SiamRPN++理解
SiamRPN++论文和代码阅读
- 论文
- Analysis on Siamese Networks for Tracking
- ResNet-driven Siamese Tracking
- Layer-wise Aggregation
- Depthwise Cross Correlation
- 代码解读
- 代码运行
- 源代码中部分代码解析 (以LT为例)
- 整体代码简述
- 代码主体
- 第一帧图片的处理即template
- track层对应的代码解析
论文
Deeper and Wider Siamese Networks for Real-Time Visual Tracking,这篇文章也是为了解决 Siamese Tracker 无法利用 Deep Backbone Network 的问题。
论文的中文翻译参考
Analysis on Siamese Networks for Tracking
作者的实验发现,较深的网络,如 ResNet, 无法带来跟踪精度提升的原因在于:
- 更深的网络的填充会破坏严格的平移不变性(Strict translation invariance)

- RPN要求分类和回归具有不对称特征
文中作者引入空间感知策略来克服第一个困难,并对第二个问题进行讨论。
针对第一个问题作者认为Strict translation invariance只存在没有padding的网络中例如Alexnet,并且假设违反了这种限制将导致空间的倾斜(spatial bias)。
作者发现如下的几个参数,对跟踪结果的影响,非常巨大:the receptive field size of neurons; network stride; feature padding。
具体来说,感受野决定了用于计算 feature 的图像区域。较大的感受野,提供了更好的 image context 信息,而一个较小的感受野可能无法捕获目标的结构信息;
网络的步长,影响了定位准确性的程度,特别是对小目标而言;与此同时,它也控制了输出 feature map 的大小,从而影响了 feature 的判别性和检测精度。
此外,对于一个全卷积的结构来说,feature padding 对卷积来说,会在模型训练中,引入潜在的位置偏移,从而使得当一个目标移动到接近搜索范围边界的时候,很难做出准确的预测。这三个因素,同时造成了 Siamese Tracker 无法很好的从更顶尖的模型中收益。
ResNet-driven Siamese Tracking
为了降低上述影响因子对中心偏移的影响,作者对原始的 ResNet-50 进行了修改。原始的残差网络 有32个pixel的大步幅,这个参数不利于密集的孪生网络预测。所以作者对最后两个 block,conv4 和 conv5 的有效 步幅,从 16 和 32改为 8,并且通过扩张的卷积 来增加感受野,同时让conv4 和 conv5 有了空间单位步长。此外还利用 1*1 的卷积,将每个块的维度降为 256。
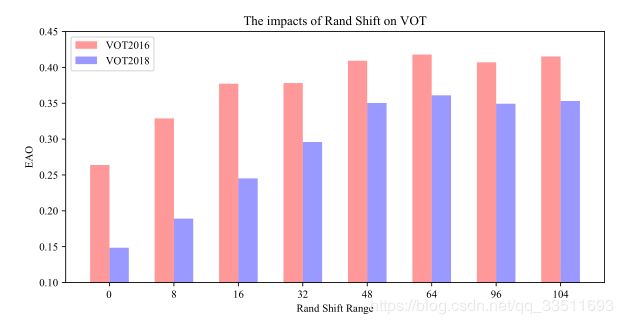
但是这篇文章,并没有将 padding 的参数进行更改,而是通过均匀分布的采样方式让目标在中心点附近进行偏移,可以缓解网络因为破坏了严格平移不变性带来的影响,即消除了位置偏见,让有padding的更深层网络可以应用于跟踪算法中。为了验证上述的猜测,文中设计了一个模拟实验。当我们像SiamFC一样训练,把正样本都放在图像中心时,网络只会对图像中心产生响应;如果我们把正样本均匀分布到某个范围内,而不是一直在中心时(所谓的范围即是指距离中心点一定距离,该距离为shift;正样本在这个范围内是均匀分布的),随着shift的不断增大,这种现象能够逐渐得到缓解。具体如下图所示:EAO是VOT比赛的一个评估指标,是将算法的鲁棒性和准确性结合起来的一个综合指标,该值越高表示算法越好。在下图中我们可以看到当shift从0变化到64的时候,跟踪算法在VOT16和VOT18数据集上面的效果都有了显著的性能提升,当shift超过64之后,提升的性能并不大,这可以从一方面说明该操作可以在一定程度上缓解上述这个问题。
作者认为 template feature map 的空间分辨率增加到 15,会导致correlation module操作的时候,计算量较大,影响跟踪速度。所以,作者从中 crop 一块 7*7 regions 作为 template feature,每一个 feature cell 仍然可以捕获整个目标区域。接下来使用交换层和全连接层构成head module 来计算分类和目标框的回归。作者发现仔细的调整 ResNet,是可以进一步提升效果的。通过将 ResNet extractor 的学习率设置为 RPN 网络的 1/10,得到的 feature 可以更加适合 tracking 任务。
Layer-wise Aggregation
作者认为后一层(latter layer)的特征具有丰富的语义信息 ,在一些挑战场景中可能有益的像运动模糊,巨大的变形。 使用这种假设分层信息有助于提高跟踪.
作者利用多层特征的聚合来提升特征表达,提升跟踪结果。作者从最后三个残差模块,得到对应的输出:F3(z), F4(z) 以及 F5(z)。这三个输出的feature map分别放入三个siamese RPN中。如图3所示
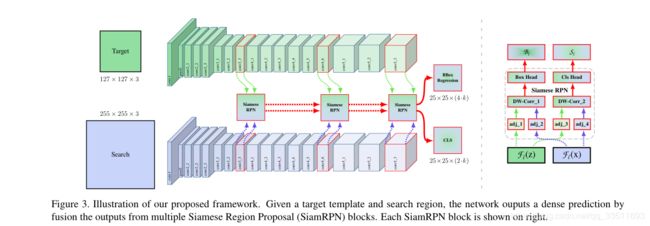
由于多个 RPN 模块的输出,有相同的分辨率。所以,直接对这几个结果进行加权求和,其中权重参数是通过网络学习得出,可以表达为:
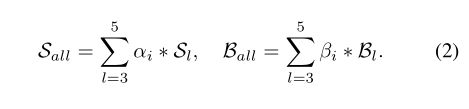
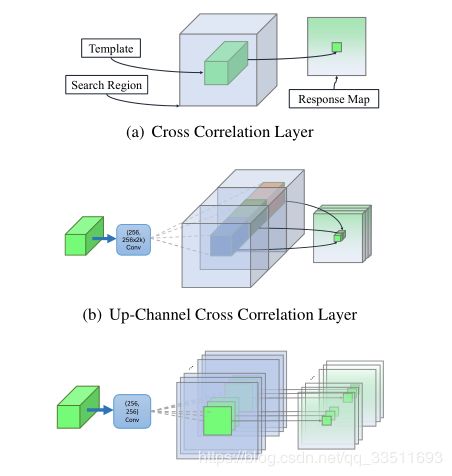
Depthwise Cross Correlation
Cross correlation module 是映射两个分支信息的核心操作。SiamFC 利用 Cross-Correlation layer 来得到单个通道响应图进行位置定位。在 SiamRPN 中,Cross-Correlation 被拓展到更加高层的信息,例如 anchors,通过增加一个 huge convolutional layer 来 scale the channels (UP-Xcorr)。这个 heavy up-channel module 使得参数非常不平衡(RPN 模块包含 20M 参数,而特征提取部分仅包含 4M 参数),这就使得 SiamRPN 变的非常困难。于是作者提出一个轻量级的 cross correlation layer,称为:Depthwise Cross Correlation (DW-XCorr),以得到更加有效的信息贯通。DW-XCorr layer 包含少于 10 倍的参数(相比于 UP-XCorr used in RPN),而性能却可以保持不降。
为了达到这个目标,作者采用一个 conv-bn block 来调整特征,来适应跟踪任务。Bounding box prediction 和 基于 anchor 的分类都是非对称的 (asymmetrical)。为了编码这种不同,the template branch 和 search branch 传输两个 non-shared convolutional layers。然后,这两个 feature maps 是有相同个数的 channels,然后一个 channel 一个 channel 的进行 correlation operation。另一个 conv-bn-relu block,用于融合不同 channel 的输出。最终,最后一个卷积层,用于输出 classification 和 regression 的结果。
通过用 Depthwise correlation 替换掉 cross-correlation,我们可以很大程度上降低计算代价和内存使用。通过这种方式,template 和 search branch 的参数数量就会趋于平衡,导致训练过程更加稳定。
代码解读
代码运行
代码地址
下载代码按照INSTALL.md中的步骤安装环境。
以SiamRPN++代码为例实现长期追踪:
- 下载预训练模型中的siamrpn_r50_l234_dwxcorr_lt,可用于长期追踪。将下载号的模型放置在目录./experiment/siamrpn_r50_l234_dwxcorr_lt下。
- 下载 VOT18-LT长期追踪数据,在pysot目录下新建目录person,将下载的长期追踪的图片放置在改目录下。
- 修改./tools/demo.py,将参数放置在脚本中。运行代码后出现第一帧图片按鼠标左键把目标框出来,然后点击enter键即可。

源代码中部分代码解析 (以LT为例)
demo.py
文件中函数get_frames通过三种方式获取三种形式的输入分别是jp*图片输入、avi mp4的音频输入以及摄像头输入
main()函数中首先是加载模型以及模型中使用的参数、创建模型、加载模型权重、构建track.
其中构建的track路径的代码在pysot.tracker.siamrpnlt_tracker.SiamRPNLTTracker
基础网络结构如下:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
)
adjust layer
AdjustAllLayer(
(downsample2): AdjustLayer(
(downsample): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(downsample3): AdjustLayer(
(downsample): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(downsample4): AdjustLayer(
(downsample): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
rpn基础框架如下:
MultiRPN(
(rpn2): DepthwiseRPN(
(cls): DepthwiseXCorr(
(conv_kernel): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(conv_search): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(head): Sequential(
(0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(128, 10, kernel_size=(1, 1), stride=(1, 1))
)
)
(loc): DepthwiseXCorr(
(conv_kernel): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(conv_search): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(head): Sequential(
(0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(128, 20, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(rpn3): DepthwiseRPN(
(cls): DepthwiseXCorr(
(conv_kernel): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(conv_search): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(head): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(256, 10, kernel_size=(1, 1), stride=(1, 1))
)
)
(loc): DepthwiseXCorr(
(conv_kernel): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(conv_search): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(head): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(256, 20, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(rpn4): DepthwiseRPN(
(cls): DepthwiseXCorr(
(conv_kernel): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(conv_search): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(head): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(512, 10, kernel_size=(1, 1), stride=(1, 1))
)
)
(loc): DepthwiseXCorr(
(conv_kernel): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(conv_search): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
)
(head): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(512, 20, kernel_size=(1, 1), stride=(1, 1))
)
)
)
)
整体代码简述
整体代码主要分成两个部分,第一个是初始帧标记的目标box为temple,第二个部分为追踪过程中的track目标。
- 代码首先将初始帧进行处理成127*127的形式然后进入主体网络(包括resnet50(经过resnet50后输出三个feature_map大小分别是[1, 512, 15, 15]、[1, 1024, 15, 15]、[1, 2048, 15, 15])和adjustnect)框架中,并将输出的3个feature_map,其大小分别是[1, 128, 7, 7]、[1, 256, 7, 7]、[1, 512, 7, 7]进行保存。
- 追踪过程(始终保持上一帧目标位置的中心),根据上一帧目标位置的得分判断是否进行长期追踪(长期追踪围绕中心位置搜索的面积较大写,短期追踪围绕中心面积搜索的范围较小,是否进行长期追踪主要是根据上上衣目标帧的得分决定),按照追踪形式将上一帧范围内的像素进行剪裁填充以及resize成255*255,将剪裁过后的图片输入到网络框架中(包括resnet50经过resnet50后输出三个feature_map大小分别是[1, 512, 31, 31]、[1, 1024, 31, 31]、[1, 2048, 31, 31])和adjustnect),并输出三个feature_map大小分别为[1, 128, 31, 31]、[1, 256, 31, 31]、[1, 512, 31, 31]
- 最后temple和track中分别输出的feature_map进入rpn网络中,按照索引一一对应进行卷积操,之后将templw中的feature展开成[temple.size[0]*temple.size[1], 1,temple.size[2],temple. zise[3]]的形式作为kernel,track同样改变通道数作输入层进行卷积操作,之后将三次卷积操作的结果按照一定权重(网络中训练出来的权重参数)相加最后输出。rpn中有两个分支一个用来预测是否是目标类别cls输出的tensor大小[1, 10, 25,25](选择的anchor数为5,预测为2分类因此第二个维度上的通道数为10),另一个分支预测位置的偏移量loc,输出的tensor大小为[1, 20, 25, 25](选择的anchor为5,预测四个位置上的偏移[x, y, w, h])。
- 根据cls何loc的输出预测是否是目标以及目标位置,将cls何loc分别展开成[3125, 2], [3125, 4]的形式,cls经过softmax分类器,并取最后一列最为目标位置的预测概率。anchor box结合回归结果得出bounding box。最后使用余弦窗和尺度变化惩罚来对cls中经过softmax处理过后的最后一列进行排序,选最好的。余弦窗是为了抑制距离过大的,尺度惩罚是为了抑制尺度大的变化
代码主体
第一帧图片的处理即template
得到测试集中的第一帧框出目标框,并初始化第一帧模型
获取目标框代码:init_rect对应目标框的[左上x位置,左上y位置,宽, 高]

初始化第一帧:
![]()
通过SiamRPNLTTracker的父类SiamRPNTracker也就是SiamRPN_Tracker.py中的init(self, img, bbox)函数。
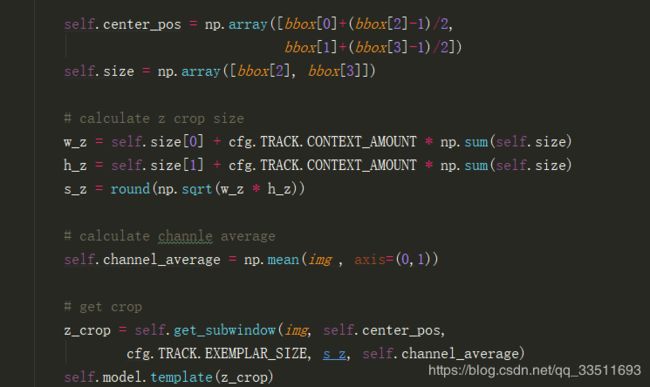
首先根据目标框框出来的位置对应的中心center_pose, 计算剪裁的图片大小s_z,channel_average为对应的图片三个通道RGB的平均值。
get_subwindow函数在SiamRPNTracker的父类BaseTracker中def get_subwindow(self, im, pos, model_sz, original_sz, avg_chans),输入分别是图片(第一帧的图片),目标框对应的中心坐标, 目标剪裁大小127,原始框定的目标框大小, 每个通道的平均值。
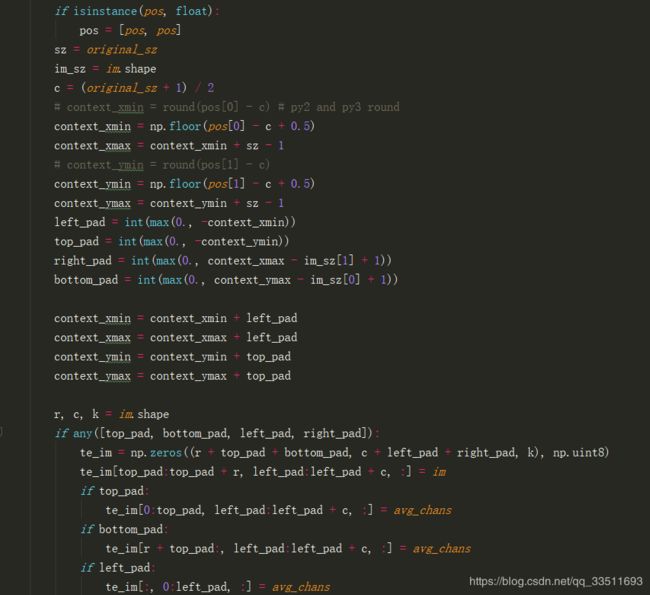
首先按照原始框的大小[s_z, s_z]剪裁图片对于超出原始图片大小范围内的像素值用通道平均值补上。
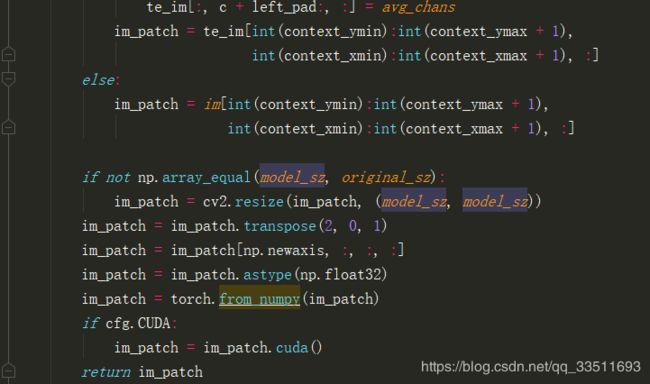
将填充玩的图片按照[s_z, s_z]的大小剪裁,如果s_z不等于127则resize成[127,127].将剪裁的图片的最后一个通道放置到第一个通道得到的z_crop为[3, 127, 127]
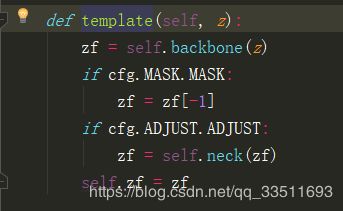
template对应model_builder.py中的函数
首先经过backbone对应pysot.models.backbone.resnet_atrous.resnet50,按照论文中的网络结构从最后三个残差模块,得到对应的输出:F3(z), F4(z) 以及 F5(z)分别对应的shape为 zf[0].shape = [1,512,15,15], zf[1].shape = [1,1024,15,15], zf[2].shape = [1,2048,15,15].
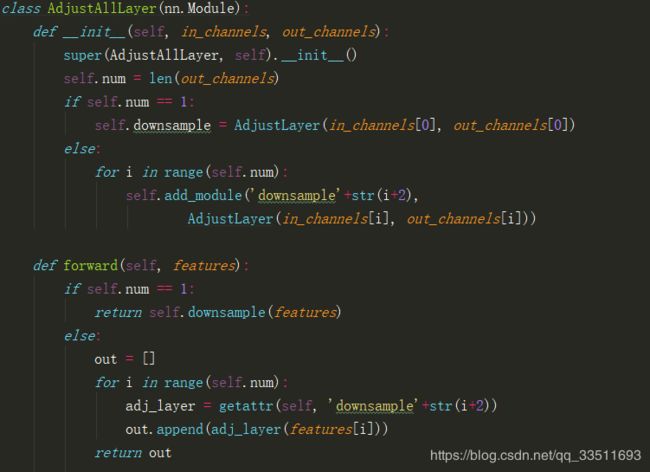
通过adjust网络neck将通道数降低,得到的输出分别为 [1,128,7,7], [1, 256, 7, 7], [1, 512, 7, 7]
track层对应的代码解析
对后续的输入图片进行追踪
![]()
track.track(frame)函数对应siamrpnlt_tracker.py中的track(self,img)
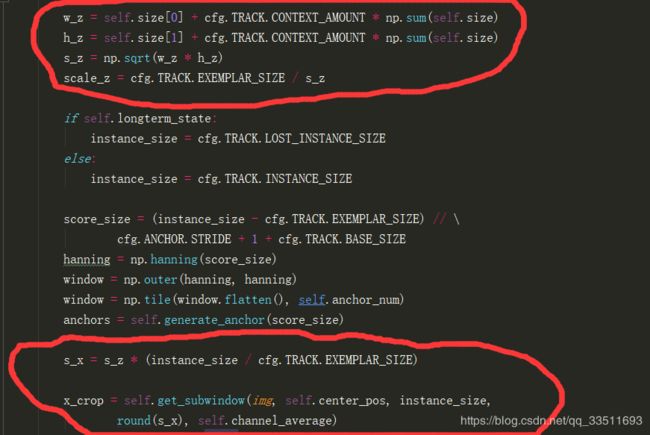
与初始帧类似,求得 s_z(原始图片剪裁的大小)*(instance_size / cfg.TRACK.EXEMPLAR_SIZE) ,以instance_size 为201,EXEMPLAR_SIZE为127为例。计算得到s_x为转换过后的剪裁图片大小。
get_subwindow操作跟初始帧一样,最终得到x_crop形状为[3, 201, 201]

model.track函数对应model_builder.py中的函数
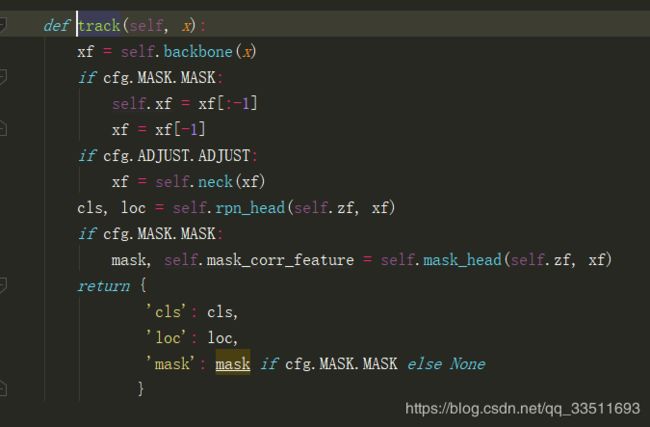
首先和初始真帧的处理类似,经过backbone得到最后三个残差对应的输出。以201的instance_size为例xf is list with len 3 shape[(1, 512, 24, 24), (1, 1024, 24, 24), (1, 2048, 24, 24)]经过neck函数变为shape[(1, 128, 24, 24), (1, 256, 24, 24), (1,512, 24, 24)](ps:目前没有弄明白初始帧和后续图片对应的neck出来的大小变化不一致).
rpn引用pysot.models.head.rpn.MultiRPN。

得到cls, loc分别为zf何xf经过DepthwiseXcorr网络,网络具体过程如下。
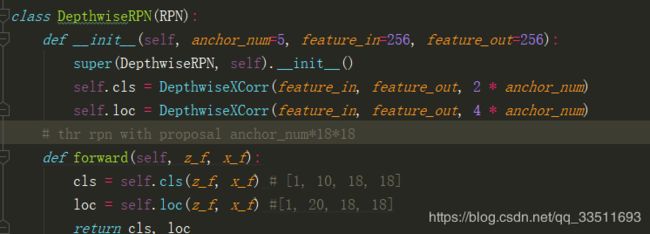
初始帧z_f经过卷积操作conv_kernel后作为卷积核, x_f经过卷积操作conv_kernel后作为t特征图进行卷积操作,z_f, x_f长度均为3,每个位置上的卷积核和特征图进行卷积操作后得到成c,l.达到的3个c求平均,3个l求平均最终输出cls, loc形状分别为[1, 10, 18, 18]、[1, 20, 18,18].其中rpn对应的proposal个数为18185(将原始图片划分成18*18的网格)
![]()
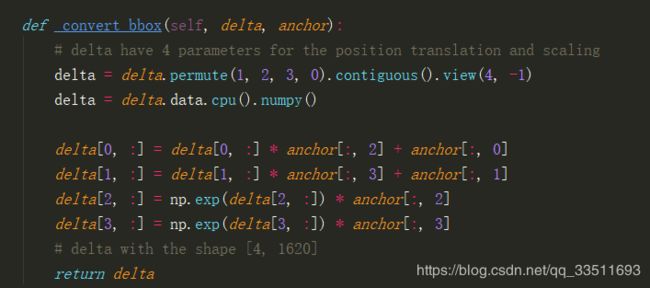
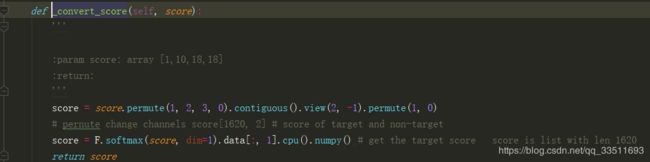
将score和pred_bbox分别平铺成直观理解的方式:
scores首先平铺成[1620,2]的形式,l两列分别为前景和背景的概率,[:1]然后经过softmax将得分约束在0-1之间。
pred_bbox在原始图片(x_crop)中5个anchor对应的[x, y, w, h]的基础上进行平移和缩放。anchor.shape[4, 1064] .