Python中Requests库学习笔记
Requests: HTTP for Humans
让HTTP服务于人类
为什么使用requests库。
相比较urllib,比如处理网页认证和Cookies时,需要写Openner和Handler来处理。为了更加方便的实现这些操作。
安装
pip install requests
验证安装

没有报错就已经证明安装成功
基本用法
- 简单实例
使用requests中的get方法得到一个Response对象,然后分别输出Response的类型,状态码,响应体的类型,内容以及Cookies
import requests
r = requests.get("https://www.baidu.com") #使用get方法模拟浏览器请求发起过程
print(type(r))
print(r.status_code)
print(type(t.text)
print(r.text)
print(r.cookies)运行结果如下:
<class 'requests.models.Response'>
200
<class 'str'>
<html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“title>head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus>span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus>span> form> div> div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录a> noscript> <script>document.write('encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录');
script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å“a> div> div> div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度a> <a href=http://ir.baidu.com>About Baidua> p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度å‰å¿…读a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> p> div> div> div> body> html>
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
{kind=link}
它的返回类型是:requests.models.Response
响应体的类型是:str
Cookies的类型是:RequestsCookieJar
requests的其他请求类型(一句话实现)
r = requests.post("http://httpbin.org/post")
r = requests.put("http://httpbin.org/put")
r = requests.delete("http://httpbin.org/delete")
r = requests.head("http://httpbin.org/head")
r = requests.options("http://httpbin.org/options")
2.GET请求
请求时附加格外信息(params)
例:加入name:germey、age:22两个参数
import requests
data = {
'name' : 'germey',
'age' : '22'
}
r = requests.get("https://httpbin.org/get",params=data)
print(r.text)运行结果如下
{
"args": {
"age": "22",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"origin": "59.51.114.211",
"url": "https://httpbin.org/get?name=germey&age=22"
}这里请求链接自动被构成了:https://httpbin.org/get?name=germey&age=22
网页的返回类型实际上是str类型,但是它很特殊,是JSON格式的。
字典格式得到方式:
print(r.json)- 抓取二进制数据
import requests
r = requests.get("https://github.com/favicon.ico")
print(r.text)
print(r.content)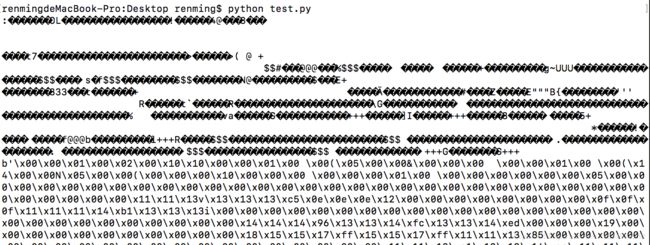
前者由于图片是二级制数据,所以打印时转化为str类型,也就是把图片直接转化为字符串,所以出现乱码。
- 添加headers
headers = {
'User-Agent' : 'xxxxxxx'
}
r = requests.get(url,headers=headers)3.POST请求
简单实例
import requests
data = {'name' : 'germey' ,'age' : '22'}
r = requests.post("http://httpbin.org/post",data = data)
print(r.text)结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "22",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "59.51.114.216",
"url": "http://httpbin.org/post"
}其中form部分就是提交的数据。
4.响应
得到响应的方法
import requests
r = requests.get("http://www.jianshu.com")
status_coder.status_code # 状态码
headers = r.headers # 响应头
cookies = r.cookies # Cookies
url = r.url # URL
hsitory = r.history # 请求历史headers得到的结果类型:CaseInsensitiveDict
cookies得到的结果类型:RequestsCookieJar
requests提供了一个内置的状态码查询对象:requests.codes
import requests
r = requests.get("http://www.jianshu.com")
exit() if not r.status_code == requests.codes.ok else print("Request Successfully")状态码解释:
HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码。它由 RFC 2616 规范定义的,并得到RFC 2518、RFC 2817、RFC 2295、RFC 2774、RFC 4918等规范扩展。
所有状态码的第一个数字代表了响应的五种状态之一。
100系列码
从100到199范围的HTTP状态码是信息报告码。基于各种原因考虑,大多数情况下我们 是很少看见这些代码的。首先,如果一个浏览器尝试访问一个网站,而网站返回这些代码时,它们往往都不会显示在屏幕上。它们只是浏览器使引用的内部码。另 外,这些代码不常见的另外一个原因是起初HTTP标准不允许使用这一范围的状态码。就其本身而言,它们也一直没有被广泛地使用。
200系列码
从200到299范围的状态码是操作成功代码。同样的,在正常的Web上网中,你也很可能不曾在屏幕上看到这些代码。相反的,这些代码是在浏览器内部使用的,用以确认操作成功确认和当前请求状态。虽然这些代码通常不显示,但是有一些故障排除工具能够读到它们,就像和其它大多数的HTTP状态码一样,它们在错误诊断过程中是非常有用的。
300系列码
从300到399范围的状态码是重定向代码。本质上,它们告诉Web浏览器必须执行其它一些操作以完成请求。基于这个命令的特点,它可以自动地执行,或者要求额外的用户输入。比如,状态码301表示一个特定资源已经被永久地先移除,因此将来所有访问该资源请求都应该定向到一个特定的URL上。
400系列码
在400范围的状态码是客户端错误码。这种类型的错误码往往跟安全相关。比如,如果一个客户端尝试访问一个未授权访问的资源,服务器就会返回一个状态码401。类似地,如果客户端尝试访问一个禁止的资源,在这种情况下客户端的认证状态是一样的,那么服务器可能会返回一个状态码403,表示禁止对该资源进行访问。
如果请求不正确或客户端超时,400级错误码也可能被返回。然而,有一个400级的代码总是具有误导性:404。虽然这个代码在技术上被归类为客户端错误,但是事实上它可以同时表示客户端或服务器上的错误。但这个错误码只是简单地显示为没有找到请求的资源。当这个错误发生在客户端时,它往往表示的是网络连接问题。在其他时候,这个错误的发生还可能是由于资源已从服务器上转移或重命名而造成的。
500系列码
500级状态码表示的是服务器错误。比如,如果Web服务器超时,它就会产生一个504错误。虽然,一个500级的错误往往表示的不是服务器的问题,而是在服务器上运行的Web应用的问题。比如,我自己的个人网站是用ASP编写的,它负责动态生成HTML网页。在调试的过程中,有Bug的代码总会导致我的Web服务器返回HTTP状态码500,该代码是一般表示内部服务器错误。这个代码只是出 现问题了,并且HTTP无法解决该问题。
1xx – 信息提示
- “100″:Continue
- “101″:witchingProtocols
2xx – 成功
- “200″:OK
- “201″:Created
- “202″:Accepted
- “203″:Non-AuthoritativeInformation
- “204″:NoContent
- “205″:ResetContent
- “206″:PartialContent
3xx – 重定向
- “300″:MultipleChoices
- “301″:MovedPermanently
- “302″:Found
- “303″:SeeOther
- “304″:NotModified
- “305″:UseProxy
- “307″:TemporaryRedirect
4xx – 客户端错误
- “400″:BadRequest
- “401″:Unauthorized
- “402″:PaymentRequired
- “403″:Forbidden
- “404″:NotFound
- “405″:MethodNotAllowed
- “406″:NotAcceptable
- “407″:ProxyAuthenticationRequired
- “408″:RequestTime-out
- “409″:Conflict
- “410″:Gone
- “411″:LengthRequired
- “412″:PreconditionFailed
- “413″:RequestEntityTooLarge
- “414″:Request-URITooLarge
- “415″:UnsupportedMediaType
- “416″:Requestedrangenotsatisfiable
- “417″:ExpectationFailed
5xx – 服务器错误
- “500″:InternalServerError
- “501″:NotImplemented
- “502″:BadGateway
- “503″:ServiceUnavailable
- “504″:GatewayTime-out
- “505″:HTTPVersionnotsupported
| 状态代码 | 状态信息 | 含义 |
| 100 | Continue | 初始的请求已经接受,客户应当继续发送请求的其余部分。(HTTP 1.1新) |
| 101 | Switching Protocols | 服务器将遵从客户的请求转换到另外一种协议(HTTP 1.1新) |
| 200 | OK | 一切正常,对GET和POST请求的应答文档跟在后面。 |
| 201 | Created | 服务器已经创建了文档,Location头给出了它的URL。 |
| 202 | Accepted | 已经接受请求,但处理尚未完成。 |
| 203 | Non-Authoritative Information | 文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝(HTTP 1.1新)。 |
| 204 | No Content | 没有新文档,浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的。 |
| 205 | Reset Content | 没有新的内容,但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容(HTTP 1.1新)。 |
| 206 | Partial Content | 客户发送了一个带有Range头的GET请求,服务器完成了它(HTTP 1.1新)。 |
| 300 | Multiple Choices | 客户请求的文档可以在多个位置找到,这些位置已经在返回的文档内列出。如果服务器要提出优先选择,则应该在Location应答头指明。 |
| 301 | Moved Permanently | 客户请求的文档在其他地方,新的URL在Location头中给出,浏览器应该自动地访问新的URL。 |
| 302 | Found | 类似于301,但新的URL应该被视为临时性的替代,而不是永久性的。注意,在HTTP1.0中对应的状态信息是“Moved Temporatily”。出现该状态代码时,浏览器能够自动访问新的URL,因此它是一个很有用的状态代码。注意这个状态代码有时候可以和301替换使用。例如,如果浏览器错误地请求HTTP://host/~user(缺少了后面的斜杠),有的服务器 返回301,有的则返回302。 严格地说,我们只能假定只有当原来的请求是GET时浏览器才会自动重定向。请参见307。 |
| 303 | See Other | 类似于301/302,不同之处在于,如果原来的请求是POST,Location头指定的重定向目标文档应该通过GET提取(HTTP 1.1新)。 |
| 304 | Not Modified | 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告 诉客户,原来缓冲的文档还可以继续使用。 |
| 305 | Use Proxy | 客户请求的文档应该通过Location头所指明的代理服务器提取(HTTP 1.1新)。 |
| 307 | Temporary Redirect | 和302 (Found)相同。许多浏览器会错误地响应302应答进行重定向,即使原来的请求是POST,即使它实际上只能在POST请求的应答是303时才能重定 向。由于这个原因,HTTP 1.1新增了307,以便更加清除地区分几个状态代码:当出现303应答时,浏览器可以跟随重定向的GET和POST请求;如果是307应答,则浏览器只 能跟随对GET请求的重定向。(HTTP 1.1新) |
| 400 | Bad Request | 请求出现语法错误。 |
| 401 | Unauthorized | 客户试图未经授权访问受密码保护的页面。应答中会包含一个WWW-Authenticate头,浏览器据此显示用户名字/密码对话框,然后在填 写合适的Authorization头后再次发出请求。 |
| 403 | Forbidden | 资源不可用。服务器理解客户的请求,但拒绝处理它。通常由于服务器上文件或目录的权限设置导致。 |
| 404 | Not Found | 无法找到指定位置的资源。这也是一个常用的应答。 |
| 405 | Method Not Allowed | 请求方法(GET、POST、HEAD、DELETE、PUT、TRACE等)对指定的资源不适用。(HTTP 1.1新) |
| 406 | Not Acceptable | 指定的资源已经找到,但它的MIME类型和客户在Accpet头中所指定的不兼容(HTTP 1.1新)。 |
| 407 | Proxy Authentication Required | 类似于401,表示客户必须先经过代理服务器的授权。(HTTP 1.1新) |
| 408 | Request Timeout | 在服务器许可的等待时间内,客户一直没有发出任何请求。客户可以在以后重复同一请求。(HTTP 1.1新) |
| 409 | Conflict | 通常和PUT请求有关。由于请求和资源的当前状态相冲突,因此请求不能成功。(HTTP 1.1新) |
| 410 | Gone | 所请求的文档已经不再可用,而且服务器不知道应该重定向到哪一个地址。它和404的不同在于,返回407表示文档永久地离开了指定的位置,而 404表示由于未知的原因文档不可用。(HTTP 1.1新) |
| 411 | Length Required | 服务器不能处理请求,除非客户发送一个Content-Length头。(HTTP 1.1新) |
| 412 | Precondition Failed | 请求头中指定的一些前提条件失败(HTTP 1.1新)。 |
| 413 | Request Entity Too Large | 目标文档的大小超过服务器当前愿意处理的大小。如果服务器认为自己能够稍后再处理该请求,则应该提供一个Retry-After头(HTTP 1.1新)。 |
| 414 | Request URI Too Long | URI太长(HTTP 1.1新)。 |
| 416 | Requested Range Not Satisfiable | 服务器不能满足客户在请求中指定的Range头。(HTTP 1.1新) |
| 500 | Internal Server Error | 服务器遇到了意料不到的情况,不能完成客户的请求。 |
| 501 | Not Implemented | 服务器不支持实现请求所需要的功能。例如,客户发出了一个服务器不支持的PUT请求。 |
| 502 | Bad Gateway | 服务器作为网关或者代理时,为了完成请求访问下一个服务器,但该服务器返回了非法的应答。 |
| 503 | Service Unavailable | 服务器由于维护或者负载过重未能应答。例如,Servlet可能在数据库连接池已满的情况下返回503。服务器返回503时可以提供一个 Retry-After头。 |
| 504 | Gateway Timeout | 由作为代理或网关的服务器使用,表示不能及时地从远程服务器获得应答。(HTTP 1.1新) |
| 505 | HTTP Version Not Supported | 服务器不支持请求中所指明的HTTP版本。(HTTP 1.1新) |
高级用法
- 上传文件
import requests
files = {'file' : open('favicon.ico','rb')}
r = requests.post("http://httpbin.org/post",files = files)
print(r.text)结果如下:
{
"args": {},
"data": "",
"files": {
"file": "a"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "148",
"Content-Type": "multipart/form-data; boundary=846578a1af414143bb31c34eb187abdf",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "59.51.114.201",
"url": "http://httpbin.org/post"
}里面包含files的字段替换为了favicon.ico中的内容。上传的文件部分会单独有一个files字段来识别
2.Cookies
- 获取Cookies
import requests
r = requests.get("https://www.baidu.com")
print(r.cookies)
for key,value in r.cookies.items():
print(key + "=" + value)结果如下
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
BDORZ=27315
3.会话维持
- Session对象
通常用于模拟等于成功之后进行下一步操作
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)结果如下
{
"cookies": {
"number": "123456789"
}
}4.SSL证书验证
requests提供了证书验证功能,当发送HTTP情书的时候,它会检查SSL证书,我们可以使用verify参数控制是否检查此证书。默认为True。
import requests
response = requests.get('https://www.12306.cn')
print(response.status_code)这里会提示一个SSLError,表示验证书错误。
下面将verify参数设置为False
import requests
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)结果如下
/Users/renming/anaconda3/lib/python3.6/site-packages/urllib3/connectionpool.py:858: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
200
发现一个警告,它建议我们给它指定证书
下面设置忽略这个警告
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)或者通过捕获警告到日志方式忽略警告:
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)或者指定一个本地证书作为客户端证书
import requests
response = requests.get('https://www.12306.cn',cert=('path/server.crt','/path/key'))
print(response.status_code)5.代理设置
- proxies参数
import requests
proxies = {
"http" : "http://10.10.1.10:3128",
"https" : "http://10.10.1.10:1080",
}
requests.get("https://www.taobao.com",proxies = proxies)若要使用HTTP Basice Auth,使用类似
http://user:password@host:port
这样的语法来设置代理
import requests
proxies = {
"http":"http://user:[email protected]:3318/",
}
requests.get("https://www.taobao.com",proxies = proxies)- SOCKS协议代理
首先需要安装socks库
pip install ‘requests[socks]’
import requests
proxies = {
"http":"socks5://user:password@10.10.1.10:3318/",
"https":"socks5://user:password@10.10.1.10:3318/",
}
requests.get("https://www.taobao.com",proxies = proxies)6.超时设置
- timeout参数
import requests
r = requests.get("https://www.taobao.com",timeout = 1)
print(r.status_code)以上超时时间为一秒,如果一秒内没有响应,那就抛出异常
实际上,请求分类两个阶段,即链接(connect)和读取read(read)
上面设置的timeout将用于链接和读取这二者的timeout的综合。
可以分别指定,传入一个元组
r = requests.get(“https://www.taobao.com“,timeout(5,11,30))
如果要永久等待则timeout为None,或者不加参数
7.身份认证
- requests自带的身份认证功能
import requests
from requests.auth import HTTPBasicAuth
r = requests.get("http://localhost:5000",auth=HTTPBasicAuth('username','password'))
print(r.status_code)更加简单的传参方式,直接传入一个元组
r = requests.get(‘http://localhost:5000‘,auth(‘username’,’password’))
- OAuth认证
需要安装oauth包
pip install requests_oauthlib
import requests
from requests_oauthlib import OAuth1
url = "https://api.twitter.com/1.1/account/verify_credentials.json"
auth = OAuth1('YOUR_APP_KEY','YOUR_APP_SECRET',
'USER_OAUTH_TOKEN','USER_OAUTH_TOKEN_SECRET')
requests.get(url,auth=auth)