百度点石-人工智能农作物识别比赛总结
(初赛排名第8,虽然成绩较差,但觉得参与其中,收获颇丰,借此分享一下,欢迎交流)
![]()
1.背景介绍
本次竞赛目的是对某一时刻一张遥感卫星多光谱影像进行分类,需识别为4种类别:玉米、大豆、水稻和其他(背景)。提供的多光谱影像,如图1所示(1,2,3波段合成的影像),覆盖850公里*300公里,8个波段。此外影像中含有较大面积的厚云、薄云、云影的部分,其中通过阈值的方法,厚云的部分占总面积的近8%,特别是右下角尤为显著。
数据标记提供:标注的样本点数据,给定玉米、大豆和水稻3个类别农作物对应区块的中心点像素位置(x,y)列表,以及对应中心点对应的区块半径3。
本次竞赛要求:利用深度学习等智能算法自动识别出所给图像对应的类别,并依据识别准确度和时效性进行评价。
图1 多光谱影像(其中1,2,3波段合成)
2.预处理
深度学习方法处理的数据是图像块或栅格数据或数值的特点,本次竞赛提供的标记是点坐标和半径,据此,我们需要制作栅格数据作为训练样本库,以训练我们使用的深度学习模型。
2.1 数据特征
提供的多光谱数据解压后,通过ENVI软件转为栅格影像后大小为13.3G。标记数据以坐标和半径的格式提供了2,372个点,只含大豆、水稻、玉米三种类别的数据点,如图2所示。根据深度学习算法使用数据的特点,我们将以每个点为中心,开一个窗口大小为7*7的影像块,并记录其所属类别值。以此建立基本的样本库。

图2 标记数据点的分布
在训练深度学习网络时,我们一般都使用较大的数据量来训练,以充分学习每类样本的各种丰富特征。另一个值得注意的点是:本次竞赛提供的样本点不包括其他类别(背景),这里我们通过对已有样本的分析,以及对原始影像的使用,以此来生成背景样本。同时基于本竞赛提供的仅有2,732个样本点,我们采用一定的策略进行数据增强,扩充样本量到40,000个样本。
2.2 数据增强
2.2.1 生成背景点
通过对提供的2,732个样本点生成的7*7影像块的特征进行分析,以生成背景样本。思路:已知数据的整体分布特点(原始影像),以及其中三种类别(大豆、水稻、玉米),要获取剩下的一种类别(背景)的数据特点,则只需进行一个减法即可。
表1 BMD分布
![]()
具体地,针对获取的2,732个7*7的8通道的影像块,计算每个影像块8个通道的平均值,以获得每一个通道的均值分布,记为BMD(Band mean distribution,BMD)分布,如表1所示。显然,某个7*7的影像块,8个通道的均值落在该BMD分布里,则该影像块属于农作物类别(属于大豆、水稻、玉米中的一种)。若不满足要求,则为背景类。这里为更好地获取背景类的样本点,加入一个约束指标,满足至少两个通道不在该范围内,则为背景样本。同时为更好符合数据的真实性,我们从原始影像中随机生成一个7*7窗口的影像块,进行实验,生成的样本量达20,000个。

图3 部分背景点显示(红色标记)
2.2.2 农作物样本点
为更好地训练深度学习网络,需对农作物样本(大豆、水稻、玉米)进行数据增强。

图4 农作物样本增强部分显示(浅色调)
思路:在提供的2,732个样本点附近,随机生成一个点,并开一个7*7窗口大小的影像块,并计算该影像块的8个波段的均值是否在当前选取点(2,732个中的某一个)对应的影像块的8波段均值加减一个阈值p的范围内。这里给定三个约束;阈值p通过试验设置为50;满足至少5个波段以上的均值在该范围内;随机点在以2,732个样本点(参考样本点)的半径为21范围内,按离参考样本点的距离生成样本点的概率依次减小。如此进行数据增强,包括原始的2732个在内,共有20,000个样本点。
2.3 建立训练样本库
根据2.2节介绍的内容,我们以此建立深度学习网络所需的训练样本库。我们设置训练集与验证集的比例为4:1,在训练的过程中,通过大样本的验证集以获取最优的训练模型。
3.网络架构
在不断试验中,我们最终提出了一种多特征增强网络模型(Multi-feature augmentation network,MFAN),其性能稳健,基于网络传输中数据存在利用不充分的问题,以及针对本竞赛利用像素信息(几乎没有涉及样本的纹理、形状、大小等特征信息)进行分类的特点进行设计。
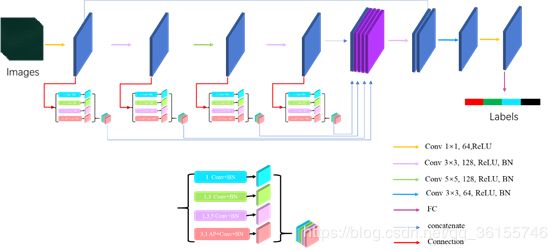
图5 MFAN网络架构
4.训练测试
4.1 训练过程
为了使训练的时间更快,我们在制作训练样本库时,将制作的样本数据以Numpy的数据格式、扩展名为.npy进行保存。
实验在GTX1080Ti,以Keras作为深度学习框架进行,我们使用的损失函数为多分类交叉熵损失函数,使用Adam优化器对网络参数进行更新,学习率为1e-4,batch_size大小设为128,epoch设为300个。训练用时50分钟左右。
在基本的设置完成后,并开始进行训练。在测试阶段,一般(以训练的经验)第220个epoch左右的训练模型进行测试完整的影像。
4.2 测试技巧
在测试时,顾及测试的时效以及测试精度,我们将3*3大小影像区域视为同一种地物。同时我们训练的样本块大小为7*7,所以在测试时,我们使用的影像块大小同样为7*7,例如在开始对影像进行测试时,我们读取影像的第1到第7行,所有的列,再依次分为7*7的影像块,并放入训练模型中进行测试。这样涉及一定的数据重叠,以及边缘无值得情况。这里主要考虑边缘填充的情况,显然这里使用就近填充的原则,进行填充。
在测试得到完整的影像后,根据第1章背景介绍,厚云所占的比重达8%左右,在一些较大面积的厚云区域,无法获取厚云下到底是什么的情况下,这里对厚云区域进行默认填充,默认值为60。除此之外,使用MFAN模型测试后的结果没有进行任何后处理。测试用时1.5小时左右。
4.3 可视化测试结果


5.竞赛总结
通过本次竞赛主要有三点值得很好总结的经验:
- 充分利用提供的数据,进行各种数据增强,这样能很大程度上提升模型的泛化能力。
- 在深度学习网络设计中,要针对特定的问题进行设计,这样更好地有利于提取分割目标的特征,便于高精度的分类。
- 目前,深度学习的方法依然是依据概率统计的思想,如没能提供大量的训练样本时,很难达到较好结果,甚至很有可能差于传统的方法。针对本次竞赛,我们并没有用一些数字图像处理方法进行后处理,在实际应用中,结合一些后处理方法,可能有更好的表现。