目录
- 1. 什么是 Kudu
- 1.1 Kudu 的应用场景是什么?
- 1.2 Kudu 在大数据平台中的位置在哪?
- 1.3 Kudu 用什么样的设计, 才能满足其设计目标?
- 1.4 Kudu 中有什么集群角色?
- 2. 操作 Kudu
- 3. 如何设计 Kudu 的表
1. 什么是 Kudu
1.1 Kudu 的应用场景是什么?
设计一个项目,分析其特点,设计方案,选取最佳处理方案
需求:做一个类似物联网的项目, 可能是对某个工厂的生产数据进行分析
- 项目特点
1. 数据量大
- 有一个非常重大的挑战, 就是这些设备可能很多, 其所产生的事件记录可能也很大, 所以需要对设备进行数据收集和分析的话, 需要使用一些大数据的组件和功能

2. 流式处理
- 因为数据是事件, 事件是一个一个来的, 并且如果快速查看结果的话, 必须使用流计算来处理这些数据
3. 数据需要存储
- 最终需要对数据进行统计和分析, 所以数据要先有一个地方存, 后再通过可视化平台去分析和处理

- 对存储层的要求
这样的一个流计算系统, 需要对数据进行什么样的处理呢?
1.要能够及时的看到最近的数据, 判断系统是否有异常
2.要能够扫描历史数据, 从而改进设备和流程
所以对数据存储层就有可能进行如下的操作
1.逐行插入, 因为数据是一行一行来的, 要想及时看到, 就需要来一行插入一行 -->随机插入,OLTP较擅长
2.低延迟随机读取, 如果想分析某台设备的信息, 就需要在数据集中随机读取某一个设备的事件记录 -->OLTP
3.快速分析和扫描, 数据分析师需要快速的得到结论, 执行一行 SQL 等上十天是不行的 -->批量读取和分析,dfs
- 方案一:使用 Spark Streaming 配合 HDFS 存储
总结一下需求实时处理
- Spark Streaming
- 大数据存储, HDFS
- 使用 Kafka 过渡数据(可以过渡实时流数据)
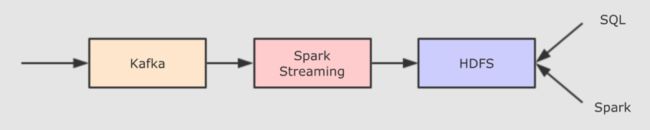
Q. 但是这样的方案有一个非常重大的问题, 就是速度机器之慢, 因为 HDFS 不擅长存储小文件, 而通过流处理直接写入 HDFS 的话, 会产生非常大量的小文件, 扫描性能十分的差