爬虫7_《隐秘的角落》豆瓣影评爬取及可视化分析
爬取链接:隐秘的角落豆瓣影评
本文源码:百度云 提取码 pra2
影评爬取
豆瓣网有限制,各种类型的评论只可以爬取220条,所以我爬取了好评、一般、差评各220条,共计630条。爬取维度为评论类型、点赞数、评分、发布日期、评论。
分析url
![]()
start:从第几条开始展示,豆瓣影评每一页都是20条评论,所以start应该是20的倍数。
limit:这个限制了每页显示多少评论,但修改数值也没用。
sort:根据热门/最新/好友进行排序, 这里我选择了热门。
status:P/F代表看过和想看,我选择了想看。
percent_type:影评类型,h/m/l分别代表好评/一般/差评,是我们需要修改的。
根据参数分析,我们得到BASE_URL应该是:
BASE_URL = 'https://movie.douban.com/subject/33404425/comments?start={}&limit=20&sort=new_score&status=P&percent_type={}'
页面解析
我使用的是Chrome浏览器,Ctrl+U显示网页源码,可以发现豆瓣影评部分并没有使用JS动态更新,所以我们可以直接对源码进行解析。

源码的部分解释如下图所示:
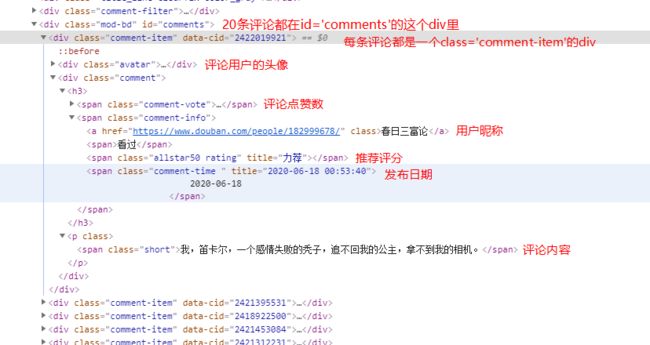
编写代码
# 初始URL
BASE_URL = "https://movie.douban.com/subject/33404425/comments?start={}&limit=20&sort=new_score&status=P&percent_type={}"
# 设置UA,Cookie
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
"Cookie": 'bid=6Y_umIrRUHk; __gads=ID=f3fa196be74c49f5:T=1589907087:S=ALNI_MbVwFaOcaNVABqsayjnOCawaNo-3A; gr_user_id=fe3032d1-40a6-4aef-93f4-054a36710beb; _vwo_uuid_v2=DE361BA9F9B9BACBDEB73CC87199709AE|bf1c5209c48152fea364a3ac6e60548f; ll="108296"; __yadk_uid=BNpZEeOtOgDz2raZXEavltn1VuJB005I; viewed="24715620_30231494"; __utma=30149280.669920134.1589907069.1593061398.1593764577.6; __utmc=30149280; __utmz=30149280.1593764577.6.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1593764586%2C%22https%3A%2F%2Fwww.douban.com%2Fsearch%3Fq%3D%25E9%259A%2590%25E8%2597%258F%25E7%259A%2584%25E8%25A7%2592%25E8%2590%25BD%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.1716723746.1590498467.1590498467.1593764586.2; __utmb=223695111.0.10.1593764586; __utmc=223695111; __utmz=223695111.1593764586.2.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/search; ct=y; _pk_id.100001.4cf6=76ecf6aae620740b.1590498467.2.1593764786.1590498508.; __utmb=30149280.11.10.1593764577'
}
# 评论类型分为好评中评差评三种
PERCENT_TYPE = ['h', 'm', 'l']
def get_html_comments_divs(url, headers):
'''
return:list
describe:访问url,解析豆瓣每页20条评论
'''
res = requests.get(url, headers=headers)
res.encoding = "UTF-8"
html = etree.HTML(res.text)
# 解析出页面20条评论部分并返回,[:-1]是因为第一页解析出的div共22个,最后2个并不是评论内容,而之后的页面都只有21个div,所以下面的循环中使用try...except是为了剔除第一页的解析错误
return html.xpath('//div[@id="comments"]/div')[:-1]
def get_comments(comments_divs, i, percent_type):
'''
return:list
describe:对20条评论div进行解析,并返回字典形式的列表
'''
comments_list = []
for div in comments_divs:
try:
comment = {}
comment['评论类型'] = percent_type
comment['点赞数'] = div.xpath("./div[2]//span[@class='votes']/text()")[0]
comment['评分'] = div.xpath(
"./div[2]//span[@class='comment-info']/span[2]/@class")[0]
comment['发布日期'] = div.xpath(
"./div[2]//span[@class='comment-time ']/@title")[0]
comment['评论'] = div.xpath("./div[2]//span[@class='short']/text()")[0]
comments_list.append(comment)
except:
# 这边使用try...except是为了跳过解析错误的数据
continue
print(f"已经爬取{i+len(comments_list)}条评论")
return comments_list
if __name__ == '__main__':
# 创建空列表用以存储评论信息
comments = []
# 外层循环评论类类型
for percent_type in PERCENT_TYPE:
# 由于豆瓣网站限制,所以每种评论类型只可以爬取220条评论
for i in range(0, 220, 20):
url = BASE_URL.format(i, percent_type)
comments_divs = get_html_comments_divs(url, headers=headers)
comments_list = get_comments(comments_divs, i, percent_type)
comments.extend(comments_list)
# 随即沉睡1-5秒后继续循环,可以不设置,但是安全第一
sleep_time = random.uniform(1, 5)
print(f"沉睡{sleep_time}秒")
time.sleep(sleep_time)
影评分析
数据清洗
首先我们看一下爬取下来的数据。

总共5个维度,我们需要对数据做如下清洗:
- 将评论类型改为中文字符以方便理解
- 评分列进行拆分,获得1-5的数值
- 发布日期转为datetime类型
# 转换日期类型
data['发布日期']=pd.to_datetime(data['发布日期'])
# 替换评论类型
type_dict={"h":"好评","m":"中评","l":"差评"}
data['评论类型']=data['评论类型'].map(type_dict)
# 截取评分
data['评分']=data['评分'].replace(regex=True,inplace=False,to_replace=['allstar','0 rating'],value='').astype('int')
以下是我们清洗好的数据:
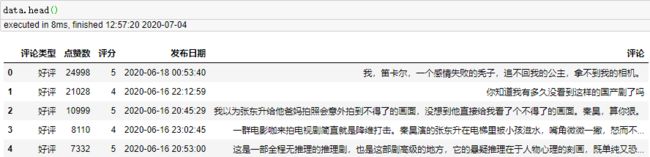
描述性分析
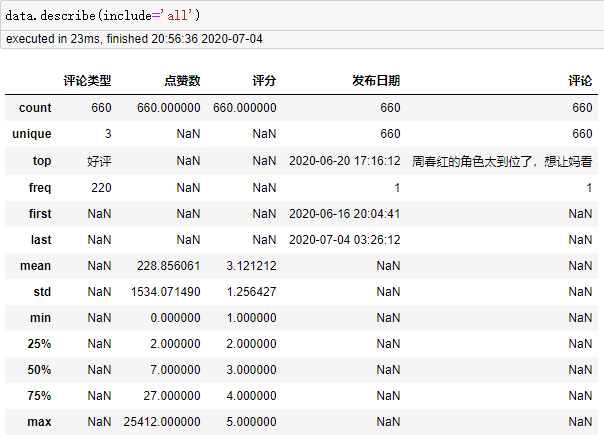
- 总共660条评论
- 一条评论最多的点赞数为25412
- 评分均值为3.12
- 评分发布日期跨度为2020/6/20-2020/7/4(可能会根据爬取日期有所变化)
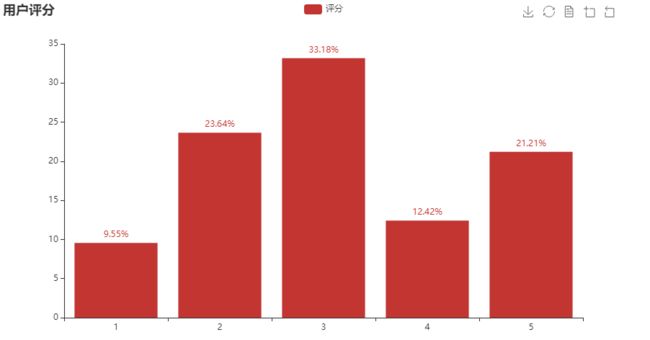
爬取下来660条评论里,33.18%的用户给了3星。其实从这个图上反应的现象是错误的,因为我们从好中差评中各爬取了220条,但是实际上就我爬取的日期而言,豆瓣上这部影片的评论数量已经接近17万。从豆瓣网上我们可以看出53.1%的用户给了好评,38.4%的用户给了差评。是因为样本大小不一样所以导致我们做出的图会与实际有所误差。

上图为爬取评论当天,豆瓣网官网显示的数据。
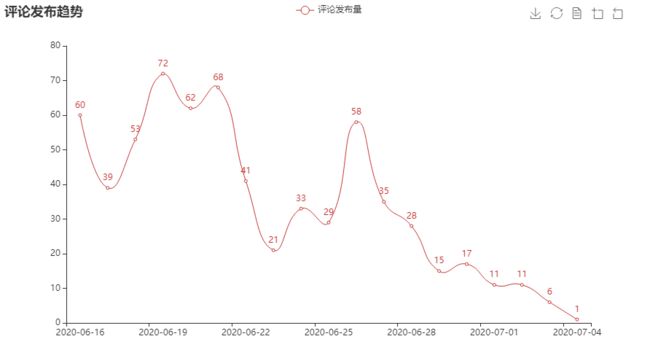
评论发布量整体呈现下降趋势。
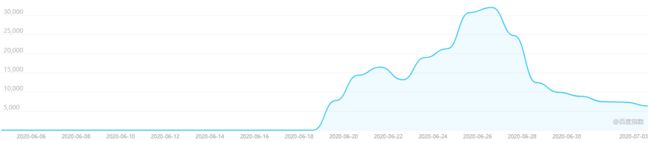
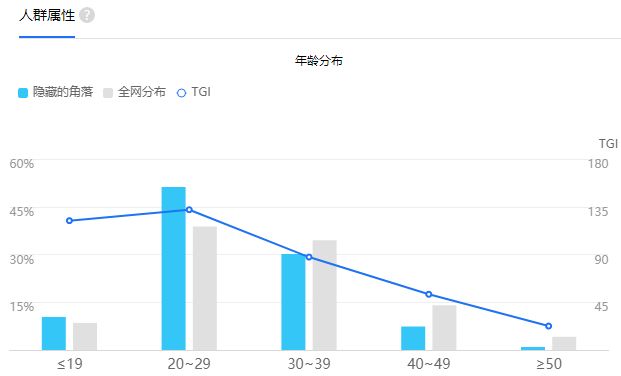
从百度指数来看,《隐秘的角落》在6月26日大结局上映后,搜索热度是下降的非常之快。从人群属性我们可以看出该剧主要的观众年龄分布为20-29岁,TGI且随着年龄增长而降低。
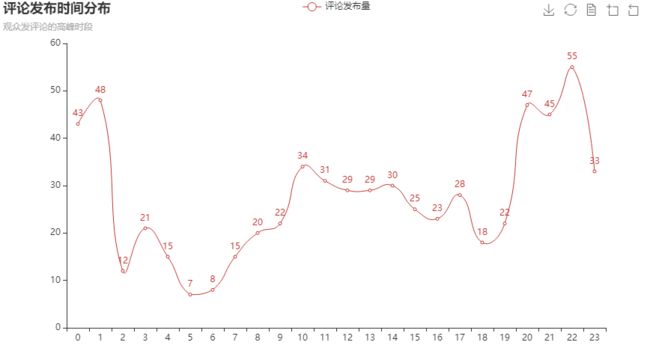
晚上10点和凌晨1点是发布评论的高峰期。夜猫子们小心猝死。
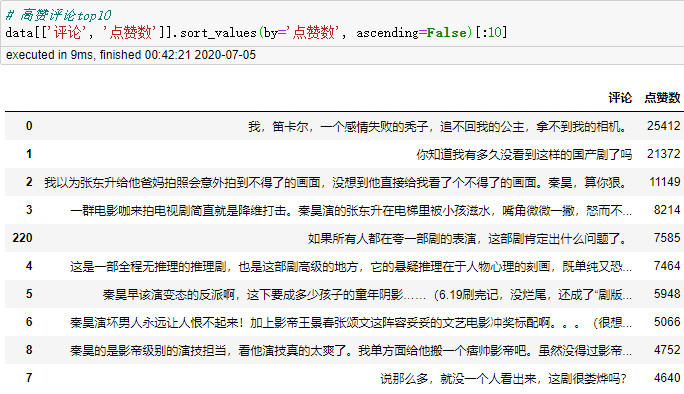
点赞数排名前10的评论。剧中张东升有提到笛卡尔的故事,而我满脑子却是百岁山的广告。
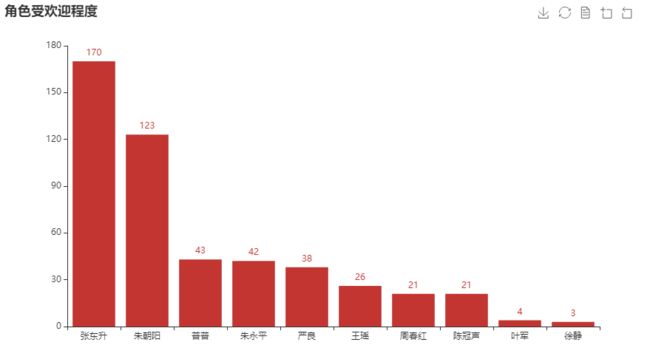
张东升以及朱朝阳是评论中出现最多的两个角色,毕竟一个是影帝一个是主角,而且剧中的对手戏及一些场景情感拿捏的确是漂亮。特别是朱朝阳和父亲出去吃甜品,发现父亲带了录音笔的那段戏,小朋友的演技相当不错。
词云图

看看这词云图,映入眼帘的是剧情、演员、孩子、国产剧及几个演员名字。可见观众们对于该剧的剧情争议较大,无论褒贬,都体现着国产剧的努力。影帝秦昊的表现毋庸置疑,他自己提出的秃头形象更是将张东升这个角色的悲惨狠辣体现的淋漓尽致。(第一眼让我想起了威虎山上的座山雕)
总结
《隐秘的角落》作为年中一部小说改编的影视剧来说可谓相当成功,国产剧质量一年比一年高,希望多出一些悬疑类的影片吧。
str = “自从关注了这个公众号,我的追求者排队到五环开外{}!”

str.format(,做梦)