dncnn(残差网络图像去燥记录)
一,生成训练数据
1,原文相关知识
we use the noisy images from a wide range of noise levels (e.g., σ ∈ [0,55]) to train a single DnCNN model。
blind Gaussian denoising, SISR, and JPEG deblocking
.the noisy image is generated by adding Gaussian noise with a certain noise level from the range of [0,55]. The SISR input is generated by first bicubic downsampling and then bicubic upsampling the highresolution image with downscaling factors 2, 3 and 4. The JPEG deblocking input is generated by compressing the image with a quality factor ranging from 5 to 99 using the MATLAB JPEG encoder. All these images are treated as the inputs to a single DnCNN model. Totally, we generate 128×8,000 image patch (the size is 50 × 50) pairs for training. Rotation/flip based operations on the patch pairs are used during mini-batch learning.
图片大小及数量:we follow [16] to use 400 images of size 180 × 180 for training。
The noise levels are also set into the range of [0,55] and 128×3,000 patches of size 50×50 are cropped to train the model.
——————————————————————————————————————————————————————
For increasing the training set, we segment these images to overlapping patches of size 50×50 with stride of 10.
二,模型构建
1,模型知识
网络层数:
we set the size of convolutional filters to be 3 × 3 but remove all pooling layers
the receptive field of DnCNN with depth of d should be (2d+1)×(2d+1).
high noise level usually requires larger effective patch size to capture more context information for restoration
Thus, for Gaussian denoising with a certain noise level, we set the receptive field size of DnCNN to 35 × 35 with the corresponding depth of 17. For other general image denoising tasks, we adopt a larger receptive field and set the depth to be 20.
输出代价函数:
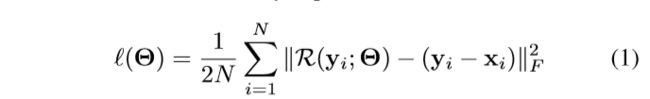
具体结构:
Deep Architecture:
Given the DnCNN with depth D, there are three types of layers, shown in Fig. 1 with three different colors. (i) Conv+ReLU: for the first layer, 64 filters of size 3×3×c are used to generate 64 feature maps, and rectified linear units (ReLU, max(0,·)) are then utilized for nonlinearity. Here c represents the number of image channels, i.e., c = 1 for gray image and c = 3 for color image. (ii) Conv+BN+ReLU: for layers 2 ∼ (D −1), 64 filters of size 3 × 3 × 64 are used, and batch normalization [21] is added between convolution and ReLU. (iii) Conv: for the last layer, c filters of size 3×3×64 are used to reconstruct the output.
padding:
Different from the above methods, we directly pad zeros
———————————————————————————————————————————————————————
感觉batch normalization没啥用,看最新的去燥论文并没有采用batch normalization。因此对模型换坑,采用最新的2018年的图像处理模型。接下来参考2018论文Adaptive Residual Networks for High-Quality Image Restoration
三,训练记录
采用学习率0.01直接导致网络训练死,后采用leak-relu网络不会学死。
采用0.0001学习率,1000轮最后loss达到0.0008。效果不理想。认为是使用学习率下降模块,学习率下降过快导致,因此采用固定学习率。