疫情一码通背后的超大数据仓库设计
tips:可以重点关注下PPT中的内容 ,PPT截图来自 2020-07直播课内容
1 防控平台引出GaussDB

平台层面 + 上层应用层面
上层应用从原来每天100w的调用查询量 ==> 提升到每天2000w次的调用查询量 ;
1.目前总计(GaussDB加工集群+GaussDB查询集群)250+个节点,共计 1PB的数据量。
2.最大集群的规模108个节点,500TB 数据量
3.每天有将近1w张表的数据 入库,30亿条数据进行加工处理–> 来生成疫情防控需要的一些专题数据,去支撑疫情防控平台,每张表平均 30w 条数据?

2017年正式上华为的公有云,华为的DWS服务
DWS2.0 多模引擎 实时数仓
2 GaussDB DWS分布式架构和执行流程

- GaussDB数据库是share-nothing的架构:集群中的每个数据节点都拥有独立的磁盘、内存和CPU等,节点之间通过高速网络进行互联互通
- 列存:每次查询只需要扫描需要的列,大大降低了磁盘的I/O
- 向量化执行:优化迭代执行模式为一次处理一批元组
关键技术:充分利用多节点并行导入,提升整体导入性能
4. 协调节点:CN节点只负责任务的规划和下发,把数据导入工作交给了DN节点,释放了CN节点的资源,使其具有能力去处理外部请求
5. 数据节点: DN通过让各个节点都参与数据导入,充分利用各个节点的计算能力以及网络带宽
Gauss的逻辑架构

几点说明:
1.集群中的每个组件都是有HA保证的,比如OM就有主备,NN节点也有主备从,其余类型节点也都是有的
2.虽然是分布式的数据库,但是还是保留了关系型数据库的一些ACID特性

通过这些特性,实现了表的行级锁,表级锁
3.假如你的CN节点有多个,这个时候我们要去连接那一个节点的IP呢?其实这里使用VPC网络来搞定,用一个外层的IP进行端口转发即可。在连接到这个VPC代理节点之后,发起一个查询请求,可能是使用 轮询的 原则,将请求发给某一个CN节点
这个CN节点就会解析我们的请求,分解任务,并调度任务到各个DN节点上并行执行,DN节点的查询结束之后返回结果给CN ,CN再返回给客户端。
补充一张分布式数据库 SQL处理流程 图:

distribute by hash(col)
分布列:分布式数据库特有的一个表定义的选项,对 指定列 进行hash ,然后根据hash结果将 表数据 打散存到各个DN节点

架构设计最佳实践:
计算靠近数据,计算在DN节点上完成:
把数据的计算 下推 到各个DN 节点上完成,这样就可以避免大量数据的迁移。
尽量避免将DN节点的数据 迁移到CN节点 或 相互迁移。
3 GaussDB 表、索引对象设计
建database ,user 之后,就要进行表设计开发:
- hash表
- 行存表
- 列存表
- 分区表(数据量大了之后,可能需要通过日期字段做过滤查询)
- 索引
分布式数据库表设计:

distributed by 可以将数据按照指定规则如: hash 进行打散到各个DN节点上

注意到上面这个列存的建表语句,发现partical cluster key (height) 做了一个身高 字段 粗粒度的聚合,
使用场景说明:
虽说在查询的时候,使用到这个height 关键字,能够提升查询效率。但是使用了partical cluster key 关键字之后在数据插入的时候,会涉及到一定的排序 ,数据入库的性能就会有损耗。
这个 查询效率的提升 和 入库性能的损耗 的取舍 就看你自己了
行存 和列存在GaussDB A里边都是支持的,适用于不同场景:
| 存储类型 | 适用场景 |
|---|---|
| 行存 | 点查询,返回记录少,基于索引的简单查询,增删改比较多 |
| 列存 | 统计分析类查询,group by /join 多的场景 ; 即席查询(查询条件列不确定,行存的话无法确定索引) |
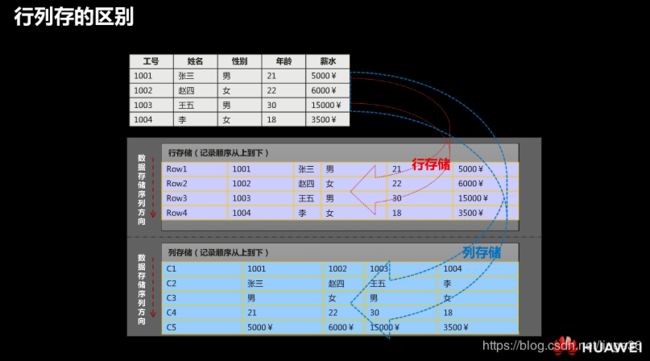
行存的话,每一行的记录实际存储是在一起的,一次一元组
列存:是将每列数据存储在一起,一次多元组
- 列存分区表(按照出身年月做分区)
-- 分区表
create table table_partition(
id int(18),
name varchar2(50),
age int(4),
birthday date
)
with (condition = column)
distribute by hash(id)
partition by range(birthday)(
partition p_start values less than('2020-01-01'),
partition p_202001 values less than('2020-02-01'),
partition p_202002 values less than('2020-03-01'),
partition p_202003 values less than('2020-04-01'),
partition p_202004 values less than('2020-05-01'),
partition p_end values less than(MAXVALUE)
);
- 复制表
replication

| 策略 | 描述 | 适用场景 |
|---|---|---|
| Hash | 将表中指定一个或几个字段进行Hash 运算后,根据生成的哈希值将 记录 map 到不同的DN数据节点上进行存储 | 数据量较大的事实表 |
| Replication | 将表的全量数据在每一个DN数据节点上保留一份 | 小表 、维表 |
开发中涉及到的维度表,通常就会常常被各个事实表进行关联
declare
i int;
begin
i := 1;
where i<=1000 loop
insert into person_row
select
lower(uuid()),
split_part('张三','李四','王五', ',' ,dbms_random.value(1, 3) :: int),
split_part('重庆','深圳','云南', ',' ,dbms_random.value(1, 3) :: int),
select string_agg((cast dbms_random.value(1,3)::int
when 1 THEN '157'
when 2 THEN '182'
else '133' END) || sustr(random(),3,4) || substr(random(),3,4,'#') from (
select generate_series(1,dbms_random.value(1,10)))),
'2020-01-01 00:00:00'::date + dbms_random.value(0,1440)/60/24::date + dbms_random.value(-1,365)::int,
dbms_random.value(150,200)::int
from dual;
i := i+1;
end LOOP;
END;
- *建索引(最基础的一个优化手段)

b-tree 索引,在点查询 的检索能力上很强

普通全文索引:分词算法功能
特殊的全文检索
- 查询

