今天任务安装R包并处理一个数据文件
R包
R包都有自己的说明书(cheatsheet),俗称小抄。
以后学习R包,主要自己研究小抄,那么小抄的获得方式有哪些?
方法1:去百度/谷歌XX小抄
方法2:找Rstudio的cheatsheet网站(网速好慢的)
https://www.rstudio.com/resources/cheatsheets/
方法3. 教程里用到的包都可以到生信星球公众号回复相应的包名来获取
了解tidyr包
tidyr的功能主要有:
(1)数据框的变形
(2)处理数据框中的空值
(3)根据一个表格衍生出其他表格
(4)实现行或列的分割和合并
这个包是把你要用的数据处理成标准而统一的数据框,就是数据分析前的准备工作。
安装tidyr包
-
下载和安装tidyr包
install.packages("tidyr")
-
加载tidyr包
library(tidyr)
-
新建数据框
a<-data.frame(GeneId = rep("gene5",times=3),SampleName =paste("Sample",1:3,sep=""),Expression=c(14,19,18))
自己随便建立一个数据框如下
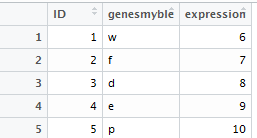
bioplanet<-data.frame(ID=c(1:5),genesmyble=c("w","f","d","e","p"),expression=c(6:10))
注释与注意事项
rep,重复,括号中填要重复的字符和重复次数。
paste,连接两个字符串,括号要填两个代连接字符并指定分隔符(sep),没有分隔符就填sep=“”。
1:3表示从1到三。如需一列中需要填入三个无规律的数字,可以用向量c(1,3,4),同样如果填的是字符串也需要加双引号,例如c("doudou","huahua","xiaoyu")。
2.了解概念:key-value--“键值对” ,表示一种对应关系。“键”和“值”都是列名,如SampleName和Expression的对应。
3.函数后面一般都要加括号,括号里第一个参数是都数据框名
4.字符串要加双引号(行名和列名也是字符串,但是可以不用加),其他单元格(姑且这么叫了)里出现的字符串要加。
行 raw
列 column,简化写法为col
-
了解Tidyr Data
这是一种组织表格数据的方式,提供了一种能够跨包使用的“统一”的数据格式。
什么叫“统一”?
每个变量(variable)占一列,每个情况(case,姑且这么翻译)和观测值(observation)占一行。
整理数据(Reshape Data)
先了解两个函数
gather函数:将宽数据变成长数据格式。把列名变行数值。
spread函数:将长数据变成宽数据格式。 把列数值变列名。
-
新建一个数据文件
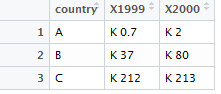
> a<- data.frame(country=c("A","B","C"),"1999"=paste("K",c(0.7,37,212)),"2000"=paste("K",c(2,80,213)))
> View(a)
-
将列名合并成一个列
gather(a,X1999,X2000,key = "year",value = "cases")
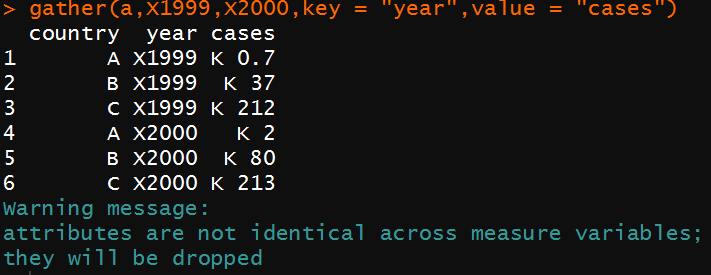
gather括号里的分别是:
数据框名,需合并的列名(两个),合并后的key列名,value列名。
其中,需合并的列名也可以列在最后(其实个顺序才是默认的),key=和value=也可以省略,如果按照上面小抄的命令括号里那个顺序,省略了就会报错。
简化代码gather(a,"year","cases",X1999,X2000) #推荐的偷懒做法
合并前的列名如果比较多,可以用排除法来偷懒,在上图例子中可用gather(a,year,cases,-country) #-country的意思就是合并除country外剩下的列。
-
处理丢失的数据
三种处理方式:
(1).删除整行
(2).根据上下文(瞎)蒙一个
(3).同一列的空值填上同一个数。
- 删除整行
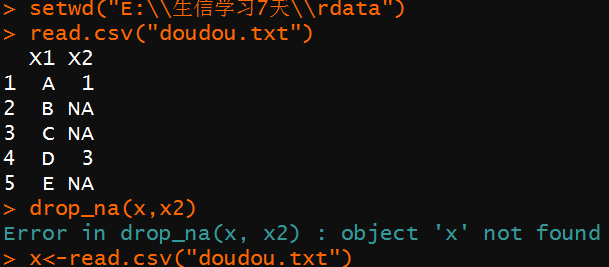
drop_na():有空值的,整行删除掉
括号里填数据框名,依据的列名(有空值那一列的列名)

这里注意读入数据并赋值给一个变量
在这里之所以选择了csv,是因为这个神奇的格式支持R和Excel,默认参数好的很(默认分隔符是“,”,导出时也不会默认加引号。如果你用read.table试试就知道默认参数多笨了),并且转换txt也不会变乱码!
在这里补充下csv的导入和导出方式。(默认参数好,学R没烦恼)
导入:X<-read.csv('doudou.csv')
导出:write.csv(X,'doudou.csv')
- 根据上下文(瞎)蒙一个
fill(),根据上一行的数值填充上(好应付的感觉)
 Snipaste_2018-10-27_22-09-00.png
Snipaste_2018-10-27_22-09-00.png
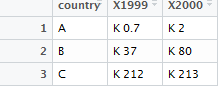
分割后的文件
csv 文件是用逗号分隔的,故而 sep = ","
tsv 文件是用制表符分隔的,故而 sep = "\t"
常用的分隔符还有空格 sep = " "
分隔符是任意的,可根据具体情况指定的。
在输入的时候,原内容是用什么符号分隔的,sep就要保持一致,否则可能无法正确读取
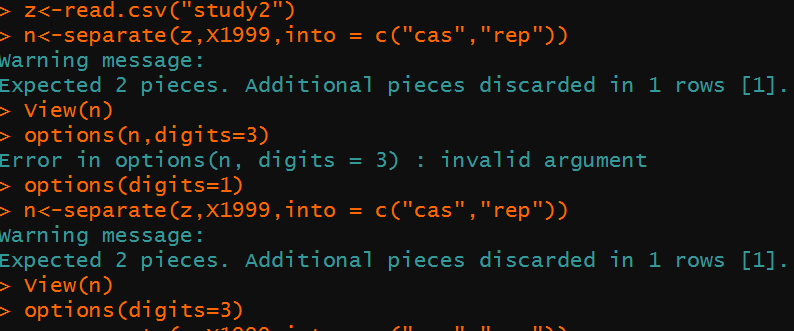
因为少打了sep函数0.7变成0了,经花花指导,原来不加sep自动识别分隔符,把小数点也算成分隔符了。因为只指定分割两列,所以7不出来了。
改为separate(a,X1999,into = c("cas","rep"),sep=" ")成功分割。

思维导图
今天学习结束,好像比昨天简单了一些,也许是我进步了。 _