Oracle 一条数据拆分成多条(regexp_substr 函数)
首先来看一下我们需要的效果:
select '2020,2019,2018,2017' year from dual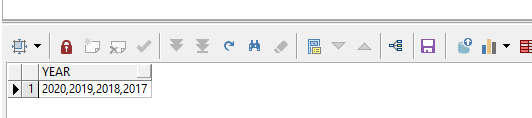
使用 regexp_substr 函数:
select regexp_substr('2020,2019,2018,2017', '[^,]+', 1, level) year from dual
connect by level <= (regexp_count('2020,2019,2018,2017', '\,')+1)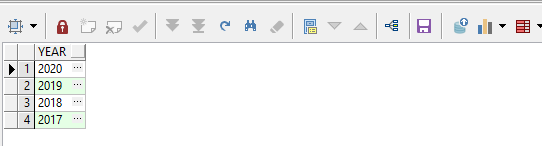
sql 解析:
函数1:regexp_substr('2020,2019,2018,2017', '[^,]+', 1, level, 'c')
'2020,2019,2018,2017':需要拆分的字符串。
'[^,]+':正则表达式匹配,以什么为条件分割。
1:匹配字符串的开始位置,开始下标为1,(默认为1)。
level:获取第几个分割出来的字符串(默认为1)。
'c':('i':不区分大小写)('c':区分大小写)默认为 'c')。
示例:
1、从第五个开始匹配:
select regexp_substr('2020,2019,2018,2017', '[^,]+', 5, level, 'i') year from dual
connect by level <= (regexp_count('2020,2019,2018,2017', '\,')+1) 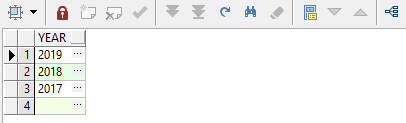
2、获取第二个分割出来的字符串:
select regexp_substr('2020,2019,2018,2017', '[^,]+', 1, 2) year from dual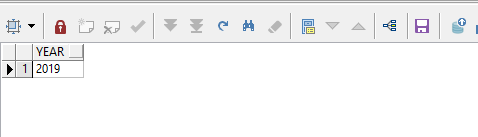
获取第三个分割出来的字符串:
select regexp_substr('2020,2019,2018,2017', '[^,]+', 1, 3) year from dual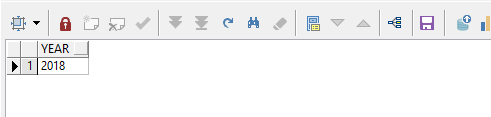
3、不区分大小写:
select regexp_substr('2020A2019a2018A2017', '[^a]+', 1, level, 'i') year from dual
connect by level <= (regexp_count('2020,2019,2018,2017', '\,')+1) 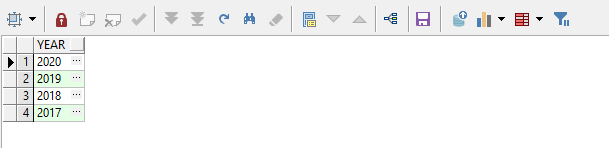
4、区分大小写:
select regexp_substr('2020A2019a2018A2017', '[^a]+', 1, level, 'c') year from dual
connect by level <= (regexp_count('2020,2019,2018,2017', '\,')+1) 或者 不写后面的 'c' (默认为 'c')
select regexp_substr('2020A2019a2018A2017', '[^a]+', 1, level) year from dual
connect by level <= (regexp_count('2020,2019,2018,2017', '\,')+1) 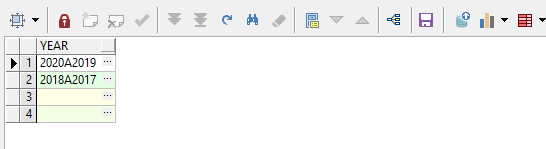

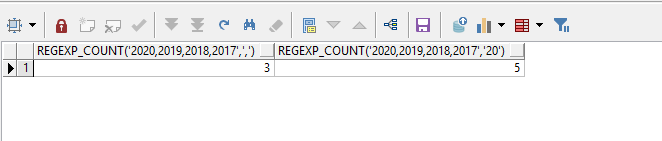
函数2:regexp_count('2020,2019,2018,2017', '\,')
这个函数是统计匹配字符出现的次数。
'2020,2019,2018,2017':需要匹配字符串
'\,':正则表达式匹配
示例:
select regexp_count('2020,2019,2018,2017', '\,') from dual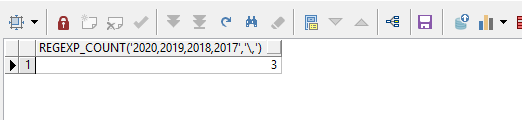
不用正则表达式:
select regexp_count('2020,2019,2018,2017', ','), regexp_count('2020,2019,2018,2017', '20') from dual