维特比算法代码
维特比算法实现python语言版
本文主要写一个关于维特比算法的代码,具体理论请参考一文搞懂HMM(隐马尔可夫模型):
HMM(隐马尔可夫模型)是用来描述隐含未知参数的统计模型,举一个经典的例子:一个东京的朋友每天根据天气{下雨,天晴}决定当天的活动{公园散步,购物,清理房间}中的一种,我每天只能在twitter上看到她发的推“啊,我前天公园散步、昨天购物、今天清理房间了!”,那么我可以根据她发的推特推断东京这三天的天气。在这个例子里,显状态是活动,隐状态是天气。
任何一个HMM都可以通过下列五元组来描述:
:param obs:观测序列
:param states:隐状态
:param start_p:初始概率(隐状态)
:param trans_p:转移概率(隐状态)
:param emit_p: 发射概率 (隐状态表现为显状态的概率)
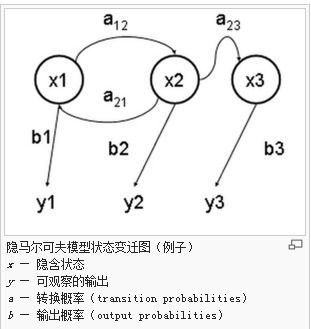
伪码如下:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}
... prompt'''求解最可能的天气:
求解最可能的隐状态序列是HMM的三个典型问题之一,通常用维特比算法解决。维特比算法就是求解HMM上的最短路径(-log(prob),也即是最大概率)的算法。
稍微用中文讲讲思路,很明显,第一天天晴还是下雨可以算出来:
定义V[时间][今天天气] = 概率,注意今天天气指的是,前几天的天气都确定下来了(概率最大)今天天气是X的概率,这里的概率就是一个累乘的概率了。
因为第一天我的朋友去散步了,所以第一天下雨的概率V[第一天][下雨] = 初始概率[下雨] * 发射概率[下雨][散步] = 0.6 * 0.1 = 0.06,同理可得V[第一天][天晴] = 0.24 。从直觉上来看,因为第一天朋友出门了,她一般喜欢在天晴的时候散步,所以第一天天晴的概率比较大,数字与直觉统一了。
从第二天开始,对于每种天气Y,都有前一天天气是X的概率 * X转移到Y的概率 * Y天气下朋友进行这天这种活动的概率。因为前一天天气X有两种可能,所以Y的概率有两个,选取其中较大一个作为V[第二天][天气Y]的概率,同时将今天的天气加入到结果序列中
比较V[最后一天][下雨]和[最后一天][天晴]的概率,找出较大的哪一个对应的序列,就是最终结果。
python代码如下:
# -*- coding: utf-8 -*-
from collections import defaultdict
states = ("Rainy", "Sunny")
observations = ("Walk", "Shop", "Walk", "Shop", "Clean", "Walk", "Shop", "Walk")
start_probability = {"Rainy": 0.6, "Sunny": 0.4}
transition_probability = {
"Rainy": {"Rainy": 0.7, "Sunny": 0.3},
"Sunny": {"Rainy": 0.4, "Sunny": 0.6},
}
emission_probability = {
"Rainy": {"Walk": 0.1, "Shop": 0.4, "Clean": 0.5},
"Sunny": {"Walk": 0.6, "Shop": 0.3, "Clean": 0.1},
}
# 利用动态规划求解最佳路径
def compute(obs, states, start_p, trans_p, emit_p):
# [{}, {}, {}] 长度与obs相同, 保存每条观测路径上面的各种天气的最佳概率
v = [{} for _ in range(len(obs))]
# {"state1": [], "state2": []} 长度与states 相同
path = defaultdict(list)
for state in states:
v[0][state] = start_p[state] * emit_p[state][obs[0]]
#path[state] = ["" for _ in range(len(obs))]
path[state].append(state)
# 以时间循环,从第一天开始循环
for t in range(1, len(obs)):
# print obs[t]
for y1 in states : # 从path中取路径,作为上一个开始的路径
max_prob = -1
for y0 in v[t-1]:
nprob = v[t - 1][y0] * trans_p[y0][y1] * emit_p[y1][obs[t]]
if nprob > max_prob:
# 暂时记录到y1状态节点最后的概率
max_prob = nprob
# 暂时记录到y1状态节点的上一个y0节点
max_state = y0
# 保存到当前的y1状态的最好的概率值
v[t][y1] = max_prob
# 到上一条路径与当前的y1链接起来,作为y1状态的最好路径
newpath = []
for state1 in path[max_state]:
newpath.append(state1)
newpath.append(y1)
path[y1] = newpath
# 寻找最终概率最大的路径
prob = -1
for y1 in states :
if v[len(obs) - 1][y1] > prob:
prob = v[len(obs) - 1][y1]
state = y1
# 返回路径最大的路径
return path[state]
if __name__ == "__main__":
max_path = compute(observations, states, start_probability,
transition_probability, emission_probability)
for state in max_path :
print state最终运行结果为:
Sunny
Sunny
Sunny
Rainy
Rainy
Rainy
Sunny
Sunny
Sunny
大部分抄来的,写得不好,请轻轻拍砖。