10. Kubernetes的日志与监控
Kubernetes的日志处理
- 日志对比:
传统服务的日志:
固定机器、固定目录
不受重启影响
不用关注stdout、stderr
k8s服务的日志:
节点不固定
重启服务会漂移
需要关注stdout、stderr
- 常见方案:
1. 远程日志 kafka、elasticsearch
2. SideCar 每个pod中运行一个sidecar,与主容器共享volume
3. LogAgent 每个node运行一个agent,daemonset方式运行
- 实践方案:
采用LogAgent方案,LogPilot + Elasticsearch + Kibana
关于LogPilot:
智能的容器日志采集工具
自动发现机制
开源 https://github.com/AliyunContainerService/log-pilot
- 主机说明:
| ip | 角色 | cpu | 内存 | hostname |
|---|---|---|---|---|
| 192.168.1.51 | master | >=2 | >=2G | master1 |
| 192.168.1.52 | master | >=2 | >=2G | master2 |
| 192.168.1.53 | master | >=2 | >=2G | master3 |
| 192.168.1.54 | node | >=2 | >=2G | node1 |
| 192.168.1.55 | node | >=2 | >=2G | node2 |
| 192.168.1.56 | node | >=2 | >=2G | node3 |
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready <none> 18h v1.14.0
node2 Ready <none> 18h v1.14.0
node3 Ready <none> 18h v1.14.0
这里master节点不作为集群工作节点,所以没有显示,属于正常情况。
- 部署es:
# cd /software
# mkdir elk && cd elk
# vim elasticsearch.yaml
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-api
namespace: kube-system
labels:
name: elasticsearch
spec:
selector:
app: es
ports:
- name: transport
port: 9200
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-discovery
namespace: kube-system
labels:
name: elasticsearch
spec:
selector:
app: es
ports:
- name: transport
port: 9300
protocol: TCP
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
spec:
replicas: 3
serviceName: "elasticsearch-service"
selector:
matchLabels:
app: es
template:
metadata:
labels:
app: es
spec:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
serviceAccountName: dashboard-admin
initContainers:
- name: init-sysctl
image: busybox:1.27
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
containers:
- name: elasticsearch
image: registry.cn-hangzhou.aliyuncs.com/imooc/elasticsearch:5.5.1
ports:
- containerPort: 9200
protocol: TCP
- containerPort: 9300
protocol: TCP
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
resources:
limits:
memory: 4000Mi
requests:
cpu: 100m
memory: 2000Mi
env: #es配置
- name: "http.host"
value: "0.0.0.0"
- name: "network.host"
value: "_eth0_"
- name: "cluster.name"
value: "docker-cluster"
- name: "bootstrap.memory_lock"
value: "false"
- name: "discovery.zen.ping.unicast.hosts"
value: "elasticsearch-discovery"
- name: "discovery.zen.ping.unicast.hosts.resolve_timeout"
value: "10s"
- name: "discovery.zen.ping_timeout"
value: "6s"
- name: "discovery.zen.minimum_master_nodes"
value: "2"
- name: "discovery.zen.fd.ping_interval"
value: "2s"
- name: "discovery.zen.no_master_block"
value: "write"
- name: "gateway.expected_nodes"
value: "2"
- name: "gateway.expected_master_nodes"
value: "1"
- name: "transport.tcp.connect_timeout"
value: "60s"
- name: "ES_JAVA_OPTS"
value: "-Xms2g -Xmx2g"
livenessProbe:
tcpSocket:
port: transport
initialDelaySeconds: 20
periodSeconds: 10
volumeMounts:
- name: es-data
mountPath: /data
terminationGracePeriodSeconds: 30
volumes:
- name: es-data
hostPath:
path: /es-data
# kubectl apply -f elasticsearch.yaml
service/elasticsearch-api created
service/elasticsearch-discovery created
statefulset.apps/elasticsearch created
# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
calico-typha ClusterIP 10.254.126.91 <none> 5473/TCP 18h
elasticsearch-api ClusterIP 10.254.249.131 <none> 9200/TCP 9s
elasticsearch-discovery ClusterIP 10.254.90.241 <none> 9300/TCP 9s
kube-dns ClusterIP 10.254.0.2 <none> 53/UDP,53/TCP 18h
kubernetes-dashboard NodePort 10.254.3.71 <none> 443:8401/TCP 18h
# kubectl get statefulsets.apps -n kube-system
NAME READY AGE
elasticsearch 3/3 29s
- 部署logpilot:
# vim log-pilot.yaml
---
apiVersion: extensions/v1beta1
kind: DaemonSet #daemonset类型
metadata:
name: log-pilot
namespace: kube-system
labels:
k8s-app: log-pilot
kubernetes.io/cluster-service: "true"
spec:
template:
metadata:
labels:
k8s-app: log-es
kubernetes.io/cluster-service: "true"
version: v1.22
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
serviceAccountName: dashboard-admin
containers:
- name: log-pilot
image: registry.cn-hangzhou.aliyuncs.com/imooc/log-pilot:0.9-filebeat #基于filebeat实现日志收集
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
env: #log-pilot配置
- name: "FILEBEAT_OUTPUT"
value: "elasticsearch"
- name: "ELASTICSEARCH_HOST"
value: "elasticsearch-api"
- name: "ELASTICSEARCH_PORT"
value: "9200"
- name: "ELASTICSEARCH_USER"
value: "elastic"
- name: "ELASTICSEARCH_PASSWORD"
value: "changeme"
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: / #配置对容器具有读写权限
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
# kubectl apply -f log-pilot.yaml
daemonset.extensions/log-pilot created
# kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
calico-node 3 3 3 3 3 <none> 18h
log-pilot 3 3 3 3 3 <none> 6s
- 部署kibana:
# vim kibana.yaml
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-system
labels:
component: kibana
spec:
selector:
component: kibana
ports:
- name: http
port: 80
targetPort: http
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: kube-system
spec:
rules:
- host: kibana.lzxlinux.cn
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 80
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: kibana
namespace: kube-system
labels:
component: kibana
spec:
replicas: 1
selector:
matchLabels:
component: kibana
template:
metadata:
labels:
component: kibana
spec:
containers:
- name: kibana
image: registry.cn-hangzhou.aliyuncs.com/imooc/kibana:5.5.1
env: #kibana配置
- name: CLUSTER_NAME
value: docker-cluster
- name: ELASTICSEARCH_URL
value: http://elasticsearch-api:9200/
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 5601
name: http
# kubectl apply -f kibana.yaml
service/kibana created
ingress.extensions/kibana created
deployment.apps/kibana created
# kubectl get deploy -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
calico-typha 1/1 1 1 18h
coredns 1/1 1 1 18h
kibana 1/1 1 1 6s
kubernetes-dashboard 1/1 1 1 18h
# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
calico-typha ClusterIP 10.254.126.91 <none> 5473/TCP 18h
elasticsearch-api ClusterIP 10.254.249.131 <none> 9200/TCP 100s
elasticsearch-discovery ClusterIP 10.254.90.241 <none> 9300/TCP 100s
kibana ClusterIP 10.254.169.82 <none> 80/TCP 24s
kube-dns ClusterIP 10.254.0.2 <none> 53/UDP,53/TCP 18h
kubernetes-dashboard NodePort 10.254.3.71 <none> 443:8401/TCP 18h
- 访问kibana:
在Windows电脑hosts文件中添加本地dns:
192.168.1.54 kibana.lzxlinux.cn
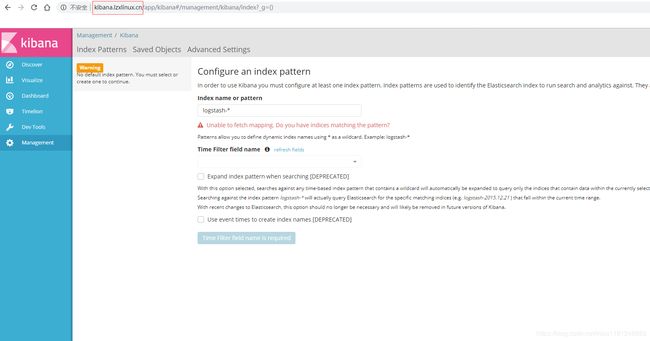
提示创建索引,kibana正常启动。此时可以查看log-pilot容器日志,看其是否启动正常。任选一个node节点查看,
# docker ps |grep log-pilot
787ee06e64da 80a82e076691 "/pilot/entrypoint" 5 minutes ago Up 5 minutes k8s_log-pilot_log-pilot-lx6fr_kube-system_8d1a3dab-1bc7-11ea-a74e-000c290f0358_0
036d26b99443 k8s.gcr.io/pause-amd64:3.1 "/pause" 5 minutes ago Up 5 minutes k8s_POD_log-pilot-lx6fr_kube-system_8d1a3dab-1bc7-11ea-a74e-000c290f0358_0
# docker logs 787ee06e64da
enable pilot: filebeat
time="2019-12-11T03:37:29Z" level=debug msg="787ee06e64da1d6632e4144da0dce5c38d352e5b249e2bf8a3e551246b5d5d8d has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="036d26b994435efa5c5a9e8091f0b3cce3309a3ef59fc7c2c97cb695fd12a4ac has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="61d447b30b1679935b88cf7860399aed2c3985c7c1ba571fde6ed19ab922209d has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="7618fdf1bda3ef5b8df9ba7bb4b6ab41d2c47b63120dd1172fb15d2de4d3e998 has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="851a74a68960cc6fa540da8124d7a64fc0f2a496cc2a8fefcb40470d14d6f657 has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="540351c879ff8a6aba5f9dc6c77fda3270f4a84798c367525c0016590ec44728 has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="0a93aaef53a96f418c12b80160e79eeece8f6a038e2936b706fb50b71d1bb500 has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="0a4546f201fe0627564d870a1ea11e2a88e72629ba93c41c4697df0691866db7 has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="85c0e9949d85648ace2cc8d0dd3fe6e30396120403fb607090d8fa91969b3950 has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="43a060f199d2408e54620fd2f66b6496e4d98921cd86fec8b895cde689f6abfd has not log config, skip"
time="2019-12-11T03:37:29Z" level=debug msg="5127010d7f9640473e4e20c8fa3058051d00049fd5f5e6fa29138615b1011769 has not log config, skip"
time="2019-12-11T03:37:29Z" level=info msg="start filebeat"
time="2019-12-11T03:37:29Z" level=info msg="filebeat watcher start"
time="2019-12-11T03:37:29Z" level=info msg="Reload gorouting is ready"
time="2019-12-11T03:37:54Z" level=debug msg="Process container start event: 80ed62ec95e8476ec12d16dde92f0f7817d8ebaec19989160742fd83be97e10f"
time="2019-12-11T03:37:54Z" level=debug msg="80ed62ec95e8476ec12d16dde92f0f7817d8ebaec19989160742fd83be97e10f has not log config, skip"
time="2019-12-11T03:37:55Z" level=debug msg="Process container start event: a49e0011afacb8ed5e042ee8e33db4eb8b78699e86d3bbe4f47a5eebf06aef4c"
time="2019-12-11T03:37:55Z" level=debug msg="a49e0011afacb8ed5e042ee8e33db4eb8b78699e86d3bbe4f47a5eebf06aef4c has not log config, skip"
可以看到log-pilot正常启动,由于当前没有采集日志的配置,所以全为skip。
- 配置日志采集:
部署一个项目,同时配置日志采集。
# vim web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
spec:
selector:
matchLabels:
app: web-demo
replicas: 3
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.lzxlinux.cn/kubernetes/web:latest
imagePullPolicy: Always
ports:
- containerPort: 8080
env:
- name: aliyun_logs_catalina
value: "stdout"
- name: aliyun_logs_access
value: "/usr/local/tomcat/logs/*"
volumeMounts:
- mountPath: /usr/local/tomcat/logs
name: accesslogs
volumes:
- name: accesslogs
emptyDir: {}
imagePullSecrets:
- name: hub-secret
---
apiVersion: v1
kind: Service
metadata:
name: web-demo
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web-demo
type: ClusterIP
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-demo
spec:
rules:
- host: web.lzxlinux.cn
http:
paths:
- path: /
backend:
serviceName: web-demo
servicePort: 80
# kubectl apply -f web.yaml
deployment.apps/web-demo created
service/web-demo created
ingress.extensions/web-demo created
# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-demo-5fd5f57698-7wtkq 1/1 Running 0 6s
web-demo-5fd5f57698-bn5jc 1/1 Running 0 6s
web-demo-5fd5f57698-qw6bq 1/1 Running 0 6s
- kibana创建索引:
使用access*作为索引,创建该索引。接着再使用catalina*创建一个索引(上面web.yaml中使用的索引),
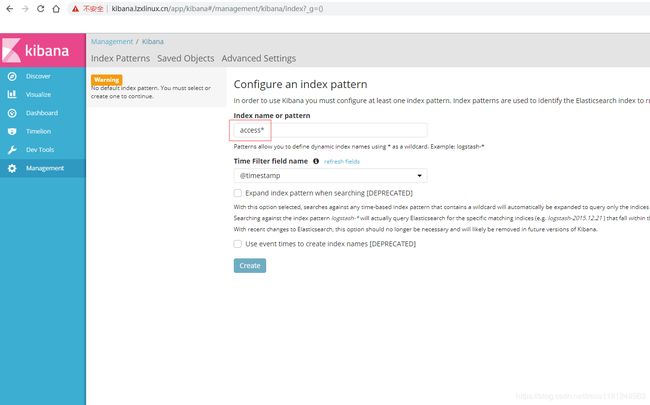
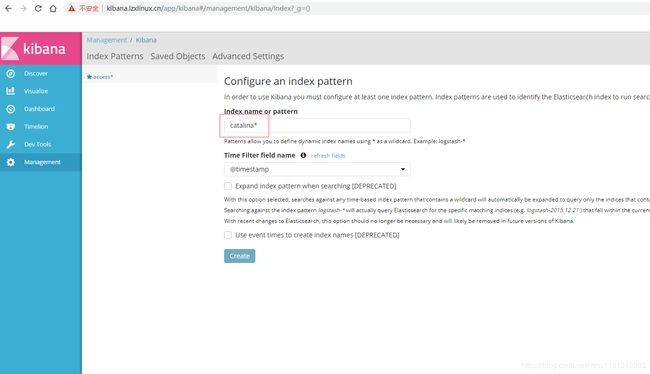
到Discover中查看,
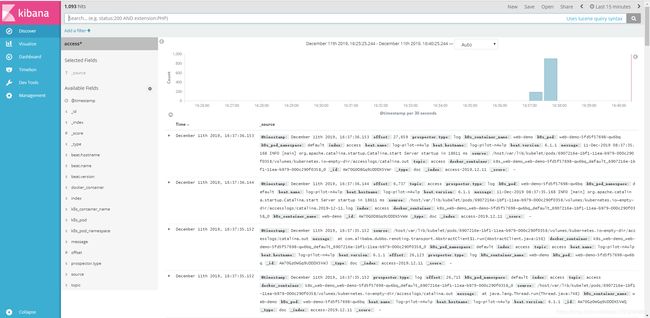
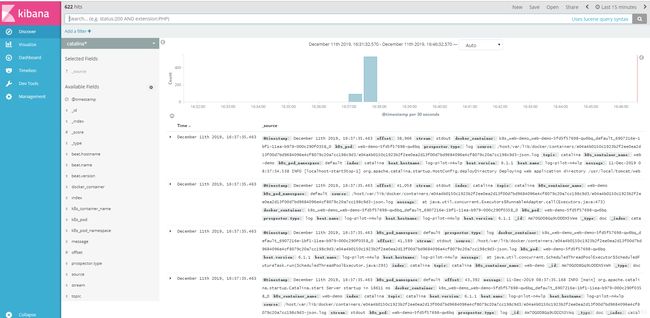
然后访问web.lzxlinux.cn/hello?name=lzx,多刷新几次页面,

接着到kibana页面搜索访问日志,
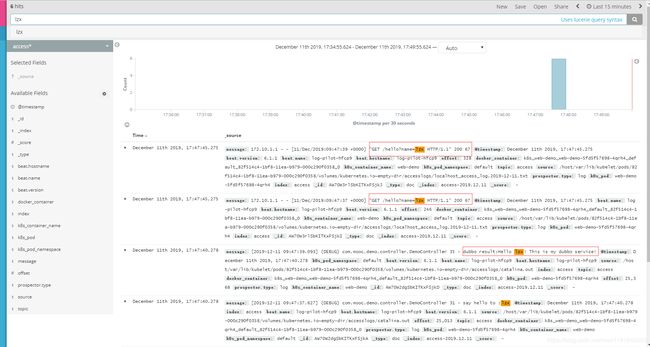
可以看到,访问日志已经在kibana页面展示出来。
通过这种方式,可以实现kubernetes的容器日志处理。
Kubernetes的监控告警
监控介绍
- 监控目的:
及时发现已经出现的问题
提前预警可能发生的问题
- 监控什么:
系统基础指标
服务基础信息
服务个性化信息
日志
- 如何监控:
数据采集
↓
数据存储(时间序列数据库)
↓
定义告警规则
↓
配置通知方式
- 常见监控方案:
Zabbix
OpenFalcon
Prometheus
- kubernetes的监控:
每个节点的基础指标
每个容器的基础指标
kubernetes的基础组件
kubernetes组件监控:
etcd https://${HOST}:2379/metrics
apiserver https://${HOST}:6443/metrics
controllermanager https://${HOST}:10252/metrics
scheduler https://${HOST}:10251/metrics
prometheus适用于kubernetes的监控。
- prometheus介绍:
prometheus是一系列服务的组合,同时也是系统和服务的监控告警平台。
特征:
由metric名称和kv标识的多维数据模型
灵活的查询语言(PromQL)
支持pull、push方式添加数据
支持基于kubernetes服务发现的动态配置
架构:
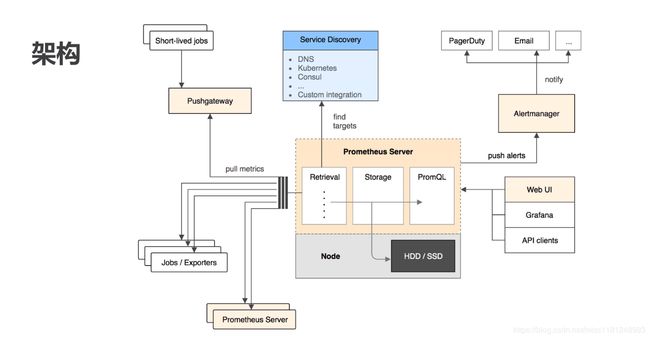
value的数据类型:
Counter 累计值,只增不减
Gauge 常规数值
Histogram && Summary 统计分析
部署Prometheus
- 部署方式:
手动
Helm
Prometheus Operator
Helm + Prometheus Operator
本文通过helm + prometheus operator部署prometheus,该方式非常优雅。
- helm部署:
类似CentOS中的yum、Ubuntu的apt-get,helm是kubernetes的包管理工具。对于helm,一个包就是一个chart(一个目录)。
官方下载地址:https://github.com/helm/helm/releases
百度云地址(推荐):https://pan.baidu.com/s/1CBeGImHY18R7PaIIHrFDLA
提取码:sjwi
首先需要保证部署helm的节点必须可以正常执行kubectl。helm客户端安装,
# cd /software
# curl -O https://storage.googleapis.com/kubernetes-helm/helm-v2.14.3-linux-amd64.tar.gz
# tar xf helm-v2.14.3-linux-amd64.tar.gz
# mv linux-amd64/helm /usr/local/bin/
# echo 'export PATH=$PATH:/usr/local/bin/' >> /etc/profile
# source /etc/profile
# helm version
Client: &version.Version{SemVer:"v2.14.3", GitCommit:"0e7f3b6637f7af8fcfddb3d2941fcc7cbebb0085", GitTreeState:"clean"}
Error: could not find tiller
tiller是以deployment方式部署在kubernetes集群中的。每个集群节点安装socat,
# yum install -y socat
否则后面会报错:unable to do port forwarding: socat not found.
tiller安装,
指向阿里云的仓库
# helm init --client-only --stable-repo-url https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts/
# helm repo add incubator https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/
# helm repo update
因为官方的镜像无法拉取,使用-i指定自己的镜像
# helm init --service-account tiller --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.3 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
创建TLS认证服务端
# helm init --service-account tiller --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.3 --tiller-tls-cert /etc/kubernetes/ssl/tiller001.pem --tiller-tls-key /etc/kubernetes/ssl/tiller001-key.pem --tls-ca-cert /etc/kubernetes/ssl/ca.pem --tiller-namespace kube-system --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
创建serviceaccount
# kubectl create serviceaccount --namespace kube-system tiller
创建角色绑定
# kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
查看Tiller的serviceaccount,需要跟我们创建的名字一致:tiller
# kubectl get deploy --namespace kube-system tiller-deploy -o yaml|grep serviceAccount
serviceAccount: tiller
serviceAccountName: tiller
验证pods
# kubectl -n kube-system get pods|grep tiller
tiller-deploy-749f694975-c9vlq 1/1 Running 0 64s
验证版本
# helm version
Client: &version.Version{SemVer:"v2.14.3", GitCommit:"0e7f3b6637f7af8fcfddb3d2941fcc7cbebb0085", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.14.3", GitCommit:"0e7f3b6637f7af8fcfddb3d2941fcc7cbebb0085", GitTreeState:"clean"}
可以看到,helm部署完成。
- 部署prometheus:
prometheus operator的实现原理:kubernetes的自定义资源类型(CRD)+ 自定义控制器。
# cd /software
# git clone https://gitee.com/zuiaihesuannaiyo/prometheus-operator.git
# ls prometheus-operator/
charts Chart.yaml ci CONTRIBUTING.md hack OWNERS README.md requirements.lock requirements.yaml templates values.yaml
修改values.yaml,
# vim /software/prometheus-operator/values.yaml #修改下面内容
alertmanager:
enabled: true
config:
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]' #发件人
smtp_auth_username: '[email protected]'
smtp_auth_password: 'aA111111'
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'email-alerts'
routes:
- match:
alertname: .*
receiver: 'email-alerts'
receivers:
- name: 'email-alerts'
email_configs:
- to: '[email protected]' #收件人,自己的邮箱
send_resolved: true #问题解决时也发送邮件
kubelet:
enabled: true
namespace: kube-system
serviceMonitor:
https: false
kubeControllerManager:
enabled: true
endpoints:
- 192.168.1.51
- 192.168.1.52
- 192.168.1.53
kubeEtcd:
enabled: true
endpoints:
- 192.168.1.51
- 192.168.1.52
- 192.168.1.53
serviceMonitor:
caFile: "/etc/prometheus/secrets/etcd-certs/ca.pem"
certFile: "/etc/prometheus/secrets/etcd-certs/etcd.pem"
keyFile: "/etc/prometheus/secrets/etcd-certs/etcd-key.pem"
kubeScheduler:
enabled: true
endpoints:
- 192.168.1.53
- 192.168.1.52
- 192.168.1.53
serviceMonitor:
https: false
prometheus:
enabled: true
secrets:
- etcd-certs
所有master节点修改相关服务文件,以master1节点为例,
# vim /etc/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/opt/kubernetes/bin/kube-scheduler \
--address=192.168.1.51 \ #修改为对应ip
--kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig \
--leader-elect=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload && systemctl restart kube-scheduler
# netstat -lntp |grep 10251
tcp 0 0 192.168.1.51:10251 0.0.0.0:* LISTEN 7604/kube-scheduler
# vim /etc/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/opt/kubernetes/bin/kube-controller-manager \
--port=0 \
--secure-port=10252 \
--bind-address=192.168.1.51 \ #修改为对应ip
--kubeconfig=/etc/kubernetes/controller-manager.kubeconfig \
--service-cluster-ip-range=10.254.0.0/16 \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--allocate-node-cidrs=true \
--cluster-cidr=172.10.0.0/16 \
--experimental-cluster-signing-duration=8760h \
--root-ca-file=/etc/kubernetes/pki/ca.pem \
--service-account-private-key-file=/etc/kubernetes/pki/ca-key.pem \
--leader-elect=true \
--feature-gates=RotateKubeletServerCertificate=true \
--controllers=*,bootstrapsigner,tokencleaner \
--horizontal-pod-autoscaler-use-rest-clients=true \
--horizontal-pod-autoscaler-sync-period=10s \
--tls-cert-file=/etc/kubernetes/pki/controller-manager.pem \
--tls-private-key-file=/etc/kubernetes/pki/controller-manager-key.pem \
--use-service-account-credentials=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload && systemctl restart kube-controller-manager
# netstat -lntp |grep 10252
tcp 0 0 192.168.1.51:10252 0.0.0.0:* LISTEN 8803/kube-controlle
在helm install之前在所有node节点手动拉取镜像,
# docker pull quay.io/prometheus/node-exporter:v0.17.0
# docker pull quay.io/coreos/prometheus-operator:v0.29.0
# docker pull quay.io/prometheus/alertmanager:v0.16.2
# docker pull quay.io/coreos/prometheus-config-reloader:v0.29.0
# docker pull quay.io/prometheus/prometheus:v2.9.1
执行helm install,
# helm install prometheus-operator/ --name prom --namespace monitoring
helm install后遇到两个报错:
# kubectl describe pod -n monitoring alertmanager-prom-prometheus-operator-alertmanager-0
Back-off restarting failed container
# kubectl logs alertmanager-prom-prometheus-operator-alertmanager-0 alertmanager -n monitoring
Failed to resolve alertmanager-prom-prometheus-operator-alertmanager-0.alertmanager-operated.monitoring.svc:6783: lookup alertmanager-prom-prometheus-operator-alertmanager-0.alertmanager-operated.monitoring.svc on 10.254.0.2:53: no such host
# kubectl describe pod -n monitoring prometheus-prom-prometheus-operator-prometheus-0
MountVolume.SetUp failed for volume "secret-etcd-certs" : secret "etcd-certs" not found
解决报错:
# kubectl create secret generic etcd-certs -n monitoring --from-file=/etc/kubernetes/pki/ca.pem --from-file=/etc/kubernetes/pki/etcd-key.pem --from-file=/etc/kubernetes/pki/etcd.pem
# vim /software/prometheus-operator/values.yaml #更改alertmanager镜像版本
alertmanager:
enabled: true
alertmanagerSpec:
podMetadata: {}
image:
repository: quay.io/prometheus/alertmanager
tag: v0.14.0
然后删除monitoring相关的资源对象,
# helm delete prom --purge
# kubectl get crd |grep coreos
# kubectl delete crd alertmanagers.monitoring.coreos.com
# kubectl delete crd prometheuses.monitoring.coreos.com
# kubectl delete crd prometheusrules.monitoring.coreos.com
# kubectl delete crd servicemonitors.monitoring.coreos.com
再次执行helm install,
# helm install prometheus-operator/ --name prom --namespace monitoring
# kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-prom-prometheus-operator-alertmanager-0 2/2 Running 0 18s
pod/prom-grafana-d4f9475c5-nz5rq 2/2 Running 0 24s
pod/prom-kube-state-metrics-fffc48566-5qn7h 1/1 Running 0 24s
pod/prom-prometheus-node-exporter-9j49w 1/1 Running 0 24s
pod/prom-prometheus-node-exporter-w2r6z 1/1 Running 0 24s
pod/prom-prometheus-node-exporter-zs2n5 1/1 Running 0 24s
pod/prom-prometheus-operator-operator-59dc6859c9-8bt7n 1/1 Running 0 24s
pod/prometheus-prom-prometheus-operator-prometheus-0 3/3 Running 1 11s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 18s
service/prom-grafana ClusterIP 10.254.66.23 <none> 80/TCP 25s
service/prom-kube-state-metrics ClusterIP 10.254.136.131 <none> 8080/TCP 25s
service/prom-prometheus-node-exporter ClusterIP 10.254.177.222 <none> 9100/TCP 25s
service/prom-prometheus-operator-alertmanager ClusterIP 10.254.160.213 <none> 9093/TCP 25s
service/prom-prometheus-operator-operator ClusterIP 10.254.172.150 <none> 8080/TCP 25s
service/prom-prometheus-operator-prometheus ClusterIP 10.254.4.212 <none> 9090/TCP 25s
service/prometheus-operated ClusterIP None <none> 9090/TCP 11s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prom-prometheus-node-exporter 3 3 3 3 3 <none> 25s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prom-grafana 1/1 1 1 25s
deployment.apps/prom-kube-state-metrics 1/1 1 1 25s
deployment.apps/prom-prometheus-operator-operator 1/1 1 1 25s
NAME DESIRED CURRENT READY AGE
replicaset.apps/prom-grafana-d4f9475c5 1 1 1 25s
replicaset.apps/prom-kube-state-metrics-fffc48566 1 1 1 24s
replicaset.apps/prom-prometheus-operator-operator-59dc6859c9 1 1 1 24s
NAME READY AGE
statefulset.apps/alertmanager-prom-prometheus-operator-alertmanager 1/1 18s
statefulset.apps/prometheus-prom-prometheus-operator-prometheus 1/1 11s
上面就是helm部署的结果,接下来为prometheus配置ingresss。
- 配置ingress:
# kubectl get svc -n monitoring prom-prometheus-operator-prometheus -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2019-12-26T03:38:14Z"
labels:
app: prometheus-operator-prometheus
chart: prometheus-operator-5.5.0
heritage: Tiller
release: prom
name: prom-prometheus-operator-prometheus
namespace: monitoring
resourceVersion: "1041537"
selfLink: /api/v1/namespaces/monitoring/services/prom-prometheus-operator-prometheus
uid: 25df39e2-2791-11ea-ac82-000c291749f6
spec:
clusterIP: 10.254.4.212
ports:
- name: web
port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus
prometheus: prom-prometheus-operator-prometheus
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
# vim ingress-prometheus.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus
namespace: monitoring
spec:
rules:
- host: prometheus.lzxlinux.cn
http:
paths:
- backend:
serviceName: prom-prometheus-operator-prometheus
servicePort: web
path: /
# kubectl apply -f ingress-prometheus.yaml
在Windows电脑hosts文件中添加本地dns:
192.168.1.54 prometheus.lzxlinux.cn
- 查看监控目标:
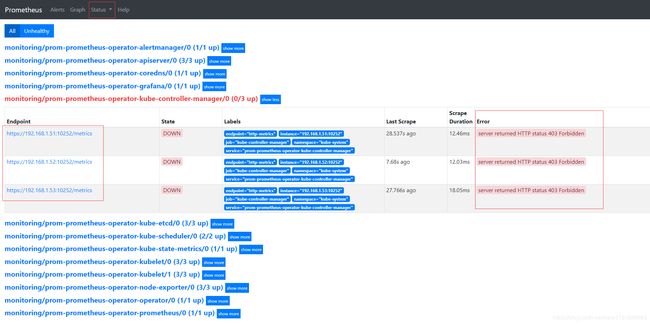
当前kube-controller-manager监控存在问题,提示server returned HTTP status 403 Forbidden。
- 查看告警邮件:
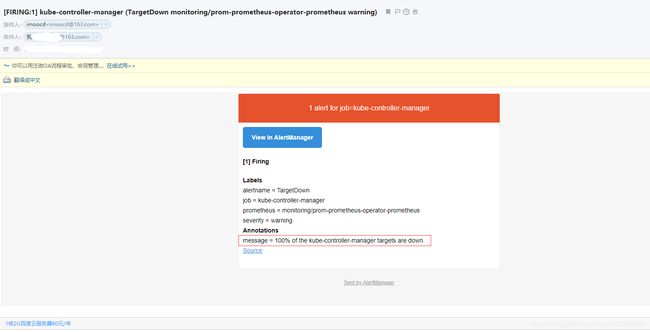
与prometheus页面提示一致,kube-controller-manager 100% down
- 解决该问题:
# vim /software/prometheus-operator/values.yaml
kubeControllerManager:
enabled: true
endpoints:
- 192.168.1.51
- 192.168.1.52
- 192.168.1.53
serviceMonitor:
interval: ""
https: false
所有master节点修改相关服务文件,以master1节点为例,
# vim /etc/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/opt/kubernetes/bin/kube-controller-manager \
--port=10252 \
--secure-port=0 \ #关闭https
--bind-address=192.168.1.51 \
--kubeconfig=/etc/kubernetes/controller-manager.kubeconfig \
--service-cluster-ip-range=10.254.0.0/16 \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--allocate-node-cidrs=true \
--cluster-cidr=172.10.0.0/16 \
--experimental-cluster-signing-duration=8760h \
--root-ca-file=/etc/kubernetes/pki/ca.pem \
--service-account-private-key-file=/etc/kubernetes/pki/ca-key.pem \
--leader-elect=true \
--feature-gates=RotateKubeletServerCertificate=true \
--controllers=*,bootstrapsigner,tokencleaner \
--horizontal-pod-autoscaler-use-rest-clients=true \
--horizontal-pod-autoscaler-sync-period=10s \
--tls-cert-file=/etc/kubernetes/pki/controller-manager.pem \
--tls-private-key-file=/etc/kubernetes/pki/controller-manager-key.pem \
--use-service-account-credentials=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload && systemctl restart kube-controller-manager
到prometheus页面查看,
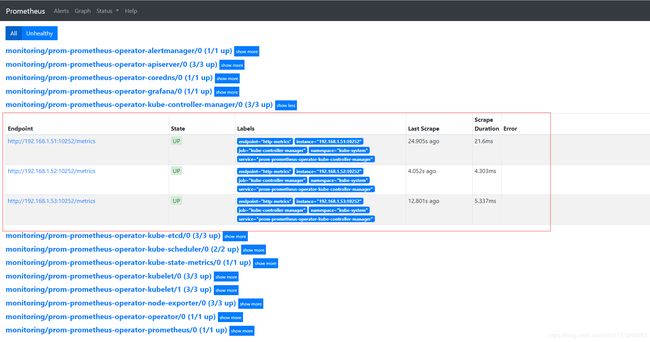
可以看到kube-controller-manager监控恢复正常。
配置Grafana
- 配置ingress:
# kubectl get svc -n monitoring prom-grafana -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2019-12-26T06:06:23Z"
labels:
app: grafana
chart: grafana-3.3.6
heritage: Tiller
release: prom
name: prom-grafana
namespace: monitoring
resourceVersion: "1058812"
selfLink: /api/v1/namespaces/monitoring/services/prom-grafana
uid: d8383b4d-27a5-11ea-ac82-000c291749f6
spec:
clusterIP: 10.254.194.116
ports:
- name: service
port: 80
protocol: TCP
targetPort: 3000
selector:
app: grafana
release: prom
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
# vim ingress-grafana.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prom-grafana
namespace: monitoring
spec:
rules:
- host: grafana.lzxlinux.cn
http:
paths:
- backend:
serviceName: prom-grafana
servicePort: 80
path: /
# kubectl apply -f ingress-grafana.yaml
在Windows电脑hosts文件中添加本地dns:
192.168.1.54 grafana.lzxlinux.cn

- 登录grafana:
# vim /software/prometheus-operator/charts/grafana/values.yaml
adminUser: admin
admin:
existingSecret: ""
userKey: admin-user
passwordKey: admin-password
# kubectl get secrets -n monitoring prom-grafana -o yaml
apiVersion: v1
data:
admin-password: cHJvbS1vcGVyYXRvcg==
admin-user: YWRtaW4=
ldap-toml: ""
kind: Secret
metadata:
creationTimestamp: "2019-12-26T06:06:23Z"
labels:
app: grafana
chart: grafana-3.3.6
heritage: Tiller
release: prom
name: prom-grafana
namespace: monitoring
resourceVersion: "1058761"
selfLink: /api/v1/namespaces/monitoring/secrets/prom-grafana
uid: d7b207d8-27a5-11ea-ac82-000c291749f6
type: Opaque
通过BASE64解码,账号为admin,密码为prom-operator,登录grafana。
- 查看grafana:
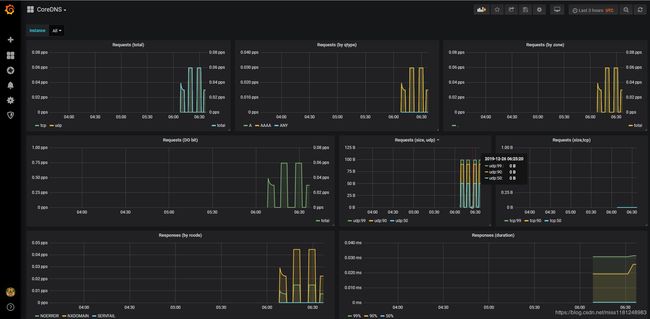
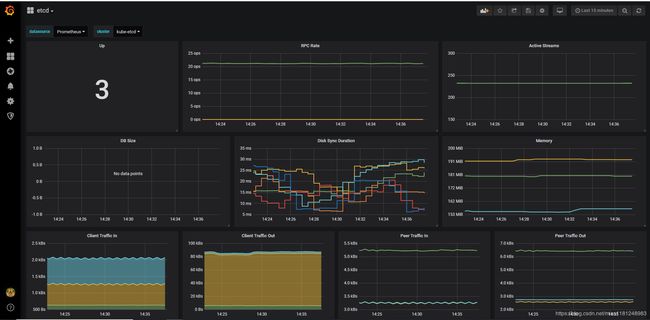
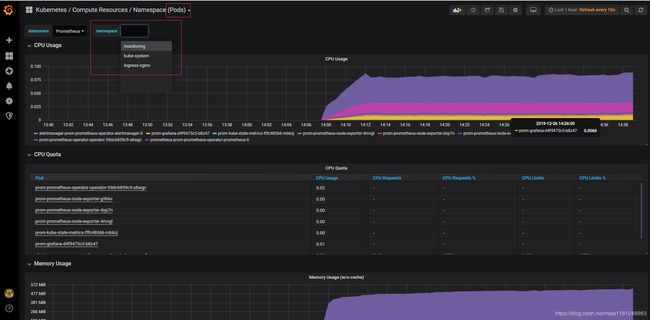
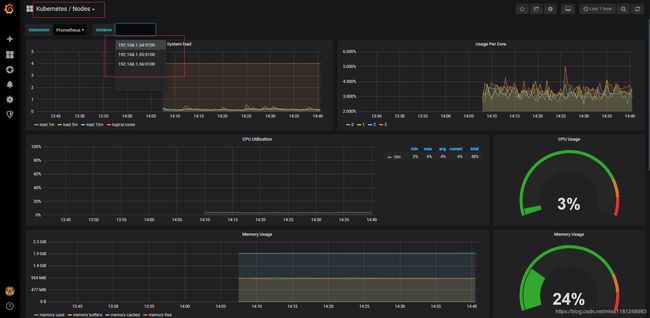
grafana的图表比较丰富,包含了kubernetes集群的集群信息,本质上是通过PromQL查询得到的数据。
至此,kubernetes集群的监控 prometheus + grafana 部署完成。