机器学习也会“标题党”?这个算法能根据标题判断新闻类别

全文共3624字,预计学习时长19分钟

图源:unsplash
语言处理中的大多数分类情况是通过监督式机器学习完成的,在该过程中,我们将与某种正确输出相关联的输入观测数据集称作监督信号。任何分类算法的目的都是学习如何将一个新的观测值映射到正确输入中。
分类算法的任务是获取一组输入x和一组输出类别Y,并返回预测类别y ∈(属于) Y。在文本分类中,输入x通常用字母d表示,代表“documents”(文档),输出Y通常用字母c表示,代表“classes”(类),这种表达方式沿用至今。文档中的单词通常被称为“features”(特征)。
用于构建分类器的算法有许多种,但本文讨论的是朴素贝叶斯算法。同时,依据不同的特征和类别,这种算法也有很多变式。其中,符合分类目的的变式为多项式型。
朴素贝叶斯法是一种基于概率的分类器,能够得出观察结果在类别中出现的概率。也就是说,我们会用公式计算c类别每项特征的出现频率(这个我后面马上会讲到),最后选择最高概率项,并由此得出类别。
初始公式为:
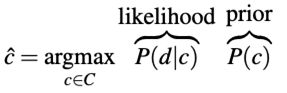
先验概率P(c)的计算方式为,在所有训练数据文档中,c类文档所占的百分比。
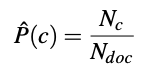
其中Nc为数据中c类文档总数,而Ndoc为文档总数。
由于文档d表示为一组特征(单词)w,因此类别中每个单词的初始似然函数公式为:
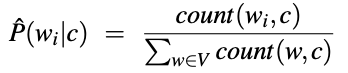
这表示,可能性等于c类中给定单词w-i的总数和c类中所有w单词的总数间的分数值。
然而,该方法存在一个缺陷。如果计算一个单词的出现概率,该单词在词汇表V中,但不在特定类别中,则该对的概率将为0。但由于我们将所有特征似然相乘,零概率将导致整个类别的概率也为零。
对此,我们需要添加一种平滑技术。平滑技术在语言处理算法中十分受欢迎。无需投入过多,使用拉普拉斯发明的一项技术(Laplace),它可以在计算中添加+1。公式最终将变为这样:
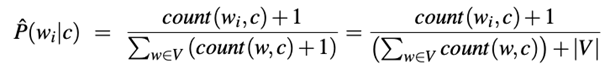
其中,V是单词类型的集合。单词类型为文档中出现的唯一单词的列表。
此外,为避免下溢出并提升速度,语言处理计算在logspace函数中完成。朴素贝叶斯算法与此同理。因此,初始公式变为:
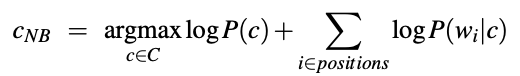

Python中多项式朴素贝叶斯算法的本机实践
作为一种流行的分类算法,很多软件包都可为朴素贝叶斯算法提供支持。我们将完全使用本机实现方式达到目的。输入新闻标题,看看朴素贝叶斯算法是如何预测新闻类别的?

图源:unsplash
前提
在Python3.x环境中开发脚本。利用Numpy包进行数组操作,并使用Pandas来管理数据。数据的使用将在“与数据打交道”部分中进行解释。
训练
训练/建立/拟合机器学习模型意味着使用某个数据集来生成信息,然后使用这些信息进行预测。依据目标,训练方法旨在执行机器算法,该算法可能简单、可能复杂。在我们的事例中,该方法将执行上述公式,并生成用于预测的必要数据,例如概率、似然和词汇表。
训练将在fit()函数中被完成。在fit函数方法中,假设文档和类别在两个单独的矢量中给出,并通过索引维持联系。在该方法中,也能生成词汇表。
建立词汇表
在我们的算法中,需要两种词汇表。其一是所有唯一单词类型的列表,称作整体词汇表;另一个是特定类别词汇表,包含一个词典中各类的文档词汇。
生成各词汇表的执行方法为:
defbuildGlobalVocab(self): vocab = [] for doc in self.docs: vocab.extend(self.cleanDoc(doc)) return np.unique(vocab) defbuildClassVocab(self, _cls): curr_word_list = [] for idx, doc inenumerate(self.docs): if self.classes[idx] == _cls: curr_word_list.extend(self.cleanDoc(doc)) if _cls notinself.class_vocab: self.class_vocab[_cls]=curr_word_list else: self.class_vocab[_cls].append(curr_word_list)
在这些方法中,我们使用了一种自定义方法cleanDoc,来处理各个文档。目前,在语言处理算法中,清理方法可能包括删除 the和a这样的停止词,这是很常见的。但在这里,删除停止词并不能提升性能,我们唯一要做的清理是删除文档标点、将字母小写并用空格分隔开。
@staticmethod defcleanDoc(doc): return re.sub(r [^a-zd ] , , doc.lower()).split( )
在使用fit函数方法的过程中,我们从类别表中获得唯一项目的列表。然后迭代该列表,并为每个唯一类别生成logprior,构建类词汇表,针对在整体词汇表中的单词,只需检查当前类别和词汇表中的计数器即可。在单词迭代内部,我们解决了单词-类别对的对数似然函数值。
我们将logprior、类别词汇表和对数似然函数值之类的信息保存在字典中。为获取单词计数,使用Counter计数器collection模块。
完整fit()函数方法如下:
deffit(self, x, y): self.docs = x self.classes = y num_doc =len(self.docs) uniq_cls = np.unique(self.classes) self.vocab = self.buildGlobalVocab() vocab_cnt =len(self.vocab) for _cls in uniq_cls: cls_docs_num = self.countCls(_cls) self.logprior[_cls] = np.log(cls_docs_num/num_doc) self.buildClassVocab(_cls) class_vocab_counter =Counter(self.class_vocab[_cls]) class_vocab_cnt =len(self.class_vocab[_cls]) for word in self.vocab: w_cnt =class_vocab_counter[word] self.loglikelihood[word, _cls] = np.log((w_cnt +1)/(class_vocab_cnt+ vocab_cnt))
测试
测试/预测方法包含一种可以评估我们训练出的模型的算法。
本例中,对于测试文档中每个唯一类别和单词,我们都寻找此类配对的先前概率,并将其添加到该类别概率的总和中,该总和与其所属类别的logprior值一起被初始化。最终,从所有总和中得到最大值,然后将其缩小至一类。
我们已将该逻辑与预测方法进行了适配。
defpredict(self,test_docs): output = [] for doc in test_docs: uniq_cls = np.unique(self.classes) sum =dict() for _cls in uniq_cls: sum[_cls] =self.logprior[_cls] for word in self.cleanDoc(doc): if word in self.vocab: try: sum[_cls] +=self.loglikelihood[word, _cls] except: print(sum, _cls) result = np.argmax(list(sum.values())) output.append(uniq_cls[result]) return output
与数据打交道
发现(和生成)一个用于数据分析的良好数据集本身就是一门学科。且数据集可能会不平均,可能拥有过多或过少数据。你可能过拟合或欠拟合数据,但本文我们不会对数据进行预处理。

图源:unsplash
为预测新闻类别,我们将使用新闻聚合器数据集,该数据集由加利福尼亚大学尔湾分校(UCI)(自2014年3月10日到8月10日)开发,涵盖约40万行分为几个专栏的新闻,包括标题和类别。
新闻类型主要有“商业”、“科技”、“娱乐”、“健康”四类,分别标记为b、t、 e、 m。
使用Pandas读取数据,并把数据集划分为训练数据和测试数据。我们还将自定义电子阅读器方法,来接受有关即将读取的数据大小和拆分率的参数。
defreadFile(self, size =70000, testSize =0.3): lines = pd.read_csv("data/news_aggregator.csv", nrows = size); x = lines.TITLE y = lines.CATEGORY skip =round(size * (1- testSize)) x_train, y_train, x_test, y_test = x[:skip],y[:skip], x[skip:size], y[skip:size] print( Train data: , len(x_train), Testing data: , len(x_test), Total: , len(x)) return x_train, y_train,x_test, y_test
使用上述所有方法
将上述所有方法一起使用,获取数据、训练分类器并使用测试数据对分类器进行测试。最后,检测分类准确率得分。
defmain(self): x_train, y_train, x_test, y_test = self.readFile(size =50000, testSize=0.3) nb =MultinominalNB() nb.fit(x_train, y_train) predictions = nb.predict(x_test) print( Accuracy: , self.accuracy(predictions,y_test))

训练结果
在该模型中,我们训练了35000个文档,测试了15000个其他文档,达到了82.9%的分类准确率得分,这非常好。
为避免每次预测时都训练模型,可以对生成的数据进行加工。辅助方法为:
defsaveModel(self): try: f =open("models/classifier", "wb") pickle.dump([self.logprior,self.vocab, self.loglikelihood, self.classes], f) f.close() except: print( Error savingthe model ) @staticmethod defreadModel(): try: f =open("models/classifier", "rb") model = pickle.load(f) f.close() return model except: print( Error readingthe model )
因而完整的fit函数和预测方法变为:
deffit(self, x, y,save =False): self.docs = x self.classes = y num_doc =len(self.docs) uniq_cls = np.unique(self.classes) self.vocab = self.buildGlobalVocab() vocab_cnt =len(self.vocab) t =time() for _cls in uniq_cls: cls_docs_num = self.countCls(_cls) self.logprior[_cls] = np.log(cls_docs_num/num_doc) self.buildClassVocab(_cls) class_vocab_counter =Counter(self.class_vocab[_cls]) class_vocab_cnt =len(self.class_vocab[_cls]) for word in self.vocab: w_cnt =class_vocab_counter[word] self.loglikelihood[word, _cls] = np.log((w_cnt +1)/(class_vocab_cnt+ vocab_cnt)) if save: self.saveModel() print( Trainingfinished at {} mins. .format(round((time() - t) /60, 2))) defpredict(self,test_docs,cached =False): output = [] ifnot cached: logprior = self.logprior vocab = self.vocab loglikelihood = self.loglikelihood classes = self.classes else: logprior, vocab, loglikelihood, classes = self.readModel() for doc in test_docs: uniq_cls = np.unique(classes) sum =dict() for _cls in uniq_cls: sum[_cls] = logprior[_cls] for word in self.cleanDoc(doc): if word in vocab: try: sum[_cls] +=loglikelihood[word, _cls] except: print(sum, _cls) result = np.argmax(list(sum.values())) output.append(uniq_cls[result]) return output
且执行变为:
defmain(self): x_train, y_train, x_test, y_test = self.readFile(size =50000, testSize=0.3) nb =MultinominalNB() """ Run the code below the first time you runthe script nb.fit(x_train,y_train, save = True) """ predictions = nb.predict([ Google launchesa new app. ], cached =True) print(predictions)
这样就建立了一个能够预测新闻标题类别的模型。
替代法

图源:unsplash
前文也提到了,朴素贝叶斯不少软件包的支持。其中最常见的一个软件包便是Sklearn。它支持所有类型的朴素贝叶斯分类算法。处理多项式算法时,Sklearn用作为数据编码器的CountVectorizer转换输入形式,从而缩短训练和测试时间。
然而,使用与之前相同的训练和测试数据,其准确性仅比本机实现算法略高,为83.4%。

用Sklearn朴素贝叶斯分类器训练和测试的结果。
看来朴素贝叶斯算法的眼光相当“毒辣”,预测新闻的准确性还是很不错的。

推荐阅读专题





留言点赞发个朋友圈
我们一起分享AI学习与发展的干货
编译组:胡家瑞、黄弈
相关链接:
https://medium.com/softup-technologies/building-a-ml-model-that-predicts-news-category-given-a-news-title-65c74867d876
如转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你