yolov3+tensorflow+keras实现吸烟的训练全流程及识别检测
一.前言
近期,在研究人工智能机器视觉领域,拜读了深度学习相关资料,在练手期间比较了各前沿的网络架构,个人认为基于darknet53网络结构的yolov3以及retinanet的faster rcnn最合适深度学习工程落地的技术选型。以下是整理的对yolov3的认知解析,同时有个基于人员吸烟检测识别的小工程练手,以望沟通学习交流。后期会继续更新对faster rcnn的认知解析。
二.yolov3理解
you only look once.采用的是多尺度预测,类似FPN;更好的基础分类网络(类ResNet)和分类器。yolov3使用逻辑回归预测每个边界框(bounding box)的对象分数。如果先前的边界框比之前的任何其他边界框重叠ground truth对象,则该值应该为1。如果以前的边界框不是最好的,但是确实将ground truth对象重叠了一定的阈值以上,我们会忽略这个预测。yolov3只为给每个groun truth对象分配一个边界框,如果之前的边界框未分配给grounding box对象,则不会对坐标或类别预测造成损失。yolo3在训练过程中,使用二元交叉熵损失来进行类别预测。yolo3创新地使用了金字塔网络,是端到端,输入图像,一次性输出每个栅格预测的一种或多种物体。每个格子可以预测B个bounding box,但是最终只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个问题。当物体占画面比例较小,如图像中包含牲畜或鸟群时,每个格子包含多个物体,但只能检测出其中一个。
1. 分类器:
YOLOv3不使用Softmax对每一个框进行分类,而使用多个logistic分类器,因为Softmax不适用于多标签分类,用独立的多个logistic分类器准确率也不会下降。分类损失采用binary cross-entropy loss.
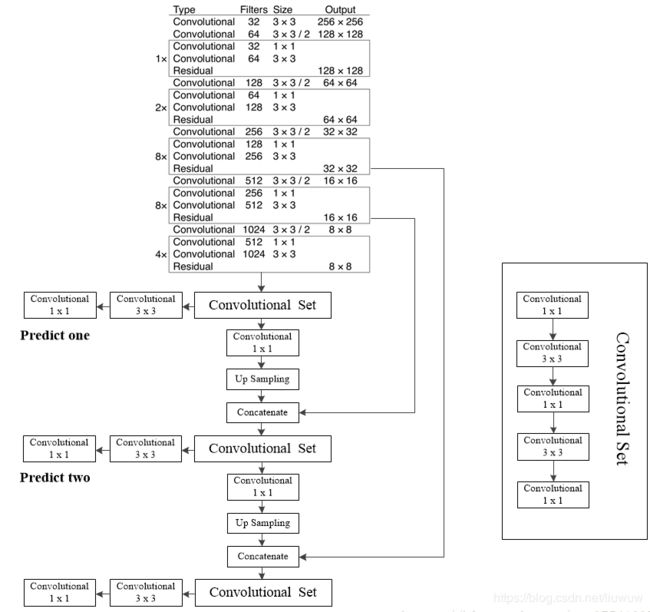
2. 多尺度预测
每种尺度预测3个box,anchor的设计方式仍然适用聚类,得到9个聚类中心,将其按照大小均分给3种尺度。尺度1:在基础网络之后添加一些卷积层再输出box信息;尺度2:在尺度1中的倒数第二层卷积层上采样(×2)再与最后一个16×16大小的特征图相加,再次通过多个卷积后输出box信息。相比尺度1变大两倍;尺度3:与尺度2类似,使用了32×32大小的特征图。
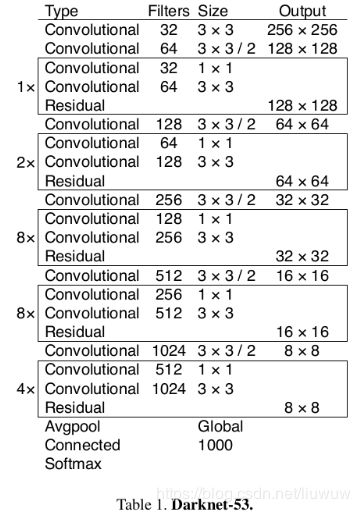
3.基础网络
基础网络采用Darknet-53(53个卷积层),仿RestNet,与ResNet-10或ResNet-152正确率接近,采用2562563作为输入。基础网络如下:
4.YOLO3算法的基本思想
- 首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图,比如13×13(相当于416416图片大小 ),然后将输入图像分成13 ×13个grid cells,接着如果GT中某个目标的中心坐标落在哪个grid cell中,那么就由该grid cell来预测该目标。每个grid cell都会预测3固定数量的边界框(YOLO v1中是2个,YOLO v2中是5个,YOLO v3中是3个,这几个边界框的初始大小是不同的)
- 预测得到的输出特征图有两个维度是提取到的特征的维度,比如13 × 13,还有一个维度(深度)是 B ×(5+C),注:YOLO v1中是(B×5+C),其中B表示每个grid cell预测的边界框的数量(比如YOLO v1中是2个,YOLO v2中是5个,YOLO v3中是3个); C表示边界框的类别数(没有背景类,所以对于VOC数据集是20),5表示4个坐标信息和一个目标性得分(objectness score)
5.类别预测
- 大多数分类器假设输出标签是互斥的。 如果输出是互斥的目标类别,则确实如此。 因此,YOLO应用softmax函数将得分转换为总和为1的概率。 而YOLOv3使用多标签分类。 例如,输出标签可以是“行人”和“儿童”,它们不是非排他性的。 (现在输出的总和可以大于1)
- YOLOv3用多个独立的逻辑(logistic)分类器替换softmax函数,以计算输入属于特定标签的可能性。在计算分类损失时,YOLOv3对每个标签使用二元交叉熵损失。 这也避免使用softmax函数而降低了计算复杂度。
三.yolov3对比情况
- 算法很快,因为我们把目标检测问题看做一个回归问题,在测试时,我们在整个图片上运行我们的神经网络来进行目标检测
- 在检测过程中,因为是在整个图片上运行网络,和滑动窗口方法和区域提议方法不同,这些方法都是以图片的局部作为输入,即已经划分好的可能存在目标的区域;而yolo则是近以整张图片作为输入,此yolo在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。
- yolo可以学到物体的泛化特征,当yolo在自然图像上做训练,在艺术品上做测试时,YOLO表现的性能比DPM、R-CNN等物体检测系统要好,因为yolo可以学习到高度泛化的特征,从而迁移到其他领域。
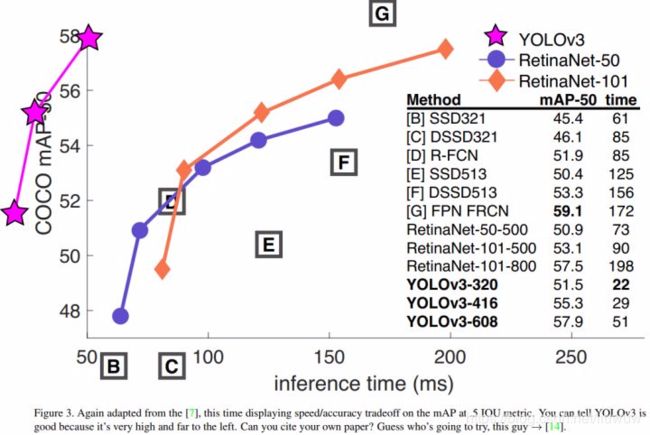
- 在输入 320 × 320 的图片后,YOLOv3 能在 22 毫秒内完成处理,并取得 28.2 mAP 的检测精准度,它的精准度和 SSD 相当,但是速度要快 3 倍。当我们用老的 .5 IOU mAP 检测指标时,YOLOv3 的精准度也是相当好的。在 Titan X 环境下,YOLOv3 在 51 毫秒内实现了 57.9 AP50 的精准度,和 RetinaNet 在 198 毫秒内的 57.5 AP50 相当,但是 YOLOv3 速度要快 3.8 倍。
- 区域建议方法将分类器限制在特定区域。YOLO在预测边界框时访问整个图像,YOLO在背景区域显示的假阳性更少。
- YOLO每个网格单元检测一个对象。它加强了预测的空间多样性。
- Darknet53新网络比Darknet-19功能强大,也比ResNet-101或ResNet-152更有效,以下是一些ImageNet结果

- 就COCO的mAP指标而言,yolo3与ssd及faster rcnn比较如下

- yolo3与Faster R-CNN、ResNet、SSD等训练算法比较,yolo3的速度与精确度远远大于他们,具体如下:
四.练手工程
1. 基本环境、工具准备:
- win10(x64)
- 显卡gtx1060
- python3.6
- cuda_9.0.176_win10
- cudnn-9.0-windows10-x64-v7
- tensorflow-gpu1.7.0
- pycharm
- labelImg
- voc2007数据集
2. 数据集说明:
- PASCAL VOC challenge: voc挑战在2005年至2012年间展开,该数据集中有20个分类,该数据集包含11530张用于训练和验证的图像,以下是数据集中20个分类:人、鸟、猫、牛、狗、马、羊、飞机、自行车、船、巴士、汽车、摩托车、火车、瓶、椅子、餐桌、盆栽植物、沙发、电视/监视器,平均每个图像有2.4个目标。下载链接:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
- ImageNet数据集:ImageNet拥有分类、定位和检测任务评估的数据。与分类数据相似,定位任务有1000个类别。正确率是根据Top5检测结果计算出来的,对200个检测问题有470000个图像,平均每个图像有1.1个目标。下载链接:http://image-net.org/download-images
- COCO:MS coco的全称是Microsoft Common Objects in Context,起源于微软与2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和权威的比赛之一。在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。COO数据集包含20万个图像,80个类别中有超过50万个目标标注,他是广泛公开的目标检测数据库,平均每个图像的目标数为7.2下载链接:http://cocodataset.org/ 类别包含:person,bicycle,car,motorbike,aeroplane,bus,train,truck,boat,traffic light,fire hydrant,stop sign,parking meter,bench,bird,cat,dog,horse,sheep,cow,elephant,bear,zebra,giraffe,backpack,umbrella,handbag,tie,suitcase,frisbee,skis,snowboard,sports ball,kite,baseball bat,baseball glove,skateboard,surfboard,tennis racket,bottle,wine glass,cup,fork,knife,spoon,bowl,banana,apple,sandwich,orange,broccoli,carrot,hot dog,pizza,donut,cake,chair,sofa,pottedplant,bed,diningtable,toilet,tvmonitor,laptop,mouse,remote,keyboard,cell phone,microwave,oven,toaster,sink,refrigerator,book,clock,vase,scissors,teddy bear,hair drier,toothbrush
- 本文练手工具是基于VOC2007格式,通过爬虫工具建立的自己的数据集
3. 训练前准备:
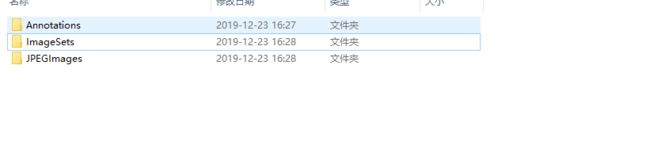
- 建立VOC2007数据集文件夹(ImageSets下还需建立Main文件集),如下:
import os
from config import cfg
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
if __name__=='__main__':
rootPath = cfg.ROOT.PATH
mkdir(os.path.join(rootPath, 'Annotations'))
mkdir(os.path.join(rootPath,'ImageSets'))
mkdir(os.path.join(rootPath,'JPEGImages'))
mkdir(os.path.join(rootPath,'ImageSets/Main'))
- 把所有的图片都复制到JPEGImages里面
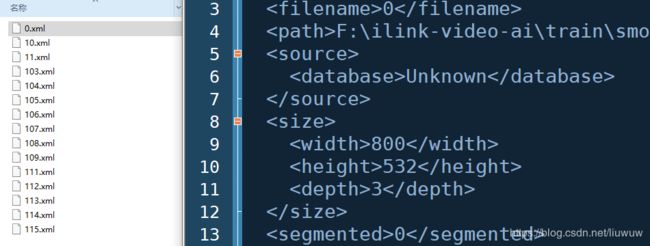
- 利用LabelImg生成每张图片的配置文件

- 划分训练集、验证集、测试集:过去,人们运用机器学习传统的方法,一般将训练集和测试集划分为7:3,若有验证集,则划分为6:2:2这样划分确实很科学(万级别以下),但到了大数据时代,数据量徒增为百万级别,此时我们不需要那么多的验证集和训练集。这时只需要拉出来1W条当验证集,1W条来当测试集,就能很好的工作了,,甚至可以达到99.5:0.3:0.2。(训练集是用来训练模型的,通过尝试不同的方法和思路使用训练集来训练不同的模型,再通过验证集使用交叉验证来挑选最优的模型,通过不断的迭代来改善模型在验证集上的性能,最后再通过测试集来评估模型的性能。如果数据集划分的好,可以提高模型的应用速度。如果划分的不好则会大大影响模型的应用的部署,甚至可能会使得我们之后所做的工作功亏一篑。),这里因为数据集不多,我们采用9:1开展训练工作
- 在Imagesets根据标注结果xml生成yolo3所需的train.txt,val.txt,test.txt,trainval.txt 保存至ImageSets/Main
import os
import random
from config import cfg
# # trainval集占整个数据集的百分比,剩下的就是test集所占的百分比
trainval_percent = cfg.ROOT.TRAIN_VAL_PERCENT
# train集占trainval集的百分比, 剩下的就是val集所占的百分比
train_percent = cfg.ROOT.TRAIN_PERCENT
rootPath = cfg.ROOT.PATH
xmlfilepath = os.path.join(rootPath, 'Annotations')
txtsavepath = 'ImageSets'
total_xml = os.listdir(os.path.join(rootPath, xmlfilepath))
# 总数据集个数
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
#用来训练和验证的图片文件的文件名列表
ftrainval = open(os.path.join(rootPath, 'ImageSets/Main/trainval.txt'), 'w')
#用来测试的图片文件的文件名列表
ftest = open(os.path.join(rootPath, 'ImageSets/Main/test.txt'), 'w')
#是用来训练的图片文件的文件名列表
ftrain = open(os.path.join(rootPath, 'ImageSets/Main/train.txt'), 'w')
#是用来验证的图片文件的文件名列表
fval = open(os.path.join(rootPath, 'ImageSets/Main/val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
# 写到训练和验证集
ftrainval.write(name)
if i in train:
# 在训练集里的写到测试集里
ftest.write(name)
else:
# 不在训练集里,写到验证集
fval.write(name)
else:
# 写到训练集
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
- 修改yolov3源码的voc_annotation.py文件,执行生产新的三个txt文件:test.txt,train.txt,val.txt
- 使用k-means聚类算法生成对应自己样本的anchor box尺寸
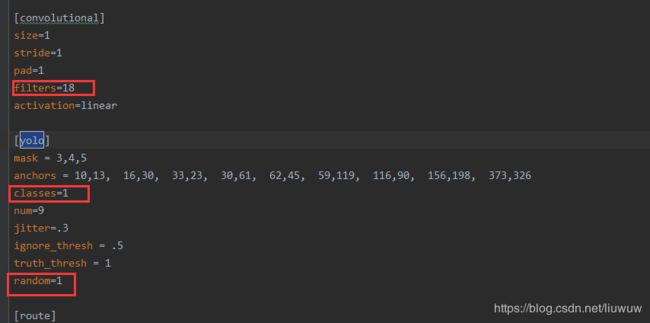
- 修改参数文件yolo3.cfg,找到[yolo]节点,修改以下三个地方,共计三个节点: fiters: 3*(5+len(classes))、classes:len(classes)=1(因为只需要识别烟)、random:默认1,显卡内存小改为0
- 新增model_data下的文件,放入你的类别,coco、voc这两个文件都需要放入,修改类别名称为smoking
4. 修改代码,开始训练。
以下代码是基于原有权重的.weights文件继续训练,需要执行python convert.py -w yolov3.cfg model/yolov3.weights model/yolo_weights.h5 转成keras可用.h5权重文件,然后在源码的train.py训练。若需全新训练的代码,可在我的github下载train.py。(batch_size设为8,epoch设为5000,连续运行18个小时左右,loss将为0.01以下即可。)
import numpy as np
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.optimizers import Adam
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
import os
import sys
sys.path.append('..')
from yolov3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolov3.utils import get_random_data
from config import cfg
def _main():
annotation_path = os.path.join(cfg.ROOT.PATH, 'train.txt')
log_dir = os.path.join(cfg.ROOT.PATH, 'logs/000/')
classes_path = os.path.join(cfg.ROOT.PATH, 'Model/voc_classes.txt')
anchors_path = os.path.join(cfg.ROOT.PATH, 'Model/yolo_anchors.txt')
class_names = get_classes(classes_path)
num_classes = len(class_names)
anchors = get_anchors(anchors_path)
input_shape = cfg.ROOT.INPUT_SHAPE # multiple of 32, hw
model = create_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path=os.path.join(cfg.ROOT.PATH, cfg.ROOT.PRE_TRAIN_MODEL)) # make sure you know what you freeze
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=True, period=3)
# reduce_lr:当评价指标不在提升时,减少学习率,每次减少10%,当验证损失值,持续3次未减少时,则终止训练。
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)
# early_stopping:当验证集损失值,连续增加小于0时,持续10个epoch,则终止训练。
# monitor:监控数据的类型,支持acc、val_acc、loss、val_loss等;
# min_delta:停止阈值,与mode参数配合,支持增加或下降;
# mode:min是最少,max是最多,auto是自动,与min_delta配合;
# patience:达到阈值之后,能够容忍的epoch数,避免停止在抖动中;
# verbose:日志的繁杂程度,值越大,输出的信息越多。
# min_delta和patience需要相互配合,避免模型停止在抖动的过程中。min_delta降低,patience减少;而min_delta增加,
# 则patience增加。
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
# 训练和验证的比例
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
'''
把目标当成一个输入,构成多输入模型,把loss写成一个层,作为最后的输出,搭建模型的时候,
就只需要将模型的output定义为loss,而compile的时候,
直接将loss设置为y_pred(因为模型的输出就是loss,所以y_pred就是loss),
无视y_true,训练的时候,y_true随便扔一个符合形状的数组进去就行了。
'''
# Train with frozen layers first, to get a stable loss.
# Adjust num epochs to your dataset. This step is enough to obtain a not bad model.
if True:
model.compile(optimizer=Adam(lr=1e-3), loss={
# use custom yolo_loss Lambda layer.
'yolo_loss': lambda y_true, y_pred: y_pred})
batch_size = 16
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[logging, checkpoint])
# 存储最终的参数,再训练过程中,通过回调存储
model.save_weights(log_dir + 'trained_weights_stage_1.h5')
# Unfreeze and continue training, to fine-tune.
# Train longer if the result is not good.
# 全部训练
if True:
for i in range(len(model.layers)):
model.layers[i].trainable = True
model.compile(optimizer=Adam(lr=1e-4), loss={'yolo_loss': lambda y_true, y_pred: y_pred}) # recompile to apply the change
print('Unfreeze all of the layers.')
batch_size = 32 # note that more GPU memory is required after unfreezing the body
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
'''
在训练中,模型调用fit_generator方法,按批次创建数据,输入模型,进行训练。其中,数据生成器wrapper是data_generator_
wrapper,用于验证数据格式,最终调用data_generator
annotation_lines:标注数据的行,每行数据包含图片路径,和框的位置信息;
batch_size:批次数,每批生成的数据个数;
input_shape:图像输入尺寸,如(416, 416);
anchors:anchor box列表,9个宽高值;
num_classes:类别的数量;
'''
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=100,
initial_epoch=50,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
model.save_weights(os.path.join(cfg.ROOT.PATH, cfg.ROOT.MODEL_RSLT_NAME))
# Further training if needed.
def get_classes(classes_path):
'''loads the classes'''
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
'''loads the anchors from a file'''
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def create_model(input_shape, anchors, num_classes, load_pretrained=True, freeze_body=2,
weights_path=os.path.join(cfg.ROOT.PATH, cfg.ROOT.PRE_TRAIN_MODEL)):
'''
create the training model
input_shape:输入图片的尺寸,默认是(416, 416);
anchors:默认的9种anchor box,结构是(9, 2);
num_classes:类别个数,在创建网络时,只需类别数即可。在网络中,类别值按0~n排列,同时,输入数据的类别也是用索引表示;
load_pretrained:是否使用预训练权重。预训练权重,既可以产生更好的效果,也可以加快模型的训练速度;
freeze_body:冻结模式,1或2。其中,1是冻结DarkNet53网络中的层,2是只保留最后3个1x1的卷积层,其余层全部冻结;
weights_path:预训练权重的读取路径;
'''
K.clear_session() # 清除session
h, w = input_shape # 尺寸
image_input = Input(shape=(w, h, 3)) # 图片输入格式
num_anchors = len(anchors) # anchor数量
# YOLO的三种尺度,每个尺度的anchor数,类别数+边框4个+置信度1
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
# 加载预训练模型
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body in [1, 2]:
# Freeze darknet53 body or freeze all but 3 output layers.
num = (185, len(model_body.layers)-3)[freeze_body-1]
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
# 构建 yolo_loss
# model_body: [(?, 13, 13, 18), (?, 26, 26, 18), (?, 52, 52, 18)]
# y_true: [(?, 13, 13, 18), (?, 26, 26, 18), (?, 52, 52, 18)]
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
'''
data generator for fit_generator
annotation_lines: 所有的图片名称
batch_size:每批图片的大小
input_shape: 图片的输入尺寸
anchors: 大小
num_classes: 类别数
'''
n = len(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
if i==0:
# 随机排列图片顺序
np.random.shuffle(annotation_lines)
# image_data: (16, 416, 416, 3)
# box_data: (16, 20, 5) # 每个图片最多含有20个框
# 获取图片和盒子
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
# 获取真实的数据根据输入的尺寸对原始数据进行缩放处理得到input_shape大小的数据图片,
# 随机进行图片的翻转,标记数据数据也根据比例改变
# 添加图片
image_data.append(image)
# 添加盒子
box_data.append(box)
i = (i+1) % n
image_data = np.array(image_data)
box_data = np.array(box_data)
# y_true是3个预测特征的列表
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
# y_true的第0和1位是中心点xy,范围是(0~13/26/52),第2和3位是宽高wh,范围是0~1,
# 第4位是置信度1或0,第5~n位是类别为1其余为0。
# [(16, 13, 13, 3, 6), (16, 26, 26, 3, 6), (16, 52, 52, 3, 6)]
yield [image_data, *y_true], np.zeros(batch_size)
def data_generator_wrapper(annotation_lines, batch_size, input_shape, anchors, num_classes):
"""
用于条件检查
"""
# 标注图片的行数
n = len(annotation_lines)
if n==0 or batch_size<=0: return None
return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if __name__ == '__main__':
_main()
5. 训练过程可视化分析:
训练过程可视化查看(命令行直接输入tensorboard --host=? --port=?–logdir=?,命令行会返回查看地址,在谷歌浏览器输入即可查看)

6. 模型效果测试:
import colorsys
import os
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolov3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolov3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
rootPath = "train/smoking"
class YOLO(object):
_defaults = {
"model_path": os.path.join(rootPath, 'Model/smoking.h5'),
"anchors_path": os.path.join(rootPath, 'Model/yolo_anchors.txt'),
"classes_path": os.path.join(rootPath, 'Model/coco_classes.txt'),
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 1,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer()
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
font = ImageFont.truetype(font='../resources/font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def close_session(self):
self.sess.close()
def detect_video(yolo, video_path, output_path=""):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError("Couldn't open webcam or video")
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC))
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != "" else False
if isOutput:
print("!!! TYPE:", type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = "FPS: ??"
prev_time = timer()
while True:
return_value, frame = vid.read()
image = Image.fromarray(frame)
image = yolo.detect_image(image)
result = np.asarray(image)
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
if accum_time > 1:
accum_time = accum_time - 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_NORMAL)
cv2.imshow("result", result)
if isOutput:
out.write(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session()
def detect_img(yolo):
#img = input('Input image filename:')
img = 'testImg/7_17.jpg'
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
else:
r_image = yolo.detect_image(image)
r_image.show()
yolo.close_session()
if __name__ == '__main__':
#detect_img(YOLO())
detect_video(YOLO(), 'smoking_detect.mp4')

五.如何提高检测识别效果及效率
- 在.cfg文件中设置flag random=1, 它将通过不同分辨率来训练yolo以提高精度
- 分类识别用不同的识别检测引擎(如:猫狗分两个模型)
- 提高.cfg文件中网络的分辨率(例如h,w=608,或者任意32的倍数),这样可以提高精度
- 确保数据集中每个类都带有标签,并且确保标签正确
- 优化标注内容(避免漏标、错标),去除数据集中重复的图片或者多余的标注文件
- 丰富数据集(达到10W+)
- 完善网络模型结构
- 优化特征提取、比对算法,优化边界识别算法
- 识别图片预处理:去噪、加强、抖动、杂线干
- 针对不同应用场景,训练不同场景应用的模型,以降低识别速度换取提高识别率
- 训练过程加大learning_rate、识别过程略调scores、iou
- 对于要检测的每一个对象,训练数据集中必须至少有一个类似的对象,其形状、对象侧面、相对大小、旋转角度、倾斜、照明等条件大致相同
- 数据集中应包括对象的不同缩放、旋转、照明、不同的面、不同的背景的图像,最好为每个类提供2000个不同的图像,并且训练(2000*类的数量)的迭代次数加多
- 对于目标物体较多的图像,在.cfg文件中最后一个[yolo]层和[region]层加入max=200参数或者更高的值。(yolov3可以检测到的对象的全局最大数目是0.0615234375 (widthheight),其中width和height是.cfg文件中[net]部分的参数)
- 训练小物体时(图像调整到416x416后物体小于16x16),将[route]参数替换为layers=-1,11,将[upsample]参数改为stride=4
- 对于都包含小对象和大对象可以使用以下的修改模型:Full-model: 5 yolo layers: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3_5l.cfg Tiny-model: 3 yolo layers: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-tiny_3l.cfg Spatial-full-model: 3 yolo layers: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-spp.cfg
- 如果要训练区分左右的对象(例如左手右手,道路上左转右转标志等),需要禁用数据翻转增强,在.cfg文件中17行左右的位置加入flip=0
- 一般规律——训练数据集应该包含一组您想要检测的对象的相对大小。简单来说,就是需要检测的对象在图像中的百分比是多少,那么训练的图像中也应该包含这个百分比的对象。例如:如果训练的时候目标在图像中都占80-90%,那检测的时候很可能就检测不出目标占0-10%情况。
- 同一个对象在不同的光照条件、侧面、尺寸、倾斜或旋转30度的情况下,对于神经网络的内部来说,都是不同的对象。因此,如果想检测更多的不同对象,就应该选择更复杂的神经网络。
- 在.cfg中重新计算锚(anchors)的width和height:在.cfg文件中的3个[yolo]层中的每个层中设置相同的9个锚,但是应该为每个[yolo]层更改锚点masks=的索引,以便[yolo]第一层的锚点大于60x60,第二层大于30x30,第三层剩余。此外,还应在每个[yolo]层之前更改过滤器filters=(classes + 5) * 。如果许多计算出的锚找不到适当的层,那么只需尝试使用所有的默认锚。这里提高了网络的分辨率,但是可以不需要重新训练(即使之前使用416*416分辨率训练的)。但是为了提高精度,还是建议使用更高的分辨率来重新训练。注意:如果出现了Out of memory的错误,建议提高.cfg文件中的subdivisions=16参数,改成32或者64等
- 在检测时,减小 yolo. py 文件参数中的 score 和 iou,如果这时候能出现框了,但是会发现效果不是很好,或者说置信度特别低,说明检测是成功的,但是训练做得比较差;如果还是不能出现框,考虑有可能检测方法错了(路径设置等),或者是训练过程错误(类名称和索引没配置好等)。
- 增加业务流程控制,对识别结果进行业务处理,对识别过程进行时序分析、控制。
六.loss收敛情况解析
训练过程loss异常说明(train loss:使用训练集的样本来计算的损失,val loss使用验证集的样本来计算的损失, 过拟合:为了得到一致假设而使假设变得更严格)
| train loss | val loss | 说明 |
|---|---|---|
| 下降 | 下降 | 网络在不断学习收敛 |
| 下降 | 不变 | 网络过拟合 |
| 不变 | 下降 | 数据集有问题 |
| 不变 | 不变 | 此次条件下学习达到瓶颈 |
| 上升 | 上升 | 网络结构或设计参数有问题,无法收敛 |
- 若一开始loss就无穷变大,可能是训练集和验证集的数据不匹配,或者归一化量纲不对或者参数设置错误。
- train loss 不断下降,test loss不断下降,说明网络仍在学习。
- train loss 不断下降,test loss趋于不变,说明网络过拟合。
- train loss 趋于不变,test loss不断下降,说明数据集100%有问题。
- train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目。
- train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
- loss值不下降问题:模型结构和特征工程存在问题;权重初始化方案有问题;正则化过度;选择合适的激活函数、损失函数;选择合适的优化器和学习速率;训练时间不足;模型训练遇到瓶颈;batch size太大或者太小,数据导入不对,比如维度错了;数据集未打乱;数据集有问题;未进行归一化;特征工程中对数据特征的选取有问题。
- LOSS持续不降,第一步先减小数据量,比方说只在单张图片上跑,使用小epochsize,观察每次LOSS下降情况,此时如果LOSS还是不下降说明网络没有学习能力,应该调整模型,一般是先把网络规模缩小,因为任何一个网络都会有学习能力,然而此时你的网络没有学习能力,则一定是你的模型有地方出错,而神经网络又是个黑盒,你只能摘除一部分网络,以排除“坏的”部分。此时网络的规模小了,又在一个相对较小的数据集上跑,必然会有个很好的学习能力。此时可以不断增加网络部件,来提高学习能力。
- 从训练开始就一直震荡或者发散:图片质量极差,人眼几乎无法识别其中想要识别的特征,对于网络来说相当于输入的一直都是噪音数据,比如通过resize的时候,图片的长宽比改变特别大,使图片丧失对应特征,或者tfrecord中图片大小是(m,n),但是读取的时候,按照(n,m)读取,所以loss一直震荡无法收敛;大部分标签都是对应错误的标签;leaning rate 设置过大。
- 训练开始会有所下降,然后出现发散:数据标签中有错误,甚至所有标签都有一定的错误,比如生成的标签文件格式和读取标签时设置的文件格式不一样,导致读取的标签是乱码;或者为标签中存在的空格未分配对应的编码,导致读取的空格为乱码(在OCR问题中);learning rate 设置过大。
- 训练开始会有所下降,然后出现震荡:loss函数中正则化系数设置有问题,或者loss函数本身有问题。比如,在序列化问题中的label_smoothing设置过大,比如设置为0.9,一般设置为0.1即可(OCR问题中);数据标签中有错误,甚至所有标签都有一定的错误。
- 在自己训练新网络时,可以从0.1开始尝试,如果loss不下降的意思,那就降低,除以10,用0.01尝试,一般来说0.01会收敛,不行的话就用0.001. 学习率设置过大,很容易震荡。不过刚刚开始不建议把学习率设置过小,尤其是在训练的开始阶段。在开始阶段我们不能把学习率设置的太低否则loss不会收敛。我的做法是逐渐尝试,从0.1,0.08,0.06,0.05 …逐渐减小直到正常为止。
- 检查lable是否有错,有的时候图像类别的label设置成1,2,3正确设置应该为0,1,2。
- 训练神经网络的时候,如果不收敛你可以改变一下图像的大小,很有可能事半功万倍。
七.下载
- yolov3开源代码:https://github.com/qqwweee/keras-yolo3
- 本文练手工程GitHub:https://github.com/swliu2016/ai-core/tree/train-core-yolov3
- CSDN下载地址:https://download.csdn.net/download/liuwuw/12066793