用Python统计文本文件中词汇字母短语等分布
这是MSRA的高级软件设计结对编程的作业
这篇博客讨论具体地实现方式与过程,包括效能分析与单元测试
分析的工具使用方法可以参考这两篇博客:
该项目的完整代码,请参考下面的Github:
https://github.com/ThomasMrY/ASE-project-MSRA
先看一下这个项目的要求:
用户需求:英语的26 个字母的频率在一本小说中是如何分布的?某类型文章中常出现的单词是什么?某作家最常用的词汇是什么?《哈利波特》 中最常用的短语是什么,等等。 我们就写一些程序来解决这个问题,满足一下我们的好奇心。
要求:程序的单元测试,回归测试,效能测试C/C++/C# 等基本语言的运用和 debug。
题目要求:
Step-0:输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
Step-1:输出单个文件中的前 N 个最常出现的英语单词。
Step-2:支持 stop words,我们可以做一个 stop word 文件 (停词表), 在统计词汇的时候,跳过这些词。
Step-3:输出某个英文文本文件中 单词短语出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
Step-4:第四步:把动词形态都统一之后再计数。
Step-0:输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
最初的想法是去除掉各种乱七八糟的符号之后,使用遍历整个文本文件的每一个字母,用一个字典存储计数,每次去索引字典的值,索引到该值之后,在字典的value上加一实现。具体实现的代码如下:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author: Enoch time:2018/10/22 0031
import time
import re
import operator
from string import punctuation
start = time.clock()
'''function:Calculate the word frequency of each line
input: line : a list contains a string for a row
counts: an empty dictionary
ouput: counts: a dictionary , keys are words and values are frequencies
data:2018/10/22
'''
def ProcessLine(line,counts):
#Replace the punctuation mark with a space
line = re.sub('[^a-z]', '', line)
for ch in line:
counts[ch] = counts.get(ch, 0) + 1
return counts
def main():
file = open("../Gone With The Wind.txt", 'r')
wordsCount = 0
alphabetCounts = {}
for line in file:
alphabetCounts = ProcessLine(line.lower(), alphabetCounts)
wordsCount = sum(alphabetCounts.values())
alphabetCounts = sorted(alphabetCounts.items(), key=lambda k: k[0])
alphabetCounts = sorted(alphabetCounts, key=lambda k: k[1], reverse=True)
for letter, fre in alphabetCounts:
print("|\t{:15}|{:<11.2%}|".format(letter, fre / wordsCount))
file.close()
if __name__ == '__main__':
main()
end = time.clock()
print (end-start)这样做的代码理论上代码是正确的,为了验证代码的正确性,我们需要使用三个文本文件做单元测试,具体就是,一个空文件,一个小样本文件,和一个样本较多的文件,分别做验证,于是可以写单元测试的代码如下:
from count import CountLetters
CountLetters("Null.txt")
CountLetters("Test.txt")
CountLetters("gone_with_the_wind.txt")
其中:
- Null.txt 是一个空的文本文件
- gone_with_the_wind.txt 是《乱世佳人》的文本文件
- Test.txt 是一个我们自己指定的内容固定的文本文件,这样就可以统计结果的正确性
经过我们的验证,这个结果是正确的。保证了结果的正确性,经过这样的验证,但还不清楚代码的覆盖率怎么样,于是我们使用工具coverage,对代码进行分析,使用如下命令行分析代码覆盖率
coverage run my_program.py arg1 arg2得到的结果如下:
Name Stmts Exec Cover
---------------------------------------------
CountLetters 56 50 100%
---------------------------------------------
TOTAL 56 50 100%可以看到,在保证代码覆盖率为100%的时候,代码运行是正确的。
但程序的运行速度怎么样呢?为了更加了解清楚它的运行速度,我们使用cprofile分析性能,从而提升运行的性能, 使用cprofile运行的结果为
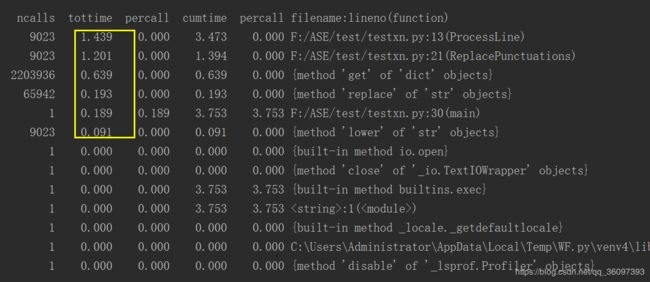
我们大致知道main,Processline,ReplacePunctuations三个模块最耗时,其中最多是ProcessLine,我们就需要看preocessLine()模块里调用了哪些函数,花费了多长时间。
最后使用图形化工具graphviz画出具体地耗时情况如下:

可以从上面的图像中看到文本有9千多行,low函数和re.sub被调用了9023次,每个字母每个字母的统计get也被调用了1765982次,这种一个字母一个字母的索引方式太慢了。我们需要寻求新的解决办法,于是想到了正则表达式,遍历字母表来匹配正则表达式,于是我们就得到了第二版的函数
###################################################################################
#Name:count_letters
#Inputs:file name
#outputs:None
#Author: Thomas
#Date:2018.10.22
###################################################################################
def CountLetters(file_name,n,stopName,verbName):
print("File name:" + os.path.abspath(file_name))
if (stopName != None):
stopflag = True
else:
stopflag = False
if(verbName != None):
print("Verb tenses normalizing is not supported in this function!")
else:
pass
totalNum = 0
dicNum = {}
t0 = time.clock()
if (stopflag == True):
with open(stopName) as f:
stoplist = f.readlines()
with open(file_name) as f:
txt = f.read().lower()
for letter in letters:
dicNum[letter] = len(re.findall(letter,txt))
totalNum += dicNum[letter]
if (stopflag == True):
for word in stoplist:
word = word.replace('\n','')
try:
del tempc[word]
except:
pass
dicNum = sorted(dicNum.items(), key=lambda k: k[0])
dicNum = sorted(dicNum, key=lambda k: k[1], reverse=True)
t1 = time.clock()
display(dicNum[:n],'character',totalNum,9)
print("Time Consuming:%4f" % (t1 - t0))该函数把运行时间从原来的1.14s直接降到了0.2s,通过重复刚才的单元测试以及效能分析(这里我就不重复粘贴结果了),验证了在代码覆盖率为100%的情况下,代码的运行也是正确的,并且发现运行时间最长的就是其中的正则表达式,在这样的情况下,我们又寻求新的解决方案。最终我们发现了文本自带的count方法,将正则表达式用更该方法替换之后,即将上面的代码:
dicNum[letter] = len(re.findall(letter,txt))替换为
dicNum[letter] = txt.count(letter) #here count is faster than re成功的将时间降到了5.83e-5s可以说提高了非常多的数量级,优化到这里,基本上已经达到了优化的瓶颈,没法继续优化了。
注:后来的版本添加了许多功能,这里的代码是添加了功能之后的代码, 如需要运行最初的功能则需要将后面的参数指定成None。
Step-1:输出单个文件中的前 N 个最常出现的英语单词。
首先的了解,单词的定义是什么:
单词:以英文字母开头,由英文字母和字母数字符号组成的字符串视为一个单词。单词以分隔符分割且不区分大小写。在输出时,所有单词都用小写字符表示。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号 例:good123是一个单词,123good不是一个单词。good,Good和GOOD是同一个单词
最初的想法是去除掉各种乱七八糟的符号之后,是用空格分隔出单词,然后遍历文本中的每一个单词,用一个字典存储计数,每次去索引字典的值,索引到该值之后,在字典的value上加一实现。具体实现的代码如下:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author: Eron time:2018/10/22 0022
import time
import re
start = time.time()
from string import punctuation #Temporarily useless
'''function:Calculate the word frequency of each line
input: line : a list contains a string for a row
counts: an empty dictionary
ouput: counts: a dictionary , keys are words and values are frequencies
data:2018/10/22
'''
def ProcessLine(line,counts):
#Replace the punctuation mark with a space
#line=ReplacePunctuations(line)
line = re.sub('[^a-z0-9]', ' ', line)
words = line.split()
for word in words:
counts[word] = counts.get(word, 0) + 1
return counts
'''function:Replace the punctuation mark with a space
input: line : A list containing a row of original strings
ouput: line: a list whose punctuation is all replaced with spaces
data:2018/10/22
'''
def ReplacePunctuations(line):
for ch in line :
#Create our own symbol list
tags = [',','.','?','"','“','”','—']
if ch in tags:
line=line.replace(ch," ")
return line
'''function:Create a taboo "stopwords.txt"
input: line : A list contains all the words in the "Gone With The Wind.txt"
ouput: nono
data:2018/10/23
'''
def CreatStopWordsTxt(list):
file = open('stopwords.txt', 'w')
for str in list:
file.write(str+'\t')
file.close()
'''function:Remove any words that do not meet the requirements
input: dict : A dict whose keys are words and values are frequencies
ouput: dictProc : A removed undesirable words dict
data:2018/10/23
'''
def RemoveUndesirableWords(dict):
wordsCount = 0 # Number of words
wordsCount = sum(dict.values())
dictProc = dict.copy();
for temp in list(dict):
if temp[0].isdigit():
del dictProc[temp]
else:
dictProc[temp] = round(dictProc[temp] / wordsCount, 4)
return dictProc
def CountWords(fileName):
file = open(fileName,'r')
count = 10 #Show the top count words that appear most frequently
alphabetCountsOrg={} # Creates an empty dictionary used to calculate word frequency
for line in file:
alphabetCountsOrg = ProcessLine(line.lower(), alphabetCountsOrg) #Calculate the word frequency of each line
alphabetCounts = RemoveUndesirableWords(alphabetCountsOrg) #Remove any words that do not meet the requirements
pairs = list(alphabetCounts.items()) #Get the key-value pairs from the dictionary
items = [[x,y]for (y,x)in pairs] #key-value pairs in the list exchange locations, data pairs sort
items.sort(reverse=True)
#Notice we didn't order words of the same frequency
for i in range(count ):
print(items[i][1] + "\t" + str(items[i][0]))
file.close()
#CreatStopWordsTxt(alphabetCounts.keys())
if __name__ == '__main__':
CountWords("gone_with_the_wind.txt")
end = time.time()
print (end-start)这样做的代码理论上代码是正确的,为了验证代码的正确性,我们需要使用三个文本文件做单元测试,具体就是,一个空文件,一个小样本文件,和一个样本较多的文件,分别做验证,于是可以写单元测试的代码如下:
from count import CountWords
CountWords("Null.txt")
CountWords("Test.txt")
CountWords("gone_with_the_wind.txt")其中:
- Null.txt 是一个空的文本文件
- gone_with_the_wind.txt 是《乱世佳人》的文本文件
- Test.txt 是一个我们自己指定的内容固定的文本文件,这样就可以统计结果的正确性
经过我们的验证,这个结果是正确的。保证了结果的正确性,经过这样的验证,但还不清楚代码的覆盖率怎么样,于是我们使用工具coverage,对代码进行分析,使用如下命令行分析代码覆盖率
coverage run test.py得到的结果如下:
Name Stmts Exec Cover
---------------------------------------------
CountWords 78 92 100%
---------------------------------------------
TOTAL 78 92 100%可以看到,在保证代码覆盖率为100%的时候,代码运行是正确的。因为代码做了修改,因此需要做回归测试,编写如下代码做回归测试:
from count import CountLetters
from count import CountWords
CountWords("Null.txt")
CountWords("Test.txt")
CountWords("gone_with_the_wind.txt")
CountLetters("Null.txt")
CountLetters("Test.txt")
CountLetters("gone_with_the_wind.txt")但程序的运行速度怎么样呢?为了更加了解清楚它的运行速度,我们使用cprofile分析性能,从而提升运行的性能, 使用cprofile运行的结果为

我们大致知道sub,Split,get三个模块最耗时,其中最多是sub,我们就需要看preocessLine()模块里调用了哪些函数,花费了多长时间。
最后使用图形化工具graphviz画出具体地耗时情况如下:
可以从上面的图像中看到文本有9千多行,low函数和re.sub被调用了9023次,每个字母每个字母的统计get也被调用了1765982次,这种一个单词一个单词的索引方式太慢了。我们需要寻求新的解决办法,于是想到了正则表达式,遍历字母表来匹配正则表达式,于是我们就得到了新的的函数,我们可以使用正则表达式的findall 函数,找到所有单词,作为单词list,使用collections 的Counter去统计字典中的重复元素,得到如下代码:
###################################################################################
#Name:count_words
#Inputs:file name,the first n words, stopfile name
#outputs:None
#Author: Thomas
#Date:2018.10.22
###################################################################################
def CountWords(file_name,n,stopName,verbName):
print("File name:" + sys.path[0] + "\\" + file_name)
if (stopName != None):
stopflag = True
else:
stopflag = False
if(verbName != None):
verbflag = True
else:
verbflag = False
t0 = time.clock()
with open(file_name) as f:
txt = f.read()
txt = txt.lower()
if(stopflag == True):
with open(stopName) as f:
stoplist = f.readlines()
pattern = r"[a-z][a-z0-9]*"
wordList = re.findall(pattern,txt)
totalNum = len(wordList)
tempc = Counter(wordList)
if (stopflag == True):
for word in stoplist:
word = word.replace('\n','')
del tempc[word]
dicNum = dict(tempc.most_common(n))
if (verbflag == True):
totalNum = 0
verbDic = {}
verbDicNum = {}
with open(verbName) as f:
for line in f.readlines():
key,value = line.split(' -> ')
verbDic[key] = value.replace('\n','').split(',')
verbDicNum[key] = tempc[key]
for word in verbDic[key]:
verbDicNum[key] += tempc[word]
totalNum += verbDicNum[key]
verbDicNum = sorted(verbDicNum.items(), key=lambda k: k[0])
verbDicNum = sorted(verbDicNum, key=lambda k: k[1], reverse=True)
dicNum = sorted(dicNum.items(), key=lambda k:k[0])
dicNum = sorted(dicNum, key=lambda k:k[1], reverse=True)
t1 = time.clock()
if (verbflag == True):
display(verbDicNum[:n], 'words',totalNum,3)
else:
display(dicNum,'words',totalNum,3)
print("Time Consuming:%4f" % (t1 - t0))修改之后,依旧需要做单元测试和回归测试,这里避免重复就不写了,成功的将时间降到了0.34s可以说提高了非常多的数量级,优化到这里,基本上已经达到了优化的瓶颈,没法继续优化了。
Step-2:支持 stop words,我们可以做一个 stop word 文件 (停词表), 在统计词汇的时候,跳过这些词。
停词表就没有之前实现那样需要这么麻烦去优化性能了,因为这个功能是基于之前的已经优化好的函数做的,因此要做的只是单元测试与回归测试,首先先分析一下实现的方式,因为之前已经统计得到了每一个单词出现的次数,现在需要做的是读取stopword文件中的单词,将这个单词在字典中删去,就可以到达最终所需要的效果,因为统计的时候用的是Counter类型的,因此只需要遍历stopword然后在counter中删掉就好了,这样得到的代码就是:
if(stopflag == True):
with open(stopName) as f:
stoplist = f.readlines()
if (stopflag == True):
for word in stoplist:
word = word.replace('\n','')
del tempc[word]同样的,我们需要使用三个文本文件做单元测试,具体就是,一个空文件,一个小样本文件,和一个样本较多的文件,分别做验证,于是可以写单元测试的代码如下:
from count import CountWords
CountWords("Null.txt","Stopwords.txt")
CountWords("Test.txt","Stopwords.txt")
CountWords("gone_with_the_wind.txt","Stopwords.txt")其中:
- Null.txt 是一个空的文本文件
- gone_with_the_wind.txt 是《乱世佳人》的文本文件
- Test.txt 是一个我们自己指定的内容固定的文本文件,这样就可以统计结果的正确性
经过我们的验证,这个结果是正确的。保证了结果的正确性,经过这样的验证,但还不清楚代码的覆盖率怎么样,于是我们使用工具coverage,对代码进行分析,使用如下命令行分析代码覆盖率
coverage run test.py得到的结果如下:
Name Stmts Exec Cover
---------------------------------------------
CountWords 78 92 100%
---------------------------------------------
TOTAL 78 92 100%可以看到,在保证代码覆盖率为100%的时候,代码运行是正确的。因为代码做了修改,因此需要做回归测试,编写如下代码做回归测试:
from count import CountLetters
from count import CountWords
CountWords("Null.txt","Stopwords.txt")
CountWords("Test.txt","Stopwords.txt")
CountWords("gone_with_the_wind.txt","Stopwords.txt")
CountLetters("Null.txt","Stopwords.txt")
CountLetters("Test.txt","Stopwords.txt")
CountLetters("gone_with_the_wind.txt","Stopwords.txt")发现之前的counterletters不支持stopword的功能,于是我们又去修改了该函数,只不过那个函数没有用counter类型,因此为了达到stopword功能,需要从字典中删去改项,于是我们得到
if (stopflag == True):
with open(stopName) as f:
stoplist = f.readlines()
if (stopflag == True):
for word in stoplist:
word = word.replace('\n','')
try:
del tempc[word]
except:
pass经过单元测试,回归测试之后,结果正确。
Step-3:输出某个英文文本文件中 单词短语出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
首先的了解,短语的定义是什么:
短语:两个或多个英语单词, 它们之间只有空格分隔. 请看下面的例子:
hello world //这是一个短语
hello, world //这不是一个短语
这个会导致一个句子中有许多短语,举个例子:
I am not a good boy.
这个就有:I am, am not, not a, a good, good boy.
这就难倒了正则表达式,因为这样就不能用回溯功能,于是队友想到了办法,我们把文章先分为句子,再从句子中提出短语,用for循环去遍历一个句子,然后我们写出了下面的代码:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author: albert time:2018/10/23 0023
import time
import re
import string
from collections import Counter
start = time.time()
from string import punctuation # Temporarily useless
def NumWordFrequency(fileContent,number):
fileContent = re.sub('\n|\t',' ',fileContent)
mPunctuation = r',|;|\?|\!|\.|\:|\“|\"|\”'
sentenceList = re.split(mPunctuation , fileContent)#Divide the text into sentences according to the punctuation marks
wordsCounts = {} # Creates an empty dictionary used to calculate word frequency
for oneSentence in sentenceList:
wordsCounts = ProcessLine(oneSentence.lower(), wordsCounts,number) # Calculate the specified length phrase frequency
return wordsCounts
'''function:Calculate the word frequency of each line
input: line : a list contains a string for a row
countsDict: an empty dictionary
ouput: counts: a dictionary , keys are words and values are frequencies
data:2018/10/22
'''
def ProcessLine(sentence, countsDict,number):
# Replace the punctuation mark with a space
# line=ReplacePunctuations(line)
sentence = re.sub('[^a-z0-9]', ' ', sentence)
words = sentence.split()
if len(words) >= number:
for i in range(len(words)-number+1):
countsDict[" ".join(words[i:i+number])] = countsDict.get(" ".join(words[i:i+number]), 0) + 1
else:
if sentence.strip()=='': #Judge if the sentence is empty
return countsDict
countsDict[sentence] = countsDict.get(sentence, 0) + 1
return countsDict
'''function:Replace the punctuation mark with a space
input: line : A list containing a row of original strings
ouput: line: a list whose punctuation is all replaced with spaces
data:2018/10/22
'''
def ReplacePunctuations(line):
for ch in line:
# Create our own symbol list
tags = [',', '.', '?', '"', '“', '”', '—']
if ch in tags:
line = line.replace(ch, " ")
return line
'''function:Create a taboo "stopwords.txt"
input: line : A list contains all the words in the "Gone With The Wind.txt"
ouput: nono
data:2018/10/23
'''
def CreatStopWordsTxt(list):
file = open('stopwords.txt', 'w')
for str in list:
file.write(str + '\t')
file.close()
'''function:Remove any words that do not meet the requirements
input: dict : A dict whose keys are words and values are frequencies
ouput: dict : A removed undesirable words dict
data:2018/10/23
'''
def RemoveUndesirableWords(dict):
'''
wordsCount = 0 # Number of words
wordsCount = sum(dict.values())
'''
listKey = list(dict)
for temp in listKey:
if temp[0].isdigit():
del dict[temp]
#else:
# dict[temp] = round(dict[temp] , 4)
return dict
'''function:Remove the words from the "stopwords.txt"
input: dict : A list transformed by a dict whose keys are words and values are frequencies
ouput: dictProc : A list after removing stopwords
data:2018/10/23
'''
def StopWordProcessing(dict):
fileTabu = open("stopwords1.txt", 'r')
stopWordlist = fileTabu.read()
fileTabu.close()
stopWordlist = re.sub('[^a-z0-9]', ' ', stopWordlist).split(' ')
dictProc = dict.copy()
for temp in dict.keys():
if temp.strip() in stopWordlist:
del dictProc[temp]
return dictProc
class WordFinder(object):
'''A compound structure of dictionary and set to store word mapping'''
def __init__(self):
self.mainTable = {}
for char in string.ascii_lowercase:
self.mainTable[char] = {}
self.specialTable = {}
#print(self.mainTable)
for headword, related in lemmas.items():
# Only 3 occurrences of uppercase in lemmas.txt, which include 'I'
# Trading precision for simplicity
headword = headword.lower()
try:
related = related.lower()
except AttributeError:
related = None
if related:
for word in related.split():
if word[0] != headword[0]:
self.specialTable[headword] = set(related.split())
break
else:
self.mainTable[headword[0]][headword] = set(related.split())
else:
self.mainTable[headword[0]][headword] = None
#print(self.specialTable)
#print(self.mainTable)
def find_headword(self, word):
"""Search the 'table' and return the original form of a word"""
word = word.lower()
alphaTable = self.mainTable[word[0]]
if word in alphaTable:
return word
for headword, related in alphaTable.items():
if related and (word in related):
return headword
for headword, related in self.specialTable.items():
if word == headword:
return word
if word in related:
return headword
# This should never happen after the removal of words not in valid_words
# in Book.__init__()
return None
# TODO
def find_related(self, headword):
pass
def VerbTableFrequency(fileContent):
global lemmas
global allVerbWords
lemmas = {}
allVerbWords = set()
with open('verbs.txt') as fileVerb:
# print(fileVerb.read())
for line in fileVerb:
# print(line)
line = re.sub(r'\n|\s|\,', ' ', line)
headWord = line.split('->')[0]
# print(headWord)
# print(headWord)
try:
related = line.split('->')[1]
# print(related)
except IndexError:
related = None
lemmas[headWord] = related
allVerbWords = set()
for headWord, related in lemmas.items():
allVerbWords.add(headWord)
# print(allVerbWords)
# print("\t")
if related:
allVerbWords.update(set(related.split()))
# allVerbWords.update(related)
tempList = re.split(r'\b([a-zA-Z-]+)\b',fileContent)
tempList = [item for item in tempList if (item in allVerbWords)]
finder = WordFinder()
tempList = [finder.find_headword(item) for item in tempList]
cnt = Counter()
for word in tempList:
cnt[word] += 1
#print(type(cnt))
return cnt
def main():
with open("Gone With The Wind.txt") as file :
content = file.read().lower()
outCounts = 10 # Show the top count words that appear most frequently
number = 1 #Phrase length
flag = 1
if flag == 1:
verbFreCount = VerbTableFrequency(content)
#print(type(cnt))
wordsCounts ={}
for word in sorted(verbFreCount, key=lambda x: verbFreCount[x], reverse=True):
wordsCounts[word] = verbFreCount[word]
print(type(wordsCounts))
freCountNum = sum(wordsCounts.values())
#print (freCountNum )
for word, fre in list(wordsCounts.items())[0:outCounts]:
print("|\t{:15}|{:<11.2f}|".format(word,fre / freCountNum))
print("--------------------------------")
else:
wordsCounts = NumWordFrequency(content,number)
wordsCounts = RemoveUndesirableWords(wordsCounts) # Remove any words that do not meet the requirements
wordsCounts = StopWordProcessing(wordsCounts) # Remove the words from the "stopwords.txt"
pairsList = list(wordsCounts.items()) # Get the key-value pairsList from the dictionary
items = [[x, y] for (y, x) in pairsList] # key-value pairsList in the list exchange locations, data pairsList sort
items.sort(reverse=True)
# Notice we didn't order words of the same frequency
for i in range(outCounts):
print(items[i][1] + "\t" + str(items[i][0]))
if __name__ == '__main__':
main()
end = time.time()
print(end - start)同样的,我们需要使用三个文本文件做单元测试,具体就是,一个空文件,一个小样本文件,和一个样本较多的文件,分别做验证,于是可以写单元测试的代码如下:
from count import CountPhrase
CountPhrase("Null.txt",2)
CountPhrase("Test.txt",2)
CountPhrase("gone_with_the_wind.txt",2)
CountPhrase("Null.txt",2,"Stopwords.txt")
CountPhrase("Test.txt",2,"Stopwords.txt")
CountPhrase("gone_with_the_wind.txt",2,"Stopwords.txt")其中:
- Null.txt 是一个空的文本文件
- gone_with_the_wind.txt 是《乱世佳人》的文本文件
- Test.txt 是一个我们自己指定的内容固定的文本文件,这样就可以统计结果的正确性
经过我们的验证,这个结果是正确的。保证了结果的正确性,经过这样的验证,但还不清楚代码的覆盖率怎么样,于是我们使用工具coverage,对代码进行分析,使用如下命令行分析代码覆盖率
coverage run test.py得到的结果如下:
Name Stmts Exec Cover
---------------------------------------------
CountPhrase 78 92 100%
---------------------------------------------
TOTAL 78 92 100%可以看到,在保证代码覆盖率为100%的时候,代码运行是正确的。因为代码做了修改,因此需要做回归测试,编写如下代码做回归测试:
from count import CountLetters
from count import CountWords
from count import CountPhrase
CountWords("Null.txt","Stopwords.txt")
CountWords("Test.txt","Stopwords.txt")
CountWords("gone_with_the_wind.txt","Stopwords.txt")
CountLetters("Null.txt","Stopwords.txt")
CountLetters("Test.txt","Stopwords.txt")
CountLetters("gone_with_the_wind.txt","Stopwords.txt")
CountPhrase("Null.txt",2)
CountPhrase("Test.txt",2)
CountPhrase("gone_with_the_wind.txt",2)
CountPhrase("Null.txt",2,"Stopwords.txt")
CountPhrase("Test.txt",2,"Stopwords.txt")
CountPhrase("gone_with_the_wind.txt",2,"Stopwords.txt")发现之前的counterPhrases不支持stopword的功能,于是我们又去修改了该函数,思想和CountWords函数相同。
经过单元测试,回归测试之后,结果正确。
但程序的运行速度怎么样呢?为了更加了解清楚它的运行速度,我们使用cprofile分析性能,从而提升运行的性能, 使用cprofile运行的结果为,一共用了2.39s,为了降低时间成本。
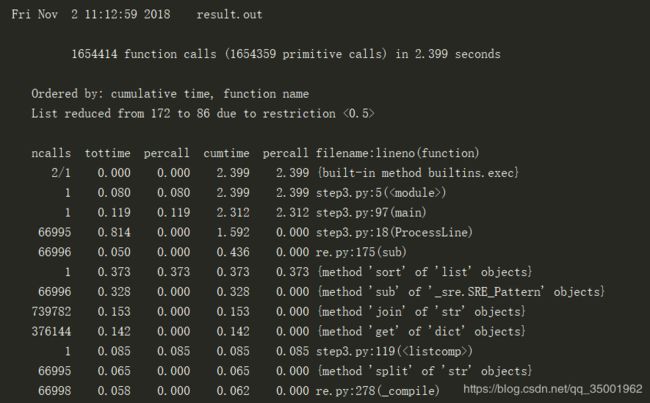
因此需要对其进行优化,我们想到一个绝妙的办法,可以将文章看作一个巨大的句子,用句号对文中的句子进行分割,然后,用正则表达式匹配第一次,这一次就会漏掉一些,但是我们删去一个词再去用正则表达式,就可以统计到缺失的那部分,同样的,一直替换到删去n-1个词语,就得到最终版本的代码:
###################################################################################
#Name:count_words
#Inputs:file name,the first n words, stopfile name
#outputs:None
#Author: Thomas
#Date:2018.10.22
###################################################################################
def CountPhrases(file_name,n,stopName,verbName,k):
print("File name:" + sys.path[0] + "\\" + file_name)
totalNum = 0
if (stopName != None):
stopflag = True
else:
stopflag = False
if(verbName != None):
verbflag = True
else:
verbflag = False
t0 = time.clock()
with open(file_name) as f:
txt = f.read()
txt = txt.lower()
txt = re.sub(r'[\s|\']+',' ',txt)
pword = r'(([a-z]+ )+[a-z]+)' # extract sentence
pattern = re.compile(pword)
sentence = pattern.findall(txt)
txt = ','.join([sentence[m][0] for m in range(len(sentence))])
if(stopflag == True):
with open(stopName) as f:
stoplist = f.readlines()
pattern = "[a-z]+[0-9]*"
for i in range(k-1):
pattern += "[\s|,][a-z]+[0-9]*"
wordList = []
for i in range(k):
if( i == 0 ):
tempList = re.findall(pattern, txt)
else:
wordpattern = "[a-z]+[0-9]*"
txt = re.sub(wordpattern, '', txt, 1).strip()
tempList = re.findall(pattern, txt)
wordList += tempList
tempc = Counter(wordList)
if (stopflag == True):
for word in stoplist:
word = word.replace('\n','')
del tempc[word]
dicNum = {}
if (verbflag == True):
verbDic = {}
with open(verbName) as f:
for line in f.readlines():
key,value = line.split(' -> ')
for tverb in value.replace('\n', '').split(','):
verbDic[tverb] = key
verbDic[key] = key
for phrase in tempc.keys():
if (',' not in phrase):
totalNum += 1
verbList = phrase.split(' ')
normPhrase = verbList[0]
for verb in verbList[1:]:
if verb in verbDic.keys():
verb = verbDic[verb]
normPhrase += ' ' + verb
if (normPhrase in dicNum.keys()):
dicNum[normPhrase] += tempc[phrase]
else:
dicNum[normPhrase] = tempc[phrase]
else:
phrases = tempc.keys()
for phrase in phrases:
if (',' not in phrase):
dicNum[phrase] = tempc[phrase]
totalNum += tempc[phrase]
dicNum = sorted(dicNum.items(), key=lambda k: k[0])
dicNum = sorted(dicNum, key=lambda k: k[1], reverse=True)
t1 = time.clock()
display(dicNum[:n], 'Phrases',totalNum,3)
print("Time Consuming:%4f" % (t1 - t0))经过运行上面的单元测试,回归测试的代码,发现运行结果没有变化,时间降到了1.8s,已经达到优化的最终目的了。
Step-4:第四步:把动词形态都统一之后再计数。
首先,我们需要看一下动词形态在Verbs.txt中是什么样子的
abandon -> abandons,abandoning,abandoned
abase -> abases,abasing,abased
abate -> abates,abating,abated
abbreviate -> abbreviates,abbreviating,abbreviated
abdicate -> abdicates,abdicating,abdicated
abduct -> abducts,abducting,abducted
abet -> abets,abetting,abetted
abhor -> abhors,abhorring,abhorred
可以看到左边是动词原形,右边是动词的各种形式,因为目前已经对单词全部统计出来了,所以现在需要做的是,首先将verbs.txt读入字典当中,用这个字典将相同词语不同形式的加到一起,于是可以编写代码如下:
if (verbflag == True):
totalNum = 0
verbDic = {}
verbDicNum = {}
with open(verbName) as f:
for line in f.readlines():
key,value = line.split(' -> ')
verbDic[key] = value.replace('\n','').split(',')
verbDicNum[key] = tempc[key]
for word in verbDic[key]:
verbDicNum[key] += tempc[word]
totalNum += verbDicNum[key]同样的,我们需要使用三个文本文件做单元测试,具体就是,一个空文件,一个小样本文件,和一个样本较多的文件,分别做验证,于是可以写单元测试的代码如下:
from count import CountWords,CountPhrases
CountWords("Null.txt","Verbs.txt")
CountWords("Test.txt","Verbs.txt")
CountWords("gone_with_the_wind.txt","Verbs.txt")
CountWords("Null.txt","Verbs.txt","Verbs.txt","stopwords.txt")
CountWords("Test.txt","Verbs.txt","Verbs.txt","stopwords.txt")
CountWords("gone_with_the_wind.txt","Verbs.txt","stopwords.txt")
CountWords("Null.txt","Verbs.txt")
CountWords("Test.txt","Verbs.txt")
CountWords("gone_with_the_wind.txt","Verbs.txt")
CountWords("Null.txt","Verbs.txt","Verbs.txt""stopphrases.txt")
CountWords("Test.txt","Verbs.txt","Verbs.txt""stopphrases.txt")
CountWords("gone_with_the_wind.txt","Verbs.txt","stopphrases.txt")其中:
- Null.txt 是一个空的文本文件
- gone_with_the_wind.txt 是《乱世佳人》的文本文件
- Test.txt 是一个我们自己指定的内容固定的文本文件,这样就可以统计结果的正确性
对于单词来说经过我们的验证,这个结果是正确的。但发现短语不支持verbs.txt的功能,于是我们对短语的功能进行了修改,但是怎么归一化呢,想到了一个绝妙的办法,就是各种形式作为key,对应值作为value,这样的话索引各种形式都可以变换到原型,然后就有了如下的代码:
if (verbflag == True):
verbDic = {}
with open(verbName) as f:
for line in f.readlines():
key,value = line.split(' -> ')
for tverb in value.replace('\n', '').split(','):
verbDic[tverb] = key
verbDic[key] = key
for phrase in tempc.keys():
if (',' not in phrase):
totalNum += 1
verbList = phrase.split(' ')
normPhrase = verbList[0]
for verb in verbList[1:]:
if verb in verbDic.keys():
verb = verbDic[verb]
normPhrase += ' ' + verb
if (normPhrase in dicNum.keys()):
dicNum[normPhrase] += tempc[phrase]
else:
dicNum[normPhrase] = tempc[phrase]经过这样的验证,但还不清楚代码的覆盖率怎么样,于是我们使用工具coverage,对代码进行分析,使用如下命令行分析代码覆盖率
coverage run test.py得到的结果如下:
Name Stmts Exec Cover
---------------------------------------------
CountWords 78 92 100%
---------------------------------------------
TOTAL 78 92 100%可以看到,在保证代码覆盖率为100%的时候,代码运行是正确的。因为代码做了修改,因此需要做回归测试,编写如下代码做回归测试:
from count import CountLetters
from count import CountWords
CountWords("Null.txt","Verbs.txt")
CountWords("Test.txt","Verbs.txt")
CountWords("gone_with_the_wind.txt","Verbs.txt")
CountWords("Null.txt","Verbs.txt","stopwords.txt")
CountWords("Test.txt","Verbs.txt","stopwords.txt")
CountWords("gone_with_the_wind.txt","Verbs.txt","stopwords.txt")
CountWords("Null.txt")
CountWords("Test.txt")
CountWords("gone_with_the_wind.txt")
CountLetters("Null.txt","Verbs.txt","Stopwords.txt")
CountLetters("Test.txt","Verbs.txt","Stopwords.txt")
CountLetters("gone_with_the_wind.txt","Verbs.txt","Stopwords.txt")
CountLetters("Null.txt","Stopwords.txt")
CountLetters("Test.txt","Stopwords.txt")
CountLetters("gone_with_the_wind.txt","Stopwords.txt")
CountLetters("Null.txt")
CountLetters("Test.txt")
CountLetters("gone_with_the_wind.txt")发现之前的counterletters不支持verbs.txt的功能,于是我们又去修改了该函数,但后来觉得归一化单词去统计字母的出现次数是没有意义的,于是便删去了原先代码。
Step-5:第五步:统计动介短语的次数。
首先先看一下动介短语的定义是什么:
VerbPhrase := Verb + Spaces + Preposition Spaces := Space+ Space := ' ' | '\t' | '\r' | '\n' Preposition := Verb := 一开始并没有想到第5步与第4步有紧密的联系,因此我们这步的代码是从头开始写的,构造了一个非常长的正则表达式,主要就是用for循环将词语用或连起来,因为这样的用时太长了,一共花了56s,可以说根本没法用,因此直接就摒弃了这种方式,也没有做单元测试性能分析,因为时间太长了,肯定需要重新想的。后来想起来第4步不是统计了所有的短语嘛,我们可以将统计的短语拿过来使用,只要归一化再加上判断介词就可以用了。但是怎么归一化呢,想到了一个绝妙的办法,就是各种形式作为key,对应值作为value,这样的话索引各种形式都可以变换到原型,这样得到最终的代码:
###################################################################################
#Name:count_words
#Inputs:file name,the first n words, stopfile name
#outputs:None
#Author: Thomas
#Date:2018.10.22
###################################################################################
def CountVerbPre(file_name,n,stopName,verbName,preName):
print("File name:" + sys.path[0] + "\\" + file_name)
dicNum = {}
totalNum = 0
if (stopName != None):
stopflag = True
else:
stopflag = False
t0 = time.clock()
with open(file_name) as f:
txt = f.read()
txt = txt.lower()
txt = re.sub(r'[\s|\']+',' ',txt)
pword = r'(([a-z]+ )+[a-z]+)' # extract sentence
pattern = re.compile(pword)
sentence = pattern.findall(txt)
txt = ','.join([sentence[m][0] for m in range(len(sentence))])
if(stopflag == True):
with open(stopName) as f:
stoplist = f.readlines()
pattern = "[a-z]+[0-9]*"
for i in range(1):
pattern += "[\s|,][a-z]+[0-9]*"
wordList = []
for i in range(2):
if( i == 0 ):
tempList = re.findall(pattern, txt)
else:
wordpattern = "[a-z]+[0-9]*"
txt = re.sub(wordpattern, '', txt, 1).strip()
tempList = re.findall(pattern, txt)
wordList += tempList
tempc = Counter(wordList)
with open(preName) as f:
preTxt = f.read()
preList = preTxt.split('\n')
verbDic = {}
with open(verbName) as f:
for line in f.readlines():
key,value = line.split(' -> ')
for tverb in value.replace('\n','').split(','):
verbDic[tverb] = key
verbDic[key] = key
for phrase in tempc.keys():
if(',' not in phrase):
totalNum += 1
verb, pre = phrase.split(' ')
if (verb in verbDic.keys() and pre in preList):
normPhrase = verbDic[verb] + ' ' + pre
if (normPhrase in dicNum.keys()):
dicNum[normPhrase] += tempc[phrase]
else:
dicNum[normPhrase] = tempc[phrase]
if (stopflag == True):
for word in stoplist:
word = word.replace('\n','')
del dicNum[word]
dicNum = sorted(dicNum.items(), key=lambda k: k[0])
dicNum = sorted(dicNum, key=lambda k: k[1], reverse=True)
t1 = time.clock()
display(dicNum[:n], 'VerbPre',totalNum, 3)
print("Time Consuming:%4f"%(t1-t0))经过单元测试,回归测试结果正确。但限于篇幅,这里就不赘述了。