GeoWave0.9.8开发人员指南
GeoWave0.9.8开发人员指南
官方英文地址:http://s3.amazonaws.com/geowave/0.9.8/docs/devguide.html
介绍
什么是GeoWave
GeoWave是一个开源库,用于在排序的键值数据存储和流行的大数据框架之上存储,索引和搜索多维数据。GeoWave包含特定的定制实现,这些实现具有对OGC空间类型(最多3维)以及有界和无界时间值的高级支持。所有轴都支持单值和范围值。GeoWave的地理空间支持建立在GeoTools项目可扩展性模型之上。这意味着它可以与任何兼容GeoTools的项目(如GeoServer和UDig)本机集成,并且可以摄取兼容GeoTools的数据源。
GeoWave为分布式键/值存储提供开箱即用的支持,以满足任务需求。最新版本的GeoWave支持Apache Accumulo和Apache HBase存储,但可以按要求或需要实现其他数据存储。
本指南旨在关注GeoWave功能的开发方面,并协助开发人员使用GeoWave代码环境。
GeoWave功能
为Apache Accumulo和Apache HBase添加多维索引功能
添加对Apache Accumulo和Apache HBase的地理对象和地理空间运算符的支持
提供GeoServer插件,允许通过OGC标准服务共享和可视化Accumulo和HBase中的地理空间数据
提供Map-Reduce输入和输出格式,用于分布式处理和分析地理空间数据
地理空间软件插件包括以下内容:
GeoServer插件允许通过OGC标准服务共享和可视化Accumulo中的地理空间数据
用于处理点云数据的PDAL插件
Mapnik插件用于生成地图图块并通常可以制作外观漂亮的地图。
基本上,GeoWave正在努力将地理空间软件与分布式计算系统联系起来,并尝试为PostGIS为PostgreSQL做分布式键/值存储。
起源
GeoWave是在国家地理空间情报局(NGA)与RadiantBlue Technologies和Booz Allen Hamilton合作开发的。政府拥有无限的权利,并且正在发布这一软件,通过为开发商提供向新方向采取行动的机会来增加政府投资的影响。Apache 2.0许可证中规定了软件的使用,修改和分发权限。
意图
可插拔后端
GeoWave旨在成为一个多维索引层,可以添加到任何已排序的键值存储之上。选择Accumulo作为初始目标架构,并且还添加了对HBase的支持。任何允许基于前缀的范围扫描的数据存储都应该是简单的扩展。
模块化框架设计
GeoWave体系结构设计为极具可扩展性,大多数功能单元由接口定义,并且这些接口的默认实现涵盖了大多数用例。GeoWave允许简单的功能扩展和平台集成 - 弥合分布式技术之间的差距,并最大限度地减少开发人员的学习曲线。目的是开箱即用的功能应满足90%的用例,但模块化架构允许轻松扩展功能以及集成到其他平台。
自描述数据
GeoWave存储数据库本身中操作数据所需的信息,例如配置和格式。这允许软件以编程方式查询存储在单个或一组GeoWave实例中的所有数据,而无需客户端,应用程序服务器或其他外部存储的配置。
可扩展
GeoWave可以在单节点设置中运行,也可以根据需要进行扩展,以支持所需的数据量和/或处理资源。通过利用分布式计算集群和服务器端细粒度过滤,GeoWave完全能够对包含数十亿个特征的数据集执行交互式时间和/或位置特定查询,并且具有100%的准确性。
概观
对于GeoWave用户,与GeoWave连接的主要方法是通过各种命令行界面(CLI)命令和选项。用户将使用GeoWave在键值数据存储中存储,索引或搜索多维数据。
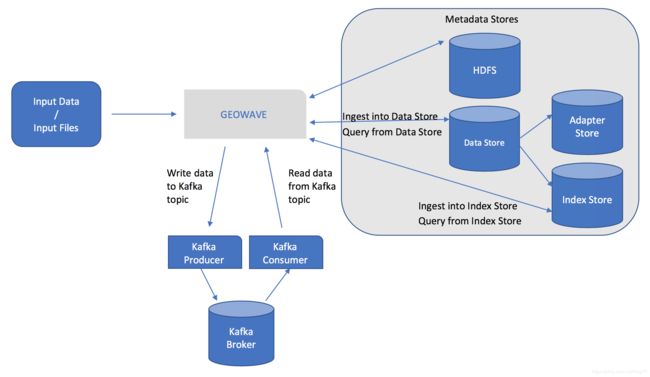
运营概览
图1.高级操作概述
这通常涉及以下四个步骤:
配置
在GeoWave上设置/配置数据存储或索引,以便根据需要在各种操作中重复使用。
摄取 / 索引
将数据摄取或索引到特定商店(例如,Accumulo,HBase)
处理
使用分布式处理引擎处理数据(例如MapReduce,Spark)
查询 / 发现
搜索/查询或发现通过GeoWave操作提取,索引或处理/转换的数据。使用的常见数据发现工具是GeoServer,它通过插件与GeoWave连接,用于与选定的数据存储区连接,例如Accumulo或HBase。
GeoWave使用分层网格空间填充曲线(SFC)将数据索引到所需的键值存储中。索引信息存储在通用密钥结构中,该结构也可用于服务器端处理。该架构允许查询,处理和渲染时间减少多个数量级。
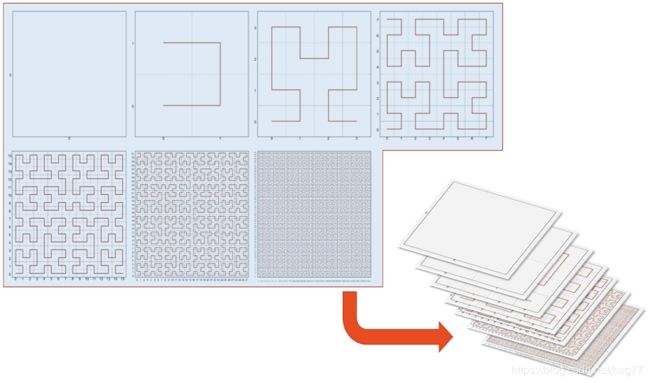
分层
图2.分层空间填充曲线
如果遇到问题或问题,或者可以解释的感兴趣的主题,请在GeoWave项目GitHub页面中创建一个问题。
假设
在设置围绕GeoWave项目的开发环境之前,本指南假定已安装以下组件。由于这些组件不断发生变化,安装和维护这些组件的广泛操作功能超出了本文档的范围。
发展与建设
为了使用GeoWave源构建和/或执行开发,需要以下组件:
Java开发工具包(JDK)(> = 1.8)
需要JDK v1.8或更高版本
从Java下载站点下载。OracleJDK是经过最彻底测试的,但OpenJDK没有已知问题。
混帐
参考Git SCM网站上的在线资料。
有关安装和使用Git的完整参考指南,请参阅在线Pro Git一书中的章节。
Maven的
需要Maven版本> = 3.2.1
有关Maven入门的参考指南,请参阅在线Maven入门指南。
GeoWave依赖于以下库 - 通过Maven处理:
Uzazygezen - 链接:https://code.google.com/p/uzaygezen/
GeoTools - 链接:http://www.geotools.org/
Log4J - 链接:http://logging.apache.org/log4j/1.2/
Java高级映像和Java映像I / O.
两者都需要安装在GeoServer实例以及Accumulo节点上。只有某些功能(分布式渲染)才需要Accumulo支持,因此在某些情况下可能会跳过此功能。
外部组件
取决于针对例如需求,数据存储,索引等开发和/或测试的环境组件,一些外部组件将是有益的。虽然此信息超出了本文档的范围,但您可以在GeoWave用户指南中找到这些要求。
开发设置
概观
设置环境包括几个步骤:
检索GeoWave代码
安装GeoWave
包GeoWave工具框架
从源创建第三方插件
GeoServer插件
Accumulo插件
HBase插件
如何贡献
检索代码
用户有两种选择来检索地理代码:通过直接下载zip存档中的代码存储库或克隆存储库,两者都是通过GitHub访问的目录。
将代码下载为Zip存档
此选项适用于不打算为GeoWave项目源做出贡献的用户,只是希望以只读用户身份进行协作,并且仍然可以构建代码并在环境中运行。这是访问代码的最简单,最直接的方法。
要下载代码存储库的只读版本:
打开Web浏览器并导航到GeoWave GitHub存储库,在该存储库中可以查看不同的项目和最新更改。
如果对特定分支感兴趣,请选择所选分支。否则,请在默认主分支上保留最新的测试更改。
找到文件导航部分右上角附近的绿色“克隆或下载”按钮。
图3.克隆和下载GeoWave存储库
单击标记为“克隆或下载”的绿色按钮,展开“克隆或下载”窗格。

图4.克隆和下载GeoWave源扩展
单击“下载ZIP”按钮下载代码。根据浏览器设置,代码将自动下载到用户帐户的下载目录,或者提示将要求下载目标。如果zip文件自动下载到downloads目录,请手动将zip文件移动到目标目标目录。
在系统上导航到zip文件所在的路径。解压缩下载的GeoWave存储库源后,即可在本地使用和构建。
克隆GeoWave Git存储库
对于打算提出对GeoWave项目源的贡献的用户,或者只是想要一个干净的方法来使代码与GeoWave团队最新提交的更改保持同步,可以通过以下方式克隆GeoWave代码源。 Git命令行界面。克隆存储库可以实现简单的界面,用户可以轻松地将其当前代码库与主(或选定分支)存储库中的最新代码进行比较。
导航到GeoWave项目代码所在的系统目录。代码将下载到名为“geowave”的父文件夹中。确保没有标题为“geowave”的现有文件夹。
通过打开终端并运行命令来克隆git存储库:
$ git clone https://github.com/locationtech/geowave.git
如果您不需要完整的历史记录,并希望加快克隆速度,则可以通过在上面的克隆命令中附加“-depth NUM_COMMITS”来限制结帐过程的深度。
克隆存储库时,应显示终端活动,类似于下面的活动。请注意,这通常需要几分钟。
克隆成’geowave’…
remote:计数对象:1311924,完成。
remote:压缩对象:100%(196/196),完成。
remote:总计1311924(delta 68),重用0(delta 0),pack-reused 1311657
接收物体:100%(1311924/1311924),784.52 MiB | 6.18 MiB / s,完成。
解决增量:100%(1159959/1159959),完成。
通过确保创建GeoWave目录来确认存储库克隆是否成功。运行命令“ls -l | grep geowave“应该产生类似于下面的结果。
$ ls -l | grep geowave
drwxr-xr-x 22 {user} {domain group} 748 Mar 16 10:41 geowave
通过检查’geowave’目录的内容,确认已正确下载和克隆GeoWave内容。请注意,文件夹条目应与GitHub网站上的列表完全相同
$ ls -lah geowave
total 144
drwxr-xr-x 22 {user} {domain group} 748B Mar 16 10:41 .
drwx------+ 9 {user} {domain group} 306B Mar 16 10:33 …
drwxr-xr-x 12 {user} {domain group} 408B Mar 16 10:44 .git
-rw-r–r-- 1 {user} {domain group} 710B Mar 16 10:35 .gitattributes
-rw-r–r-- 1 {user} {domain group} 147B Mar 16 10:35 .gitignore
drwxr-xr-x 6 {user} {domain group} 204B Mar 16 10:36 .metadata
-rw-r–r-- 1 {user} {domain group} 3.1K Mar 16 10:35 .travis.yml
drwxr-xr-x 7 {user} {domain group} 238B Mar 16 10:35 .utility
-rw-r–r-- 1 {user} {domain group} 11K Mar 16 10:35 LICENSE
-rw-r–r-- 1 {user} {domain group} 724B Mar 16 10:35 NOTICE
-rw-r–r-- 1 {user} {domain group} 8.0K Mar 16 10:35 README.md
drwxr-xr-x 6 {user} {domain group} 204B Mar 16 10:35 analytics
drwxr-xr-x 9 {user} {domain group} 306B Mar 16 10:35 core
drwxr-xr-x 10 {user} {domain group} 340B Mar 16 10:37 deploy
drwxr-xr-x 7 {user} {domain group} 238B Mar 16 10:42 dev-resources
drwxr-xr-x 6 {user} {domain group} 204B Mar 16 10:37 docs
drwxr-xr-x 9 {user} {domain group} 306B Mar 16 10:37 examples
drwxr-xr-x 7 {user} {domain group} 238B Mar 16 10:35 extensions
-rw-r–r-- 1 {user} {domain group} 31K Mar 16 10:35 pom.xml
drwxr-xr-x 6 {user} {domain group} 204B Mar 16 10:35 services
drwxr-xr-x 10 {user} {domain group} 340B Mar 16 10:38 test
GeoWave源现在可以在本地使用和构建
建立源头
工具框架概述
插件框架(使用基于服务提供程序接口(SPI)的注入)提供了几种支持开箱即用的输入格式和实用程序。首先,我们将展示如何构建和使用内置格式,然后介绍如何创建新插件。
建造
GeoWave将很快在Maven中心提供(用于标记版本),但在此之前,或者为了获得最新功能,从源代码构建GeoWave是最好的选择。
构建GeoWave
要构建项目源,请导航到下载GeoWave代码的目录。从命令行使用Maven,在本地终端中运行以下命令:
$ mvn clean install
你可以通过添加-Dfindbugs.skip = true -Dformatter.skip = true -DskipITs = true -DskipTests = true来跳过测试来加速构建。
集成测试:Windows
集成测试目前无法在Windows上开箱即用。如果你安装cygwin并将环境变量CYGPATH设置为cygwin提供的cygpath二进制文件的位置,以使其工作。
执行上面的命令后,您应该看到一个以下面类似代码开头的终端输出。Maven将在存储库中构建所有项目,因此这将需要几分钟才能完成。
[INFO]扫描项目…
[INFO] ----------------------------------------------- -------------------------
[INFO]反应堆建造订单:
[信息]
[INFO] GeoWave Parent POM
[INFO] GeoWave核心父POM
[INFO] GeoWave CLI
[INFO] GeoWave Index
[INFO] GeoWave Store
[INFO] GeoWave MapReduce
[INFO] GeoWave摄取框架
[INFO] GeoWave空间和时间支持
[INFO] GeoWave Extensions
[INFO] Geowave矢量适配器
[INFO] Geowave光栅适配器
[INFO] GeoWave Analytics父POM
[INFO] GeoWave Analytics API
[INFO] GeoWave MapReduce Analytics
[INFO] GeoWave Spark Analytics
[INFO] GeoWave部署配置
[INFO] GeoWave文档
[INFO] GeoWave Accumulo
[INFO] GeoWave Hbase
[INFO] GeoWave示例
[INFO] GeoWave BigTable
[INFO] GeoWave GeoLife格式支持
[INFO] GeoWave栅格格式
[INFO] GeoWave矢量格式
[INFO] GeoWave GPX格式
[INFO] GeoWave T-Drive格式
[INFO] GeoWave GDELT格式支持
[INFO] GeoWave Avro格式
[INFO] GeoWave Twitter格式支持
[INFO] geowave-format-4676
[INFO] GeoWave Services Parent POM
[INFO] GeoWave Services API
[INFO] geowave-service-4676
[INFO] GeoWave调试命令行工具
[INFO] Geowave GeoServer命令行工具
[INFO] Geowave OSM命令行工具
[INFO] GeoWave LandSat8运营
[INFO]用于REST服务的GeoWave Java客户端
[INFO] GeoWave REST服务WebApp
[INFO] GeoWave集成测试
[信息]
[INFO] ----------------------------------------------- -------------------------
[INFO]构建GeoWave Parent POM 0.9.8
[INFO] ----------------------------------------------- -------------------------
完成此操作后,已编译的工件(jar,war等)将“安装”到每个相应项目的本地存储库中。编译的工件也可在每个项目目标目录中使用。
Maven依赖
不在Maven Central中的必需存储库已添加到父POM,特别是cloudera和opengeo存储库。
Docker构建过程
我们支持从Docker容器构建GeoWave jar工件和RPM。此功能适用于多种不同情况:
Jenkins构建工作者可以在各种主机操作系统上运行Docker,并为其他人构建
任何运行Docker的人都可以复制我们的构建和打包环境
将允许我们构建现有的容器集群而不是单一用途的构建VM
如果使用Docker容器构建工件感兴趣,请查看README中的deploy/packaging/docker。
创建Eclipse项目
为了促进更完整的开发环境,我们现在需要将GeoWave源代码放入集成开发环境(IDE)中。本节将向您介绍如何将Maven项目导入Eclipse IDE。
有几个IDE可用,但本指南将假设使用Eclipse。如果您使用的是与Eclipse不同的IDE,那么Internet上可能会有指南指导您将Maven项目转换为IDE。
使用Eclipse Maven M2Eclipse插件,我们可以将maven项目导入eclipse,eclipse将自动解析/下载每个项目的pom.xml文件中列出的依赖项。
如果更改/更新任何项目pom.xml依赖项,Eclipse将自动更新项目以及对相关/依赖项目的任何下游更改。
将Maven GeoWave项目导入Eclipse工作区。
在Eclipse中,选择文件→导入。
图5. Eclipse文件导入菜单
在“导入”窗口中,为“现有Maven项目”选择“Maven”下的选项,然后选择“下一步”按钮。
图6.现有的Maven项目向导
从“导入Maven项目”窗口中,选择“浏览”按钮并导航到GeoWave源位于文件系统上的根目录。找到后,选择geowave目录并选择“打开”按钮。
在“导入Maven项目”窗口中,现在应该使用所有GeoWave项目填充“项目”窗格。选择“完成”按钮退出。
返回到Eclipse中的工作区后,现在应该使用所有GeoWave项目填充Project Explorer窗格。

图7. Eclipse Workspace
打包源
本节旨在概述如何将各种GeoWave构建打包为可部署的jar文件。
打包CLI工具框架
当GeoWave代码准备好打包和部署时,可以通过从GeoWave主目录运行以下命令,使用Maven轻松打包代码:
$ mvn package -P geowave-tools-singlejar
你可以通过添加-Dfindbugs.skip = true -Dformatter.skip = true -DskipITs = true -DskipTests = true来跳过测试来加速构建。
这个过程需要一两分钟才能构建完成。
打包过程完成后,geowave-tools jar现在打包在deploy / target目录中。
打包安装时,会有一个名为’geowave’的包装器别名命令,它将安装在$ PATH中。
在尚未安装此脚本的开发环境中,可以使用任何所需的插件jar创建包含工具jar的目录,并使用类似以下命令的内容:
java -cp "$DIR/*
或者,如果在基于* nix的环境中运行,则可以通过以下步骤将命令作为别名添加到用户配置文件:
打开用户帐户配置文件脚本以进行编辑。
$ vi ~/.profile [Press Enter]
为geowave的配置文件添加别名。别名的结构类似于下面的结构。
alias geowave="java -cp G E O W A V E H O M E / d e p l o y / t a r g e t / g e o w a v e − d e p l o y − 0.9.8 − t o o l s . j a r m i l . n g a . g i a t . g e o w a v e . c o r e . c l i . G e o W a v e M a i n " 将 GEOWAVE_HOME/deploy/target/geowave-deploy-0.9.8-tools.jar mil.nga.giat.geowave.core.cli.GeoWaveMain" 将 GEOWAVEHOME/deploy/target/geowave−deploy−0.9.8−tools.jarmil.nga.giat.geowave.core.cli.GeoWaveMain"将 GEOWAVE_HOME替换为GeoWave主目录的值,或为该名称和值创建环境变量。
保存并关闭编辑器。
:q! [Press Enter]
在当前环境中更新配置文件
$ source ~/.profile [Press Enter]
此时,您现在可以运行GeoWave命令行指令。有关这些命令的完整列表,请参阅GeoWave CLI附录。
如何贡献
GeoWave是一个开源项目,我们欢迎社区的贡献。
请求
来自非locationtech成员的拉取请求必须通过分叉存储库完成。
要创建一个新的fork,只需单击GeoWave GitHub页面顶部的“Fork”按钮。您现在可以将您叉上工作分支的拉取请求直接提交到locationtech上的主分支。
GeoWave使用Maven插件格式化程序来保持所有代码的标准化。您应该在提交和推送更改之前立即运行Maven安装。
在提交拉取请求之前,请将您的提交压缩成一个。这将有助于保持我们的提交历史记录清洁,并将减少“进行中提交”,这些提交将来不会传递任何有用的信息。
对该项目的所有拉取请求贡献都将在Apache 2.0许可下发布。
先前根据开源许可证发布然后由NGA工作人员修改的软件源代码被视为“联合工作”(参见17 USC 101); 它是部分版权,部分公共领域,并且整体受非政府作者的版权保护,必须根据原始开源许可的条款发布。
建筑
概观
架构概述
图8. GeoWave架构概述
GeoWave架构概念的核心是获取数据(Ingest),并将数据拉出(Query)。系统中还存在两种类型的数据:要素数据和元数据。特征数据是存储用于以后检索的实际属性和几何集。元数据描述了数据在数据库中的持久性。目的是将数据发现和检索所需的信息存储在数据库中。这意味着现有数据存储不依赖于特定外部服务器或客户端上的一些配置,而是“自我描述”。
坚持
将数据加载到工作累积群集中需要三件事:索引,要素类型和支持的源格式。
来源格式
利用GeoTools基础架构,GeoWave支持提取GeoTools支持的任何数据源。目前支持的数据类型包括:
arcgrid
的ArcSDE
DB2
栅格格式
的GeoTIFF
grassraster
GTOPO30
ImageIO的-EXT-@中
imagemoasaic
imagepyramid
JP2K
数据库“jdgc-ng”支持
H2
MySQL的
神谕
PostGIS的
spatialite
SQLSERVER
PostGIS的
属性文件
shape文件
DFS
edigeo
以GeoJSON
WFS
有关支持的格式的最新列表,请参阅GeoTools用户指南。参考GeoWave构建的GeoTools版本(目前为18.1)。
索引
从GeoWave快速检索数据的核心引擎是基于SFC的索引。该索引可以配置几个不同的参数:
级别数
尺寸数量
每个维度的基数
尺寸类型(有界/无界)
每个维度的值范围
稍后将描述关于这些属性中的每一个的更多内容,但是该列表的目的是提供关于持久存在什么类型的配置信息的概念。
为了在数据存储中插入数据,必须知道索引的配置。索引保存在一个特殊的表中,并通过表名引用到包含数据的表中。因此,查询可以检索数据而无需索引配置。有一个限制,即每个表只支持一个索引配置,即,您无法在同一个表中的二维和三维索引上存储数据。(您可以将二维几何类型存储在三维索引中)。
适配器
为了存储几何,属性和其他信息,需要一种格式来描述如何序列化和反序列化数据。GeoWave提供了一个处理特征数据序列化和反序列化的接口。默认情况下包含支持GeoTools简单要素类型的默认实现。有关此特定实现以及接口的更多信息将在本文档的后面部分详细介绍。预期在类路径上的Java类的指针存储在适配器持久性表中。在查询数据并将结果转换为本机数据类型时动态加载。

特征序列化
图9.特征序列化
GeoWave允许开发人员创建自己的数据适配器。适配器不仅确定数据的实际存储方式(序列化/反序列化),还包含属性类型的层次结构。这种层次结构的原因与可扩展性和优化性有关。理论上,数据适配器可以依赖于ffmpeg,将该功能作为元数据存储在视频流中,并将该值保存到数据库中。除了解决这个解决方案的所有问题之外,细粒度过滤的方式还有一些额外的具体问题,特别是由于迭代器。
基于此,我们的目标是最小化代码并尽可能少地使用迭代器进行标准化。这与使用任意DataAdapter实现最大灵活性的愿望相冲突。找到了一个中间地带,并创建了这个层次结构。围绕如何存储和序列化某些数据类型进行了一些标准化,但仍然为任意数据留下了“本机数据”部分。需要注意的是,本机数据不能用于分布式(基于迭代器的)过滤 - 仅在客户端过滤中使用。
主要指数数据
这些数据集也用于构造主索引SFC。它们通常是几何坐标和可选的时间,但可以是任何数值集(想想分解的特征向量等)。它们不能为空。
共同指数数据
这些是属性的集合。可以有任意数量的属性,但它们必须符合NumericDimensionField接口。属性类型必须具有FieldReader和FieldWriter,它位于平板电脑服务器的类路径中。GeoWave为这些属性类型提供了基本实现:
布尔
字节
短
浮动
双
BigDecimal的
整数
长
的BigInteger
串
几何
日期
日历
不属于主索引的值可用于分布式二级过滤,并且可以为null。与主索引关联的值将用于迭代器中的细粒度过滤。
原生数据
这些可以是字面上的任何东西。除Accumulo的可见性过滤器外,不能对此数据执行分布式过滤,但如有必要,仍可使用客户端过滤扩展点。数据适配器必须提供以字段读取器和写入器的形式序列化和反序列化这些项的方法,但没有必要在任何节点的类路径上使用这些方法。
现场作家/读者
这些是类型特定的实现,由mil.nga.giat.geowave.core.store.adapter.DataAdapter用于告诉GeoWave如何序列化或反序列化某种类型的信息。默认实现包含在分布式筛选器迭代器中。这就是驱动上面公共索引数据部分中列出的类型要求的原因。
写数据
在编写数据时,编写实现类应该实现Writable接口。
写矢量数据
在编写矢量数据时,GeoWave提供默认的矢量可写实现,即mil.nga.giat.geowave.adapter.vector.FeatureWritable类。
mil.nga.giat.geowave.adapter.vector.FeatureDataAdapter使用此类来持久保存org.opengis.feature.simple.SimpleFeature及其org.opengis.feature.simple.SimpleFeatureType。在对特征进行反序列化之前,必须先了解特征的属性类型,因此每个org.opengis.feature.simple.SimpleFeature都会序列化其类型。
此类缓存要素类型信息。如果要素类型更改,则应使用clearCache()方法清空缓存。
编写栅格数据
在编写栅格数据时,GeoWave提供默认的光栅可写实现,即mil.nga.giat.geowave.adapter.raster.adapter.GridCoverageWritable类。
GridCoverageDataAdapter(例如,mil.nga.giat.geowave.adapter.raster.adapter.RasterDataAdapter)使用此类来持久保存org.opengis.coverage.grid.GridCoverage。适配器具有关于样本模型和颜色模型的信息,因此持久化所需的全部是缓冲区和包络。
关键结构
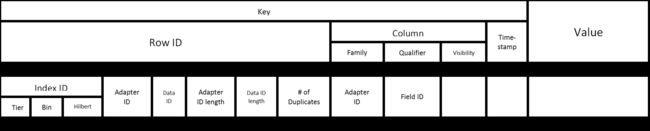
图10. Accumulo数据模式
上图描述了数据存储中条目的默认结构。该指数ID直接从分层证监会执行来。我们并未强制要求数据ID是全局唯一的,但它们对于适配器应该是唯一的。因此,适配器ID和数据ID的配对定义了数据元素的唯一标识符。长度作为4字节整数存储在行ID中。这样可以完全读取行ID,因为这些ID可以是可变长度的。重复数量存储在行ID中同时通知重复数据删除过滤器是否需要临时存储该元素,以确保不向调用者发送重复项。的适配器ID是内行ID来执行唯一行ID作为一整行迭代器被用于为可分配的过滤器集料领域。该适配器ID也被用来作为列族的机制来具体适配器的查询只取相应的列科。
统计
适配器提供存储在统计存储中的一组统计信息。可用统计信息集特定于每个适配器以及适配器管理的那些数据项的属性集。统计包括:
范围超出属性,包括时间
在所有几何体上包围边界框
存储项数量的基数
属性值范围内的直方图
属性离散值的基数
在数据摄取和删除期间更新统计信息。范围和边界框统计数据反映了随时间变化的最大范围。删除期间不会更新这些统计信息。基于基数的统计数据在删除时更新。
在三种情况下需要重新计算统计数据:
当索引项目从适配器存储中删除时,如果删除的项目包含表示总体的最小值或最大值的属性,则范围和包络统计信息可能会失去准确性。
摄取数据项后,将新统计信息添加到统计信息存储中。这些新的统计数据并不能反映整个人口。
软件更改使先前存储的统计图像无效。
统计信息保留与关联属性相同的可见性约束。因此,每个唯一约束都有一组统计信息。统计信息存储使用与请求者的授权匹配的那些统计信息来回答给定适配器的每个统计信息查询。统计信息存储库合并包含相同属性的授权统计信息。
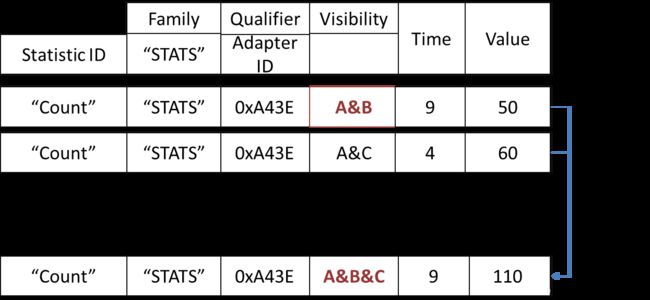
图11.统计信息合并
表结构

图12.统计结构
摄取
概观
除了要摄取的原始数据之外,摄取过程还需要适配器将本机数据转换为可以持久保存到数据存储中的格式。此外,摄取过程需要一个索引,该索引是所有已配置参数的定义,这些参数定义了如何将数据转换为行ID(如何编制索引)以及需要在表中维护哪些公共字段以供细粒度使用和二次过滤器。
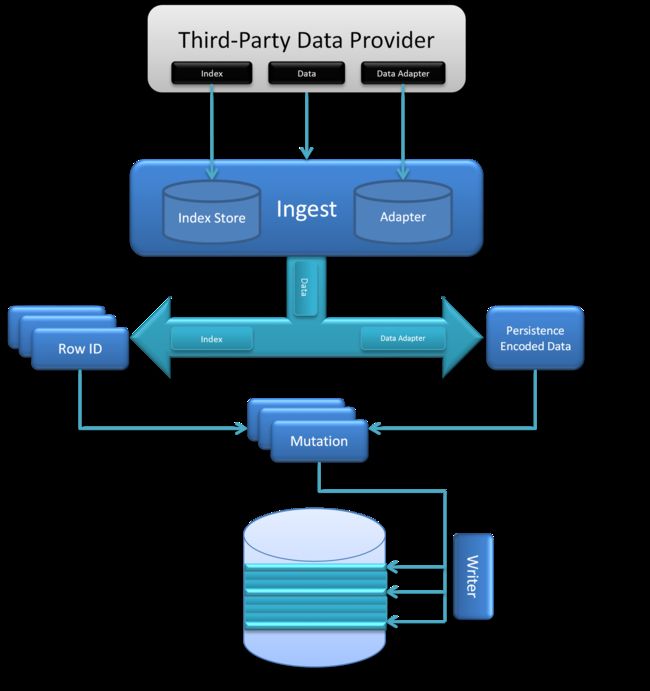
图13.摄取架构
摄取过程中的逻辑可立即确保索引和数据适配器保留在索引存储和适配器存储中,以支持自描述的数据发现。对于在摄取过程中不希望与第三方数据存储(例如,Accumulo,HBase)的连接(例如在Map-Reduce作业中摄取批量数据)的情况,提供了这两个存储的内存中实现。然后,流程确定行ID的集合需要插入数据。在某些情况下,复制是必不可少的,因此可以在多个位置插入数据,例如跨越日期线的多边形或跨越分箱边界的日期范围,例如12月31日 - 1月1日按年分类。在查询数据时,重复数据删除始终作为客户端过滤器执行。在适配器执行转换以创建一组突变之后,这将以可持久格式与实际数据组合。
有一个Writer接口,数据存储的AccumuloOperations将实例化,指定如何实际写入突变。默认实现将使用此接口包装Accumulo BatchWriter,但在某些情况下,提供编写器的自定义实现是有意义的。使用HBase数据存储区时,此过程相同。在映射器或作业的缩减器中执行批量摄取时,最好定义一个编写器将突变添加到批量摄取的上下文中,而不是直接写入Accumulo或HBase。
可以在commands.html #ingest-commands [GeoWave CLI附录^]中找到GeoWave摄取命令的完整列表。
摄取插件
GeoWave命令行实用程序附带了几个开箱即用的插件。您可以列出使用命令行工具注册的可用插件。
geowave ingest listplugins
只需将所需的插件复制到/ usr / local / geowave / tools / plugins目录中即可添加更多内容。
Available index types currently registered as plugins:
spatial_temporal:
This dimensionality type matches all indices that only require Geometry and Time.
spatial:
This dimensionality type matches all indices that only require Geometry.
Available ingest formats currently registered as plugins:
twitter:
Flattened compressed files from Twitter API
geotools-vector:
all file-based vector datastores supported within geotools
geolife:
files from Microsoft Research GeoLife trajectory data set
gdelt:
files from Google Ideas GDELT data set
stanag4676:
xml files representing track data that adheres to the schema defined by STANAG-4676
geotools-raster:
all file-based raster formats supported within geotools
gpx:
xml files adhering to the schema of gps exchange format
tdrive:
files from Microsoft Research T-Drive trajectory data set
avro:
This can read an Avro file encoded with the SimpleFeatureCollection schema. This schema is also used by the export tool, so this format handles re-ingesting exported datasets.
Available datastores currently registered:
accumulo:
A GeoWave store backed by tables in Apache Accumulo
bigtable:
A GeoWave store backed by tables in Google’s Cloud BigTable
hbase:
A GeoWave store backed by tables in Apache HBase
摄取统计信息和时间维度配置
可用的矢量插件通过命令行调整其配置。可以将系统属性“SIMPLE_FEATURE_CONFIG_FILE”分配给定义配置的本地可访问JSON文件的名称。
例
$ GEOWAVE_TOOL_JAVA_OPT="-DSIMPLE_FEATURE_CONFIG_FILE=myconfigfile.json"
$ geowave ingest localtogw ./ingest mystore myindex
配置包括几个部分:
选择时间索引的时间属性。
为每个属性分配要在统计信息存储中捕获的统计信息的类型。
确定应在二级索引中索引哪些属性。
确定哪个属性包含其他属性的可见性信息
通过GeoServer插件设置要在WFS-T事务中更新的索引的名称。
JSON文件由配置组成。每个配置都由类名和一组属性定义。配置按简单要素类型名称分组。
时间配置
时态配置有三个属性:
timeName
startRangeName
endRangeName
这些属性与引用时间值的简单要素类型属性的名称相关联。要按单个时间属性进行索引,请设置timeName为单个属性的名称。到由一系列索引,同时设置startRangeName并且endRangeName对定义的开始和结束时间的值的简单特征类型属性的名称。
统计配置
每个简单要素类型属性可能有多个已分配的统计信 为几何和时间属性自动捕获边界框和范围统计。
属性类型 统计名称 统计配置属性(使用默认值) 统计类
数字
固定Bin直方图
minValue =-∞,maxValue =∞,bins = 32
mil.nga.giat.geowave.adapter.vector.stats。FeatureFixedBinNumericStatistics $ FeatureFixedBinConfig
动态直方图
mil.nga.giat.geowave.adapter.vector.stats。FeatureNumericHistogramStatistics $ FeatureNumericHistogramConfig
数字范围
mil.nga.giat.geowave.adapter.vector.stats。FeatureNumericRangeStatistics $ FeatureNumericRangeConfig
串
算Min Sketch
errorFactor = 0.001,probabilityOfCorrectness = 0.98
mil.nga.giat.geowave.adapter.vector.stats。FeatureCountMinSketchStatistics $ FeatureCountMinSketchConfig
超级日志日志
精度= 16
mil.nga.giat.geowave.adapter.vector.stats。FeatureHyperLogLogStatistics $ FeatureHyperLogLogConfig
可见性配置
可见性配置有两个属性:可见性管理器类和可见性属性名称。
可见性管理器扩展了mil.nga.giat.geowave.core.store.data.visibility.VisibilityManagement。此类的实例在简单要素中解释可见性属性的内容,以确定该简单要素中其他属性的可见性约束。默认的可见性管理类是mil.nga.giat.geowave.adapter.vector.plugin.visibility.JsonDefinitionColumnVisibilityManagement。
二级索引配置
辅助索引配置由以下三个类别之一组成:
mil.nga.giat.geowave.adapter.vector.index.NumericSecondaryIndexConfiguration
mil.nga.giat.geowave.adapter.vector.index.TemporalSecondaryIndexConfiguration
mil.nga.giat.geowave.adapter.vector.index.TextSecondaryIndexConfiguration
每个配置都维护一组简单的要素属性名称,以便在二级索引中进行索引。
主要索引标识符
mil.nga.giat.geowave.adapter.vector.index.SimpleFeaturePrimaryIndexConfiguration类用于维护用于通过GeoServer插件(FeatureWriter)添加或更新简单要素的主索引的配置。
例
{
“configurations”: {
“myFeatureTypeName” : [
{
“@class” : “mil.nga.giat.geowave.adapter.vector.utils.TimeDescriptorsKaTeX parse error: Expected 'EOF', got '}' at position 137: …reTime" }̲, { …SimpleFeatureStatsConfigurationCollection”,
“attConfig” : {
“population” : {
“configurationsForAttribute” : [
{
“@class” : “mil.nga.giat.geowave.adapter.vector.stats.FeatureFixedBinNumericStatisticsKaTeX parse error: Expected 'EOF', got '}' at position 67: … }̲ ]…FeatureCountMinSketchConfig”,
“probabilityOfCorrectness” : 0.98,
“errorFactor” : 0.001
},
{
“@class” : “mil.nga.giat.geowave.adapter.vector.stats.FeatureHyperLogLogStatistics$FeatureHyperLogLogConfig”
}
]
}
}
}
]
}
}
指数策略
GeoWave中的索引数据可以通过多种方式完成,具体取决于索引数据的性质以及索引/查询哪些属性。
所有GeoWave索引都必须实现IndexStrategy接口。索引数据时,在处理过程中应用IndexStrategy实现,并将数据作为Persistable对象索引,以支持GeoWave中的序列化和反序列化。
目前,所有索引策略实现都实现了FieldIndexStrategy接口或NumericIndexStrategy接口。
FieldIndexStrategy
FieldIndexStrategy接口是一种更通用的策略,用于定义要编制索引的数据,这些策略可以是任何类型。该策略的每个实现都负责定义如何序列化和反序列化数据以及每个其他索引策略方法。
NumericIndexStrategy
顾名思义,NumericIndexStrategy用于索引数字数据,并定义了进一步描述数值数据的方法。
IndexStrategy层次结构
下图概述了GeoWave中当前可用的各种索引策略的层次结构。

图14. IndexStrategy层次结构
如果没有适合您的索引数据的索引策略实现,可以根据您的数据和任务的特定需求开发一个。请随意参考上述策略或任何可用示例。
新格式
在尝试摄取新数据格式时,需要将新的摄取插件写入与不同数据类型的接口。格式化插件挂钩到摄取框架并允许从数据存储区(例如accumulo或hbase)和索引进行解耦。通常,目的是将格式插件限制为将原始文件转换为GeoWave行所需的内容。对于矢量数据,geowave行表示GeoTools的SimpleFeature对象,对于栅格,它表示GeoTools的GridCoverage对象。此外,数据格式可以提供从文件到任何自定义模式的转换,而后者又将用作支持分布式摄取的中间格式。
摄取插件应该扩展AbstractSimpleFeatureIngestPlugin。
我们的任何扩展/格式项目都是可在运行时发现的可扩展新格式的良好示例,例如AvroIngestPlugin或任何其他现有的摄取插件,如下面列出的那些:
AbstractSimpleFeatureIngestPlugin
AvroIngestPlugin
GDELTIngestPlugin
GeoLifeIngestPlugin
GpxIngestPlugin
TdriveIngestPlugin
TwitterIngestPlugin
Analytics(分析)
概观
分析体现了针对地理空间数据量身定制的算法。大多数分析都利用Hadoop MapReduce进行批量计算。分析作业的结果包括存储在GeoWave中的矢量或栅格数据。分析基础架构提供了在Spark中构建算法的工具。例如,Kryo序列化器/解串器允许交换SimpleFeature,GeoWaveInputFormat将数据提供给Hadoop RDD。
GeoWaveInputFormat不会删除引用跨多个索引区域的多边形的重复要素。
提供以下算法:
名称 描述
KMEANS ++
用于在数据群上查找K质心的K-Means实现。一组初步采样迭代找到K的最佳值和K个质心的初始集合。该算法产生K个质心及其相关的多边形。每个多边形表示包含与质心相关的所有特征的凹壳。该算法支持向下钻取多个级别。在每个级别,设置的质心是从与先前级别相同的质心相关联的特征集合中确定的。
KMeans Jump
在k范围内使用KMeans ++,使用基于信息理论的测量选择最佳k。
KMeans Parallel
执行KMeans并行群集
DBSCAN
基于密度的扫描仪算法为满足密度标准的每个区域生成一组凸多边形。区域密度通过彼此指定距离内的封闭特征的最小基数来测量。
最近的邻居
基础结构组件,用于生成特定距离内的要素的所有邻居。
建造
按照“ToolsFramework→Building”部分中的说明构建GeoWave工具项目。
运行
yarn jar geowave-tools.jar analytic
上面的命令将执行(例如dbscan),从数据存储区获取数据(请参阅GeoWave CLI命令中的config addstore)。
分析命令
可以在GeoWave CLI附录中找到GeoWave分析命令的完整列表。
询问
GeoWave中的查询当前包含主索引维度上的一组范围。最多三个维度(加上temporal可选)可以利用查询窗口的任何复杂OGC几何。对于四维或更大的维度,查询只能是每个维度上的一组范围(例如,超矩形等)。
概观
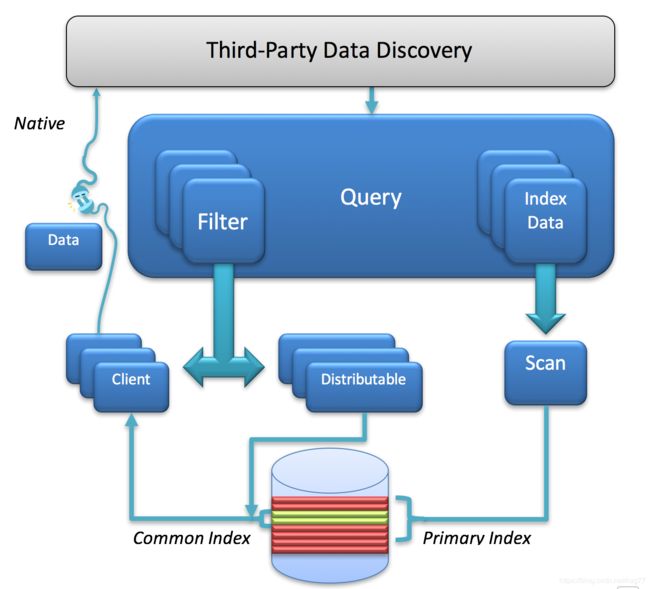
图15.查询体系结构
基于紧凑的希尔伯特空间填充曲线排序,通过GeoWave将查询几何分解为一维数字线上的一系列范围。这些范围通过批扫描程序发送到所有平板电脑服务器。这些范围代表粗粒过滤。
同时,查询几何已被序列化并发送到自定义迭代器。然后,这些迭代器对每个特征进行第二阶段过滤,以进行精确的交叉测试。仅当存储的几何体和查询几何体相交时,处理链才会继续。
然后可以应用二阶滤波器。这用于根据其他属性(通常是时间或其他要素属性)删除要素。这些运算符只能从范围定义的集合中排除项目,而不是任何其他功能 - 想想“AND”运算符 - 而不是“OR”。
在将所有返回的结果聚合在一起之后,可以在客户端集上进行最终过滤。目前,这仅用于最终重复数据删除。应尽可能使用分布式过滤器选项,因为它会在所有平板电脑服务器之间分配工作负载。
查询实施
GeoWave查询必须实现mil.nga.giat.geowave.core.store.query.Query接口。
与大多数其他查询环境(例如,RDBMS中的SQL)一样,查询可以根据需要简单或复杂。GeoWave中最基本的查询是EverythingQuery,与SQL“星型搜索”查询等效,其中没有约束被添加到查询中。
作为带有约束的示例引用的简单查询的更有用的示例是SpatialQuery或TemporalQuery。
虽然可以自定义GeoWave查询实现以满足在GeoWave中被摄取和/或索引的数据的特定需求,但是最新版本的GeoWave中已存在以下查询:
接口 询问
AdapterIdQuery
BatchIdQuery
DataIdQuery
EverythingQuery
PrefixIdQuery
RowIdQuery
接口 DistributableQuery
BasicQuery
空间查询
IndexOnlySpatialQuery
SpatialTemporalQuery
TemporalQuery
CoordinateRangeQuery
CQLQuery
上下文查询语言
查询的结构是实现上下文查询语言(CQL),以前称为/通用查询语言。开发CQL的目的是成为各种数据库中查询或存储系统中其他信息的形式化表示。它旨在使查询更易于人类阅读和理解,同时仍保持通常必要的复杂性。
CQL主要由GeoServer用于对GeoWave数据执行过滤和查询。有关详细信息,请参阅GeoServer教程。
有关CQL规范的更多信息,请参阅官方图书馆CQL标准网站。此外,可以在CQL规范部分中找到有关查询语法的示例和详细信息。
服务
GRPC
GeoWave的gRPC服务为远程gRPC客户端应用程序提供了与GeoWave交互的方法。
gRPC Protobuf
在构建过程中,GeoWave会自动为从抽象类ServiceEnabledCommand派生的所有GeoWave命令生成protobuf消息文件(.proto)。生成过程的源可以在geowave-grpc-protobuf-generator项目中找到。自动生成的protobuf文件以及任何手动生成的GeoWave protobuf文件都可以位于geowave-grpc-protobuf项目中。protobuf文件也被该项目编译为各自的Java类。有关protobuf的更多详细信息,请参阅Protocol Buffers教程
gRPC服务器
gRPC服务器通过GeoWaveGrpcServiceSpi接口发现并加载所有GeoWave gRPC服务实现。可以在geowave-grpc-server项目中找到服务器代码和gRPC服务实现。此项目还包含一些用于启动和停止服务器的CLI命令的定义。
第三方
GeoServer的
GeoWave支持通过GeoServer公开的光栅图像和矢量数据。深入了解GeoServer不在开发人员指南的范围之内。有关GeoServer的详细信息,以及如何配置或添加GeoWave数据存储,请参阅GeoWave用户指南。
从RPM安装
有一个公共的GeoWave RPM Repo可以通过GeoWave提供各种分发包。RPM Repo页面将列出可用的不同软件包和供应商。有关如何通过命令行搜索,安装和更新GeoWave软件包的详细信息和示例,请参阅GeoWave用户指南。
Maven存储库
概观
有一些公共maven存储库可用于发布和快照GeoWave工件(没有传递依赖项)。可以使用自动部署,但需要S3访问密钥(通常添加到〜/ .m2 / settings.xml)。
Maven POM碎片
发布
geowave-maven-releases
GeoWave AWS Release Repository
http://geowave-maven.s3-website-us-east-1.amazonaws.com/release
true
false
快照
geowave-maven-snapshot
GeoWave AWS Snapshot Repository
http://geowave-maven.s3-website-us-east-1.amazonaws.com/snapshot
false
true
Maven settings.xml片段
除非您正在部署官方GeoWave工件,否则您可能不需要这样做。
快照
geowave-maven-releases
ACCESS_KEY_ID
SECRET_ACCESS_KEY
geowave-maven-snapshots
ACCESS_KEY_ID
SECRET_ACCESS_KEY
创建第三方插件
本节重点介绍如何为第三方组件创建GeoWave插件。
当前选项包括:
GeoServer的
Accumulo插件
HBase插件
GeoServer插件
本节将概述如何生成GeoServer插件jar,它可以在运行的GeoServer服务器中部署和运行,以便能够在GeoServer中执行GeoWave功能。
GeoServer版本
GeoWave必须针对特定版本的GeoWave和GeoTools构建。要查看当前支持的版本,请查看项目根目录中.travis.yml文件的构建矩阵部分。
创建GeoServer插件
首先,我们需要构建GeoServer插件。从GeoWave根目录,运行以下命令:
mvn package -P geotools-container-singlejar
您可以通过附加命令“-Dfindbugs.skip = true -Dformatter.skip = true -DskipITs = true -DskipTests = true”跳过测试来加速构建(没有引号)
成功运行上述命令后,可以在“deploy / target /”目录中找到GeoServer插件jar文件。
假设您在“/ opt / tomcat”中的Tomcat容器中部署了GeoServer。
cp deploy/target/*-geoserver-singlejar.jar /opt/tomcat/webapps/geoserver/WEB-INF/lib/
现在重新启动Tomcat。
以前版本的GeoWave RPMs(0.9.5及更低版本)使用Jetty而不是Tomcat。
Accumulo插件
本节将概述如何生成Accumulo插件jar,它可以在单个节点上运行,也可以在运行和分布式集群上运行,以便与GeoWave中的Accumulo进行交互。
Accumulo版本
GeoWave已经过测试,并且针对Accumulo 1.5.0到1.7.2进行了测试。
创建Accumulo插件
从GeoWave根目录,运行以下命令以创建accumulo插件:
mvn package -P accumulo-container-singlejar
您可以通过附加命令跳过测试来加速构建:“-Dfindbugs.skip = true -Dformatter.skip = true -DskipITs = true -DskipTests = true”(无引号)。
成功运行上述命令后,可以在“deploy / target /”目录中找到Accumulo插件jar文件。
有关配置Accumulo的详细信息,请参阅“ Accumulo配置”部分。
HBase插件
本节将概述如何生成一个hbase插件jar,它可以在单个节点或运行和分布式集群上部署和运行,以便与GeoWave中的HBase进行交互。
HBase版本
GeoWave已经过测试,并且针对HBase 1.2.1进行了测试并向前发展。
创建HBase插件
从GeoWave根目录,运行以下命令以创建hbase插件:
mvn package -P hbase-container-singlejar
您可以通过附加命令跳过测试来加速构建:“-Dfindbugs.skip = true -Dformatter.skip = true -DskipITs = true -DskipTests = true”(无引号)。
成功运行上述命令后,可以在“deploy / target /”目录中找到hbase插件jar文件。
Jace JNI Proxies
使用Jace,我们可以为GeoWave创建可用于C / C ++应用程序的JNI代理类。
使用Jace绑定时需要Boost。
预打包的源和二进制文件
有一个公共GeoWave RPM Repo,您可以在其中下载适用于所需平台的GeoWave Jace绑定的tarball。如果您的平台不可用,则有一个源tarball可以与CMake一起使用,为您所需的平台构建GeoWave Jace绑定。
从源代码生成代理和构建
如果需要,您可以自己生成和构建Jace代理。
第1步 - 结帐Jace和GeoWave
首先,我们需要克隆Jace和GeoWave。
$ git clone [email protected]:jwomeara/jace.git
$ git clone [email protected]:locationtech/geowave.git
注意:我们使用的是非标准的Jace实现。
第2步 - 安装Jace
首先,我们需要安装Jace v1.3.0。这是用于生成C ++代理类的软件。
$ cd jace
$ git checkout tags/v1.3.0
$ mvn clean install -Dsources
第3步 - 生成GeoWave Jace代理
在这里,我们将指定一个Maven配置文件,指定我们正在构建jace代理。
$ cd geowave
$ mvn clean package -pl deploy -am -P generate-geowave-jace -DskipTests
这将生成构建GeoWave所需的源文件和头文件。要构建库,只需运行cmake,然后运行make。
注意:要构建静态库,请使用“-DBUILD_SHARED_LIBS = OFF”。否则使用“-DBUILD_SHARED_LIBS = ON”(无引号)。
Mapnik插件配置
Mapnik的
Mapnik是一个用于开发地图应用程序的开源工具包。支持GeoWave作为Mapnik的插件,用于从Accumulo读取矢量数据。
PDAL插件配置
PDAL
点数据抽象库PDAL是一个BSD许可库,用于翻译和操作各种格式的点云数据。支持GeoWave作为PDAL的插件,用于读取和写入Accumulo的数据。
注意:这些说明假定您使用的是预先打包的二进制文件。
为PDAL配置CMake
要将PDAL配置为与GeoWave一起运行,需要配置一些CMake选项。虽然某些选项(即JAVA选项)可能会自动配置,但有些选项需要手动设置。请参阅下表,了解如何在Ubuntu 14.04 LTS上配置这些选项。
选项 值 自动配置?
BUILD_PLUGIN_GEOWAVE
上
BUILD_GEOWAVE_TESTS
上
GEOWAVE_RUNTIME_JAR
/path/to/geowave/geowave-runtime.jar
GEOWAVE_INCLUDE_DIR
/路径/到/ geowave /包括
GEOWAVE_LIBRARY
/path/to/geowave/libgeowave.so
JAVA_AWT_INCLUDE_PATH
/ usr / lib中/ JVM / JAVA -8- ORACLE /包括
X
JAVA_INCLUDE_PATH
/ usr / lib中/ JVM / JAVA -8- ORACLE /包括
X
JAVA_INCLUDE_PATH2
/ usr / lib中/ JVM / JAVA -8- ORACLE /包括/ Linux的
X
JAVA_AWT_LIBRARY
/usr/lib/jvm/java-8-oracle/jre/lib/amd64/libjawt.so
X
JAVA_JVM_LIBRARY
/usr/lib/jvm/java-8-oracle/jre/lib/amd64/server/libjvm.so
X
注意:由于Boost是PDAL依赖项,因此它应该已包含在内。
建立PDAL
配置CMake后,您可以继续进行正常的PDAL构建过程。
最后但并非最不重要的是,在构建共享库时,应确保通过PATH或LD_LIBRARY_PATH提供上面指定的库。
在PDAL文档中,您可以看到GeoWave如何同时用作读者和编写者的示例。
文档
概观
该文档是在AsciiDoc中编写的,这是一种纯文本标记格式,可以使用任何文本编辑器创建并“按原样”读取,或者呈现为其他几种格式,如HTML,PDF或EPUB。
有用的网址:
什么是Asciidoc?
作家指南
AsciiDoc语法参考
订购
存储在docs/content该项目目录中的所有内容将呈现为具有自动生成的目录和PDF的单个网页。页面出现的顺序取决于为docs/content目录中的ASCIIDOC文件指定的文件名的排序顺序,因此为每个文件指定了一个数字前缀。可以在数字之间保留差距(仅排序顺序很重要)以允许将来编辑,而无需重新编号将在新内容之后出现的其他文档。
预习
要在提交之前将标记预览为HTML,可以使用插件,以及可在编辑时使用的各种文本编辑器和IDE。如果您的首选文本编辑器没有可用插件,则可以使用Firefox AsciiDoc插件,通过快速刷新浏览器进行预览。
现场
要构建用于整个完成的网页或GeoWave网站生成的PDF的所有内容,请使用以下命令。
cd geowave
mvn -P {FORMAT}安装
支持的格式包括’pdf’和’html’(无引号)。
整个站点(包括docs和javadocs)都可以在geowave/target/site/目录中查看。
附录
版
本文档是为GeoWave 0.9.8版生成的。
GeoWave项目描述
下表概述了GeoWave项目中的不同项目层次结构
路径 名称 描述
geowave
GeoWave Parent
父目录
分析
GeoWave Analytics
为GeoWave数据集提供的一组分析。geowave-core-mapreduce用于特定方法的扩展(hadoop / yarn上的火花或hadoop / yarn上的mapreduce)。
API
GeoWave Analytics API
GeoWave API和可重用的分析代码,可以跨特定的外部框架共享,例如mapreduce和spark
MapReduce的
GeoWave MapReduce Analytics
用mapduce编写的特定算法用于GeoWave
火花
GeoWave Spark Analytics
在GeoWave数据上为spark编写的特定算法
核心
GeoWave Core
为GeoWave的所有配置提供的基本功能集
CLI
GeoWave核心CLI
GeoWave工具的命令行界面。在商店上构建,以提供与GeoWave交互的命令行工具框架
geotime
GeoWave空间和时间支持
构建在核心存储和索引模块上特别将多维索引问题作为排序键值存储上的空间和时空索引
指数
GeoWave指数
专注于维护多维数据的良好字典排序顺序的问题,主要通过NumericIndexStrategy公开,即如何在键值存储中形成我的键
摄取
GeoWave摄取框架
构建在cli上以提供摄取命令行工具
MapReduce的
GeoWave MapReduce
在商店中构建,以便为在Hadoop上运行作业提供基本的分析组件。首先,它公开了GeoWave的Hadoop输入和输出格式,可用于在YARN上运行的任何分布式处理框架(如Spark或MapReduce)的上下文中智能地分布GeoWave数据中的作业。
商店
GeoWave商店
专注于将索引应用于主要通过DataStore公开的排序键值存储,即如何通过其多维边界来持久化和检索对象
部署
GeoWave部署配置
用于在生产中打包和部署GeoWave的各种脚本
开发资源
GeoWave开发资源
GeoWave的开发资源和设置
文档
GeoWave文档
文档,主要以asciidoc的形式,可以编译成各种格式,包括HTML,PDF,EPUB等(在http://locationtech.github.io/geowave上看到的所有内容都会在每次提交时自动构建和发布)
例子
GeoWave示例
一些非常基本的代码示例,用于在GeoWave中读取和写入矢量数据,以及运行一些基本分析。如果你看到你认为应该涵盖的差距,这是一个伟大而简单的贡献场所。
扩展
GeoWave扩展
GeoWave支持的扩展功能集
适配器
GeoWave扩展适配器
系统中的DataAdapter基本上负责获取任何java对象并处理键值对的值部分的序列化/反序列化。这就是所谓的编码和解码的代码,因为它是一个小不仅仅是更复杂的系列化和_deserialization-,但在一般情况下,过于简单化了高层次的看法是,NumericIndexStrategy从geowave核心指数处理构建一个良好的关键,并且DataAdapter处理构建一个好的值,然后是DataStore没有将java对象映射到键或值的直接逻辑。如果您有一个新的java对象,则可以编写一个独立于特定数据存储的新适配器。同样,如果您有索引的新策略或索引的不同维度,那么它将独立于任何特定数据存储区(即,如果您有唯一的数据集,您可以简单地编写自己的适配器,并且它可以存储您的数据任何后端数据存储区上的任何索引方案)。
AUTH
GeoWave数据适配器的授权功能
光栅
Geowave光栅适配器
DataAdapter for GridCoverage数据(例如,GIS词汇表中的“栅格”数据)是RasterDataAdapter,它还包含插件包中GeoWave栅格数据的GeoTools / GeoServer扩展。
向量
Geowave矢量适配器
DataAdapter for SimpleFeature数据(例如,GIS词汇表中的“矢量”数据)是FeatureDataAdapter,它还包含插件包中GeoWave矢量数据的geotools / geoserver扩展
CLI
GeoWave Extension CLI
其他工具插件,可以作为命令包含在命令行框架中,这是任何工具插入geowave-core-cli作为GeoWave命令的地方。GeoWave服务现已可用,它会自动将CLI命令公开为服务端点。
调试
GeoWave调试命令行工具
可通过命令行使用的一组临时调试工具,可应用于GeoWave数据
GeoServer的
Geowave GeoServer命令行工具
用于管理GeoServer层和数据存储的GeoWave命令行工具
landsat8
GeoWave LandSat8运营
GeoWave支持公共LandSat8数据
OSM
Geowave OSM命令行工具
用于GeoWave的OSM数据处理系统
数据存储
GeoWave DataStores
对特定数据存储区(例如,Accumulo,HBase)的唯一依赖性,项目的其余部分独立于数据存储区; 目的是在具体数据存储区实现之外保留尽可能多的可重用代码,这是明智的
accumulo
GeoWave Accumulo
Apache Accumulo上的Geowave数据存储
Bigtable中
GeoWave BigTable
Google BigTable上的Geowave数据存储
HBase的
GeoWave HBase
Apache HBase上的Geowave数据存储
格式
GeoWave扩展格式
系统中的格式插件是命令行摄取框架的扩展,提供了从特定感兴趣格式读取数据并将其映射到特定适配器的方法; 在开源项目中,我们提供了各种矢量格式和一种包含流行库的光栅格式; GeoTools(“geotools-vector”格式涵盖了GeoTools和geotools-raster支持的所有格式,涵盖了geotools支持的所有栅格格式,每种格式都涵盖了各种流行的地理空间格式)
Avro公司
GeoWave Avro格式
GeoWave提供对Avo数据匹配的支持GeoWave的通用矢量avro架构
gdelt
GeoWave GDELT格式支持
GeoWave提取对Google Ideas的GDELT数据集的支持
geolife
GeoWave GeoLife格式支持
GeoWave提取对Microsoft Research的GeoLife数据集的支持
geotools光栅
GeoWave栅格格式
GeoWave提供对地理工具中支持的所有栅格格式的支持
geotools矢量
GeoWave矢量格式
GeoWave提供对地理工具中支持的所有矢量格式的支持
GPX
GeoWave GPX格式
GeoWave提取对GPX数据的支持
stanag4676
GeoWave stanag4676支持轨道数据的NATO规范。
格式
geowave格式-4676
GeoWave stanag4746格式实现支持将轨迹,轨迹点,运动事件和相关图像芯片摄取到GeoWave中。
服务
geowave服务-4676
GeoWave stanag4746服务实现提供了一个休息端点,以获取每个点和运动事件的图像芯片,并将每个轨道的视频拼接在一起。
tdrive
GeoWave T-Drive格式
GeoWave提取对Microsoft Research的T-Drive数据集的支持
推特
GeoWave Twitter格式支持
GeoWave提取对twitter JSON数据的支持
服务
GeoWave服务
提供与GeoWave交互的REST服务和客户端集。
API
GeoWave Services API
与GeoWave作为使用者连接时使用的服务API。
客户
用于REST服务的GeoWave Java客户端
公开GeoWave CLI接口和功能的Java客户端。
Web应用程序
GeoWave REST服务WebApp
GeoWave服务API的服务器端实现
测试
GeoWave集成测试
用于GeoWave集成和功能测试的模块。针对每个数据存储区的本地测试环境进行端到端功能的集成测试(通常也可以作为示例,但通常示例的目的是简单明了;集成测试更复杂,但肯定更具包容性各种功能)
理论
空间索引
GeoWave创建一个空间索引,以一种可以在一维数字线上缩减为一系列范围的方式表示多维数据。这些例子包括:
纬度,经度
纬度,经度,时间
纬度,经度,海拔,时间
特征向量1,特征向量2(…),特征向量n
这是由于基于大表的数据库存储数据的方式 - 作为一组有序的键/值对。
目标是提供一种属性,确保在n维空间中接近的值仍然在一维空间中接近。这有几个原因,但主要是因为我们可以将n维范围选择器(通常是bbox,但可以抽象为超矩形)表示为较少数量的高度连续的1维范围。
Z曲线:2D - > 1D
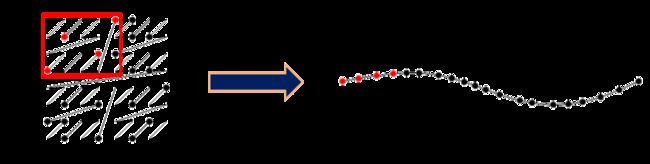
图16.基于Z-Order曲线的尺寸分解
幸运的是,已经存在一种描述数学运算的变换,称为“空间填充曲线”(SFC)。不同的SFC具有不同的属性,但它们都采用n维空间并描述了一组步骤以跟踪单个序列中的所有点。
各种空间填充曲线
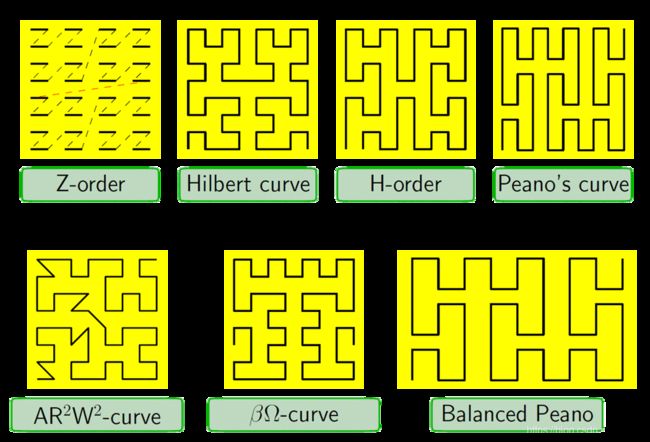
图17. Haverkort,Walderveen局部性和二维空间填充曲线的边界框质量2008 arXiv:0806.4787v2
各种曲线的权衡取决于本用户手册的范围,但图2中引用的论文是开始学习这些曲线的一个很好的起点。
GeoWave支持两个空间填充曲线:Z-Order和Hilbert,后者是主要实现。
希尔伯特证监会
在计算和执行分解时,希尔伯特曲线比Z曲线更复杂。然而,它在计算机科学的某些领域很受欢迎,其中需要以线性顺序设置多个变量 - 一个进程调度。映射到希尔伯特曲线的地球标准投影的简单视图看起来类似于下图,其中每个维度显示4位基数(我们有多少个桶)。
希尔伯特SFC
图18.希尔伯特空间填充曲线叠加在地球投影上
请注意,基数(每个维度的桶数)会影响我们的希尔伯特指数的分辨率。这里我们通过16个桶从-180到+180进行映射,因此我们的分辨率不高于360/16,或者经度为22.5度(纬度为11.25度)。这并不意味着我们不能比这更准确地表示价值。它只是意味着我们的初始(粗略)索引(基于SFC范围)无法提供比此更好的解决方案。每个维度添加更多位将提高基于SFC的索引的精度。
Z-Order SFC
这通常也称为GeoHash或Morton顺序,有时被错误地称为Peano曲线。这是用于多维→1维映射的最流行的SFC,主要是因为它很容易在代码中实现。
为了实现这一点,理想情况下,使用比特交织方法(这就是图中基于Z-Order曲线的维度分解的图)。想象一下,我们有两个数字,A和B.让这些数字的二进制表示为A1A2A3和B1B2B3。“比特交错”版本将是A1B1A2B2A3B3。由于我们使用的是二进制数,因此它提供了2x2的“单元格”。如果我们添加尺寸,只需想象相同的交错,但另一个术语 - C1C2C3等。这有时在Base 10而不是Base 2中实现。这种实现在某种程度上减少了局部性(“包装属性” - 或者衡量n维空间中数字与1维空间中数字的接近程度)。正如您可能预期的那样,二维版本的单元格为10x10(二维) - 因此包装更差。
XZ-Order SFC
XZ-Order SFC是Z-Ordering的扩展,用于映射空间对象。这是通过将每个Z-Order维度的区域扩展2来完成的,以便支持映射空间 - 非点 - 对象,例如多边形或矩形。
分解
范围分解是基于SFC的索引概念的核心。这是当我们采用多维描述的范围并将其转换为一系列1维范围时。
希尔伯特分解1
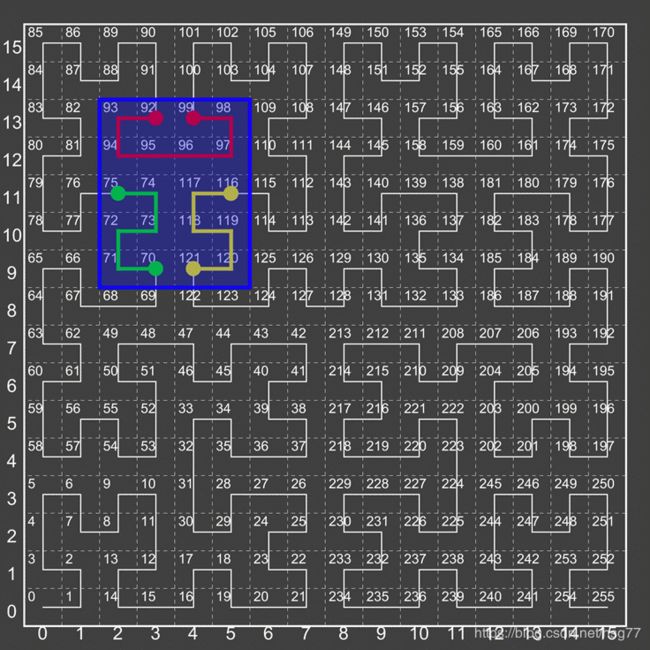
图19.希尔伯特分解1
图:希尔伯特山脉
在上图中,我们展示了我们的意思。蓝色选择窗口描述的边界框或(2,9)→(5,13)将“完全”分解为3个范围 - 70→75,92→99和116→121。
应该注意的是,有时更简单的算法不会完全分解,而是将其表示为70→121或甚至64→127(此框适合的最小“单元格”)。如您所见,这将导致扫描许多无关的细胞。
在某些时候,具有高精度,高维度曲线,可能的单位单元的数量可能变得太大而无法处理。在这种情况下,GeoWave通过将曲线视为“低基数”曲线而不是实际来优化这一点。因此单元格大小可能不是1,而是64,128,1024等。这使得用户在选择窗口很小时仍然可以实现高精度,但是不会花费过多的时间来完全分解大的选择窗口。
希尔伯特分解2
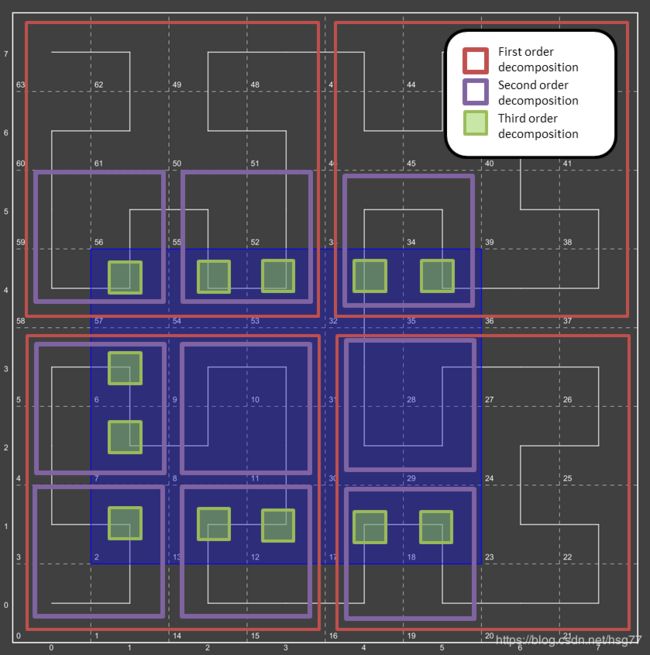
图20.希尔伯特分解2
考虑一个区域查询,询问来自的所有数据:
(1,1) - >(5,4)
此查询范围左侧显示为蓝色边界框。
我们在这做了什么?
我们将初始区域分解为4个子区域(红色框)。
我们将每个子区域(红色框)分解为4个子区域(紫色框)。
然后我们将每个紫色盒子分解成绿色盒子。
一旦我们有一个完全由边界框包含的分解四边形,我们就停止了分解。
我们没有打扰分解与原始搜索条件不重叠的区域。
希尔伯特分解3

图21.希尔伯特分解3
在这里,我们看到查询范围完全分解为底层的“四边形”。请注意,在某些情况下,当查询窗口完全包含四元组(段3和段8)时,我们能够停止分解。
希尔伯特分解4
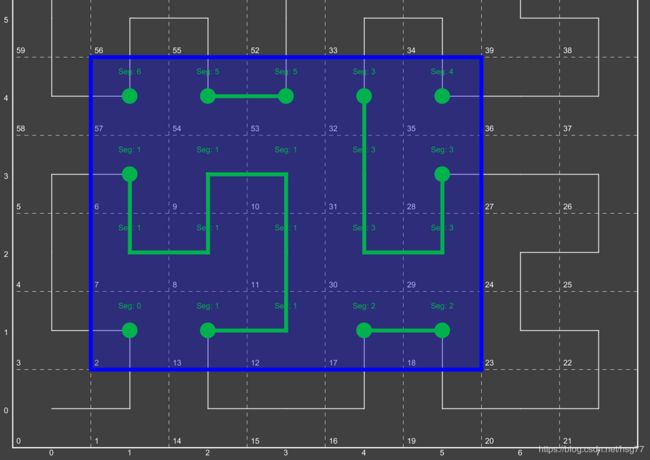
图22.希尔伯特分解4
现在我们已完全转换到前一组四边形的一维数字线。我们还将连续的区域汇总在一起。