python爬虫:利用BeautifulSoup爬取酷我音乐
python爬取酷我音乐,最终实现的效果是这样的:


分析:如何获得歌曲文件?
以歌曲《知否知否》为例,进入到该歌曲的播放页面,
http://www.kuwo.cn/yinyue/60140414/
分析请求到的文件:
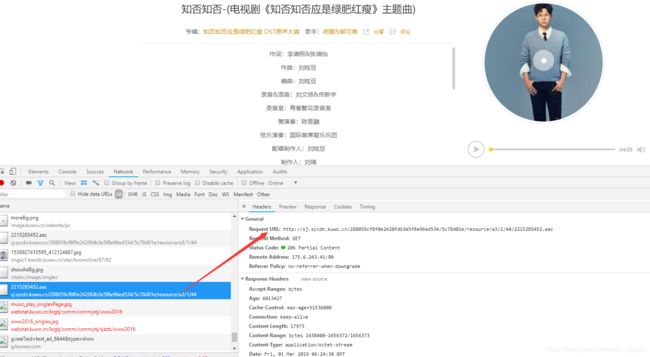
不难发现一个后缀为aac的文件,该文件即为对应的歌曲文件。
这个文件请求的地址为http://sj.sycdn.kuwo.cn/288059cf8f0e2420fdb3e5f8e96ed534/5c78d01e/resource/a3/1/44/2215285452.aac
这个链接看上去是没有关键点可言的,别着急,接着分析请求到的文件,可以看到如下图所示的请求:

这个请求的Response Headers中的Location字段即为上面的aac文件请求地址。
仔细观察该请求的url:
http://antiserver.kuwo.cn/anti.s?format=aac|mp3&rid=MUSIC_60140414&type=convert_url&response=res
与其它歌曲对比可以发现,唯一发生变化的只有rid的值,即“MUSIC_60140414”在变化,数字“60140414”就是这首歌的ID,而这个数字刚好就是播放页面地址中的一个字段:http://www.kuwo.cn/yinyue/60140414/
这样的话就很明确了,呵呵,下面根据以上信息分析一下思路:
- 通过播放地址拿到类似于“60140414”这样的歌曲ID;
- 把ID拼接到那个链接中,发送get请求,拿到Response Headers中的Location字段;
- 通过Location字段发送get请求,得到aac文件。
代码实现
1、得到歌曲ID:
def getMusic_id( url ):
if 'catalog' in url:
mid = re.match( 'http://www\.kuwo\.cn/yinyue/(.*)\?catalog=yueku2016', url ).group(1)
else:
mid = re.match( 'http://www\.kuwo\.cn/yinyue/(.*)/', url ).group(1)
return mid
在后面我发现播放地址有两种形式:
http://www.kuwo.cn/yinyue/60140414/
http://www.kuwo.cn/yinyue/60140414?catalog=yueku2016
为了方便后面的爬取,我就做了个判断来获取ID了。
2、得到aac地址:
def getAac_url( url ):
headers = {
'Accept': '*/*',
'Accept-Encoding': 'identity;q=1, *;q=0',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'antiserver.kuwo.cn',
'Range': 'bytes=0-',
'Referer': url,
'User-Agent':random.choice( UserAgents )
}
request_url = 'http://antiserver.kuwo.cn/anti.s?format=aac|mp3&rid=MUSIC_%s&type=convert_url&response=res'%getMusic_id(url)
m = requests.get( request_url, headers=headers,allow_redirects=False )
aac_url = m.headers['Location']
return aac_url
注意,这里酷我对于请求头的检查比较严格,请按照实际情况填写好。我这里的User-Agent是从我写好的一个文件中随机获取的,大家可以根据自己的情况填写。
3、得到歌曲信息:
def getMusicInfo( url ):
info = {}
headers = {
'User-Agent':random.choice( UserAgents ),
'Referer':url
}
result = requests.get( url, headers=headers )
soup = BeautifulSoup( result.text, 'lxml' )
name = soup.find( id='lrcName' ).get_text()
artist = soup.find( class_='artist' ).find('a').get_text()
album = soup.find( class_='album' ).find('a').get_text()
info['name'] = name
info['artist'] = artist
info['album'] = album
return info # {'name': '', 'artist': '', 'album': ''}
通过播放地址爬取到歌曲的相关信息。
4.下载歌曲:
def downloadMusic( url, aac_url, artist, name ):
headers = {
'Accept': '*/*',
'Accept-Encoding': 'identity;q=1, *;q=0',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Range': 'bytes=0-',
'Referer': url,
'User-Agent':random.choice( UserAgents )
}
m = requests.get(aac_url, headers=headers)
# 音乐存放在music文件夹中
if not os.path.exists( 'music' ):
os.mkdir('music')
if m.status_code == 206:
with open('music/'+artist+' - '+name+'.mp3', 'wb') as fp:
fp.write( m.content )
print( artist+' - '+name+'.mp3 获取成功' )
else:
print( artist+' - '+name+'.mp3 获取失败' )
这里我最后保存文件的时候把后缀固定为.mp3了。
好,以上方法都实现了,下面就是直接搜索并下载想要的歌曲了。
5.搜索并下载:
def searchMusic( name ):
info = []
search_url = 'http://sou.kuwo.cn/ws/NSearch?type=all&catalog=yueku20177&key=%s'%name
headers = {
'User-Agent':random.choice( UserAgents )
}
result = requests.get( search_url, headers=headers )
soup = BeautifulSoup( result.text, 'lxml' )
musicList = soup.find( class_='list' ).find_all('li')
# 循环得到每一首歌的url,通过url调用getMusicInfo()方法得到每一首歌的信息,将其存入到info中
for music in musicList:
url = music.find( class_='m_name' ).find('a')['href']
data = getMusicInfo( url )
data['url'] = url
info.append( data )
for i in range( len(info) ):
print(i+1, info[i]['artist']+' - '+info[i]['name']+'.mp3') # 打印出每首歌曲
index = int( input('请选择下载的歌曲序号:') ) - 1
url = info[index]['url']
downloadMusic( url, getAac_url(url), info[index]['artist'], info[index]['name'] )
print( '下载完成' )
酷我音乐搜索的链接是:
http://sou.kuwo.cn/ws/NSearch?type=all&catalog=yueku20177&key=知否知否
我们只要把想要的内容拼接到后面就好了。
到此我们只需要调用searchMusic() 方法,把要搜索的内容传进去,就可以下载到我们想要的歌曲了,呵呵。
以上代码并没有经过优化,如果大家参照了本人的代码,请根据实际使用情况稍作调整优化。
下一步就可以批量爬取各个榜单的歌曲了,这个大家有兴趣的话可以自己去实现一下。
请注意:以上内容只作学习交流使用,请勿用于违法目的!