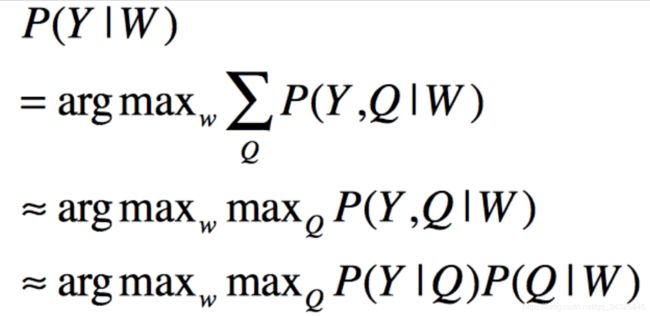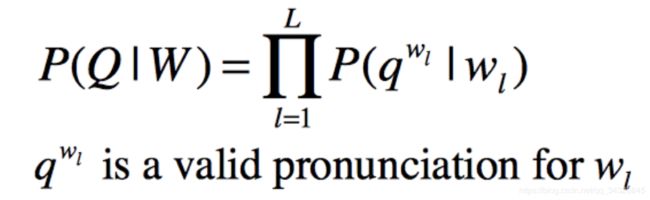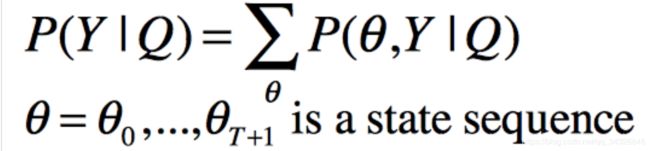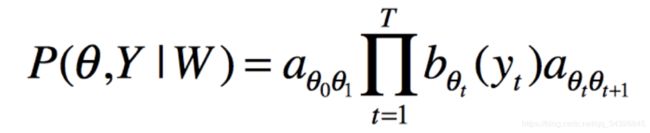- mysql查询统计聚合函数
三小皮
mysql数据库
业务中用户统计报表使用,查询字段使用聚合函数+条件,快速实现报表统计。SELECTMIN(s.org_name)ASorgName,s.way_nameASwayName,COUNT(s.id)ASwaybillTotal,SUM(s.take_weight)AStakeWeightTotal,SUM(s.revert_weight)ASrevertWeightTotal,SUM(s.settle
- 英语日积月累2023-06-08
抽刀断水2
StratifiedStratifiedStratified分层此外,欧洲社会相对来说是分阶层的;职业和社会地位是通过继承得到的。Moreover,Europeansocietywasrelativelystratified;occupationandsocialstatuswereinherited.straightforwardstraightforwardstraightforward直爽的
- 辛普森积分公式
maze_illusion
数论模板
f()为被积函数doublesimpson(doublel,doubler){doublemid=(l+r)/2;return(f(l)+4*f(mid)+f(r))*(r-l)/6.0;}doubleasr(doublel,doubler){doublemid=(l+r)/2;doubleres=simpson(l,r);if(fabs(res-simpson(l,mid)-simpson(mi
- 大规模 K8s 集群管理经验分享 · 上篇
尔达 Erda
数据库javajenkins
11月23日,Erda与OSCHINA社区联手发起了【高手问答第271期–聊聊大规模K8s集群管理】,目前问答活动已持续一周,由ErdaSRE团队负责人骆冰利为大家解答,以下是本次活动的部分问题整理合集,其他问题也将于近期整理后发布,敬请期待!Q1:K8s上面部署不通的应用对于存储有不同的要求,有的要高吞吐,有的是要低响应。大规模K8s部署的时候是怎么协调这种存储差异的问题?还是说需要根据不同的场
- docker打印容器启动命令和输出dockerfile
liujiangxu
dockerdocker容器运维
runlike:通过容器打印启动命令通过pip方式安装pipinstallrunlike通过容器方式安装(永久别名:配置在~/.bashrc中)aliasrunlike="dockerrun--rm-v/var/run/docker.sock:/var/run/docker.sockassaflavie/runlike"用法:runlike容器名/容器idrunlike-p容器名/容器id示例:r
- 蒙特卡罗——三门问题python代码实现
潮汐退涨月冷风霜
python开发语言蒙特卡罗
三门问题b站李永乐老师讲解三门问题python蒙特卡罗模拟#模拟三门问题importrandomasrd#n:模拟次数,m:中奖次数n=100000m=0foriinrange(n):#车位于的门号car=rd.randint(0,2)#人随机选择一个门door=rd.randint(0,2)#主持人展示空门empties={0,1,2}-{car,door}empty=rd.choice(lis
- python爬虫处理滑块验证_python selenium爬虫滑块验证
用户6731453637
python爬虫处理滑块验证
importrandomimporttimefromPILimportImagefromioimportBytesIOimportrequestsasrqfrombs4importBeautifulSoupasbsfromseleniumimportwebdriverfromselenium.webdriverimportActionChainsfromselenium.webdriverimpo
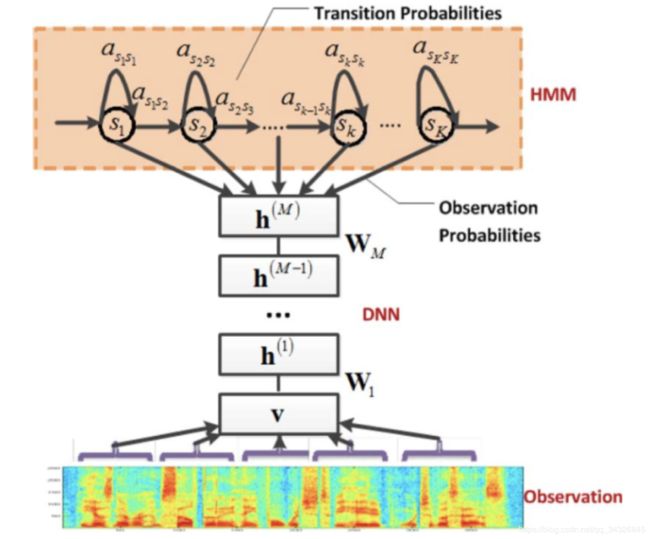
- FunASR 语音识别系统概述
瑞雪兆我心
语音识别人工智能
FunASR(AFundamentalEnd-to-EndSpeechRecognitionToolkit)是一个基础的语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复(PR)、语言模型(LM)、说话人分离等。项目源地址1语音识别(ASR)参考语音交互:聊聊语音识别-ASR(万字长文)语音识别技术(AutomaticSpeechRecognition,ASR)
- 蒙特卡罗方法——布丰投针实验近似计算圆周率python代码实现
潮汐退涨月冷风霜
python开发语言蒙特卡罗
布丰实验数学原理python代码importrandomasrdimportnumpyasnpimportmathimportmatplotlib.pyplotaspltimportmatplotlibmatplotlib.rcParams['font.family']='SimHei'#或者'MicrosoftYaHei'matplotlib.rcParams['axes.unicode_min
- ERROR:master启动报错: Attempting to operate on hdfs namenode as root
CourageLee
Dockerhadooplinux
[root@masterhadoop]#sbin/start-all.shStartingnamenodeson[master]ERROR:AttemptingtooperateonhdfsnamenodeasrootERROR:butthereisnoHDFS_NAMENODE_USERdefined.Abortingoperation.StartingdatanodesERROR:Attemp
- VBA核对数据
猛犸象和剑齿虎
OptionExplicitSub分机床产量()DimrngAsRange,rng1AsRangeForEachrngInWorksheets("产量表").Range("c2:c85")ForEachrng1InRange("c2:c81")Ifrng1.Value=rng.ValueThenIfApplication.WorksheetFunction.CountIf(Range("c2:c8
- 语音识别 学习笔记2024
AI算法网奇
深度学习基础音视频人工智能
目录dragonfly阿里达摩院FunASR:一款高效的端到端语音识别工具包不错的功能介绍librosa安装语音识别dragonfly阿里达摩院FunASR:一款高效的端到端语音识别工具包不错的功能介绍librosa,一个很有趣的Python库!-简书音频转特征向量GitHub-librosa/librosa:Pythonlibraryforaudioandmusicanalysislibrosa
- Oracle SQL下的数据小数位数控制
奔驰在大道上的程序猿
Java小功能分析oraclejavasql小数位数控制
一般,控制数据小数的方法我认为的有三大类,但如果可以在sql中设置那最好。Java次之,然后是前台。因为在前台最好不要有大多的业务处理代码。在sql中设置"selectyearmon,round(data,2)asdata,round(rate,2)asratefrom"+dbTable+"wheredept_code=?anditem_code=?andlength(yearmon)=?"+"o
- sqlserver 删除重复数据,保留一条
mmkkuoi
sqlsql
1.WITHcteAS(SELECTFBase1,ftext,ROW_NUMBER()OVER(PARTITIONBYFBase1,ftextORDERBY(SELECT0))ASrnFROMtablewherefid=1006)DELETEFROMcteWHERErn>1;2.--查询重复数据,确认select*From(SelectRow_Number()Over(PartitionBy[Na
- 【论文阅读】Purloining Deep Learning Models Developed for an Ultrasound Scanner to a Competitor Machine
Bosenya12
科研学习模型窃取论文阅读深度学习人工智能模型安全
TheArtoftheSteal:PurloiningDeepLearningModelsDevelopedforanUltrasoundScannertoaCompetitorMachine(2024)摘要Atransferfunctionapproach(传递函数方法)hasrecentlyproveneffectiveforcalibratingdeeplearning(DL)algorit
- 《PRINCIPLES》
鹿女神奇
DaytwoIamconfidentthatwhateversuccessBridgewaterandIhavehadhasresultedfromouroperatingbycertainprinciples.Creatingagreatculture,findingtherightpeople,managingthemtodogreatthingsandsolvingproblemscreat
- 如何快速判断Excel中选区跨页?
taller_2000
VBAExcel表格跨页选区跨页分页符工作表跨页水平分页
实例需求:应用开发过程中,需要校验选中区域,要求选中区域不能跨页,即选中区域分布在两个不同的页面中。示例代码如下。SubDemo()DimrSelectAsRange,oHPAsHPageBreakDimUpCellAsRange,DownCellAsRangeSetrSelect=Selection.EntireRowActiveWindow.View=xlPageBreakPreviewFor
- The connection to the server localhost:8080 was refused - did you specify the right host or port?
做咩啊~
K8s报错收集kubernetes
如果在node节点上执行kubectlgetnode报Theconnectiontotheserverlocalhost:8080wasrefused-didyouspecifytherighthostorport?1.将master节点中/etc/kubernetes/admin,conf拷贝到需要运行的服务器的/etc/kubernetes目录中scp/etc/kubernetes/admin
- python爬虫:通过DBLP数据库获取数据挖掘顶会KDD在2023年的论文收录和相关作者信息
千里澄江
python数据分析python爬虫算法数据挖掘数据分析
Task1读取网站主页整个页面的html内容并解码为文本串(可使用urllib.request的相应方法),将其以UTF-8编码格式写入page.txt文件。Code1importurllib.requestwithurllib.request.urlopen('https://dblp.dagstuhl.de/db/conf/kdd/kdd2023.html')asresponse:html=r
- 写个vba程序,能合并多个文件
谛听汪
microsoft深度学习人工智能
你好!下面是一个可以合并多个文件的VBA程序:SubMergeFiles()'定义变量DimFilesToOpen,FileNameAsStringDimFileNumAsIntegerDimCounterAsIntegerDimRowNdxAsLongDimColNdxAsIntegerDimSheetAsWorksheetDimWorkBkAsWorkbookDimSourceRangeAsR
- vue实现抓娃娃机效果
一个萌新小土豆
vue.js前端javascript
1.抓娃娃机随机抓取底部多行娃娃左右滚动,点击开始随机抓取exportdefault{data(){return{yidongtime:null,yidongtimeright:null,yidongright:0,yidongleft:0,zhuazhu:'',zhuasrc:require('../assets/jiazi.png'),//按钮图片isend:true,long:0,list:
- 破解树莓派RP2350!获得10000美元的奖励!
上海晶珩EDATEC
树莓派树莓派5RaspberryPiRaspberryPi5工业计算机
我们认为RP2350这款新型高性能安全微控制器相当安全和坚固。你愿意测试一下这个理论吗?(我们完全承认,只要有足够的时间和资源,任何东西都是可以破解的)。接受挑战!在我们推出RP2350和RaspberryPiPico2之前,我们希望对芯片和软件的安全功能进行一些测试,因此我们与安全测试领域的一些顶尖人物进行了合作:托马斯-罗斯(ThomasRoth)和科林-奥弗林(ColinO'Flynn)。通
- 经验-总结1
DongGei
数据库java
IDEAdebug启动慢断点先全部关了group_concat的长度限制现象:roleNames直接会截取到默认的group_concat的长度限制设置(1024字节)selectgroup_concat(role.rolename)asroleNames,group_concat(role.roleId)asroleIdsfromPUB_USER_ROLE_LINKp,PUB_ROLE_INFO
- Unity世界坐标转屏幕坐标计算
问道飞鱼
UnitycanvasWorldToScreenunity
这个是最近工作当中遇到的问题,世界坐标转Canvas坐标,实际操作过可以,在这里记录一下privateVector2WorldToScreen(Transformtrans){//首先找到你画布的矩形框RectTransformCanvasRect=_canvas.GetComponent();//然后计算UI元素的位置//0,0forthecanvasisatthecenterofthescre
- oracle中10张表合并一张,oracle 将多张表中的列合并到一张表中
weixin_39538607
oracle中10张表合并一张
oracle将多张表中的列合并到一张表中一.问题回顾我们目前有表A和表B,两个表分别有一列,我们想查询出来的结果如表C,它同时包含了表A和表B的列;二.解决方案为了测试方便,我们直接使用Oracle数据库的scott用户下的表emp和表dept;表emp:selectrownumasrn1,t.*fromscott.empt表dept:selectrownumasrn2,t.*fromscott.
- AttributeError: module ‘keras.api._v2.keras‘ has no attribute ‘wrappers‘
qq_58677554
pythontensorflow2
fromtensorflow.python.keras.wrappers.scikit_learnimportKerasRegressor在使用KerasRegressor函数时出现问题方法一:降低tensorflow的版本为2.5,keras也要改变,看到有一个2.5的使用教程,但没试方法二:改用其他函数scikeras,因为wrappers.scikit_learn内容发生迁移,如图西克拉斯·
- react native 总结
一切顺势而行
reactnativereact.jsjavascript
reactapp.js相当与vueapp.vueimportReactfrom'react';import'./App.css';importReactRoutefrom'./router'import{HashRouterasRouter,Link}from'react-router-dom'classAppextendsReact.Component{constructor(props){su
- 【ARMv8M Cortex-M33 系列 2.4 -- JFlash 烧写之链接脚本介绍】
主公CodingCos
#【ARMv8MM33专栏】嵌入式硬件arm开发
文章目录JFlash烧写之链接脚本介绍MEMORY区段示例SECTIONS区段示例符号定义启动代码实际使用ARMBCC指令介绍BCC指令使用举例JFlash烧写之链接脚本介绍在RT-Thread实时操作系统中,链接脚本(LinkerScript)定义了如何将代码和数据映射到微控制器的内存中。链接脚本通常以.ld为扩展名。对于特定的微控制器,如RenesasR7FA4M2AC3C,链接脚本中的MEM
- sqlserver 里面top语句会影响到数据库查询速度
巧克力牌猫头鹰
数据库sqlserver
具体什么原因不太清楚,有个写法大家参考一下RANK()OVER(ORDERBYst.study_uid_id)ASrnkSELECT文档IdFROM(SELECT'1.2.3.4.'+st.study_uidAS文档Id,RANK()OVER(ORDERBYst.study_uid_id)ASrnkFROMdbo.patient1A(NOLOCK)INNERJOINdbo.study1stONST
- tvm交叉编译android opencl
极乐净土0822
androidtvmndk交叉编译opencl
模型编译:#encoding:utf-8importonnximportnumpyasnpimporttvmimporttvm.relayasrelayimportosfromtvm.contribimportndkonnx_model=onnx.load('mobilenet_v3_small.onnx')x=np.ones([1,3,224,224])input_name='input1'sh
- java责任链模式
3213213333332132
java责任链模式村民告县长
责任链模式,通常就是一个请求从最低级开始往上层层的请求,当在某一层满足条件时,请求将被处理,当请求到最高层仍未满足时,则请求不会被处理。
就是一个请求在这个链条的责任范围内,会被相应的处理,如果超出链条的责任范围外,请求不会被相应的处理。
下面代码模拟这样的效果:
创建一个政府抽象类,方便所有的具体政府部门继承它。
package 责任链模式;
/**
*
- linux、mysql、nginx、tomcat 性能参数优化
ronin47
一、linux 系统内核参数
/etc/sysctl.conf文件常用参数 net.core.netdev_max_backlog = 32768 #允许送到队列的数据包的最大数目
net.core.rmem_max = 8388608 #SOCKET读缓存区大小
net.core.wmem_max = 8388608 #SOCKET写缓存区大
- php命令行界面
dcj3sjt126com
PHPcli
常用选项
php -v
php -i PHP安装的有关信息
php -h 访问帮助文件
php -m 列出编译到当前PHP安装的所有模块
执行一段代码
php -r 'echo "hello, world!";'
php -r 'echo "Hello, World!\n";'
php -r '$ts = filemtime("
- Filter&Session
171815164
session
Filter
HttpServletRequest requ = (HttpServletRequest) req;
HttpSession session = requ.getSession();
if (session.getAttribute("admin") == null) {
PrintWriter out = res.ge
- 连接池与Spring,Hibernate结合
g21121
Hibernate
前几篇关于Java连接池的介绍都是基于Java应用的,而我们常用的场景是与Spring和ORM框架结合,下面就利用实例学习一下这方面的配置。
1.下载相关内容: &nb
- [简单]mybatis判断数字类型
53873039oycg
mybatis
昨天同事反馈mybatis保存不了int类型的属性,一直报错,错误信息如下:
Caused by: java.lang.NumberFormatException: For input string: "null"
at sun.mis
- 项目启动时或者启动后ava.lang.OutOfMemoryError: PermGen space
程序员是怎么炼成的
eclipsejvmtomcatcatalina.sheclipse.ini
在启动比较大的项目时,因为存在大量的jsp页面,所以在编译的时候会生成很多的.class文件,.class文件是都会被加载到jvm的方法区中,如果要加载的class文件很多,就会出现方法区溢出异常 java.lang.OutOfMemoryError: PermGen space.
解决办法是点击eclipse里的tomcat,在
- 我的crm小结
aijuans
crm
各种原因吧,crm今天才完了。主要是接触了几个新技术:
Struts2、poi、ibatis这几个都是以前的项目中用过的。
Jsf、tapestry是这次新接触的,都是界面层的框架,用起来也不难。思路和struts不太一样,传说比较简单方便。不过个人感觉还是struts用着顺手啊,当然springmvc也很顺手,不知道是因为习惯还是什么。jsf和tapestry应用的时候需要知道他们的标签、主
- spring里配置使用hibernate的二级缓存几步
antonyup_2006
javaspringHibernatexmlcache
.在spring的配置文件中 applicationContent.xml,hibernate部分加入
xml 代码
<prop key="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</prop>
<prop key="hi
- JAVA基础面试题
百合不是茶
抽象实现接口String类接口继承抽象类继承实体类自定义异常
/* * 栈(stack):主要保存基本类型(或者叫内置类型)(char、byte、short、 *int、long、 float、double、boolean)和对象的引用,数据可以共享,速度仅次于 * 寄存器(register),快于堆。堆(heap):用于存储对象。 */ &
- 让sqlmap文件 "继承" 起来
bijian1013
javaibatissqlmap
多个项目中使用ibatis , 和数据库表对应的 sqlmap文件(增删改查等基本语句),dao, pojo 都是由工具自动生成的, 现在将这些自动生成的文件放在一个单独的工程中,其它项目工程中通过jar包来引用 ,并通过"继承"为基础的sqlmap文件,dao,pojo 添加新的方法来满足项
- 精通Oracle10编程SQL(13)开发触发器
bijian1013
oracle数据库plsql
/*
*开发触发器
*/
--得到日期是周几
select to_char(sysdate+4,'DY','nls_date_language=AMERICAN') from dual;
select to_char(sysdate,'DY','nls_date_language=AMERICAN') from dual;
--建立BEFORE语句触发器
CREATE O
- 【EhCache三】EhCache查询
bit1129
ehcache
本文介绍EhCache查询缓存中数据,EhCache提供了类似Hibernate的查询API,可以按照给定的条件进行查询。
要对EhCache进行查询,需要在ehcache.xml中设定要查询的属性
数据准备
@Before
public void setUp() {
//加载EhCache配置文件
Inpu
- CXF框架入门实例
白糖_
springWeb框架webserviceservlet
CXF是apache旗下的开源框架,由Celtix + XFire这两门经典的框架合成,是一套非常流行的web service框架。
它提供了JAX-WS的全面支持,并且可以根据实际项目的需要,采用代码优先(Code First)或者 WSDL 优先(WSDL First)来轻松地实现 Web Services 的发布和使用,同时它能与spring进行完美结合。
在apache cxf官网提供
- angular.equals
boyitech
AngularJSAngularJS APIAnguarJS 中文APIangular.equals
angular.equals
描述:
比较两个值或者两个对象是不是 相等。还支持值的类型,正则表达式和数组的比较。 两个值或对象被认为是 相等的前提条件是以下的情况至少能满足一项:
两个值或者对象能通过=== (恒等) 的比较
两个值或者对象是同样类型,并且他们的属性都能通过angular
- java-腾讯暑期实习生-输入一个数组A[1,2,...n],求输入B,使得数组B中的第i个数字B[i]=A[0]*A[1]*...*A[i-1]*A[i+1]
bylijinnan
java
这道题的具体思路请参看 何海涛的微博:http://weibo.com/zhedahht
import java.math.BigInteger;
import java.util.Arrays;
public class CreateBFromATencent {
/**
* 题目:输入一个数组A[1,2,...n],求输入B,使得数组B中的第i个数字B[i]=A
- FastDFS 的安装和配置 修订版
Chen.H
linuxfastDFS分布式文件系统
FastDFS Home:http://code.google.com/p/fastdfs/
1. 安装
http://code.google.com/p/fastdfs/wiki/Setup http://hi.baidu.com/leolance/blog/item/3c273327978ae55f93580703.html
安装libevent (对libevent的版本要求为1.4.
- [强人工智能]拓扑扫描与自适应构造器
comsci
人工智能
当我们面对一个有限拓扑网络的时候,在对已知的拓扑结构进行分析之后,发现在连通点之后,还存在若干个子网络,且这些网络的结构是未知的,数据库中并未存在这些网络的拓扑结构数据....这个时候,我们该怎么办呢?
那么,现在我们必须设计新的模块和代码包来处理上面的问题
- oracle merge into的用法
daizj
oraclesqlmerget into
Oracle中merge into的使用
http://blog.csdn.net/yuzhic/article/details/1896878
http://blog.csdn.net/macle2010/article/details/5980965
该命令使用一条语句从一个或者多个数据源中完成对表的更新和插入数据. ORACLE 9i 中,使用此命令必须同时指定UPDATE 和INSE
- 不适合使用Hadoop的场景
datamachine
hadoop
转自:http://dev.yesky.com/296/35381296.shtml。
Hadoop通常被认定是能够帮助你解决所有问题的唯一方案。 当人们提到“大数据”或是“数据分析”等相关问题的时候,会听到脱口而出的回答:Hadoop! 实际上Hadoop被设计和建造出来,是用来解决一系列特定问题的。对某些问题来说,Hadoop至多算是一个不好的选择,对另一些问题来说,选择Ha
- YII findAll的用法
dcj3sjt126com
yii
看文档比较糊涂,其实挺简单的:
$predictions=Prediction::model()->findAll("uid=:uid",array(":uid"=>10));
第一个参数是选择条件:”uid=10″。其中:uid是一个占位符,在后面的array(“:uid”=>10)对齐进行了赋值;
更完善的查询需要
- vim 常用 NERDTree 快捷键
dcj3sjt126com
vim
下面给大家整理了一些vim NERDTree的常用快捷键了,这里几乎包括了所有的快捷键了,希望文章对各位会带来帮助。
切换工作台和目录
ctrl + w + h 光标 focus 左侧树形目录ctrl + w + l 光标 focus 右侧文件显示窗口ctrl + w + w 光标自动在左右侧窗口切换ctrl + w + r 移动当前窗口的布局位置
o 在已有窗口中打开文件、目录或书签,并跳
- Java把目录下的文件打印出来
蕃薯耀
列出目录下的文件文件夹下面的文件目录下的文件
Java把目录下的文件打印出来
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年7月11日 11:02:
- linux远程桌面----VNCServer与rdesktop
hanqunfeng
Desktop
windows远程桌面到linux,需要在linux上安装vncserver,并开启vnc服务,同时需要在windows下使用vnc-viewer访问Linux。vncserver同时支持linux远程桌面到linux。
linux远程桌面到windows,需要在linux上安装rdesktop,同时开启windows的远程桌面访问。
下面分别介绍,以windo
- guava中的join和split功能
jackyrong
java
guava库中,包含了很好的join和split的功能,例子如下:
1) 将LIST转换为使用字符串连接的字符串
List<String> names = Lists.newArrayList("John", "Jane", "Adam", "Tom");
- Web开发技术十年发展历程
lampcy
androidWeb浏览器html5
回顾web开发技术这十年发展历程:
Ajax
03年的时候我上六年级,那时候网吧刚在小县城的角落萌生。传奇,大话西游第一代网游一时风靡。我抱着试一试的心态给了网吧老板两块钱想申请个号玩玩,然后接下来的一个小时我一直在,注,册,账,号。
彼时网吧用的512k的带宽,注册的时候,填了一堆信息,提交,页面跳转,嘣,”您填写的信息有误,请重填”。然后跳转回注册页面,以此循环。我现在时常想,如果当时a
- 架构师之mima-----------------mina的非NIO控制IOBuffer(说得比较好)
nannan408
buffer
1.前言。
如题。
2.代码。
IoService
IoService是一个接口,有两种实现:IoAcceptor和IoConnector;其中IoAcceptor是针对Server端的实现,IoConnector是针对Client端的实现;IoService的职责包括:
1、监听器管理
2、IoHandler
3、IoSession
- ORA-00054:resource busy and acquire with NOWAIT specified
Everyday都不同
oraclesessionLock
[Oracle]
今天对一个数据量很大的表进行操作时,出现如题所示的异常。此时表明数据库的事务处于“忙”的状态,而且被lock了,所以必须先关闭占用的session。
step1,查看被lock的session:
select t2.username, t2.sid, t2.serial#, t2.logon_time
from v$locked_obj
- javascript学习笔记
tntxia
JavaScript
javascript里面有6种基本类型的值:number、string、boolean、object、function和undefined。number:就是数字值,包括整数、小数、NaN、正负无穷。string:字符串类型、单双引号引起来的内容。boolean:true、false object:表示所有的javascript对象,不用多说function:我们熟悉的方法,也就是
- Java enum的用法详解
xieke90
enum枚举
Java中枚举实现的分析:
示例:
public static enum SEVERITY{
INFO,WARN,ERROR
}
enum很像特殊的class,实际上enum声明定义的类型就是一个类。 而这些类都是类库中Enum类的子类 (java.l