实例恢复(Instance Recovery)之前滚(Rolling Forward)和回滚(Rolling Back)
Oracle实例恢复(Instance Recovery)之前滚(Rolling Forward)和回滚(Rolling Back)

关于oracle实例恢复的一些理解,一直都有误区,今天通过查看相关资料和与同学探讨,发觉了自己的错误,探讨结果如下:
实例恢复:当数据库非正常关闭的时候(断电或者shu abort等等非一致性关闭),当你从新启动数据库的时候,数据库相关进程自动进行实例恢复,无须人工干预,
一. 什么时候需要实例恢复 在shutdown normal or shutdown immediate下,也就是所谓的 clean shutdown ,checkpoint也会自动触发,并且把SCN纪录写回。 当发生checkpoint时,会把SCN写到四个地方: 三个地方于control file内:
(1)SYSTEM CHECKPOINT SCN
(2)Datafile checkpoint SCN
(3)Stop SCN ---就是在实例一致性关闭的时候,更新 一个在datafile header内: Start SCN
正常open的状态下一致性的数据库,SYSTEM CHECKPOINT SCN,Datafile checkpoint SCN和数据文件头Start SCN的这三个SCN是一致,并且 储存在control file中的stop scn就会恢复为NULL值,
1.1 Clean shutdown 时
当clean shutdown 时, checkpoint会进行,并且 此时datafile的start scn和控制文件里的stop scn会相同 , 等到open 数据库 时,Oracle检查datafile header中的start scn和存于control file中的datafile的scn是否相同, 如果相同,接着检查datafile header中的start scn和control file中stop scn是否相同,如果仍然相同,数据库就会正常开启,否则就需要recovery。 等到数据库开启后,储存在control file中的stop scn就会恢复为NULL值 ,此时表示datafile是open在正常模式下了。
1.2 非正常shutdown
如果不正常SHUTDOWN (shutdown abort),则mount数据库后, 会发现stop scn并不是等于其它位置的scn, 而是等于NULL, 这表示Oracle在shutdown时没有进行checkpoint, 下次开机必须进行crash recovery(实例恢复) , 注意一点:
(1)启动数据库时,如果发现STOP SCN = NULL, 表示需要进行crash recovery;
(2)启动数据库时,如果发现有datafile header的START SCN 不等于储存于CONTROLFILE的DATAFILE SCN, 表示需要进行Media recovery
二 . 实例恢复的具体过程:
当数据库突然崩溃,而还没有来得及将buffer cache里的脏数据块刷新到数据文件里,同时在实例崩溃时正在运行着的事务被突然中断,则 事务为中间状态,也就是既没有提交也没有回滚 。这时数据文件里的内容不能体现实例崩溃时的状态。 这样关闭的数据库是不一致的 。 下次启动实例时,Oracle会由SMON进程自动进行实例恢复 。实例启动时,SMON进程会去检查控制文件中所记录的、每个在线的、可读写的数据文件的END SCN号。
数据库正常运行过程中 ,该END SCN号始终为NULL,而当数据库正常关闭时,会进行完全检查点,并将检查点SCN号更新该字段,所以可以通过END SCN号是否为null来判断是不是需要实例恢复。 而崩溃时,Oracle还来不及更新该字段,则该字段仍然为NULL 。当SMON进程发现该字段为空时,就知道实例在上次没有正常关闭,于是由SMON进程就开始进行实例恢复了。 SMON进程进行实例恢复时,会从控制文件中获得检查点位置 。于是,SMON进程到联机日志文件中,找到该检查点位置,然后从该检查点位置开始往下,应用所有的重做条目,从而在buffer cache里又恢复了实例崩溃那个时间点的状态。 这个过程叫做前滚 ,前滚完毕以后,buffer cache里既有崩溃时已经提交还没有写入数据文件的脏数据块,也还有事务被突然终止,而导致的既没有提交又没有回滚的事务所弄脏的数据块。 前滚一旦完毕,SMON进程立即打开数据库 。但是,这时的数据库中还含有那些中间状态的、既没有提交又没有回滚的脏块,这种脏块是不能存在于数据库中的,因为它们并没有被提交,必须被回滚。 打开数据库以后,SMON进程会在后台进行回滚。 有时,数据库打开以后,SMON进程还没来得及回滚这些中间状态的数据块时,就有用户进程发出读取这些数据块的请求。这时, 服务器进程在将这些块返回给用户之前,由服务器进程负责进行回滚, 回滚完毕后,将数据块的内容返回给用户。
三. 为什么数据库的实例恢复是先前滚再回滚
回滚段实际上也是以回滚表空间的形式存在的,既然是表空间,那么肯定就有对应的数据文件,同时在buffer cache 中就会存在映像块,这一点和其他表空间的数据文件相同。
当发生DML操作时,既要生成REDO(针对DML操作本身的REDO Entry)也要生成UNDO(用于回滚该DML操作,记录在UNDO表空间中),但是既然UNDO信息也是使用回滚表空间来存放的,那么该DML操作 对应的UNDO信息(在BUFFER CACHE生成对应中的UNDO BLOCK)就会首先生成其对应的REDO信息(UNDO BLOCK's REDO Entry)并写入Log Buffer中 。 这样做的原因 是因为Buffer Cache中的有关UNDO表空间的块也可能因为数据库故障而丢失 , 为了保障在下一次启动时能够顺利进行回滚,首先就必须使用REDO日志来恢复UNDO段 (实际上是先回复Buffer Cache中的脏数据块,然后由Checkpoint写入UNDO段中),在数据库OPEN以后再使用UNDO信息来进行回滚,达到一致性的目的。 生成完UNDO BLOCK's REDO Entry后才轮到该DML语句对应的REDO Entry,最后再修改Buffer Cache中的Block,该Block同时变为脏数据块。 实际上, 简单点说REDO的作用就是记录所有的数据库更改,包括UNDO表空间在内。
总结: 今天最重要的一点我知道了,所谓的前滚,是应用redo来恢复buffer cache的数据,将buffer cache恢复到crash之前状态,所以此时buffer cache 中既有崩溃时已经提交还没有写入数据文件的脏数据块,也还有事务被突然终止,而导致的既没有提交又没有回滚的事务所弄脏的数据块(也就是没有commit,但是dbwr已经将改变刷新到底层磁盘),还有一点是控制文件中还有一个 end scn,用来记录数据库正常关闭的时候的数据库文件头的scn,并且可以通过这个scn是否为null来判断需或者不需实例恢复。
保持数据一致性和完整性,是每一款成功商业数据库软件都必须要做到的基本要求。从故障中恢复,保证ACID原则,保证事务完整性,一直是Oracle数据库核心功能组成部分。本篇主要介绍Oracle实例意外终止(断电或者强制关闭)之后,重新启动时发生的恢复过程,也可以称作“前滚和回滚”。
基础知识说明
为了更明确的说明问题,笔者首先介绍一下本文涉及到的一些重要知识。
数据库实例失败
我们经常说的数据库服务器failure是有多层含义的。Oracle数据库是一个由多进程组件共同构成的结构体系。最重要的部分包括监听器、Oracle数据库实例两个部分,当然还包括各类文件,更广义的还有硬件和操作系统OS。不同部分的Failure现象和处理方法都有所不同。本文所阐述的过程是Oracle实例失败后的自动恢复过程。
在实例失败的时候,往往是突然性的终止。此时Oracle数据库可能在进行一系列完成或者未完成的事务。实例失败恢复,就是要将这些状态进行还原,恢复到数据完整性的状态。
写日志(Redo Log)在先机制
Oracle数据库是采用“日志在先”机制的。当我们对数据库数据进行修改时,并不是立即将修改写入到文件中,而是写入到共享内存SGA空间中的Buffer Cache里。同时,将修改的日志不断的写入到SGA中另一块Log Buffer缓存中。有一个后台进程LGWn不断的将Log Buffer缓存中的日志内容写入到online redo log文件中。
写入Log Buffer缓存和LGWn写入文件的过程是异步进行的。触发LGWn工作的时点有几个:
ü 用户进行直接的commit操作;
ü 日志进行切换;
ü 距离上次LGWn写入操作超过三秒;
ü Redo Buffer数据超过1/3或者超过1M大小;
ü DBWn启动,将Buffer Cache中的脏数据写入到文件中;
而数据文件写入进程DBWn工作的触发点,则比较平缓和低频率。
ü 当Buffer Cache中缺少用于写入数据的clean block的时候,DBWn会开始将一些脏块“Dirty Block”写入到文件中,清理出一些可以使用的Clean Block;
ü 周期性的CheckPoint写入,当CKPT进程进行检查点打入的时候,DBWn会启动进行写入;
综合DBWn和LGWn工作的特点,我们可以得到日志文件的几个特点:
首先,日志文件的写入是很频繁的。LGWn会不断将日志信息从Log Buffer中写入Online Redo Log;
其次,在日志文件上,可以有三个类型的事务事件。
1、事务结束,已经被commit,之后打过checkpoint检查点。这种事务记录在Log File上,但是变化信息已经被DBWn写入进数据文件;
2、事务结束,已经被commit,之后没有打入checkpint检查点。这种情况下,Log File已经写入了日志项目,数据文件可能包括脏数据,也可能没有写入脏数据;
3、事务未结束,没有commit。这种时候,数据块Dirty Block上面是有事务槽信息,表示未结束事务,是不会将数据写入到数据文件中。但是,日志Log Buffer可能将部分未提交的DML操作项目写入到Log File中;
检查点Checkpoint
检查点Checkpoint是数据库一致性检查的一个标记。简单的说,就是在这个点上,Oracle保证各个文件(数据、控制、日志等)是一致的。检查点的作用就是在进行实例恢复的时候,告诉SMON进程,这个点之前的内容不需要进行恢复。
前滚和回滚介绍
“前滚和回滚”是Oracle数据库实例发生意外崩溃,重新启动的时候,由SMON进行的自动恢复过程。下面通过模拟实例和讲解介绍这个过程。
失败前场景说明
日志中记录过程如下:
1、事务A进行之后,结束commit。之后系统进行了一次checkpoint A;
2、Checkpoint之后,进行事务B,结束commit;
3、进行事务C,C事务量较大,其中进行了一定量的Redo Log文件写入。之后系统断电;
1、系统启动过程,进入实例恢复阶段
当实例意外中断的时候,各类型文件,包括控制文件、数据文件和日志文件上,会存在不一致的问题。这种不一致主要体现在SCN值的差异上。
实例在启动的时候,经过三阶段(nomount、mount和open)。在open之前,会进行这种不一致现象的检查,如果出现不一致,要启动SMON进程的恢复流程。
SMON是Oracle实例的一个后台进程,主要负责进行系统监控恢复。进行恢复的依据主要是Redo Log记录。
2、前滚进程
SMON首先找到最后SCN记录的Redo Log File。寻找最后一个打入的Checkpoint。
顺序找到CheckPoint A之后,表示A之前的所有事务都是完全写入到数据文件中,不存在不一致性问题。恢复过程从Checkpoint A开始,Oracle开始依据重做日志Redo Log的系列条目,进行推进。
首先遇到了事务B信息,由于事务B已经commit,所以事务B所有相关的Redo Log条目已经全都写入到Redo Log File中。所以,按照日志继续条目推进,完全可以重演replay,并且应用apply事务B的全部过程。
这样,事务B全部实现,最终将通过DBWn完全写入到数据文件中。所以,实例失败之前提交commit的事务B,完全恢复。
进入事务C的范畴,由于一部分事务C的Redo Log条目已经进入Redo Log File中,所以在进行前滚的时候,一定会replay到这部分的内容。不过,这部分内容中不可能出现commit的标记。所以,前滚的结果一定是遇到实例突然中断的那个时点。此时replay的结果是,事务C没有提交。这样结束了前滚过程,进入回滚阶段。
3、回滚过程
对事务C,要进行回滚过程,释放所有相关资源。从Undo空间中寻找到旧版本SCN的数据块信息,来进行SGA中Buffer Cache数据块恢复。
4、说说恢复过程的损耗
很多时候,由于我们事务规模较大,当出现实例崩溃的时候,重启所需要的时间很多。有一种经验说法是,事务有多长,前滚和回滚所消耗的时间有多长×2。而且,如果不能完成SMON恢复过程,数据库是不能算作正常的Open的。
SMON的恢复过程是Oracle强制进行的一个过程,即使恢复中发生断电或者其他中断失败事件。Oracle在下一次启动的时候,还是会继续这个过程,只有耐心等待。
通过检查一些内部视图(X$视图),可以观察到恢复进程和速度,但是丝毫不能影响到最终恢复的过程。
这个过程虽然可以保证数据一致性,但是也带来了系统不能启动,影响生产环境的问题。我们可以通过两个方式进行缓解:
首先,我们在设计开发系统时,要保证事务规模的可控性,不要让事务规模在技术层面上过大。避免一旦发生崩溃,大规模强制回滚的发生;
其次,一旦出现了这个强制回滚,要注意对生产环境的影响。可以采用备库standby进行顶替,让主库安静的慢慢恢复;
官方文档地址:http://docs.oracle.com/cd/E11882_01/server.112/e40540/startup.htm#CNCPT1290
Overview of Instance Recovery
Instance recovery is the process of applying records in the online redo log to data files to reconstruct changes made after the most recent checkpoint. Instance recovery occurs automatically when an administrator attempts to open a database that was previously shut down inconsistently.
实例恢复概述
实例恢复是将联机重做日志中的记录应用到数据文件,以重建最近检查点之后所做更改的过程。当管理员尝试打开一个之前以不一致方式关闭的数据库时,会自动执行实例恢复。
Purpose of Instance Recovery
Instance recovery ensures that the database is in a consistent state after an instance failure. The files of a database can be left in an inconsistent state because of how Oracle Database manages database changes.
A redo thread is a record of all of the changes generated by an instance. A single-instance database has one thread of redo, whereas an Oracle RAC database has multiple redo threads, one for each database instance.
When a transaction is committed, log writer (LGWR) writes both the remaining redo entries in memory and the transaction SCN to the online redo log. However, the database writer (DBW)process writes modified data blocks to the data files whenever it is most efficient. For this reason, uncommitted changes may temporarily exist in the data files while committed changes do not yet exist in the data files.
If an instance of an open database fails, either because of a SHUTDOWN ABORT statement or abnormal termination, then the following situations can result:
-
Data blocks committed by a transaction are not written to the data files and appear only in the online redo log. These changes must be reapplied to the database.
-
The data files contains changes that had not been committed when the instance failed. These changes must be rolled back to ensure transactional consistency.
Instance recovery uses only online redo log files and current online data files to synchronize the data files and ensure that they are consistent.
See Also:
-
"Database Writer Process (DBWn)" and "Database Buffer Cache"
-
"Introduction to Data Concurrency and Consistency"
实例恢复的目的
实例恢复可确保数据库在一个实例失败后仍能回到一个一致的状态。由于oracle数据库对数据文件更改的管理方式所致,数据库的文件可以处于不一致的状态。
重做线程是对实例生成的所有更改的记录。单实例数据库拥有一个重做线程,而一个Oracle RAC数据库拥有多个重做线程——每个数据库实例有一个。
当事务提交时,日志写入器(LGWR)将内存中的重做条目和事务SCN同时写入联机重做日志。但是,数据库写入器(DBWn)进程只在最有利的时机将已修改的数据块写入数据文件。由于这个原因,未提交的更改可能会暂时存在于数据文件中,而已提交的更改也可能还不在数据文件中。
如果某个打开的数据库的实例失败,或者由于SHUTDOWN ABORT语句或异常终止,则可能会导致下列情况:
l由某事务已提交的数据块更新还未写入数据文件,而仅写入了联机重做日志中。这些更改必须重新应用到数据库。
l数据文件包含实例失败时尚未提交的更改。这些更改必须回滚,以确保事务一致性。
实例恢复只使用联机重做日志文件和当前在线的数据文件,以同步数据文件,并确保它们一致。
When Oracle Database Performs Instance Recovery
Whether instance recovery is required depends on the state of the redo threads. A redo thread is marked open in the control file when a database instance opens in read/write mode, and is marked closed when the instance is shut down consistently. If redo threads are marked open in the control file, but no live instances hold the thread enqueues corresponding to these threads, then the database requires instance recovery.
Oracle Database performs instance recovery automatically in the following situations:
-
The database opens for the first time after the failure of a single-instance database or all instances of an Oracle RAC database. This form of instance recovery is also called crash recovery. Oracle Database recovers the online redo threads of the terminated instances together.
-
Some but not all instances of an Oracle RAC database fail. Instance recovery is performed automatically by a surviving instance in the configuration.
The SMON background process performs instance recovery, applying online redo automatically. No user intervention is required.
See Also:
-
"System Monitor Process (SMON)"
-
Oracle Real Application Clusters Administration and Deployment Guide to learn about instance recovery in an Oracle RAC database
Oracle数据库何时执行实例恢复
是否需要实例恢复取决于重做线程的状态。在数据库实例被打开为读/写模式时,重做线程在控制文件中被标记为打开,而当实例被一致关闭时,重做线程被标记为关闭。如果重做线程在控制文件中被标记为打开,但没有活动的实例持有对应于这些线程的线程队列,则数据库将需要实例恢复。
oracle数据库在以下情况下自动执行实例恢复:
·单实例数据库或Oracle RAC数据库的所有实例失败后第一次打开数据库。这种形式的实例恢复也称为崩溃恢复。Oracle数据库一起恢复所有已终止实例的联机重做线程。
·只是Oracle RAC数据库中的某些、但不是所有实例失败。实例恢复将由配置中的某个存活实例自动进行。
SMON后台进程自动执行实例恢复并应用联机重做记录。而不需要任何用户干预。
Importance of Checkpoints for Instance Recovery
Instance recovery uses checkpoints to determine which changes must be applied to the data files. The checkpoint position guarantees that every committed change with an SCN lower than the checkpoint SCN is saved to the data files.
Figure 13-5 depicts the redo thread in the online redo log.
Figure 13-5 Checkpoint Position in Online Redo Log
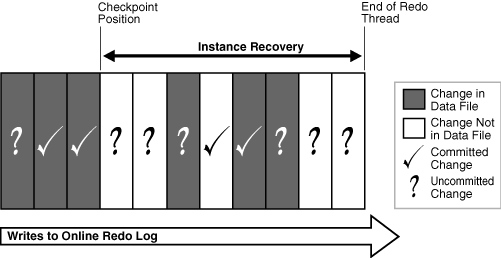
Description of "Figure 13-5 Checkpoint Position in Online Redo Log"
During instance recovery, the database must apply the changes that occur between the checkpoint position and the end of the redo thread. As shown in Figure 13-5, some changes may already have been written to the data files. However, only changes with SCNs lower than the checkpoint position are guaranteed to be on disk.
See Also:
Oracle Database Performance Tuning Guide to learn how to limit instance recovery time实例恢复检查点的重要性
实例恢复使用检查点来确定必须将哪些更改应用到数据文件。检查点位置始终保证所有比其SCN低的检查点所对应的已提交更改都已保存到数据文件。
图13-5描述了联机重做日志中的重做线程。
图13-5联机重做日志中的检查点位置
实例恢复期间,数据库必须应用检查点位置和重做线程结尾之间发生的更改。如图13-5所示,某些更改可能已经写入数据文件。但是,只有其SCN低于检查点位置的更改,才保证已被写到了磁盘上。
Instance Recovery Phases
The first phase of instance recovery is called cache recovery or rolling forward, and involves reapplying all of the changes recorded in the online redo log to the data files. Because rollback data is recorded in the online redo log, rolling forward also regenerates the corresponding undo segments.
Rolling forward proceeds through as many online redo log files as necessary to bring the database forward in time. After rolling forward, the data blocks contain all committed changes recorded in the online redo log files. These files could also contain uncommitted changes that were either saved to the data files before the failure, or were recorded in the online redo log and introduced during cache recovery.
After the roll forward, any changes that were not committed must be undone. Oracle Database uses the checkpoint position, which guarantees that every committed change with an SCN lower than the checkpoint SCN is saved on disk. Oracle Database applies undo blocks to roll back uncommitted changes in data blocks that were written before the failure or introduced during cache recovery. This phase is called rolling back or transaction recovery.
Figure 13-6 illustrates rolling forward and rolling back, the two steps necessary to recover from database instance failure.
Figure 13-6 Basic Instance Recovery Steps: Rolling Forward and Rolling Back
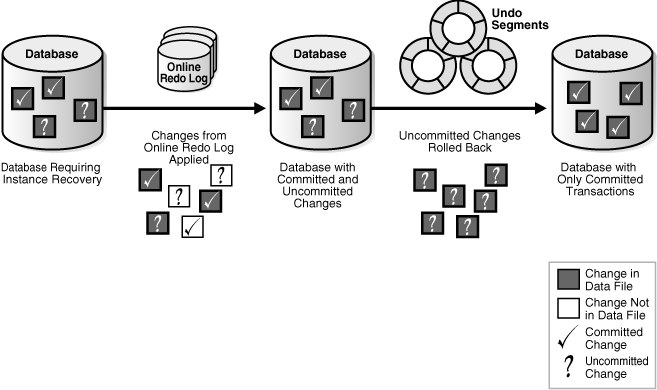
Description of "Figure 13-6 Basic Instance Recovery Steps: Rolling Forward and Rolling Back"
Oracle Database can roll back multiple transactions simultaneously as needed. All transactions that were active at the time of failure are marked as terminated. Instead of waiting for the SMON process to roll back terminated transactions, new transactions can roll back individual blocks themselves to obtain the required data.
See Also:
-
"Undo Segments" to learn more about undo data
-
Oracle Database Performance Tuning Guide for a discussion of instance recovery mechanics and tuning
实例恢复阶段
实例恢复的第一阶段称为缓存恢复或前滚,这涉及将联机重做日志中记录的所有更改重新应用到数据文件。因为回滚数据记录在联机重做日志中,前滚也会重新生成相应的撤消段。
前滚会遍历各个必要的联机重做日志,以将数据库推进到一个更前的一致时间点。前滚之后,数据块包含记录在联机重做日志文件中的所有已提交更改。这些文件可能还包含未提交的更改,要么是在实例失败前保存到数据文件中的,或者是在缓存恢复过程中引入的。
前滚之后,任何未提交的更改必须被撤消。oracle数据库使用检查点位置,保证每个低于其SCN的已提交更改都已保存到磁盘。oracle数据库应用撤消块,以回滚数据块中在实例失败前写入的或缓存恢复过程中引入的未提交更改。这一阶段称为回滚或事务恢复。
图 13-6 说明了前滚和回滚,这是恢复数据库实例失败的两个必要步骤。
oracle数据库可以根据需要同时回滚多个事务。实例失败时的所有活动事务被标记为终止。新事务可以自己回滚个别块以获取所需的数据,而不必等待SMON进程来回滚这些已终止的事务。
3.8.1 实例恢复
对于单实例的系统,实例恢复一般是在数据库实例异常故障后数据库重启时进行,当数据库执行了SHUTDOWN ABORT或者由于操作系统、主机等原因宕机重启后,在执行ALTER DATABASE OPEN的时候,就会自动做实例恢复。而在RAC环境中,如果某个实例宕机了,那么剩下的实例将会代替宕掉的实例做实例恢复。除非是所有的实例都宕机了,这样的话,第一个执行ALTER DATABASE OPEN的实例将会做实例恢复。这也是在RAC环境中,REDO LOG是实例私有的组件,但是REDO LOG的文件必须存放在共享存储上的原因。
一、 RAC中的实例恢复一个单实例数据库或者RAC数据库所有实例失败之后,第一个打开数据库的实例会自动执行实例恢复。这种形式的实例恢复称为Crash恢复。一个RAC数据库的一部分但不是所有实例失败后,在RAC中幸存的实例自动执行失败实例的恢复称为实例恢复。一般而言,在崩溃或关机退出之后第一个打开数据库的实例将自动执行崩溃恢复。
根据Crash恢复和实例恢复的不同,由幸存实例或者第一个重启的实例读取失败实例生成的联机Redo日志和UNDO表空间数据,使用这些信息确保只有已提交的事务被写到数据库中,回滚在失败时候活动的事务,并释放事务使用的资源。
| [ZFZHLHRDB1:oracle]:/oracle>crsctl stat res -t -------------------------------------------------------------------------------- NAME TARGET STATE SERVER STATE_DETAILS -------------------------------------------------------------------------------- Local Resources -------------------------------------------------------------------------------- ora.DATA.dg ONLINE ONLINE zfzhlhrdb1 ONLINE ONLINE zfzhlhrdb2 ora.LISTENER.lsnr ONLINE ONLINE zfzhlhrdb1 ONLINE ONLINE zfzhlhrdb2 ora.LISTENER_LHRDG.lsnr ONLINE ONLINE zfzhlhrdb1 ONLINE ONLINE zfzhlhrdb2 ora.asm ONLINE ONLINE zfzhlhrdb1 Started ONLINE ONLINE zfzhlhrdb2 Started ora.gsd OFFLINE OFFLINE zfzhlhrdb1 OFFLINE OFFLINE zfzhlhrdb2 ora.net1.network ONLINE ONLINE zfzhlhrdb1 ONLINE ONLINE zfzhlhrdb2 ora.ons ONLINE ONLINE zfzhlhrdb1 ONLINE ONLINE zfzhlhrdb2 ora.registry.acfs ONLINE ONLINE zfzhlhrdb1 ONLINE ONLINE zfzhlhrdb2 -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE zfzhlhrdb1 ora.cvu 1 ONLINE ONLINE zfzhlhrdb1 ora.lhrdb.db 1 ONLINE ONLINE zfzhlhrdb1 Open ora.oc4j 1 ONLINE ONLINE zfzhlhrdb1 ora.raclhr.db 1 ONLINE ONLINE zfzhlhrdb2 Open 2 ONLINE ONLINE zfzhlhrdb1 Open ora.scan1.vip 1 ONLINE ONLINE zfzhlhrdb1 ora.zfzhlhrdb1.vip 1 ONLINE ONLINE zfzhlhrdb1 ora.zfzhlhrdb2.vip 1 ONLINE ONLINE zfzhlhrdb2 [ZFZHLHRDB1:oracle]:/oracle>srvctl stop instance -d raclhr -i raclhr1 -o abort [ZFZHLHRDB1:oracle]:/oracle>srvctl status db -d raclhr Instance raclhr1 is not running on node zfzhlhrdb1 Instance raclhr2 is running on node zfzhlhrdb2 |
abort掉实例1后:
实例一的告警日志:
| Thu Oct 13 15:51:30 2016 Shutting down instance (abort) License high water mark = 60 USER (ospid: 4194780): terminating the instance Instance terminated by USER, pid = 4194780 Thu Oct 13 15:51:32 2016 Instance shutdown complete |
实例二的告警日志:
| Thu Oct 13 15:51:31 2016 Reconfiguration started (old inc 4, new inc 6) List of instances: 2 (myinst: 2) Global Resource Directory frozen * dead instance detected - domain 0 invalid = TRUE Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Thu Oct 13 15:51:31 2016 LMS 0: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Oct 13 15:51:31 2016 LMS 1: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Set master node info Submitted all remote-enqueue requests Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted Post SMON to start 1st pass IR Thu Oct 13 15:51:31 2016 Instance recovery: looking for dead threads Submitted all GCS remote-cache requests Post SMON to start 1st pass IR Fix write in gcs resources Reconfiguration complete Beginning instance recovery of 1 threads parallel recovery started with 7 processes Started redo scan Completed redo scan read 18 KB redo, 14 data blocks need recovery Started redo application at Thread 1: logseq 235, block 68352 Recovery of Online Redo Log: Thread 1 Group 1 Seq 235 Reading mem 0 Mem# 0: +DATA/raclhr/onlinelog/group_1.362.916601361 Mem# 1: +DATA/raclhr/onlinelog/group_1.361.916601361 Completed redo application of 0.01MB Completed instance recovery at Thread 1: logseq 235, block 68389, scn 9725527 14 data blocks read, 14 data blocks written, 18 redo k-bytes read Thu Oct 13 15:51:33 2016 minact-scn: Inst 2 is now the master inc#:6 mmon proc-id:25100420 status:0x7 minact-scn status: grec-scn:0x0000.00000000 gmin-scn:0x0000.009417d9 gcalc-scn:0x0000.009417e3 minact-scn: master found reconf/inst-rec before recscn scan old-inc#:6 new-inc#:6 Thread 1 advanced to log sequence 236 (thread recovery) Redo thread 1 internally disabled at seq 236 (SMON) Thu Oct 13 15:51:34 2016 Thread 2 advanced to log sequence 265 (LGWR switch) Current log# 4 seq# 265 mem# 0: +DATA/raclhr/onlinelog/group_4.349.916601715 Current log# 4 seq# 265 mem# 1: +DATA/raclhr/onlinelog/group_4.348.916601715 Thu Oct 13 15:51:35 2016 Archived Log entry 493 added for thread 1 sequence 235 ID 0x441b1480 dest 1: Thu Oct 13 15:51:35 2016 ARC0: Archiving disabled thread 1 sequence 236 Archived Log entry 494 added for thread 1 sequence 236 ID 0x441b1480 dest 1: Thu Oct 13 15:51:35 2016 Archived Log entry 495 added for thread 2 sequence 264 ID 0x441b1480 dest 1: minact-scn: master continuing after IR |
About Me
...............................................................................................................................
● 本文整理自网络
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-06-02 09:00 ~ 2017-06-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。





来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2140915/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26736162/viewspace-2140915/