[asp]让你知道codepage的重要
这几天研究UTF-8编码,太晕了,把我的看法和各位讨论讨论。
欢迎来批啊。以下都是我的想法,哪里有不对的请不吝赐教,帮忙指出来。
相关的题外话:
一、操作系统
window系统内部都是unicode的。文件夹名,文件名等都是unicode的,任何语言系统下都能正常显示。
二、输入法:
微软拼音输出的是Unicode的,智能ABC输出是简体中文的(所以智能ABC在非简体中文系统根本不能用,只能打英文)。
三、网页的textarea
网页的textarea是用unicode显示的。所以往里打什么字都能显示。而一些flash做的输入框就不行了。
四、Access2000
access里面保存的数据是unicode的,在任何语言系统下都能显示。
如果数据视图查看有些字符不正常,那是因为显示所用的字体不是Unicode字体,
换用Arial Unicode MS 字体就能全部显示了。(access帮助,搜索,输入unicode,有说明)
五、Word
word里的繁简转换,简体转换到繁体后,内码仍是简体中文的,其实只是简体中的繁体字。
六、ASP内部是Unicode的,所有文本都是Unicode存储的。需要时转换到指定字符集。
首先说下结论:
<%@ codepage=936%>简体中文
<%@ codepage=950%>繁体中文
<%@ codepage=65001%>UTF-8
codepage指定了IIS按什么编码读取传递过来的串串(表单提交,地址栏传递等)。
也指定了所有文本变量从Unicode转换到的编码,
也就指定了从数据库取出的数据从Unicode转换到的编码。(注意这个,很重要。)
关键字:
读取:一个串串,按简体读取是一些字,按繁体读取是一些字,串串本身编码没有变。
转换:系统主动的转换,比如从Unicode的“化”字到Big5的“化”字,内码变成Big5的。如果Big5没有对应的字,保留Unicode形式(&#xxxx;)
简体中文:化六个结论
Unicode16进制形式:化六个结论
Unicode10进制形式:化六个结论
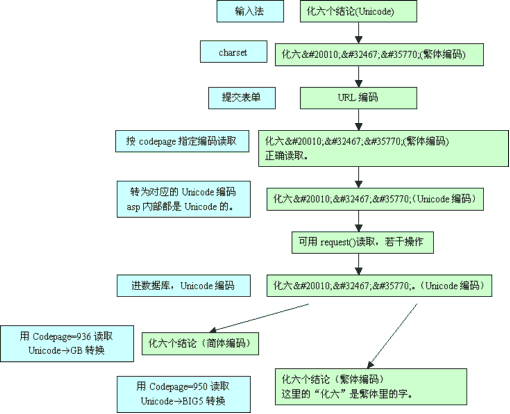
下面是我推测出来的编码转换的过程:
客户端:输入法Unicode--输入框unicode--从Unicode按charset转换到对应编码()--表单发送编码
服务器端:IIS解开表单编码--按codepage指定编码读取--转换到对应的Unicode--可以用request("")读取了--进行一些处理--以Unicode编码保存到数据库
服务器端:读取数据库的Unicode数据,转换到codepage指定编码---生成源代码--IE按charset读取显示。
下面举两个例说明:
例一:
假设有三个asp页面,典型的留言页面:
1.write.asp 简单的输入表单,提交到add.asp。
2.add.asp 接收留言,保存到数据库
<%@ codepage=936%>
3.read.asp 从数据库取得留言,显示。
<%@ codepage=936%> charset=GB2312 或
<%@ codepage=950%> charset=big5
大家可以猜一猜,我在write.asp里用微软拼音输入法输入“化六个讨论”。最后在read.asp里会显示什么样?
是不是晕了。让我们从头分析。

例二:
把例一的add.asp的<%@ codepage=936%>改为<%@ codepage=950%>,又会怎么样呢?
到这里发现了什么?
1.如果输入的文字和Charset对应的不同,一转换,就可能出现Unicode形式的字了。这里就是原因所在。以后整个过程都保留着。
2.Add.asp里codepage决定了保存到数据库的文字,用的是哪个语言对应的Unicode.如codepage=936,
那么数据库保存的就是简体中文的Unicode(数据库拿回简体中文系统,一切正常的),
codepage=950保存的就是繁体中文的Unicode.(拿回简体中文系统,就不对了)。
3.注意一下串串的变化过程:
1)输入法---CharsetUnicode----指定字符集的映射
2)Charset----表单编码串串简单编码
3)表单解码上步的逆过程,两步抵消了。
4)串串à按codepage读取串串没变,这步有可能“误会读取”
5)转为对应的Unicode Codepage指定字符集----Unicode映射
6)中间处理,进数据库无变化,直接以Unicode形式进入
7)按codepage读取数据库 Unicode----codepage指定字符集的映射
8)显示,按Charset指定字符集读取串串没变。
以例一说明:

例二:

晕了。现在来用用知识。
案例1:
简体中文系统下跑的好好的代码,放到国外空间上,数据库里乱码,原有的数据也乱码。
分析:因为大多数人平时用的都是简体中文系统,默认的codepage=936,所以平时大家不写也没有关系。
但到了国外空间问题就出来了。从数据库里的Unicode转换到英文编码去了,所以数据库原有的简体中文转换到英文后,按GB显示自然乱码。
如图,新输入的文字显示正常,但数据库里保存的是英文的Unicode的。
解决方法:全部加上<%@codepage=936%>即可。
全程只有简体中文与对应Unicode间的转换。

案例二:
简体中文的代码和数据,想转为完全的繁体版,该怎么办?
分析:1。代码文件编码全部改为Big5的,文件本身保存编码选繁体。
2.<%@ codepage=936 %>
3.Charset=big5
4.access版本无所谓,因为access里的数据是Unicode的。
5.好了,代码可以在纯繁体系统下跑了。
6.遗留问题:原有的简体中文数据读出会有一些问号。效果同例一的950读取,big5显示。因为从简体中文的Unicode转换到繁体中文了,有些字繁体中没有,就会出问号。
7.解决:用一个临时asp页,codepage=65001,读出为简体中文的Unicode,用一个Unicode->Big5的函数,转为繁体中文,然后写回数据库,应该行了吧?
两个案例完全是我按照理论推导出来了,未经证实。
有类似经历的欢迎批评指正。
论坛的相关讨论:http://www.blueidea.com/bbs/NewsDetail.asp?id=1831362
--------------------------------------------------------------------------------------------------------------------------------------------
Codepage简介
1. Codepage的定义和历史
字符内码(charcter code)指的是用来代表字符的内码.读者在输入和存储文档时都要使用内码,内码分为
- 单字节内码 -- Single-Byte character sets (SBCS),可以支持256个字符编码.
- 双字节内码 -- Double-Byte character sets)(DBCS),可以支持65000个字符编码.主要用来对大字符集的东方文字进行编码.
codepage 指的是一个经过挑选的以特定顺序排列的字符内码列表,对于早期的单字节内码的语种,codepage中的内码顺序使得系统可以按照此列表来根据键盘的输入值给出一个对应的内码.对于双字节内码,则给出的是MultiByte到Unicode的对应表,这样就可以把以Unicode形式存放的字符转化为相应的字符内码,或者反之,在Linux核心中对应的函数就是utf8_mbtowc和utf8_wctomb.
在1980年前,仍然没有任何国际标准如ISO-8859或Unicode来定义如何扩展US-ASCII编码以便非英语国家的用户使用.很多IT 厂商发明了他们自己的编码,并且使用了难以记忆的数目来标识:
例如 936代表简体中文. 950代表繁体中文.
1.1 CJK Codepage
同 Extended Unix Coding ( EUC )编码大不一样的是,下面所有的远东 codepage 都利用了C1控制码 { =80..=9F } 做为首字节, 使用ASCII值 { =40..=7E { 做为第二字节,这样才能包含多达数万个双字节字符,这表明在这种编码之中小于3F的ASCII值不一定代表ASCII字符.
CP932
Shift-JIS包含日本语 charset JIS X 0201 (每个字符一个字节) 和 JIS X 0208 (每个字符两个字节),所以 JIS X 0201平假名包含一个字节半宽的字符,其剩馀的60个字节被用做7076个汉字以及648个其他全宽字符的首字节.同EUC-JP编码区别的是, Shift-JIS没有包含JIS X 202中定义的5802个汉字.
CP936
GBK 扩展了 EUC-CN 编码( GB 2312-80编码,包含 6763 个汉字)到Unicode (GB13000.1-93)中定义的20902个汉字,中国大陆使用的是简体中文zh_CN.
CP949
UnifiedHangul (UHC) 是韩文 EUC-KR 编码(KS C 5601-1992 编码,包括2350 韩文音节和 4888 个汉字a)的超集,包含 8822个附加的韩文音节( 在C1中 )
CP950
是代替EUC-TW (CNS 11643-1992)的 Big5 编码(13072 繁体 zh_TW 中文字) 繁体中文,这些定义都在Ken Lunde的 CJK.INF中或者 Unicode 编码表中找到.
注意: Microsoft采用以上四种Codepage,因此要访问Microsoft的文件系统时必需采用上面的Codepage .
1.2 IBM的远东语言Codepage
IBM的Codepage分为SBCS和DBCS两种:
IBM SBCS Codepage
37 (英文) * 290 (日文) * 833 (韩文) * 836 (简体中文) * 891 (韩文) 897 (日文) 903 (简体中文) 904 (繁体中文)IBM DBCS Codepage
300 (日文) * 301 (日文) 834 (韩文) * 835 (繁体中文) * 837 (简体中文) * 926 (韩文) 927 (繁体中文) 928 (简体中文)将SBCS的Codepage和DBCS的Codepage混合起来就成为: IBM MBCS Codepage
930 (日文) (Codepage 300 加 290) * 932 (日文) (Codepage 301 加 897) 933 (韩文) (Codepage 834 加 833) * 934 (韩文) (Codepage 926 加 891) 938 (繁体中文) (Codepage 927 加 904) 936 (简体中文) (Codepage 928 加 903) 5031 (简体中文) (Codepage 837 加 836) * 5033 (繁体中文) (Codepage 835 加 37) **代表采用EBCDIC编码格式
由此可见,Mircosoft的CJK Codepage来源于IBM的Codepage.
2. Linux下Codepage的作用
在Linux下引入对Codepage的支持主要是为了访问FAT/VFAT/FAT32/NTFS/NCPFS等文件系统下的多语种文件名的问题,目前在NTFS和FAT32/VFAT下的文件系统上都使用了Unicode,这就需要系统在读取这些文件名时动态将其转换为相应的语言编码.因此引入了NLS支持.其相应的程序文件在/usr/src/linux/fs/nls下:
- Config.in
- Makefile
- nls_base.c
- nls_cp437.c
- nls_cp737.c
- nls_cp775.c
- nls_cp850.c
- nls_cp852.c
- nls_cp855.c
- nls_cp857.c
- nls_cp860.c
- nls_cp861.c
- nls_cp862.c
- nls_cp863.c
- nls_cp864.c
- nls_cp865.c
- nls_cp866.c
- nls_cp869.c
- nls_cp874.c
- nls_cp936.c
- nls_cp950.c
- nls_iso8859-1.c
- nls_iso8859-15.c
- nls_iso8859-2.c
- nls_iso8859-3.c
- nls_iso8859-4.c
- nls_iso8859-5.c
- nls_iso8859-6.c
- nls_iso8859-7.c
- nls_iso8859-8.c
- nls_iso8859-9.c
- nls_koi8-r.c
实现了下列函数:
- extern int utf8_mbtowc(__u16 *, const __u8 *, int);
- extern int utf8_mbstowcs(__u16 *, const __u8 *, int);
- extern int utf8_wctomb(__u8 *, __u16, int);
- extern int utf8_wcstombs(__u8 *, const __u16 *, int);
这样在加载相应的文件系统时就可以用下面的参数来设置Codepage:
对于Codepage 437 来说
mount -t vfat /dev/hda1 /mnt/1 -o codepage=437,iocharset=cp437
这样在Linux下就可以正常访问不同语种的长文件名了.
3. Linux下支持的Codepage
nls codepage 437 -- 美国/加拿大英语nls codepage 737 -- 希腊语nls codepage 775 -- 波罗的海语nls codepage 850 -- 包括西欧语种(德语,西班牙语,意大利语)中的一些字符nls codepage 852 -- Latin 2 包括中东欧语种(阿尔巴尼亚语,克罗地亚语,捷克语,英语,芬兰语,匈牙利语,爱尔兰语,德语,波兰语,罗马利亚语,塞尔维亚语,斯洛伐克语,斯洛文尼亚语,Sorbian语)nls codepage 855 -- 斯拉夫语nls codepage 857 -- 土耳其语nls codepage 860 -- 葡萄牙语nls codepage 861 -- 冰岛语nls codepage 862 -- 希伯来语nls codepage 863 -- 加拿大语nls codepage 864 -- 阿拉伯语nls codepage 865 -- 日尔曼语系nls codepage 866 -- 斯拉夫语/俄语nls codepage 869 -- 希腊语(2)nls codepage 874 -- 泰语nls codepage 936 -- 简体中文GBKnls codepage 950 -- 繁体中文Big5nls iso8859-1 -- 西欧语系(阿尔巴尼亚语,西班牙加泰罗尼亚语,丹麦语,荷兰语,英语,Faeroese语,芬兰语,法语,德语,加里西亚语,爱尔兰语,冰岛语,意大利语,挪威语,葡萄牙语,瑞士语.)这同时适用于美国英语.nls iso8859-2 -- Latin 2 字符集,斯拉夫/中欧语系(捷克语,德语,匈牙利语,波兰语,罗马尼亚语,克罗地亚语,斯洛伐克语,斯洛文尼亚语)nls iso8859-3 -- Latin 3 字符集, (世界语,加里西亚语,马耳他语,土耳其语)nls iso8859-4 -- Latin 4 字符集, (爱莎尼亚语,拉脱维亚语,立陶宛语),是Latin 6 字符集的前序标准nls iso8859-5 -- 斯拉夫语系(保加利亚语,Byelorussian语,马其顿语,俄语,塞尔维亚语,乌克兰语) 一般推荐使用 KOI8-R codepagenls iso8859-6 -- 阿拉伯语.nls iso8859-7 -- 现代希腊语nls iso8859-8 -- 希伯来语nls iso8859-9 -- Latin 5 字符集, (去掉了 Latin 1中不经常使用的一些冰岛语字符而代以土耳其语字符)nls iso8859-10 -- Latin 6 字符集, (因纽特(格陵兰)语,萨摩斯岛语等Latin 4 中没有包括的北欧语种)nls iso8859-15 -- Latin 9 字符集, 是Latin 1字符集的更新版本,去掉一些不常用的字符,增加了对爱莎尼亚语的支持,修正了法语和芬兰语部份,增加了欧元字符)nls koi8-r -- 俄语的缺省支持
4. 简体中文GBK/繁体中文Big5的Codepage
如何制作简体中文GBK/繁体中文Big5的Codepage?
- 从 Unicode 组织取得GBK/Big5的Unicode的定义.
由于GBK是基于ISO 10646-1:1993标准的,而相应的日文是JIS X 0221-1995,韩文是KS C 5700-1995,他们被提交到Unicode标准的时间表为:
Unicode Version 1.0
Unicode Version 1.1 <-> ISO 10646-1:1993, JIS X 0221-1995, GB 13000.1-93
Unicode Version 2.0 <-> KS C 5700-1995从Windows 95开始均采用GBK编码. 您需要的是 CP936.TXT和 BIG5.TXT
- 然后使用下面的程序就可以将其转化为Linux核心需要的Unicode<->GBK码表
./genmap BIG5.txt | perl uni2big5.pl./genmap CP936.txt | perl uni2gbk.pl - 再修改fat/vfat/ntfs的相关函数就可以完成对核心的修改工作. 具体使用时可以使用下面的命令:
有趣的是,由于GBK包含了全部的GB2312/Big5/JIS的内码,所以使用936的Codepage也可以显示Big5的文件名.
5. 附录
5.1 作者和相关文档
制作codepage950支持的是台湾的 cosmos先生, 主页为http://www.cis.nctu.edu.tw:8080/~is84086/Project/kernel_cp950/
制作GBK的cp936支持的是TurboLinux的中文研发小组的 方汉和陈向阳
5.2 genmap
#!/bin/sh
cat $1 | awk '{if(index($1,"#")==0)print $0}' | awk 'BEGIN{FS="0x"}{print $2 $3}' | awk '{if(length($1)==length($2))print $1,$2}'
5.3 uni2big5.pl
#!/usr/bin/perl
@code = (
"00", "01", "02", "03", "04", "05", "06", "07",
"08", "09", "0A", "0B", "0C", "0D", "0E", "0F",
"10", "11", "12", "13", "14", "15", "16", "17",
"18", "19", "1A", "1B", "1C", "1D", "1E", "1F",
"20", "21", "22", "23", "24", "25", "26", "27",
"28", "29", "2A", "2B", "2C", "2D", "2E", "2F",
"30", "31", "32", "33", "34", "35", "36", "37",
"38", "39", "3A", "3B", "3C", "3D", "3E", "3F",
"40", "41", "42", "43", "44", "45", "46", "47",
"48", "49", "4A", "4B", "4C", "4D", "4E", "4F",
"50", "51", "52", "53", "54", "55", "56", "57",
"58", "59", "5A", "5B", "5C", "5D", "5E", "5F",
"60", "61", "62", "63", "64", "65", "66", "67",
"68", "69", "6A", "6B", "6C", "6D", "6E", "6F",
"70", "71", "72", "73", "74", "75", "76", "77",
"78", "79", "7A", "7B", "7C", "7D", "7E", "7F",
"80", "81", "82", "83", "84", "85", "86", "87",
"88", "89", "8A", "8B", "8C", "8D", "8E", "8F",
"90", "91", "92", "93", "94", "95", "96", "97",
"98", "99", "9A", "9B", "9C", "9D", "9E", "9F",
"A0", "A1", "A2", "A3", "A4", "A5", "A6", "A7",
"A8", "A9", "AA", "AB", "AC", "AD", "AE", "AF",
"B0", "B1", "B2", "B3", "B4", "B5", "B6", "B7",
"B8", "B9", "BA", "BB", "BC", "BD", "BE", "BF",
"C0", "C1", "C2", "C3", "C4", "C5", "C6", "C7",
"C8", "C9", "CA", "CB", "CC", "CD", "CE", "CF",
"D0", "D1", "D2", "D3", "D4", "D5", "D6", "D7",
"D8", "D9", "DA", "DB", "DC", "DD", "DE", "DF",
"E0", "E1", "E2", "E3", "E4", "E5", "E6", "E7",
"E8", "E9", "EA", "EB", "EC", "ED", "EE", "EF",
"F0", "F1", "F2", "F3", "F4", "F5", "F6", "F7",
"F8", "F9", "FA", "FB", "FC", "FD", "FE", "FF");
while (){
($unicode, $big5) = split;
($high, $low) = $unicode =~ /(..)(..)/;
$table2{$high}{$low} = $big5;
($high, $low) = $big5 =~ /(..)(..)/;
$table{$high}{$low} = $unicode;
}
print <
#include
#include
#include
/* A1 - F9*/
static struct nls_unicode charset2uni[(0xF9-0xA1+1)*(0x100-0x60)] = {
EOF
for ($high=0xA1; $high <= 0xF9; $high++){
for ($low=0x40; $low <= 0x7F; $low++){
$unicode = $table2{$code[$high]}{$code[$low]};
$unicode = "0000" if (!(defined $unicode));
print "/n/t" if ($low%4 == 0);
print "/* $code[$high]$code[$low]*//n/t" if ($low%0x10 == 0);
($uhigh, $ulow) = $unicode =~ /(..)(..)/;
printf("{0x%2s, 0x%2s}, ", $ulow, $uhigh);
}
for ($low=0xA0; $low <= 0xFF; $low++){
$unicode = $table2{$code[$high]}{$code[$low]};
$unicode = "0000" if (!(defined $unicode));
print "/n/t" if ($low%4 == 0);
print "/* $code[$high]$code[$low]*//n/t" if ($low%0x10 == 0);
($uhigh, $ulow) = $unicode =~ /(..)(..)/;
printf("{0x%2s, 0x%2s}, ", $ulow, $uhigh);
}
}
print "/n};/n/n";
for ($high=1; $high <= 255;$high++){
if (defined $table{$code[$high]}){
print "static unsigned char page$code[$high]/[512/] = {/n/t";
for ($low=0; $low<=255;$low++){
$big5 = $table{$code[$high]}{$code[$low]};
$big5 = "3F3F" if (!(defined $big5));
if ($low > 0 && $low%4 == 0){
printf("/* 0x%02X-0x%02X *//n/t", $low-4, $low-1);
}
print "/n/t" if ($low == 0x80);
($bhigh, $blow) = $big5 =~ /(..)(..)/;
printf("0x%2s, 0x%2s, ", $bhigh, $blow);
}
print "/* 0xFC-0xFF *//n};/n/n";
}
}
print "static unsigned char *page_uni2charset[256] = {";
for ($high=0; $high<=255;$high++){
print "/n/t" if ($high%8 == 0);
if ($high>0 && defined $table{$code[$high]}){
print "page$code[$high], ";
}
else{
print "NULL, ";
}
}
print <
5.4 uni2gbk.pl
#!/usr/bin/perl
@code = (
"00", "01", "02", "03", "04", "05", "06", "07",
"08", "09", "0A", "0B", "0C", "0D", "0E", "0F",
"10", "11", "12", "13", "14", "15", "16", "17",
"18", "19", "1A", "1B", "1C", "1D", "1E", "1F",
"20", "21", "22", "23", "24", "25", "26", "27",
"28", "29", "2A", "2B", "2C", "2D", "2E", "2F",
"30", "31", "32", "33", "34", "35", "36", "37",
"38", "39", "3A", "3B", "3C", "3D", "3E", "3F",
"40", "41", "42", "43", "44", "45", "46", "47",
"48", "49", "4A", "4B", "4C", "4D", "4E", "4F",
"50", "51", "52", "53", "54", "55", "56", "57",
"58", "59", "5A", "5B", "5C", "5D", "5E", "5F",
"60", "61", "62", "63", "64", "65", "66", "67",
"68", "69", "6A", "6B", "6C", "6D", "6E", "6F",
"70", "71", "72", "73", "74", "75", "76", "77",
"78", "79", "7A", "7B", "7C", "7D", "7E", "7F",
"80", "81", "82", "83", "84", "85", "86", "87",
"88", "89", "8A", "8B", "8C", "8D", "8E", "8F",
"90", "91", "92", "93", "94", "95", "96", "97",
"98", "99", "9A", "9B", "9C", "9D", "9E", "9F",
"A0", "A1", "A2", "A3", "A4", "A5", "A6", "A7",
"A8", "A9", "AA", "AB", "AC", "AD", "AE", "AF",
"B0", "B1", "B2", "B3", "B4", "B5", "B6", "B7",
"B8", "B9", "BA", "BB", "BC", "BD", "BE", "BF",
"C0", "C1", "C2", "C3", "C4", "C5", "C6", "C7",
"C8", "C9", "CA", "CB", "CC", "CD", "CE", "CF",
"D0", "D1", "D2", "D3", "D4", "D5", "D6", "D7",
"D8", "D9", "DA", "DB", "DC", "DD", "DE", "DF",
"E0", "E1", "E2", "E3", "E4", "E5", "E6", "E7",
"E8", "E9", "EA", "EB", "EC", "ED", "EE", "EF",
"F0", "F1", "F2", "F3", "F4", "F5", "F6", "F7",
"F8", "F9", "FA", "FB", "FC", "FD", "FE", "FF");
while (){
($unicode, $big5) = split;
($high, $low) = $unicode =~ /(..)(..)/;
$table2{$high}{$low} = $big5;
($high, $low) = $big5 =~ /(..)(..)/;
$table{$high}{$low} = $unicode;
}
print <
#include
#include
#include
/* 81 - FE*/
static struct nls_unicode charset2uni[(0xFE-0x81+1)*(0x100-0x40)] = {
EOF
for ($high=0x81; $high <= 0xFE; $high++){
for ($low=0x40; $low <= 0x7F; $low++){
$unicode = $table2{$code[$high]}{$code[$low]};
$unicode = "0000" if (!(defined $unicode));
print "/n/t" if ($low%4 == 0);
print "/* $code[$high]$code[$low]*//n/t" if ($low%0x10 == 0);
($uhigh, $ulow) = $unicode =~ /(..)(..)/;
printf("{0x%2s, 0x%2s}, ", $ulow, $uhigh);
}
for ($low=0x80; $low <= 0xFF; $low++){
$unicode = $table2{$code[$high]}{$code[$low]};
$unicode = "0000" if (!(defined $unicode));
print "/n/t" if ($low%4 == 0);
print "/* $code[$high]$code[$low]*//n/t" if ($low%0x10 == 0);
($uhigh, $ulow) = $unicode =~ /(..)(..)/;
printf("{0x%2s, 0x%2s}, ", $ulow, $uhigh);
}
}
print "/n};/n/n";
for ($high=1; $high <= 255;$high++){
if (defined $table{$code[$high]}){
print "static unsigned char page$code[$high]/[512/] = {/n/t";
for ($low=0; $low<=255;$low++){
$big5 = $table{$code[$high]}{$code[$low]};
$big5 = "3F3F" if (!(defined $big5));
if ($low > 0 && $low%4 == 0){
printf("/* 0x%02X-0x%02X *//n/t", $low-4, $low-1);
}
print "/n/t" if ($low == 0x80);
($bhigh, $blow) = $big5 =~ /(..)(..)/;
printf("0x%2s, 0x%2s, ", $bhigh, $blow);
}
print "/* 0xFC-0xFF *//n};/n/n";
}
}
print "static unsigned char *page_uni2charset[256] = {";
for ($high=0; $high<=255;$high++){
print "/n/t" if ($high%8 == 0);
if ($high>0 && defined $table{$code[$high]}){
print "page$code[$high], ";
}
else{
print "NULL, ";
}
}
print <
5.5 转换CODEPAGE的工具
/*
* CPI.C: A program to examine MSDOS codepage files (*.cpi)
* and extract specific codepages.
* Compiles under Linux & DOS (using BC++ 3.1).
*
* Compile: gcc -o cpi cpi.c
* Call: codepage file.cpi [-a|-l|nnn]
*
* Author: Ahmed M. Naas ([email protected])
* Many changes: [email protected] [changed until it would handle all
* *.cpi files people have sent me; I have no documentation,
* so all this is experimental]
* Remains to do: DRDOS fonts.
*
* Copyright: Public domain.
*/
#include
#include
#include
#include
int handle_codepage(int);
void handle_fontfile(void);
#define PACKED __attribute__ ((packed))
/* Use this (instead of the above) to compile under MSDOS */
/*#define PACKED */
struct {
unsigned char id[8] PACKED;
unsigned char res[8] PACKED;
unsigned short num_pointers PACKED;
unsigned char p_type PACKED;
unsigned long offset PACKED;
} FontFileHeader;
struct {
unsigned short num_codepages PACKED;
} FontInfoHeader;
struct {
unsigned short size PACKED;
unsigned long off_nexthdr PACKED;
unsigned short device_type PACKED; /* screen=1; printer=2 */
unsigned char device_name[8] PACKED;
unsigned short codepage PACKED;
unsigned char res[6] PACKED;
unsigned long off_font PACKED;
} CPEntryHeader;
struct {
unsigned short reserved PACKED;
unsigned short num_fonts PACKED;
unsigned short size PACKED;
} CPInfoHeader;
struct {
unsigned char height PACKED;
unsigned char width PACKED;
unsigned short reserved PACKED;
unsigned short num_chard PACKED;
} ScreenFontHeader;
struct {
unsigned short p1 PACKED;
unsigned short p2 PACKED;
} PrinterFontHeader;
FILE *in, *out;
void usage(void);
int opta, optc, optl, optL, optx;
extern int optind;
extern char *optarg;
unsigned short codepage;
int main (int argc, char *argv[])
{
if (argc < 2)
usage();
if ((in = fopen(argv[1], "r")) == NULL) {
printf("/nUnable to open file %s./n", argv[1]);
exit(0);
}
opta = optc = optl = optL = optx = 0;
optind = 2;
if (argc == 2)
optl = 1;
else
while(1) {
switch(getopt(argc, argv, "alLc")) {
case 'a':
opta = 1;
continue;
case 'c':
optc = 1;
continue;
case 'L':
optL = 1;
continue;
case 'l':
optl = 1;
continue;
case '?':
default:
usage();
case -1:
break;
}
break;
}
if (optind != argc) {
if (optind != argc-1 || opta)
usage();
codepage = atoi(argv[optind]);
optx = 1;
}
if (optc)
handle_codepage(0);
else
handle_fontfile();
if (optx) {
printf("no page %d found/n", codepage);
exit(1);
}
fclose(in);
return (0);
}
void
handle_fontfile(){
int i, j;
j = fread(, 1, sizeof(FontFileHeader), in);
if (j != sizeof(FontFileHeader)) {
printf("error reading FontFileHeader - got %d chars/n", j);
exit (1);
}
if (!strcmp(FontFileHeader.id + 1, "DRFONT ")) {
printf("this program cannot handle DRDOS font files/n");
exit(1);
}
if (optL)
printf("FontFileHeader: id=%8.8s res=%8.8s num=%d typ=%c offset=%ld/n/n",
FontFileHeader.id, FontFileHeader.res,
FontFileHeader.num_pointers,
FontFileHeader.p_type,
FontFileHeader.offset);
j = fread(, 1, sizeof(FontInfoHeader), in);
if (j != sizeof(FontInfoHeader)) {
printf("error reading FontInfoHeader - got %d chars/n", j);
exit (1);
}
if (optL)
printf("FontInfoHeader: num_codepages=%d/n/n",
FontInfoHeader.num_codepages);
for (i = FontInfoHeader.num_codepages; i; i--)
if (handle_codepage(i-1))
break;
}
int
handle_codepage(int more_to_come) {
int j;
char outfile[20];
unsigned char *fonts;
long inpos, nexthdr;
j = fread(, 1, sizeof(CPEntryHeader), in);
if (j != sizeof(CPEntryHeader)) {
printf("error reading CPEntryHeader - got %d chars/n", j);
exit(1);
}
if (optL) {
int t = CPEntryHeader.device_type;
printf("CPEntryHeader: size=%d dev=%d [%s] name=%8.8s /
codepage=%d/n/t/tres=%6.6s nxt=%ld off_font=%ld/n/n",
CPEntryHeader.size,
t, (t==1) ? "screen" : (t==2) ? "printer" : "?",
CPEntryHeader.device_name,
CPEntryHeader.codepage,
CPEntryHeader.res,
CPEntryHeader.off_nexthdr, CPEntryHeader.off_font);
} else if (optl) {
printf("/nCodepage = %d/n", CPEntryHeader.codepage);
printf("Device = %.8s/n", CPEntryHeader.device_name);
}
#if 0
if (CPEntryHeader.size != sizeof(CPEntryHeader)) {
/* seen 26 and 28, so that the difference below is -2 or 0 */
if (optl)
printf("Skipping %d bytes of garbage/n",
CPEntryHeader.size - sizeof(CPEntryHeader));
fseek(in, CPEntryHeader.size - sizeof(CPEntryHeader),
SEEK_CUR);
}
#endif
if (!opta && (!optx || CPEntryHeader.codepage != codepage) && !optc)
goto next;
inpos = ftell(in);
if (inpos != CPEntryHeader.off_font && !optc) {
if (optL)
printf("pos=%ld font at %ld/n", inpos, CPEntryHeader.off_font);
fseek(in, CPEntryHeader.off_font, SEEK_SET);
}
j = fread(, 1, sizeof(CPInfoHeader), in);
if (j != sizeof(CPInfoHeader)) {
printf("error reading CPInfoHeader - got %d chars/n", j);
exit(1);
}
if (optl) {
printf("Number of Fonts = %d/n", CPInfoHeader.num_fonts);
printf("Size of Bitmap = %d/n", CPInfoHeader.size);
}
if (CPInfoHeader.num_fonts == 0)
goto next;
if (optc)
return 0;
sprintf(outfile, "%d.cp", CPEntryHeader.codepage);
if ((out = fopen(outfile, "w")) == NULL) {
printf("/nUnable to open file %s./n", outfile);
exit(1);
} else printf("/nWriting %s/n", outfile);
fonts = (unsigned char *) malloc(CPInfoHeader.size);
fread(fonts, CPInfoHeader.size, 1, in);
fwrite(, sizeof(CPEntryHeader), 1, out);
fwrite(, sizeof(CPInfoHeader), 1, out);
j = fwrite(fonts, 1, CPInfoHeader.size, out);
if (j != CPInfoHeader.size) {
printf("error writing %s - wrote %d chars/n", outfile, j);
exit(1);
}
fclose(out);
free(fonts);
if (optx) exit(0);
next:
/*
* It seems that if entry headers and fonts are interspersed,
* then nexthdr will point past the font, regardless of
* whether more entries follow.
* Otherwise, first all entry headers are given, and then
* all fonts; in this case nexthdr will be 0 in the last entry.
*/
nexthdr = CPEntryHeader.off_nexthdr;
if (nexthdr == 0 || nexthdr == -1) {
if (more_to_come) {
printf("mode codepages expected, but nexthdr=%ld/n",
nexthdr);
exit(1);
} else
return 1;
}
inpos = ftell(in);
if (inpos != CPEntryHeader.off_nexthdr) {
if (optL)
printf("pos=%ld nexthdr at %ld/n", inpos, nexthdr);
if (opta && !more_to_come) {
printf("no more code pages, but nexthdr != 0/n");
return 1;
}
fseek(in, CPEntryHeader.off_nexthdr, SEEK_SET);
}
return 0;
}
void usage(void)
{
printf("/nUsage: cpi code_page_file [-c] [-L] [-l] [-a|nnn]/n");
printf(" -c: input file is a single codepage/n");
printf(" -L: print header info (you don't want to see this)/n");
printf(" -l or no option: list all codepages contained in the file/n");
printf(" -a: extract all codepages from the file/n");
printf(" nnn (3 digits): extract codepage nnn from the file/n");
printf("Example: cpi ega.cpi 850 /n");
printf(" will create a file 850.cp containing the requested codepage./n/n");
exit(1);
}