超级文件夹管理器
一般10M以下的文件上传通过设置Web.Config,再用VS自带的FileUpload控件就可以了,但是如果要上传100M甚至1G的文件就不能这样上传了。我这里分享一下我自己开发的一套大文件上传控件供大家参考
控件功能:
1. 文件批量上传
此文件管理器支持文件批量上传。您可以上传30G及以上的大型文件,在上传过程中您不需要担心刷新网页造成的进度丢失问题。也不需要担心浏览器重启或崩溃,电脑重启等极端应用场景造成的进度丢失问题。文件管理器能够自动定时保存文件上传进度。以便为您提供更好的用户体验。
2. 文件夹批量上传
此文件管理器提供文件夹的批量上传功能。您可以同时上传一个或者多个文件夹,文件管理器会将这些文件夹以及他们的结构信息同时保存在服务器中。您不需要担心浏览器重启或崩溃造成的进度丢失的问题。
3. 文件批量下载
此文件管理器提供了文件批量下载功能。您现在可以同时下载多个文件,并将他们保存在本地指定的目录中。这一功能为图库应用场景,多资料共享应用场景提供了使用便利。
4. 文件夹批量下载
此文件管理器提供了文件夹的批量下载功能。您可以同时下载多个文件夹,这些文件夹下载完毕后,他们的层级信息也将会同时在本地保留。
5. 新建目录
此文件管理器提供了多层级目录管理功能。您现在可以根据需求新建目录。
6. 文件目录重命名。
7. 树型目录导航
8. 路径导航
9. 开源
此文件管理器是开款开源产品,无论您是个人还是企业都可以获取他的源代码来进行二次开发。我们为ASP.NET,JAVA,PHP等语言提供了示例,您可以同时选择这3种开发语言来进行项目开发。同时我们将提供长期的更新和维护服务,帮助企业节省后期的产品维护成本。
这是前端代码:
{{ message }}
这是部分报错信息

这是后台部分代码和截图:
文件上传完毕,f_complete.
文件初始化,f_create
文件块处理,f_post
文件夹上传完毕,fd_complete
文件夹初始化,fd_create
using System.Web;
using up6.db.model;
namespace up6.db.biz
{
///
/// 路径生成器基类
/// 提供文件或文件夹的存储路径
///
public class PathBuilder
{
///
/// 根级存储路径,
///
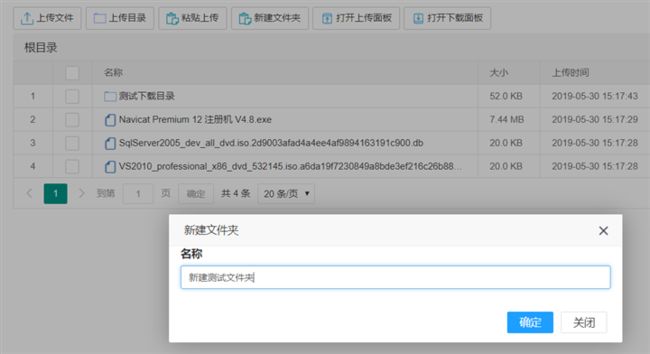
/// 新建文件夹
点击新建文件夹按钮,弹出此窗口,填写新建文件夹名称后点击确定
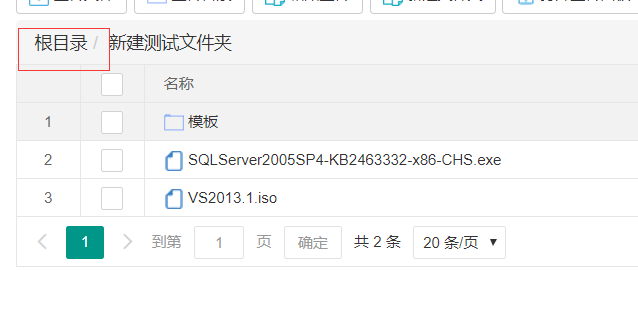
页面左上角出现刚刚新建的文件夹名称

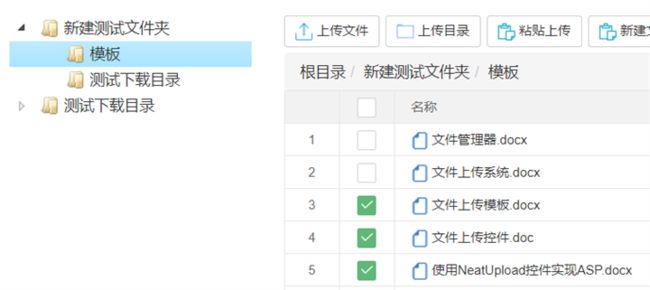
文件和文件夹批量上传上传功能,在新建文件夹目录内上传文件,选择多个文件或文件夹上传

如果上传的是文件夹,那么左侧的文件夹内会自动添加一个子文件夹,与上传的文件夹相符并可以展开查看文件夹内文件
在哪个目录下上传文件,文件就会存储在哪个目录下
点击根目录按钮可以返回根目录
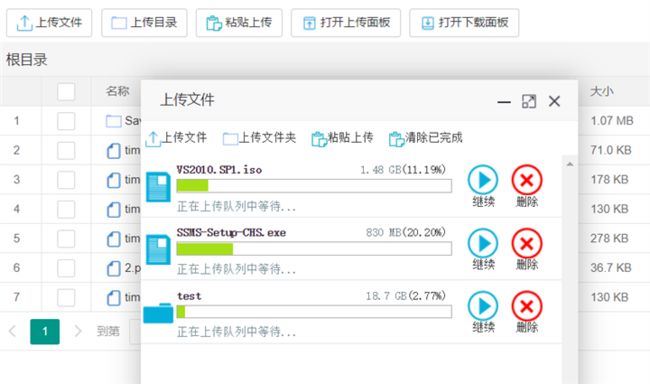
当网络问题导致传输错误时,只需要重传出错分片,而不是整个文件。另外分片传输能够更加实时的跟踪上传进度。
上传成功后打开我们的存储文件夹查看,发现自动生成了几个文件夹,打开文件夹确认上传文件成功

点击文件夹后的重命名按钮
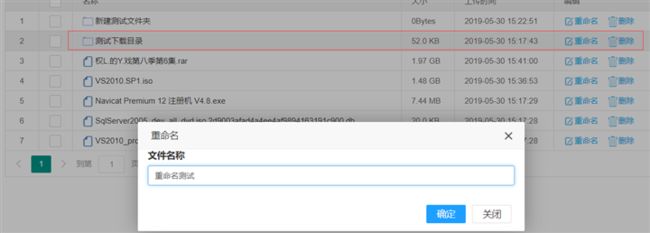
修改文件名后点击确定

页面左侧文件夹与页面中间的文件夹名称同时改变
文件及文件夹批量下载
这是下载所需的脚本截图和部分代码:

using System;
using System.IO;
using System.Web;
namespace up6.down2.db
{
public partial class f_down : System.Web.UI.Page
{
bool check_params(params string[] vs)
{
foreach(string v in vs)
{
if (String.IsNullOrEmpty(v)) return false;
}
return true;
}
protected void Page_Load(object sender, EventArgs e)
{
string id = Request.Headers["id"];//文件id
string blockIndex = Request.Headers["blockIndex"];//基于1
string blockOffset = Request.Headers["blockOffset"];//块偏移,相对于整个文件
string blockSize = Request.Headers["blockSize"];//块大小(当前需要下载的)
string pathSvr = Request.Headers["pathSvr"];//文件在服务器的位置
pathSvr = HttpUtility.UrlDecode(pathSvr);
if ( !this.check_params(id,blockIndex,blockOffset,pathSvr))
{
Response.StatusCode = 500;
return;
}
Stream iStream = null;
try
{
// Open the file.
iStream = new FileStream(pathSvr, FileMode.Open, FileAccess.Read, FileShare.Read);
iStream.Seek(long.Parse(blockOffset),SeekOrigin.Begin);//定位
// Total bytes to read:
long dataToRead = long.Parse(blockSize);
Response.ContentType = "application/octet-stream";
Response.AddHeader("Content-Length", blockSize );
int buf_size = Math.Min(1048576, int.Parse(blockSize));
byte[] buffer = new Byte[ buf_size];
int length;
while (dataToRead > 0)
{
// Verify that the client is connected.
if (Response.IsClientConnected)
{
// Read the data in buffer.
length = iStream.Read(buffer, 0, buf_size);
dataToRead -= length;
// Write the data to the current output stream.
Response.OutputStream.Write(buffer, 0, length);
// Flush the data to the HTML output.
Response.Flush();
}
else
{
//prevent infinite loop if user disconnects
dataToRead = -1;
}
}
}
catch (Exception ex)
{
Response.StatusCode = 500;
// Trap the error, if any.
Response.Write("Error : " + ex.Message);
}
finally
{
if (iStream != null)
{
//Close the file.
iStream.Close();
}
}
}
}
}选择上传后的文件夹内的子目录文件或文件夹下载
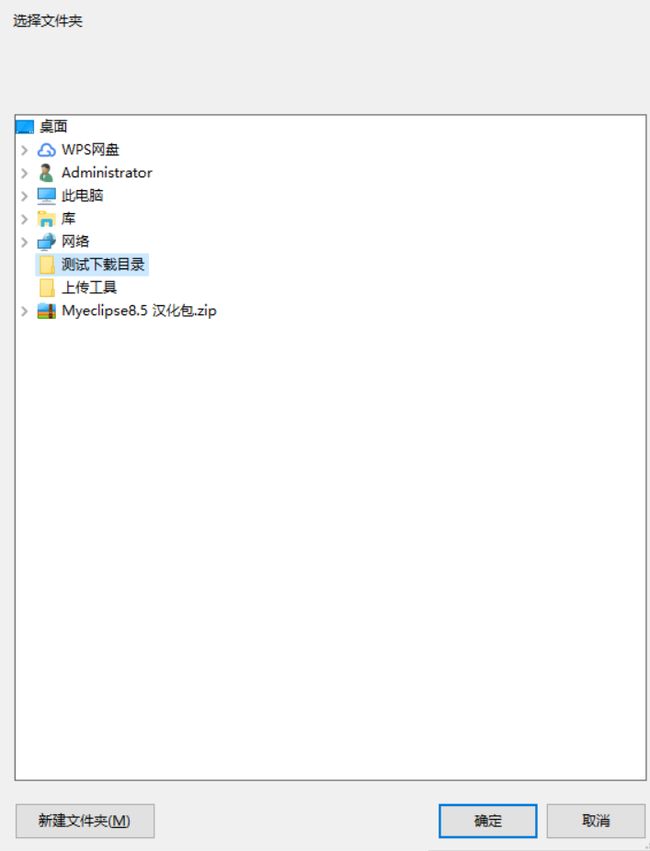
然后点击下载按钮,设置下载目录文件夹
设置完成后继续点击下载按钮,页面的右下角出现了下载面板,你选择的文件已出现在目录中,然后点击全部下载,或者单个点击继续,自动加载未上传完的任务。在刷新浏览器或重启电脑后任然可以自动加载未完成的任务
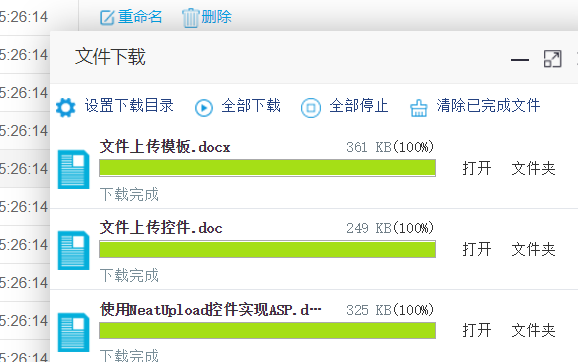
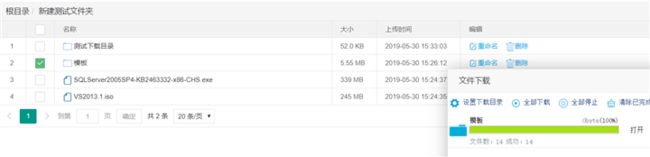
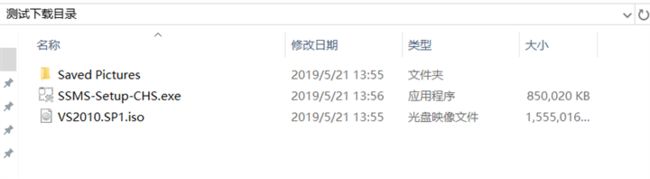
下载完成后打开我们设置的下载目录文件夹,发现需下载的文件或文件夹确认已下载成功,经确认文件夹内的内容与下载文件夹内容一致
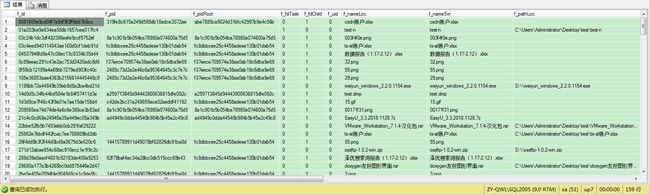
数据库记录
产品介绍官网:https://dwz.cn/fgXtRtnu