(一)架构篇之架构概况总览
1、总体架构
总结
1)接入层架构要考虑的问题域为:高可用、扩展性、反向代理+扩展均衡
2)nginx、keepalived、lvs、f5可以很好的解决高可用、扩展性、反向代理+扩展均衡的问题
3)水平扩展scale out是解决扩展性问题的根本方案,DNS轮询是不能完全被nginx/lvs/f5所替代的
最重要的一点就是服务不能宕机,宕机可以立马恢复。
可根据实际情况来采用以下三种策略--都是可实用的。
(1)基础高可用--nginx&keepalived 保活策略

缺点:
1)资源利用率只有50%
2)nginx仍然是接入单点,如果接入吞吐量超过的nginx的性能上限怎么办,例如qps达到了50000咧?
(2)scale up扩容方案lvs/f5

这就完美了嘛?还有潜在问题么?
好吧,不管是使用lvs还是f5,这些都是scale up的方案,根本上,lvs/f5还是会有性能上限,假设每秒能处理10w的请求,一天也只能处理80亿的请求(10w秒吞吐量*8w秒),那万一系统的日PV超过80亿怎么办呢?(好吧,没几个公司要考虑这个问题)
(3)scale out扩容方案 DNS轮询

此时:
1)通过DNS轮询来线性扩展入口lvs层的性能
2)通过keepalived来保证高可用
3)通过lvs来扩展多个nginx
4)通过nginx来做负载均衡,业务七层路由
2、容量估算
(1)机器能抗住么?
(2)如果扛不住,需要加多少台机器?
互联网架构设计如何进行容量评估:
【步骤一:评估总访问量】
->询问业务、产品、运营
【步骤二:评估平均访问量QPS】
->除以时间,一天算4w秒
提问:为什么一天按照4w秒计算?
回答:一天共24小时*60分钟*60秒=8w秒,一般假设所有请求都发生在白天,所以一般来说一天只按照4w秒评估
【步骤三:评估高峰QPS】
->根据业务曲线图来--对比平均和最高峰
【步骤四:评估系统、单机极限QPS】
->压测很重要
【步骤五:根据线上冗余度回答两个问题】
-> 估计冗余度与线上冗余度差值
3、线程数设置
计算时间占用cpu,等待时间为发出请求等待服务器相应的时间。
N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,则工作线程数(线程池线程数)设置为 N*(x+y)/x,能让CPU的利用率最大化。
4、负载均衡
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。
(1)【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的
(2)【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的
(3)【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的
(4)【数据层】的负载均衡,要考虑“数据的均衡”与“请求的均衡”两个点,常见的方式有“按照范围水平切分”与“hash水平切分”
5、过载保护
达到处理能力80%应当对请求进行处理
(1)简单粗暴的方式也是最本质的方式:对于过多地请求抛弃--“请求超时,请稍后再试”
(2)对于异构架构(能力不同的服务器):采取权重的方式进行过载保护--即某台服务器多次出现超时可根据服务器能力不让请求到达。
应该实施一些什么样的策略呢,例如:
1)如果某一个service的连接上,连续3个请求都超时,即连续-10分三次,客户端就可以认为,服务器慢慢的要处理不过来了,得给这个service缓一小口气,于是设定策略:接下来的若干时间内,例如1秒(或者接下来的若干个请求),请求不再分配给这个service;
2)如果某一个service的动态权重,降为了0(像连续10个请求超时,中间休息了3次还超时),客户端就可以认为,服务器完全处理不过来了,得给这个service喘一大口气,于是设定策略:接下来的若干时间内,例如1分钟(为什么是1分钟,根据经验,此时service一般在发生fullGC,差不多1分钟能回过神来),请求不再分配给这个service;
3)可以有更复杂的保护策略…
6、高并发
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
7、高可用
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过冗余+自动故障转移来实现的。
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
(1)【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
(2)【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
(3)【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
(4)【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
(5)【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
(6)【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
8、数据库架构设计
1)架构设计
•业务初期用单库
•读压力大,读高可用,用分组 -- 一主多从,读写分离
•数据量大,写线性扩容,用分片 -- 建议分库,而不是分表
•属性短,访问频度高的属性,垂直拆分到一起
•最强方案:分组+分片
分组保证高可用,分片保证数据无忧。
2)需要考虑的问题:
(1)缓存与数据库读写顺序:都是缓存为先
(2)主从数据库的同步问题-从库会有一点点延迟(主流方案:双主)
(3)缓存与主从库一致性问题
3)数据库拆分
8.3.1 垂直拆分-将表中字段拆开
流量大,数据量大时,数据访问要有service层,并且service层不要通过join来获取主表和扩展表的属性
垂直拆分的依据,尽量把长度较短,访问频率较高的属性放在主表里
8.3.2水平拆分--按范围或者hash取模来进行拆分
可解决数据库容量瓶颈
4)拆分后分库分表---解决分片事务性
主流的分布式事务解决方案有三种:https://dbaplus.cn/news-141-2017-1.html
两阶段提交协议:不利于水平扩展,相应慢
最大努力保证模式:出错回滚,性能不好
事务补偿机制:在一定时间窗口内,通过补偿和重试(最优)
9、反向依赖与解耦
常见反向依赖及优化方案?
(1)公共库导致耦合
优化一:如果公共库是业务特性代码,进行公共库垂直拆分
优化二:如果公共库是业务共性代码,进行服务化下沉抽象
(2)服务化不彻底导致耦合
特征:服务中包含大量“根据不同业务,执行不同个性分支”的代码
优化方案:个性代码放到业务层实现,将服务化更彻底更纯粹
(3)notify的不合理实现导致的耦合
特征:调用方不关注执行结果,以调用的方式去实现通知,新增订阅者,修改代码的是发布者
优化方案:通过MQ解耦
(4)配置中的ip导致上下游耦合
特征:多个上游需要修改配置重启
优化方案:使用内网域名替代内网ip,通过“修改DNS指向,统一切断旧连接”的方式来上游无感切换
(5)下游扩容导致上下游耦合
特性:多个上游需要修改配置重启
10、线上数据库操作权限严格管理
避免误操作引发危机
是不是经常有这类误操作?
(1)本来只想update一条记录,where条件搞错,update了全部的记录
(2)本来只想delete几行记录,结果删多了,四下无人,再insert回去
(3)以为drop的是测试库,结果把线上库drop掉了
(4)以为操作的是分库x,结果SecureCRT开窗口太多,操作成了分库y
(5)写错配置文件,压力测试压到线上库了,生成了N多脏数据
11、微服务化
1、微的粒度:降低服务之间的耦合性,以业务为单位进行拆分服务比较合适
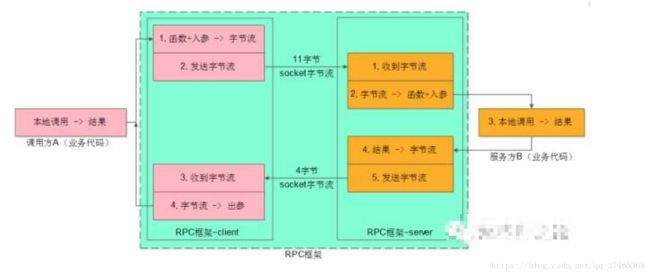
2、RPC框架:解决了调用方与服务方之间数据传递的问题,打通不同语言的限制。
通过protobuf提供统一的接口,通过grpc编译成不同的语言支持,可供多语言平台使用。
如:后端使用java,前端web,ios,android,分别可以直接编译使用接口。