- Hive小文件合并
云掣YUNCHE
hivehadoop数据仓库
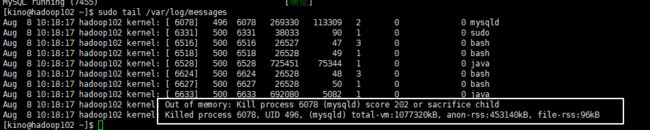
作者:振鹭一、参数配置:在Map输入的时候,把小文件合并。--每个Map最大输入大小,决定合并后的文件数setmapred.max.split.size=256000000;--一个节点上split的至少的大小,决定了多个datanode上的文件是否需要合并setmapred.min.split.size.per.node=100000000;--一个交换机下split的至少的大小,决定了多个交换
- hive小文件合并机制_hive小文件的问题弊端以及合并
做生活的创作者
hive小文件合并机制
小文件的弊端1、HDFS中每个文件的元数据信息,包括位置大小分块信息等,都保存在NN内存中,在小文件数较多的情况下,会造成占用大量内存空间,导致NN性能下降;2、在读取小文件多的目录时,MR会产生更多map数,造成GC频繁,浪费集群资源;3、现在大数据平台文件总数超过30亿,单个NS文件数超过4亿的时候,读写性能会急剧下降,影响到所有读写该NS的任务性能;4、如果队列限制最大map数是20000,
- 数仓建模(五)选择数仓技术栈:Hive & ClickHouse & 其它
昊昊该干饭了
数仓建模大数据hiveclickhousehadoop
在大数据技术的飞速发展下,数据仓库(DataWarehouse,简称数仓)成为企业处理和分析海量数据的核心工具。市场上主流数仓技术栈丰富,如Hive、ClickHouse、Druid、Greenplum等,对于初学者而言,选择合适的技术栈是一项挑战。本文将详细解析Hive、ClickHouse及其他数仓技术,帮助读者根据场景需求选择最佳工具。目录一、数据仓库的基础概念和技术选型原则1.1什么是数据
- Hive--HiveServer2 命令行代码连接、Hive常用命令、自定义UDF函数、排序
XK&RM
Hivehivehiveserver2udfjava
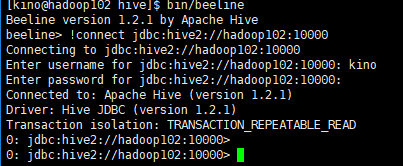
目录1Hive--HiveServer2命令行代码连接1.1配置HiveServer2WEB参数1.2开启HiveServer21.3使用Beeline连接HiveServer21.4使用代码查询HiveServer21.5使用DBeaver连接Hive2Hive--Hive常用命令2.1Hive命令2.2HiveShell命令3Hive--自定义UDF函数(User-DefinedFunctio
- Hive 数据类型全解析:大数据开发者的实用指南
大鳥
sqlhive数据仓库
在大数据处理领域,Hive作为一款基于Hadoop的数据仓库工具,被广泛应用于数据的存储、查询和分析。而理解Hive的数据类型是有效使用Hive的基础,本文将深入探讨Hive的数据类型,帮助大家更好地掌握Hive的使用。Hive数据类型概述Hive支持多种数据类型,主要可分为数值类型、日期/时间类型、字符类型、Misc类型以及复杂类型。这些数据类型为存储和处理各种不同格式的数据提供了有力的支持。以
- Apache Hive--排序函数解析
大鳥
apachehivehadoop
在大数据处理与分析中,ApacheHive是一个至关重要的数据仓库工具。其丰富的函数库为数据处理提供了诸多便利,排序函数便是其中一类非常实用的工具。通过排序函数,我们能够在查询结果集中为每一行数据分配一个排名值,这对于数据分析、报表生成等工作具有重要意义。本文将深入探讨ApacheHive中的排序函数,通过具体的HQL代码和数据实例进行说明,并阐述它们之间的区别。0.排序函数:ORDER、SORT
- 大数据新视界 -- Hive 数据仓库设计的优化原则(2 - 16 - 4)
青云交
大数据新视界#Hive之道Hive数据仓库优化原则数据分区存储格式查询优化B树索引查询性能大数据
亲爱的朋友们,热烈欢迎你们来到青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。本博客的精华专栏:大数
- 使用 Hadoop 实现大数据的高效存储与查询
王子良.
经验分享大数据hadoop分布式
欢迎来到我的博客!非常高兴能在这里与您相遇。在这里,您不仅能获得有趣的技术分享,还能感受到轻松愉快的氛围。无论您是编程新手,还是资深开发者,都能在这里找到属于您的知识宝藏,学习和成长。博客内容包括:Java核心技术与微服务:涵盖Java基础、JVM、并发编程、Redis、Kafka、Spring等,帮助您全面掌握企业级开发技术。大数据技术:涵盖Hadoop(HDFS)、Hive、Spark、Fli
- ORACLE与SQL SERVER的区别
nanzhuhe
文章笔记数据库Oracle
ORACLE与SQLSERVER的区别转载自:https://www.cnblogs.com/chuncn/archive/2009/01/28/1381262.html体系结构ORACLE的文件体系结构为:数据文件.DBF(真实数据)日志文件.RDO控制文件.CTL参数文件.ORASQLSERVER的文件体系结构为:.MDF(数据字典).NDF(数据文件).LDF(日志文件)ORACLE存储结构
- hdfs和hive对于小文件的处理方案
二进制_博客
大数据
一、hdfs如何处理小文件小文件问题的危害小文件问题对HDFS的性能和稳定性产生显著影响,主要包括:占用过多的存储空间:每个小文件都会占用一个独立的Block,导致存储资源的浪费。降低数据处理效率:HDFS是为处理大文件而设计的,小文件会导致大量的Map任务启动,增加处理时间和资源消耗。NameNode内存压力增大:NameNode需要维护所有文件和目录的元数据信息,小文件过多会导致NameNod
- hive 创建访问用户_Hive权限控制和超级管理员的实现
weixin_39826089
hive创建访问用户
Hive权限控制Hive权限机制:Hive从0.10可以通过元数据控制权限。但是Hive的权限控制并不是完全安全的。基本的授权方案的目的是防止用户不小心做了不合适的事情。先决条件:为了使用Hive的授权机制,有两个参数必须在hive-site.xml中设置:hive.security.authorization.enabledtrueenableordisablethehiveclientauth
- hive表级权限控制_Hive权限管理
weixin_39769091
hive表级权限控制
最近遇到一个hive权限的问题,先简单记录一下,目前自己的理解不一定对,后续根据自己的理解程度更新一、hive用户的概念hive本身没有创建用户的命令,hive的用户就是Linux用户,若当前是用mr用户输入hive,进入hive的shell,则当前hive的用户为mr。hive本身不提供用户和用户的管理,只做权限控制。所以在实际的生产中,容易造成创表和使用表的用户不统一的情况,针对该情况可以使用
- HIVE的权限控制和超级管理员的实现
weixin_34364071
大数据数据库java
Hive用户权限管理从remote部署hive和mysql元数据表字典看,已经明确hive是通过存储在元数据中的信息来管理用户权限。现在重点是Hive怎么管理用户权限。首先要回答的是用户是怎么来的,发现hive有创建角色的命令,但没有创建用户的命令,显然Hive的用户不是在mysql中创建的。在回答这个问题之前,先初步了解下Hive的权限管理机制。Hive用户组和用户即Linux用户组和用户,和h
- hive批量修复分区
青云游子
Hivehive数据库hadoop
#!/bin/bashset-x#定义Hive数据库的名称database_name="edu"#定义要排除的表名exclude_table="tab_name"#使用Hive的shell命令获取所有的表名tables=$(hive-e"USE$database_name;SHOWTABLES;")#初始化一个字符串,用于存储所有的MSCKREPAIRTABLE命令commands="USE$da
- HiveMetaException: Unknown version specified for initialization: 3.1.0(或者其他版本号)
一品_人生
mysqlhive大数据
遇到这个问题,也是很难发现的,查阅很多文章,乱七八糟,也可能是遇到的问题不相同吧,我们从以下两个方面去排查吧1.检查你的hive-site.xml和hive-env.sh,配置对就行,这个网上一大片,注意要正确。2.那就是你解压的hive压缩文件,然后发现要安装mysql,这时你会先检查你本地有没有mysql,使用find/-namemysql(罪源),然后你就一通删除,你没有发现你删除了一个hi
- hive表修改字段类型没有级连导致历史分区报错
尘世壹俗人
大数据Hive技术hivehadoop数据仓库
一:问题背景修改hive的分区表时有级连概念,指字段的最新状态,默认只对往后的分区数据生效,而之前的分区保留历史元数据状态。好处就是修改语句的效率很快,坏处就是如果历史分区的数据还有用,那就回发生分区元数据和表元数据的不一致报错最终导致:presto或hive任务抽取历史分区会报如下的错误Thereisamismatchbetweenthetableandpartitionschemas.Thet
- Hive 查看partition 以及msck 修复分区
dgsdaga3026010
大数据
#checktable的partitionhive>showpartitionstable_name;如果是外部表,不小心把表给删除了,可以适用下命令重新关联表和数据[MSCKREPAIRTABLE]全量修复分区hive>msckrepairtabletable_name;转载于:https://www.cnblogs.com/TendToBigData/p/10501178.html
- 集群间hive数仓迁移
one code
database
方式一:(此方法需要建库建表)第一步:建库建表在原集群hive上查看迁移表的建表语句及所在库,然后在新集群hive上建库建表;showcreatetabletb_name;createdatabasedb_name;createtabletb_name.....第二步:转移数据文件到新集群;在旧集群中下载数据到本地hadoopfs-get/user/hive/warehouse/dc_ods.db
- HIVE合并小文件
难以触及的高度
hivehadoop数据仓库
8.分区分桶,合并小文件为什么小文件需要合并?1.小文件过多,MR处理数据时,会产生多个MapTask,然而每个MapTask处理的数据量很少,那么导致MapTask启动时间大于执行时间,整体任务时间消耗较大如何合并小文件:1)在map执行前合并小文件,减少map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件
- Hive中没有超级管理员,如何进行权限控制
二进制_博客
大数据hivehadoop数据仓库
Hive中没有超级管理员,任何用户都可以进行Grant/Revoke操作开发实现自己的权限控制类,确保某个用户为超级用户比如任何用户都可以grant权限给别的用户。grantselectontabletest2touserhadoop;如何开发一个超级管理员:创建一个项目,导入mavanjar包,然后开始编写hook类importcom.google.common.base.Joiner;impo
- docker-ubuntu-24.04安装openresty1.21.4.3全过程
司江龙
ubuntulinux运维
拉取最新的ubuntu镜像dockerpullubuntu:latest创建启动容器dockerrun-it--name容器名称-p8082:8082镜像id/bin/bash更换apt-get为阿里云镜像sed-i'
[email protected]/@/mirrors.aliyun.com/@g'/etc/apt/sources.list&&apt-getupdate创建目录cdhome
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
武子康
大数据离线数仓大数据数据仓库java后端hadoophive
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- 架构师反向代理Haproxy+压力测试 - 学习笔记
无影V随风
学习笔记linux相关
一.Apache的反向代理(生产不建议使用)1.Apache的编译安装:yuminstallapr-develapr-util-develpcre-developenssl-develcd/usr/local/src/wgethttp://archive.apache.org/dist/httpd/httpd-2.4.18.tar.gztar-zxvfhttpd-2.4.18.tar.gzcdht
- Python 爬虫:获取网页数据的 5 种方法
王子良.
经验分享pythonpython开发语言爬虫
欢迎来到我的博客!非常高兴能在这里与您相遇。在这里,您不仅能获得有趣的技术分享,还能感受到轻松愉快的氛围。无论您是编程新手,还是资深开发者,都能在这里找到属于您的知识宝藏,学习和成长。博客内容包括:Java核心技术与微服务:涵盖Java基础、JVM、并发编程、Redis、Kafka、Spring等,帮助您全面掌握企业级开发技术。大数据技术:涵盖Hadoop(HDFS)、Hive、Spark、Fli
- QT ListView 记录
weixin_30872157
数据库
http://www.cnblogs.com/chenxuelian/archive/2009/12/22/1629601.html转载于:https://www.cnblogs.com/whisht/archive/2012/06/12/3085088.html
- linux安装卸载软件
int8
linuxlinux运维服务器
一、首先要清楚几个概念(一)归档:归档是把多个文件合并成一个文件的过程。生成的文件称为归档包。归档包带后缀名。不同的归档程序,生成的归档包的后缀名不同。(二)压缩:压缩是把一个大文件变成一个小文件的过程。生成的文件称为压缩包。压缩包名带后缀名。不同的压缩程序,生成的压缩包的后缀名不同。(三)归档压缩程序仅归档ar:archiver。后缀名为.a,.arTar:TapeArchive。通过Tar归档
- 一步到位:购买适合 SEO 的域名全攻略
后端
选择一个对SEO友好的域名不仅可以提高搜索引擎排名,还能增强品牌影响力。以下是简化优化后的购买流程:1.检查域名历史,确保无负面记录在购买域名前,务必确认它没有被封锁或拉黑,并且历史记录与您的行业相关:检查域名安全性和历史VirusTotal:查看域名是否被列为不安全。WebArchive:查看域名以前的用途,判断是否有不良记录或与您的行业冲突。GoogleTransparencyReport:检
- 2024年最新Python:Page Object设计模式_python page object,BTAJ大厂最新面试题汇集
m0_60707708
程序员python设计模式开发语言
最后硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是
- 采用海豚调度器+Doris开发数仓保姆级教程(满满是踩坑干货细节,持续更新)
大模型大数据攻城狮
海豚调度器从入门到精通doris海豚调度器离线数仓实时数仓国产代替信创大数据flink数仓
目录一、采用海豚调度器+Doris开发平替CDHHdfs+Yarn+Hive+Oozie的理由。1.架构复杂性2.数据处理性能3.数据同步与更新4.资源利用率与成本6.生态系统与兼容性7.符合信创或国产化要求二、ODS层接入数据接入kafka实时数据踩坑的问题细节三、海豚调度器调度Doris进行报表开发创建带分区的表在doris进行开发调试开发海豚调度器脚本解决shell脚本使用MySQL命令行给
- 【YashanDB知识库】原生mysql驱动配置连接崖山数据库
数据库
本文内容来自YashanDB官网,原文内容请见https://www.yashandb.com/newsinfo/7919231.html?templateId=171...【问题分类】功能兼容【关键字】YAS-07202、YAS\_MYERROR,不兼容【问题描述】本项目的架构是hadoop+hive+yashandb使用崖山数据库,将mysql相关的创建表语句进行初始化同步使用崖山23.3版本
- html页面js获取参数值
0624chenhong
html
1.js获取参数值js
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = windo
- MongoDB 在多线程高并发下的问题
BigCat2013
mongodbDB高并发重复数据
最近项目用到 MongoDB , 主要是一些读取数据及改状态位的操作. 因为是结合了最近流行的 Storm进行大数据的分析处理,并将分析结果插入Vertica数据库,所以在多线程高并发的情境下, 会发现 Vertica 数据库中有部分重复的数据. 这到底是什么原因导致的呢?笔者开始也是一筹莫 展,重复去看 MongoDB 的 API , 终于有了新发现 :
com.mongodb.DB 这个类有
- c++ 用类模版实现链表(c++语言程序设计第四版示例代码)
CrazyMizzz
数据结构C++
#include<iostream>
#include<cassert>
using namespace std;
template<class T>
class Node
{
private:
Node<T> * next;
public:
T data;
- 最近情况
麦田的设计者
感慨考试生活
在五月黄梅天的岁月里,一年两次的软考又要开始了。到目前为止,我已经考了多达三次的软考,最后的结果就是通过了初级考试(程序员)。人啊,就是不满足,考了初级就希望考中级,于是,这学期我就报考了中级,明天就要考试。感觉机会不大,期待奇迹发生吧。这个学期忙于练车,写项目,反正最后是一团糟。后天还要考试科目二。这个星期真的是很艰难的一周,希望能快点度过。
- linux系统中用pkill踢出在线登录用户
被触发
linux
由于linux服务器允许多用户登录,公司很多人知道密码,工作造成一定的障碍所以需要有时踢出指定的用户
1/#who 查出当前有那些终端登录(用 w 命令更详细)
# who
root pts/0 2010-10-28 09:36 (192
- 仿QQ聊天第二版
肆无忌惮_
qq
在第一版之上的改进内容:
第一版链接:
http://479001499.iteye.com/admin/blogs/2100893
用map存起来号码对应的聊天窗口对象,解决私聊的时候所有消息发到一个窗口的问题.
增加ViewInfo类,这个是信息预览的窗口,如果是自己的信息,则可以进行编辑.
信息修改后上传至服务器再告诉所有用户,自己的窗口
- java读取配置文件
知了ing
1,java读取.properties配置文件
InputStream in;
try {
in = test.class.getClassLoader().getResourceAsStream("config/ipnetOracle.properties");//配置文件的路径
Properties p = new Properties()
- __attribute__ 你知多少?
矮蛋蛋
C++gcc
原文地址:
http://www.cnblogs.com/astwish/p/3460618.html
GNU C 的一大特色就是__attribute__ 机制。__attribute__ 可以设置函数属性(Function Attribute )、变量属性(Variable Attribute )和类型属性(Type Attribute )。
__attribute__ 书写特征是:
- jsoup使用笔记
alleni123
java爬虫JSoup
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.3</version>
</dependency>
2014/08/28
今天遇到这种形式,
- JAVA中的集合 Collectio 和Map的简单使用及方法
百合不是茶
listmapset
List ,set ,map的使用方法和区别
java容器类类库的用途是保存对象,并将其分为两个概念:
Collection集合:一个独立的序列,这些序列都服从一条或多条规则;List必须按顺序保存元素 ,set不能重复元素;Queue按照排队规则来确定对象产生的顺序(通常与他们被插入的
- 杀LINUX的JOB进程
bijian1013
linuxunix
今天发现数据库一个JOB一直在执行,都执行了好几个小时还在执行,所以想办法给删除掉
系统环境:
ORACLE 10G
Linux操作系统
操作步骤如下:
第一步.查询出来那个job在运行,找个对应的SID字段
select * from dba_jobs_running--找到job对应的sid
&n
- Spring AOP详解
bijian1013
javaspringAOP
最近项目中遇到了以下几点需求,仔细思考之后,觉得采用AOP来解决。一方面是为了以更加灵活的方式来解决问题,另一方面是借此机会深入学习Spring AOP相关的内容。例如,以下需求不用AOP肯定也能解决,至于是否牵强附会,仁者见仁智者见智。
1.对部分函数的调用进行日志记录,用于观察特定问题在运行过程中的函数调用
- [Gson六]Gson类型适配器(TypeAdapter)
bit1129
Adapter
TypeAdapter的使用动机
Gson在序列化和反序列化时,默认情况下,是按照POJO类的字段属性名和JSON串键进行一一映射匹配,然后把JSON串的键对应的值转换成POJO相同字段对应的值,反之亦然,在这个过程中有一个JSON串Key对应的Value和对象之间如何转换(序列化/反序列化)的问题。
以Date为例,在序列化和反序列化时,Gson默认使用java.
- 【spark八十七】给定Driver Program, 如何判断哪些代码在Driver运行,哪些代码在Worker上执行
bit1129
driver
Driver Program是用户编写的提交给Spark集群执行的application,它包含两部分
作为驱动: Driver与Master、Worker协作完成application进程的启动、DAG划分、计算任务封装、计算任务分发到各个计算节点(Worker)、计算资源的分配等。
计算逻辑本身,当计算任务在Worker执行时,执行计算逻辑完成application的计算任务
- nginx 经验总结
ronin47
nginx 总结
深感nginx的强大,只学了皮毛,把学下的记录。
获取Header 信息,一般是以$http_XX(XX是小写)
获取body,通过接口,再展开,根据K取V
获取uri,以$arg_XX
&n
- 轩辕互动-1.求三个整数中第二大的数2.整型数组的平衡点
bylijinnan
数组
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ExoWeb {
public static void main(String[] args) {
ExoWeb ew=new ExoWeb();
System.out.pri
- Netty源码学习-Java-NIO-Reactor
bylijinnan
java多线程netty
Netty里面采用了NIO-based Reactor Pattern
了解这个模式对学习Netty非常有帮助
参考以下两篇文章:
http://jeewanthad.blogspot.com/2013/02/reactor-pattern-explained-part-1.html
http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
- AOP通俗理解
cngolon
springAOP
1.我所知道的aop 初看aop,上来就是一大堆术语,而且还有个拉风的名字,面向切面编程,都说是OOP的一种有益补充等等。一下子让你不知所措,心想着:怪不得很多人都和 我说aop多难多难。当我看进去以后,我才发现:它就是一些java基础上的朴实无华的应用,包括ioc,包括许许多多这样的名词,都是万变不离其宗而 已。 2.为什么用aop&nb
- cursor variable 实例
ctrain
variable
create or replace procedure proc_test01
as
type emp_row is record(
empno emp.empno%type,
ename emp.ename%type,
job emp.job%type,
mgr emp.mgr%type,
hiberdate emp.hiredate%type,
sal emp.sal%t
- shell报bash: service: command not found解决方法
daizj
linuxshellservicejps
今天在执行一个脚本时,本来是想在脚本中启动hdfs和hive等程序,可以在执行到service hive-server start等启动服务的命令时会报错,最终解决方法记录一下:
脚本报错如下:
./olap_quick_intall.sh: line 57: service: command not found
./olap_quick_intall.sh: line 59
- 40个迹象表明你还是PHP菜鸟
dcj3sjt126com
设计模式PHP正则表达式oop
你是PHP菜鸟,如果你:1. 不会利用如phpDoc 这样的工具来恰当地注释你的代码2. 对优秀的集成开发环境如Zend Studio 或Eclipse PDT 视而不见3. 从未用过任何形式的版本控制系统,如Subclipse4. 不采用某种编码与命名标准 ,以及通用约定,不能在项目开发周期里贯彻落实5. 不使用统一开发方式6. 不转换(或)也不验证某些输入或SQL查询串(译注:参考PHP相关函
- Android逐帧动画的实现
dcj3sjt126com
android
一、代码实现:
private ImageView iv;
private AnimationDrawable ad;
@Override
protected void onCreate(Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
setContentView(R.layout
- java远程调用linux的命令或者脚本
eksliang
linuxganymed-ssh2
转载请出自出处:
http://eksliang.iteye.com/blog/2105862
Java通过SSH2协议执行远程Shell脚本(ganymed-ssh2-build210.jar)
使用步骤如下:
1.导包
官网下载:
http://www.ganymed.ethz.ch/ssh2/
ma
- adb端口被占用问题
gqdy365
adb
最近重新安装的电脑,配置了新环境,老是出现:
adb server is out of date. killing...
ADB server didn't ACK
* failed to start daemon *
百度了一下,说是端口被占用,我开个eclipse,然后打开cmd,就提示这个,很烦人。
一个比较彻底的解决办法就是修改
- ASP.NET使用FileUpload上传文件
hvt
.netC#hovertreeasp.netwebform
前台代码:
<asp:FileUpload ID="fuKeleyi" runat="server" />
<asp:Button ID="BtnUp" runat="server" onclick="BtnUp_Click" Text="上 传" />
- 代码之谜(四)- 浮点数(从惊讶到思考)
justjavac
浮点数精度代码之谜IEEE
在『代码之谜』系列的前几篇文章中,很多次出现了浮点数。 浮点数在很多编程语言中被称为简单数据类型,其实,浮点数比起那些复杂数据类型(比如字符串)来说, 一点都不简单。
单单是说明 IEEE浮点数 就可以写一本书了,我将用几篇博文来简单的说说我所理解的浮点数,算是抛砖引玉吧。 一次面试
记得多年前我招聘 Java 程序员时的一次关于浮点数、二分法、编码的面试, 多年以后,他已经称为了一名很出色的
- 数据结构随记_1
lx.asymmetric
数据结构笔记
第一章
1.数据结构包括数据的
逻辑结构、数据的物理/存储结构和数据的逻辑关系这三个方面的内容。 2.数据的存储结构可用四种基本的存储方法表示,它们分别是
顺序存储、链式存储 、索引存储 和 散列存储。 3.数据运算最常用的有五种,分别是
查找/检索、排序、插入、删除、修改。 4.算法主要有以下五个特性:
输入、输出、可行性、确定性和有穷性。 5.算法分析的
- linux的会话和进程组
网络接口
linux
会话: 一个或多个进程组。起于用户登录,终止于用户退出。此期间所有进程都属于这个会话期。会话首进程:调用setsid创建会话的进程1.规定组长进程不能调用setsid,因为调用setsid后,调用进程会成为新的进程组的组长进程.如何保证? 先调用fork,然后终止父进程,此时由于子进程的进程组ID为父进程的进程组ID,而子进程的ID是重新分配的,所以保证子进程不会是进程组长,从而子进程可以调用se
- 二维数组 元素的连续求解
1140566087
二维数组ACM
import java.util.HashMap;
public class Title {
public static void main(String[] args){
f();
}
// 二位数组的应用
//12、二维数组中,哪一行或哪一列的连续存放的0的个数最多,是几个0。注意,是“连续”。
public static void f(){
- 也谈什么时候Java比C++快
windshome
javaC++
刚打开iteye就看到这个标题“Java什么时候比C++快”,觉得很好笑。
你要比,就比同等水平的基础上的相比,笨蛋写得C代码和C++代码,去和高手写的Java代码比效率,有什么意义呢?
我是写密码算法的,深刻知道算法C和C++实现和Java实现之间的效率差,甚至也比对过C代码和汇编代码的效率差,计算机是个死的东西,再怎么优化,Java也就是和C