Impala的定位是一种新型的MPP查询引擎,但是它又不是典型的MPP类型的SQL引擎,提到MPP数据库首先想到的可能是GreenPlum,它的每一个节点完全独立,节点直接不共享数据,节点之间的信息传递全都通过网络实现。而Impala可以说是一个MPP计算引擎,它需要处理的数据存储在HDFS、Hbase或者Kudu之上,这些存储引擎都是独立于Impala的,可以称之为第三方存储引擎,Impala使用MPP的思想实现了计算。
对于每一个Impala执行的SQL,可能同时在多个工作节点上运行计算,每一个节点执行查询任务的一部分,然后通过网络通信传递给下一个子任务,中间数据尽可能的不落地(写磁盘,无论是本地还是第三方存储引擎)。之所以Impala能够提供较高性能的查询服务,最根本的原因就在于这两点:中间数据不落地;任务尽可能并行化。当然,还有一些实现细节也是非常重要的,本文就从一个SQL的执行过程来详细介绍Impala是如何处理查询的。
名词解释
- Impala:一个SQL查询引擎
- HDFS:分布式数据存储引擎
- catalogd:impala系统中的元数据服务节点
- statestored:impala系统中的消息同步节点
- impalad:impala系统中的任务执行节点
- coordinator:impalad节点中的协调者模块,对外提供查询接口,包括beeswax和HiveServer2接口
- backend:impalad节点中任务执行模块,提供执行任务的接口
- BE:impalad代码上划分的frontend部分,使用JAVA实现
- FE:impalad代码上划分的backend部分,使用C++实现
- beeswax接口:impalad提供的一种SQL查询接口。
- HiveServer2接口:impalad提供的一种兼容HiveServer2的接口。
- Analyser:Impala FE中实现的SQL解析器。
- Planner:Impala FE中实现的SQL执行计划生成器。
- PlanNode:SQL解析得到的逻辑执行计划中的节点基类,具体类型包括ScanNode、AggregationNode、HashJoinNode等。
- Fragment:SQL生成的分布式执行计划中的一个子任务,它包括执行计划的一个子树。
- ExchangeNode:比较特殊的一种PlanNode,处理前一个Fragment传递过来的数据。
- DataStreamSink:它不是PlanNode,用于传输当前Fragment输出数据到不同的节点。
系统架构
在真正介绍Impala查询执行流程之前,需要先贴上一张Impala的架构图镇楼,下图中描述了一个SQL查询的执行流程。
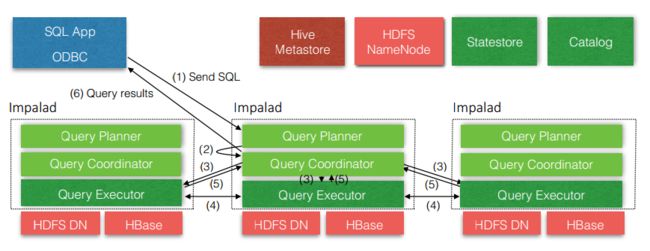
从上图中看出,可以首先大体上描述下一个SQL从提交到获取查询结果是经历了哪些步骤(下面的步骤和上图中步骤不一一对应):
- 1、客户端提交任务:客户端通过beeswax或者HiveServer2接口发送一个SQL查询请求到impalad节点,查询包括一条SQL和相关的configuration信息(只对本次查询生效),查询接口提供同步和异步的方式执行,两种接口都会返回一个queryId用于之后的客户端操作。
- **2、查询解析和分析:**SQL提交到impalad节点之后交由FE模块处理,由Analyser依次执行SQL的词法分析、语法分析、语义分析、查询重写等操作,生成该SQL的Statement信息。
- 3、单机执行计划生成:根据上一步生成的Statement信息,由Planner生成单机的执行计划,该执行计划是有PlanNode组成的一棵树,这个过程中也会执行一些SQL优化,例如Join顺序改变、谓词下推等。
- 4、分布式执行计划生成:由Planner将单机执行计划转换成分布式并行物理执行计划,物理执行计划由一个个的Fragment组成,Fragment之间有数据依赖关系,处理过程中需要在原有的执行计划之上加入一些ExchangeNode和DataStreamSink信息等。
- 5、任务调度和分发:由BE处理生成的分布式物理执行计划,将Fragment根据数据分区信息发配到不同的Impalad节点上执行。Impalad节点接收到执行Fragment请求交由Backend模块处理Fragment的执行。
- 6、子任务执行:每一个Fragment的执行输出通过DataStreamSink发送到下一个Fragment,由下一个Fragment的ExchangeNode接收,Fragment运行过程中不断向coordinator节点汇报当前运行状态。
- 7、结果汇总:查询的SQL通常情况下需要有一个单独的Fragment用于结果的汇总,它只在coordinator节点运行,将多个backend的最终执行结果汇总,转换成ResultSet信息。
- 8、客户端查询结果:客户端调用获取ResultSet的接口,读取查询结果。
- 9、关闭查询:客户端调用CloseOperation关闭本次查询,标志着本次查询的结束。
查询实例
本文下面的查询流程解析将使用如下介绍的一个关于在线购物系统的数据作为实例,本查询实例中包含了三个表,查询SQL如下:
select t1.goods_id, t1.title, count(1) as ba from
items t1
join
item_orders t2
on t1.goods_id = t2.goods_id
where
t2.day >= '2017-04-29'
and
t2.day <= '2017-05-01'
and
t1.cat1_id in ('438', '437', '440', '381')
and
t2.order_id in (select order_id from orders where order_status in ('1','2'))
group by
t1.goods_id, t1.title
having
count(distinct t2.buy_account) > 1000
order by ba desc
limit 30
使用的三个表如下:
- items:商品详细信息表,即商品维度表,记录数100W左右。
- item_orders:每日增加的订单记录,事实表,每日新增记录大约为100W。
- orders:订单维度表,包含每一个订单实时的信息,记录数为1亿。
该查询实现这样的需求:查询2017年五一三天假期中满足一定条件购买次数TOP 30的商品,条件为:商品的类目属于指定四类,商品的订单状态是1、2两种并且这三天购买的人数大于1000。
这个查询是一个典型的OLAP分析查询,从SQL结构上看,包括了多个join,子查询,过滤信息和聚合操作。
总结
本文主要根据Impala系统架构从宏观角度上分析了一个OLAP查询在Impala执行的流程,并且附上了再具体业务查询中遇到的一个典型的OLAP查询实例,后面我们将根据这个例子详细解析Impala处理该查询的几个关联步骤,未完待续。