这样的:占6位数,所以必要是要修改dst那行的几个’000’,你一试就行
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
class ImageRename():
def __init__(self):
self.path = '/home/hujinlei/dev/YOLOv3-dev/darknet/scripts/VOCdevkit/VOC2007/rename'
def rename(self):
filelist = os.listdir(self.path)
total_num = len(filelist)
i = 2548
for item in filelist:
if item.endswith('.jpg'):
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), '000' + format(str(i), '0>3s') + '.jpg')
os.rename(src, dst)
print ('converting %s to %s ...'%(src, dst))
i = i + 1
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
newname = ImageRename()
newname.rename()
都标注好,重命名ok以后。
在VOC2007目录下,也就是这个目录下:
以下脚本可以给整个数据集划分为:训练集、测试集、验证集.
"""
将voc_2007格式的数据集划分下训练集、测试集和验证集
"""
import os
import random
trainval_percent = 0.96
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w', encoding="utf-8")
ftest = open('ImageSets/Main/test.txt', 'w', encoding="utf-8")
ftrain = open('ImageSets/Main/train.txt', 'w', encoding="utf-8")
fval = open('ImageSets/Main/val.txt', 'w', encoding="utf-8")
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
会在目录下,生成ImageSets/Main/
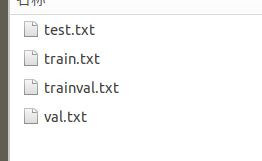
最后,在工程项目的/scripts目录下,修改voc_label.py文件:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#将下面的sets和classes改为自己对应的
#sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["Fire extinguisher","Fire extinguisher box","Fire hydrant","trolley","ladder"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt")
运行此脚本,会在当前目录,产生以下文件:
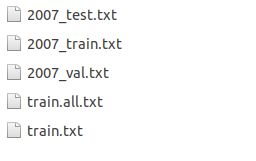
其中,2007_test.txt测试集
2007_train.txt训练集
2007_val.txt验证集
我们使用2007_test.txt和train.txt就可以。
=============================================================
日后在更